
基于深度学习的视频插帧算法
2019-09-12 10:41张倩姜峰
智能计算机与应用 2019年4期
关键词:深度学习
张倩 姜峰

摘 要:视频帧率转换技术是利用视频中相邻两帧之间的相关信息并应用插值的方法将中间帧重建出来的一种技术。由于该技术能在编码中去除冗余信息并降低视频传输过程中的帧率,减少视频网络传输的数据量,因此可应用于视频压缩或增强视频连续性。本文将传统方法中的光流估计与深度学习相结合,提出了一种将运动估计和遮挡处理联合建模的视频帧插值的端到端卷积神经网络模型。首先使用改进的GridNet网络模型计算输入图像之间的双向光流,根据估计到的双向光流信息与输入图像进行warp操作得到2个翘曲图像,为解决遮挡问题,使用另一個GridNet网络模型重新估计图像的双向光流信息并预测插值帧的像素的可见性,最后将估计到的信息与原图像通过线性融合以形成中间帧。本文还尝试了多种损失函数,最终确定了将L1损失、感知损失、warp损失、平滑度损失等多种损失函数加权而成的损失函数。实验结果证明,本文提出的视频插帧网络结构可以有效提高光流估计的质量并改善遮挡问题,可以生成逼真、自然、质量更好的中间帧。
关键词:视频插帧;深度学习;光流估计
文章编号:2095-2163(2019)04-0252-07 中图分类号:TP391.4 文献标志码:A
0 引 言
伴随智能终端及多媒体技术的迅猛发展,视频应用更加多样化,其中涉及到的视频内容和种类正陆续增多。与此同时,高清晰度的显示设备也呈现出大规模增长态势,高刷新频率的显示器不断普及,人们对视频分辨率的要求也越来越高。目前情况下,很多视频的帧率通常只用30帧/秒,人们在观看这种视频时视觉感知上会出现卡顿等问题,也无法发挥高刷新频率显示器的优势。因此可以将低帧率的视频通过视频帧率转换技术插值为高帧率视频,例如可将帧率为30帧/秒的视频提升至帧率为60帧/秒,使视频更加地平滑和连续,从而提升人们在观看视频时的逼真度和交互感。
研究可知,作为数据量非常巨大的信息载体,视频在网络传输过程中对带宽的要求非常高,而且存储视频的成本也变得巨大,因此就必须采取高效的视频压缩方法,尽可能去除视频中的冗余成分。主流的视频编码标准H.265/HEVC[1]已经在很大程度上降低了视频的冗余信息。视频冗余信息整体上可分为时间冗余和空间冗余等。其中,时间冗余信息主要指视频相邻帧之间具有相似性,H.265/HEVC采用帧间预测的方法来去除时间冗余信息,帧间预测则通过将已编码的视频帧作为当前帧的参考,进行运动估计来获取运动信息,从而去除时间冗余。空间冗余信息主要指视频单帧图像在空间上的局部相似性,H.265/HEVC通常采用帧内预测和变换编码的技术去除空间冗余信息,帧内预测通过已编码的像素预测当前像素去除空间冗余信息。变换编码将图像能量在空间域的分散分布转换至变换域的集中分布,从而去除空间冗余。
尽管最新的国际视频压缩标准H.265/HEVC较H.264/AVC相比性能上有了显著的提高,可以大幅度地去除视频中的冗余信息。但在网络带宽有限等情况下,这些压缩标准仍然不能满足人们的需求,所以一些研究人员开始尝试用其他的方法手段继续对视频进行压缩处理,其中效果较好的方法为帧率转换技术。视频帧率转换技术是指利用视频中相邻两帧之间的相关信息并应用插值的方法将中间帧重建出来的一种技术。该技术在视频编码中去除冗余信息并降低视频传输过程中的帧率,有效减少视频网络传输的数据量。视频插帧技术的效果决定了重建帧的质量,因此视频插帧技术在视频压缩领域有着重要影响。
视频插帧技术一直是计算机视觉领域的热点研究内容之一,视频插帧技术的提升对帧率转换技术及视频压缩技术的研发起着举足轻重的作用,同时视频插帧技术也广泛应用于慢镜头回放等场景中,这也推动相关研究人员不断地改进这一技术,并积极展开更深层次的探索。
1 相关工作
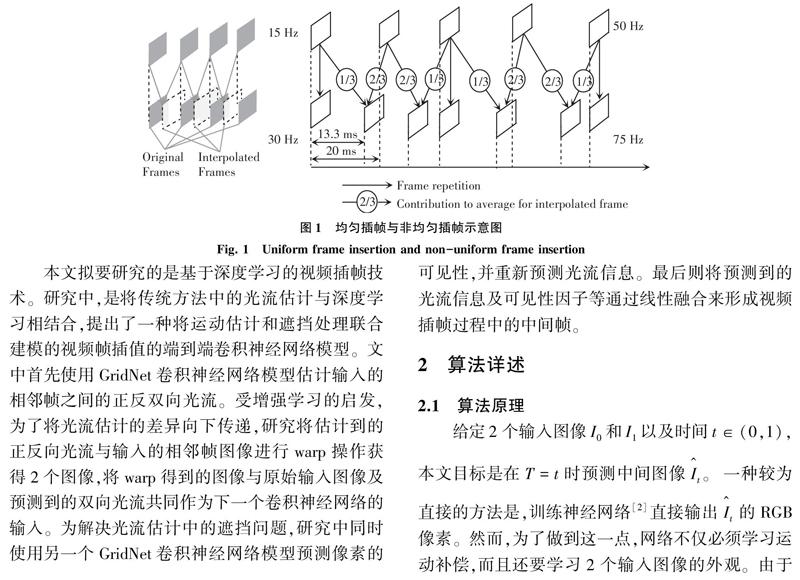
随着深度学习在计算机领域不断取得成功,研究者们即尝试将深度学习与视频插帧技术相结合来满足插帧需求。视频插帧技术是指利用视频中相邻前后帧之间的相关信息,应用插值的方法获得中间帧。根据新的插值帧的数量与输入视频帧的数量关系,视频插帧可分为均匀插帧与非均匀插帧,如图1所示。相应地,均匀插帧是指新的插值帧与输入的视频帧序列按照1:1的比例合成新的视频序列,非均匀插帧一般是指新的插值帧与输入的视频序列按照如图1所示2:3的比例合成新的视频序列,本文着重研究的是均匀的视频插帧技术。
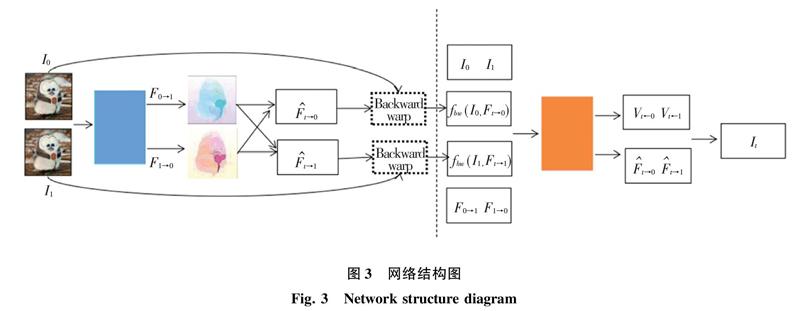
本文拟要研究的是基于深度学习的视频插帧技术。研究中,是将传统方法中的光流估计与深度学习相结合,提出了一种将运动估计和遮挡处理联合建模的视频帧插值的端到端卷积神经网络模型。文中首先使用GridNet卷积神经网络模型估计输入的相邻帧之间的正反双向光流。受增强学习的启发,为了将光流估计的差异向下传递,研究将估计到的正反向光流与输入的相邻帧图像进行warp操作获得2个图像,将warp得到的图像与原始输入图像及预测到的双向光流共同作为下一个卷积神经网络的输入。为解决光流估计中的遮挡问题,研究中同时使用另一个GridNet卷积神经网络模型预测像素的可见性,并重新预测光流信息。最后则将预测到的光流信息及可见性因子等通过线性融合来形成视频插帧过程中的中间帧。
2 算法详述
2.1 算法原理
研究在相同或相反的方向上取2个输入图像之间的光流方向,并相应地调整公式(3)的幅度(1-t)。类似于RGB图像合成的时间一致性,可以通过如下组合双向输入光流来近似中间光流(以矢量形式表示)。可参考写作如下数学形式:
2.2 网络结构
研究中用到的网络结构整体如图3所示。对于光流计算和光流插值CNN,研究采用GridNet架构[8]。GridNet是一个完全卷积的神经网络,由编码器和解码器组成,对于2个网络,在相同的空间分辨率下将编码器和解码器进行连接。研究中的编码器共有6个层次结构,包括2个卷积和1个Leaky ReLU(α=0.1)图层。设计时,除去最底层之外的每个层次结构的末尾,使用步幅为2的平均池化层来减小空间维度。解码器部分配置了5个层次结构。在每个层次结构的起始处,使用双线性上采样层将空间维度增加2倍,紧接着就是2个卷积和Leaky ReLU层。
对于光流计算CNN,在编码器的前面数层中使用大型滤波器以捕获大幅运动是至关重要的。因此,研究在前两个卷积层中使用7*7内核,在第二层次中使用5*5。对于整个网络其余部分的层,研究使用了3*3卷积内核。
2.3 学习算法
本文中的网络使用Adam优化器[9]训练500次迭代。学习率初始化为0.000 1,每200个迭代减少10倍。在训练期间,所有视频剪辑先被分成较短的视频剪辑,每个视频剪辑中有12帧,并且2个剪辑中的任何一个之间没有重叠。对于数据增强,研究将随机反转整个序列的方向,并选择9个连续帧进行训练。
2.4 损失函数
对于视频插帧合成的插值帧的质量良好与否,损失函数起着不可低估的作用。研究时最直接的衡量模型效果的损失函数就是计算合成帧与真实帧之间的像素误差,这种方法虽然可以得到高优的量化指标,但是人眼往往对这种像素级别的微小误差并不敏感,而是更加关注图像的边缘及纹理信息。广泛调研后可知,并未发现哪种损失函数的性能堪称完美,而是各占胜场、也各有不足,因此可将多种损失函数进行综合加权,这样一来也许会取得较好效果。此处,给定输入图像I0和I1,两者之间有一组中间帧It(t∈(0,1))。文中针对实验时采用的4种损失函数,可做研究阐析论述如下。
2.4.1 L1范数与L2范数
像素之间的误差小并不代表着肉眼对2张图片感受相同,由于自然图像遵循多模态分布,因此L1范数与L2范数收敛的结果非常模糊。
2.4.2 感知损失
感知损失在文献[10]中首获提出,用于图像风格转换。感知损失如图4所示。
感知损失将已经训练好的VGG-16[11]网络作为损失函数的一部分。研究可知,感知损失是从预先训练的VGG网络中提取特征误差、而非像素误差,因此就包含了对高频细节的感受能力,这也是L1范数与L2范数所不具备的。在实际训练中,加入了感知损失后,纹理和细节得到了明显的增强。
由于本课题的任务与风格转换不同,更加需要逼近真实的图像,因而即需使用更加浅层的网络输出。经过调试,使用VGG-16的第二层池化层作为输出获得了良好效果。感知损失的计算公式如下:
其中,函数为ImageNet预训练VGG16模型的第二层池化层之前的网络结构,包括4个卷积层和2个池化层。
2.4.3 warp损失
warp损失主要用来计算光流估计的质量。光流信息则是用于表示相邻帧对应像素位置的运动矢量信息,而warp操作可依次分为2个步骤:像素映射以及二维线性插值,因此当已知相邻帧之间的光流场信息时,就可以通过变形操作将一帧图像映射为另一帧图像。再通过计算目标图像与变形操作合成的新图像间的差异,就可以用来检测光流估计的质量。warp损失的计算公式如下:
2.4.4 平滑度损失
平滑度损失的计算公式如下:
平滑度损失与warp损失相结合都是用来检测光流估计的质量。
由于本文所讨论的L1范数与L2范数、感知损失、warp损失、平滑度损失单独应用到视频插帧技术中都存在一定的缺陷与不足。其中,L1范数和L2范数直接体现了像素级别的误差,训练速度快,但是却只是给出了像素的差值而忽略了对插值帧图像结构等差异的计算。感知损失虽然有效解决了使用像素误差产生的模糊问题,更加关注了图像的细节纹理信息,但是感知损失对图像的低频信息却并不敏感。单独使用warp损失和平滑度损失仅能衡量光流估计的质量而无法准确衡量最终插值结果的质量。因此经过仿真验证,将多种损失函数引入加权处理会弥补单独使用损失函数的缺点,将会取得比较良好的结果。给定输入图像I0和I1,两者之间有一组中间帧It(t∈(0,1)),本次研究的最终损失函数是4种损失函数的线性组合,其数学公式可表示为:
同时,文中网络的每个组成部分都是可区分的,包括warp和光流计算。因此,实验的模型可以进行端到端的训练。
3 实验
3.1 实验参数及数据集
本文使用Adam学习算法优化训练模型,进行参数更新,设置 Adam 学习算法中相关参数为:α= 0.000 1,β1= 0.9,β2 = 0.999,ε= 10-8。
研究中训练使用的数据集是从YouTube收集的240-fps视频,数据集中都有各种各样的场景,从室内到室外、从静态到移动的摄像机、从日常活动到专业运动等。在训练期间,所有视频剪辑先被分成较短的视频剪辑,每个视频剪辑中有12帧,并且2个剪辑中的任何一个之间没有重叠。对于数据增强,研究中随机反转整个序列的方向,并选择9个连续帧进行训练。在图像级别上,每个视频帧的大小被调整为较短的空间维度,再结合水平移动随机裁剪为352*352大小。
3.2 实验结果
研究使用所有数据训练本文组建的网络,并在多个独立的数据集上测试本文的模型,包括Middlebury基准、UCF101、慢流数据集和高帧率Sintel序列。
总地来说,对于Middlebury,研究中将8个序列的单帧视频插值结果提交给其评估服务器。对于UCF101,在每三帧中,第一和第三帧用作输入,预测第二帧。慢速流动数据集包含46个使用专业高速摄像机拍摄的视频。研究使用第一和第三视频帧作为输入,并插入中间帧,相当于将30-fps视频转换为60-fps視频。
最初的Sintel序列以24-fps渲染。其中13个以1 008-fps重新渲染。要使用视频帧插值方法从24-fps转换为1008-fps,需要插入41个中间帧。然而,正如在前文中所分析的那样,使用递归单帧插值方法不能直接实现这一点。因此,本次研究预测31个中间帧,以便与先前的方法做出公平比较。
實验中,研究对比了训练样本数量的影响,这里比较2个模型。一个仅在Adobe240-fps上训练,另一个在完整的数据集上进行训练,2个模型在UCF101数据集上的性能见表1。
从表1的实验结果可以看出,训练数据越多,本文模型的效果越好。以图片的形式给出对比效果如图5所示。网络模型在慢数据集下的实验结果见表2。网络模型在高帧率数据集下的实验结果见表3。
在本节中,研究将本文的方法与最先进的方法进行比较,包括基于相位的插值、可分离的自适应卷积(SepConv)和深度体素流(DVF)。实验表明,本文提出的网络模型可以获得更加精确的视频插帧效果。
4 结束语
本文研发提出了一种端到端可训练的CNN,可以在2个输入图像之间根据需要产生尽可能多的中间视频帧。首先使用流量计算CNN来估计2个输入帧之间的双向光流,并且2个流场线性融合以接近中间光流场。然后,使用流动插值CNN来重新定义近似流场并预测用于插值的软可见性图。接下来,又使用超过1.1K 240-fps的视频剪辑来训练本文的网络预测7个中间帧。对单独验证集的消融研究证明了流动插值和可见性图的优势。仿真实验证明,本文的多帧方法在Middlebury、UCF101、慢速流和高帧率Sintel数据集上始终优于最先进的单帧方法。对于光学流的无监督学习,本文研发的网络也要优于KITTI 2012基准测试中最近的DVF方法。
参考文献
[1]SULLIVAN G J, OHM J R, HAN W J, et al. Overview of the high efficiency video coding (HEVC) standard[J]. IEEE Transactions on circuits and systems for video technology, 2012, 22(12):1649-1668.
[2]LONG G, KNEIP L, ALVAREZ J M, et al. Learning image matching by simply watching video[M]//LEIBE B, MATAS J, SEBE N, et al. Computer Vision-ECCV 2016. ECCV 2016. Lecture Notes in Computer Science. Cham:Springer,2016, 9910:434-450.
[3]BAKER S, SCHARSTEIN D, LEWIS J P, et al. A database and evaluation methodology for optical flow[C]//2007 IEEE 11th International Conference on Computer Vision. Rio de Janeiro, Brazil:IEEE,2007:1-8.
[4]NIKLAUS S, MAI Long, LIU Feng. Video frame interpolation via adaptive convolution[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu, HI, USA:IEEE, 2017:2270-2279.
[5]NIKLAUS S, MAI Long , LIU Feng. Video frame interpolation via adaptive separable convolution[C]//2017 IEEE International Conference on Computer Vision (ICCV).Venice, Italy:IEEE, 2017:261-270.
[6]LIU Ziwei, YEH R, TANG Xiaoou, et al. Video frame synthesis using deep voxel flow[C]//Proceedings of International Conference on Computer Vision (ICCV). Venice, Italy:IEEE, 2017:1-10.
[7]ZHOU Tinghui, TULSIANI S, SUN Weilun, et al. View synthesis by appearance flow[C]//LEIBE B, MATAS J, SEBE N, et al. Computer Vision-ECCV 2016. ECCV 2016. Lecture Notes in Computer Science, Cham:Springer,2016,9908:286-301.
[8]FOURURE D , EMONET R, FROMONT E , et al. Residual Conv-Deconv grid network for semantic segmentation[C]//British Machine Vision Conference, 2017 (BMVC'17).London, UK:BMVC, 2017:1-12.
[9]KINGMA D P, BA J. Adam:A method for stochastic optimization[J]. arXiv preprint arXiv:1412.6980, 2014.
[10]JOHNSON J, ALAHI A, LI Feifei. Perceptual losses for real-time style transfer and super-resolution[M]//LEIBE B, MATAS J, SEBE N, et al. Computer Vision-ECCV 2016. ECCV 2016. Lecture Notes in Computer Science. Cham:Springer, 2016,9906:694-711.
[11]SIMONYAN K, ZISSERMAN A. Very deep Convolutional Networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556v6, 2015.
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
中国远程教育(2016年11期)2016-12-27
现代商贸工业(2016年25期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
