
基于先验Haar-Like特征的多通道人体检测方法*
2019-09-11 02:25周剑宇
传感器与微系统 2019年9期
周剑宇, 梁 栋, 唐 俊
(安徽大学 电子与信息工程学院,安徽 合肥 230601)
0 引 言
目前人体目标检测方法主要分为三大类:DPM法[1,2]、深度学习法[3]、决策森林法[4,5]。这三类方法在行人检测方面都能够获得比较好的结果。本文提出基于决策森林的方法。文献[6]中梯度方向直方图(histograms of oriented gradients,HOG)特征的提出,为近年来的人体目标检测提供了最为有效的特征。HOG特征[7~10]能够通过边缘的方向密度分布较好地描述出目标的轮廓信息。文献[5]提出积分通道特征(integral channel feature,ICF)的概念,将HOG特征通道与3个颜色特征通道以及一个梯度幅值特征通道结合在一起,通过计算各个通道上的积分图像,在保证检测效果的同时,能够获取更快的速度。文献[4]则提出了一种基于ICF的优化算法,即聚合通道特征(aggregation channel feature,ACF),根据自然图像中尺度不变性的特性,利用邻近尺度进行快速特征金字塔的多尺度计算。文献[5]提出,对低阶特征进行滤波提取出高阶特征,将高阶特征输入增强型决策森林,达到较好的检测效果。
本文提出了一种基于先验知识的人体检测方法。不同于文献[7]的使用整个行人检测器用于区域建议,提出了使用人体上半身检测器。实验表明,所提方法提升人体检测器的性能。
1 基于先验知识的Haar-Like特征
Haar-like特征是检测中常用的二阶特征,在计算机视觉领域内Haar-like特征经常用于人脸检测。但是将传统的Haar-like特征与传统的一阶通道特征结合在一起去训练人体检测器时,并不能很好提升检测器的检测效果。受到Haar-like特征在人脸检测中取得较好的结果的启发,尝试在ACF检测方法的基础上,加入二阶的Haar-like特征来进行人体检测。
通过观察可以发现,在遮挡现象不可避免时,上半身以及头部被遮挡的往往能够保持较好的轮廓特征。针对此现象,根据人体身形中头部以及肩膀部分所形成的投影特点,设计了一个人体上半身模型。随后,根据该模型提供的先验知识,设计了一个基于人体上半身特点的Haar-Like特征模板族。
1.1 人体半身模型
首先,根据人体上半身的投影特点,可以设计一个人体形状模型。然后,使用不同大小尺寸的模板在这个上半身模型上进行滑动,据此能够生成若干个不同的Haar-Like特征。模板族及部分不同大小的模板示例如图1所示。
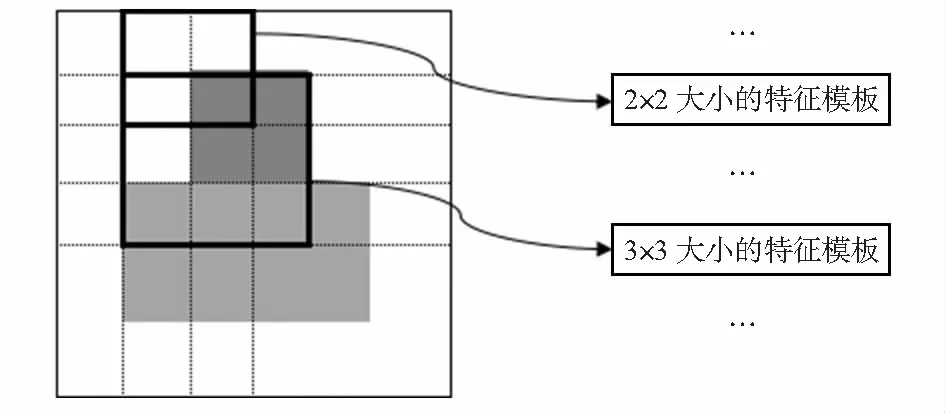
图1 特征模板示例
为了方便计算以及提高运算效率,所设计的人体模板均匀分割成相同大小的矩形块。每一个矩形块将对应于一定的权重,此权重则将用于二阶特征的计算。
根据梯度向量生成人体模型的边缘图以及分割效果如图2所示。
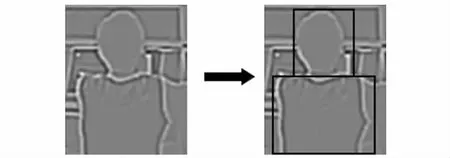
图2 人体模型的边缘图以及分割效果
如图2所示,可以通过分割结果图清晰地看出,整个人体上半身模型可以看成3个部分:头部、上半身以及背景。这三个部分在图像中具有不同的颜色或者纹理特征。在给不同部分中的每一个矩形块设置不同的特征权重之后,将这些矩形块的特征权重则与上文提到的不同大小尺寸的模板相结合,构成提出的人体检测器的先验知识。通过实验结果可以发现,该先验知识能够有效提高检测器的鲁棒性。
在对图像进行分割计算时,将图像分割成60像素×60像素大小的图像块,而文中提出的二阶特征提取及计算都是在这一系列图像块的基础上进行的。再将这些图像块以6像素×6像素大小为计算单元进行划分,划分所得的每一个计算单元则与上文所述的一个矩形块相对应。
1.2 特征模板族生成
根据1.1中所设计的人体上半身模型以及特征模板族的概念,通过将每个矩形块权重赋予不同尺寸的模板中,即可得到特征模板族。
1)特征模板为一列固定高和宽的矩形框。所有的矩形框的宽度为1~4个计算单元,高度为1~3个计算单元,据此可以算得12个不同的尺寸大小矩形框。利用这些不同尺寸的矩形框滑动人体上半身模型,就可以生成一组Haar-Like特征。
特征模板尺寸大小符合如下条件
M={(w,h)|w≤Wmax,h≤Hmax,w,h∈N+}
(1)
式中M为模板所有尺寸的集合,w为模板的宽度,h为模板的高度,Wmax为模板的宽度上限,Hmax为模板的高度上限。
2) 人体上半身模型是由3个部分构成:头部、上半身、背景。i表示矩形块在人体上半身模型中的横坐标,j表示其纵坐标,P(i,j)为矩形块在模型中的位置。人体模型内矩形块的权重符合等式
(2)
式中W(i,j)为人体上半身模型内,位置坐标为P(i,j)矩形块的的权重。Phead,Pbody,Pbackground分别为人体半身模型中头部、上半身和背景区域包含的所有矩形块位置坐标。
由1.1节可知,人体上半身模型被分割成了若干个矩形块,而每个矩形块对应某一特定的权重,所以,当模板矩形框滑过模型时,该矩形框内每个矩形块的权重构成了一个Haar-Like特征。最后生成的每一个特征模板都符合如下条件
F={(m,Wf)|m∈M,Wf∈R2}
(3)
式中m为该Haar-Like特征的尺寸大小,Wf为尺寸大小为m特征模板矩阵。
1.3 Haar-Like特征计算
在计算Haar-Like特征之前,先对全图进行聚合通道特征的提取。聚合通道特征包含10个通道的特征,10个通道分别是:LUV颜色的3个颜色通道特征,1个梯度幅度的通道特征,6个方向的梯度直方图的通道特征。在得到10个通道的特征之后,分别对这些特征进行Haar-Like特征的提取。单个Haar-Like特征的具体计算步骤如下:
1) 将聚合通道特征的每一个通道的特征图分割成60像素×60像素大小的图像块。
2) 使用Haar-Like特征模板通过滑窗的方式提取该图像块上每一个位置的Haar-Like特征值。Haar-Like特征图上位置(x,y)对应的权重矩阵计算方式
W(x,y,w)=Fmodel(m)⊗C(x,y,m)
(4)
式中m为该Haar-Like特征的尺寸大小,Fmodel(m)为尺寸为m的某一个特征模板,特征模板Fmodel(m)中,权重为1的计算元是增性算子,权重为-1的计算元是减性算子,权重为0的计算元是是中性算子。C(x,y,m)为聚合通道特征图上起始位置为(x,y)尺寸为m的矩形区域。⊗表示的是两个相同尺寸矩阵逐个元素相乘运算,W(x,y,m)为Fmodel(m)与C(x,y,m)两个矩阵内元素逐个相乘的结果,即为特征图坐标为(x,y)处的权重矩阵。
3) 根据每一个位置的权重矩阵,计算出整个Haar-Like特征图,特征图上每一个位置的特征值的大小与该位置上权重矩阵的关系
(5)
式中F(x,y,m)为Haar-Like特征图上位置为(x,y)上,尺寸大小为m的某一个Haar-Like特征值。sum(Wadd(x,y,m))为该Haar-Like特征内增性算子在W(x,y,m)对应位置权重的和。sum(Wdec(x,y,m))为该Haar-Like特征内减性算子在W(x,y,m)对应位置权重的和。中性算子对应的一阶特征值则不做处理。Numadd和Numdec则分别为该Haar-Like特征内增性算子以及减性算子的个数。
2 本文方法
根据基于上半身先验知识的Haar-Like特征能够较好的描述人体上半身的特点,为了更好地获得检测效果,引入基于上半身先验知识的Haar-Like特征与ACF特征来提高检测器的准确性。
利用训练所得的两个检测器,具体的检测过程
1)提取出测试图像的ACF特征以及Haar-Like特征;
2)再分别对提取到的两类特征进行滑窗,将滑窗得到的检测块送入对应的特征检测器进行检测;
3)检测块被检测出包含行人的被标记为候选框,即bbshaar和bbsacf;bbshaar是Haar-Like特征检测器检测结果的边界框,bbsacf是ACF特征检测器检测结果的候选框。
4)将bbshaar和bbsacf叠加在一起得到BBS,之后对BBS使用非极大值抑制原理,获得最终的检测结果。
3 实验与分析
3.1 实 验
实验所使用的数据集为INRIA数据集。该数据集中训练正样本共有614张,共计2 416个行人,测试集有正样本288张,共计1 126个行人。训练负样本有1218张,测试负样本有453张。样本的尺寸大小都为64×128。在Haar-Like的特征提取过程中,使用训练正样本标注的上一半图像作为训练数据。在检测过程中,将Haar-Like特征检测器检测出的边界框的高度乘以2,宽度保持不变作为最后的边界框结果。
Haar-Like特征检测器的训练分为4个阶段进行,4个阶段分别使用了16,64,256和1 024个弱分类器,并且决策树的深度都为4。在训练的第一个阶段,使用随机生成的10 000负样本;而用于训练的总负样本数则不超过50 000个。
文中设计的人体半身模型大小为6×6个计算单元,特征模板的大小从1×1个计算单元到4×3个计算单元。根据设计的不同尺寸对人体半身模型进行滑窗提取,一共可以获得100个Haar-Like特征模板。当使用该Haar-Like特征模板族对大小为60像素×60像素的图像进行特征提取时,一共可以提取出71 620个特征。
3.2 实验结果分析
为了保证算法的检测效果,在实验过程当中,实验使用了相同的训练样本以及测试样本,对ACF,pAUCBoost[13],HOG-LBP[12],ChnFtrs[5]和本文方法的检测效果进行了对比实验。在实验中,使用召回率、平均对数漏检率、漏警率和PR曲线对检测器的检测效果进行评估。从实验对比结果可以看出使用级联的检测算法有着较好的检测结果。5种检测方法的召回率结果对比如表1所示。

表1 本文算法与其他算法对比 %
5种算法对比实验的PR曲线结果如图3(a)所示。
通过对ACF,pAUCBoost,HOG-LBP,ChnFtrs与本文方法的比较,可以看出:在结合了Haar-Like特征之后,检测器的检测效果有一定程度的提升,本文方法的召回率提高到了94.57 %。相比于传统的ACF算法,本文提出的方法召回率提升了大约2 %,平均对数漏检率降低了0.63 %。而相比于ChnFtrs算法,本文提出的方法召回率提升了大约2.89 %,平均对数漏检率降低了4.53 %。
如图3(b)所示,通过对检测结果的PR曲线和ROC曲线的观察以及对其召回率和平均对数漏检率的分析,可以看出:在结合了基于先验Haar-Like特征检测器具有更好的检测精度。本文算法检测效果如图4所示。
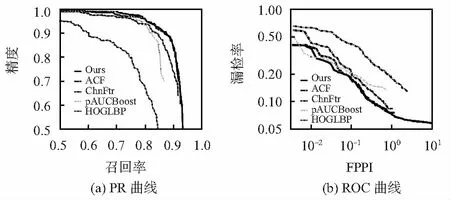
图3 5种算法的PR和ROC曲线

图4 本文方法检测效果示意
4 结束语
考虑ACF算法中只提取了颜色和梯度的特征,本文设计了结合基于先验知识的Haar-Like特征的人体检测方法。能够根据人体上半身的轮廓特点,增强检测器对人体特征的描述能力。实验结果表明:结合基于先验知识的Haar-Like特征的检测方法能够弥补ACF特征对人体轮廓描述的不足,从而能够对检测结果有一定的提升。
猜你喜欢
ELLE世界时装之苑(2022年2期)2022-02-14
数学年刊A辑(中文版)(2020年2期)2020-07-25
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
火力与指挥控制(2018年10期)2018-11-13
环球时报(2017-12-06)2017-12-06
中学生数理化·八年级数学人教版(2017年4期)2017-07-08
中国交通信息化(2017年9期)2017-06-06
电子制作(2017年10期)2017-04-18
中国医学装备(2016年6期)2016-12-01
中国新闻周刊(2016年33期)2016-10-27
