
VSM在旅游自动问答系统中的应用研究
2019-09-10 21:13:51欧阳林艳
山西能源学院学报 2019年2期
欧阳林艳


向量空间模型VSM是一种文本相似度比较算法,在自然语言处理领域有着十分重要的作用。自动问答系统作为自然语言处理的一个应用领域,可以根据用户问题,将用户问题与问答库中的问题进行相似度比较,找出相似度最高的问题,检索出其对应的答案,作为對用户的回答。采用向量空间模型VSM算法来进行相似度计算,能较好地解决这一类型的问题。
1 自动问答系统
自动问答系统(Question Answering System,QAS)是自然语言处理的一个重要应用领域,成为当前信息处理中的一个十分热门的话题。所谓问答(Question Answering ,QA),是指针对用户以自然语言方式提出的问题(Q),从文档集合DS={d1,d2,…dn}中,找出简短精确的答案(A)的过程。自动问答系统能够根据用户的自然语言提问,从知识库中抽取一个比较符合用户所提问题的答案,从而很好地回答用户问题,而不再像传统的信息检索只提供与关键词相关的信息列表。大规模文本处理技术的日趋成熟也成为推动问答系统实现的强大力量。
自动问答系统的处理步骤:
(1)输入问题;
(2)通过计算从数据库中找出与用户问题相近的问题;
(3)根据数据库中的“问答对”找出与之匹配的答案;
(4)将该答案反馈给用户,作为其需要的答案。
而其中,如何找出与用户问题最相近的数据库中的问题则成为了一个核心的问题,要进行相近问题的寻找,就必须采用合适的相似度计算方法进行计算。
2向量空间模型VSM
向量空间模型(VSM)是20世纪60年代末由Gerard Salton等人提出的,在Smart检索系统中有进行应用。该模型的设计思想是:将要比较的文档看成是空间中的两个向量,要判断两个文档的相似程度,则只要计算这两个“向量”之间的内积,内积越小,说明两个文档的相似程度越低;反之亦然。两个文档D1与D2之间的相关程度(Degree of Relevance)常常用它们之间的相似度Sim(D1,D2)来度量。
其中W表示的是每篇文档中每个项对应的权值。权值主要指的是在整个文档中,该项所携带的信息量的多少。在VSM算法中,定义每个项的权值则成为了一个重要问题。
3 TF-IDF算法
TF-IDF(Term Frequency–Inverse Document Frequency)算法是一种比较实用的权值定义算法,它是利用统计学原理,来评价一个字或者是词语对于文档集中某个文档的重要性。在TF-IDF算法中,权值可以表示为如公式2所示:
tfik表示项Tk在文档Di中的文档内频数,idfk表示项Tk的反比文档频数,其中idfk的计算一般采用idfk=log(N/nk)。N表示文档集中文档数量,nk表示项Tk的文档频数。
如果包含项Tk的文档越多,也就是nk越大,idfk越小,则说明项Tk类别区分能力不强,反之,则说明项Tk具有很好的区分能力。除此之外,文档的长度也是必须考虑的因素,因为在我们这种计算的情况下,如果某个文档越长,那么它被检索到的可能性也就越大。因此,通过对上式进行归一化处理,得到如公式3所示:
4 VSM在自动问答系统中的应用
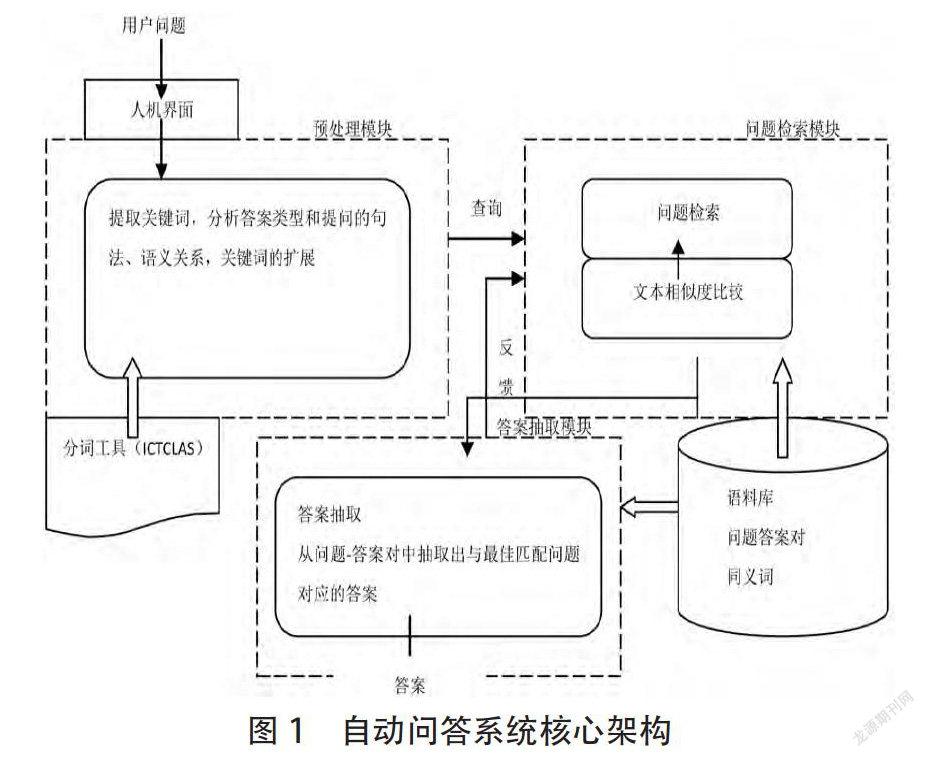
根据VSM相似度计算方法,以及自动问答系统本身的特点,设计的自动问答系统架构体系如图1,其核心主要包含预处理、问题检索以及答案抽取。
4.1问题预处理
4.1.1词的切分
利用中科院分词系统ICTCLAS将用户输入的问句以及问答库中的问题进行分词。对问句进行关键词语的提取,这样的好处是区分用户问句所关心的主题是什么,实际上也是提取主题关键词。关键词词典是一个有着相同或相似意义的词的聚类,可降低模板的复杂度,提高了词的重用性。同时在旅游问答库进行分类预处理,把相同类的问题放在一起,这样在把用户问句与知识库中问题进行比较的时候就避免了盲目比较和多余计算。
4.1.2 TF、IDF与权值的计算
按照TF、IDF的计算方法,将分词后每个问题的每个词语其TF、IDF计算出来,如“西安/有/哪些/景点”,则该问题中每个词语的TF均为1/4,每个IDF的值取决于两个因素:整个问题集的个数,以及该词语在整个问题集中出现的次数。从而根据这两个数据计算出初步的N/nk,假设“西安”只出现3次,则nk为3,而整个问题集为300个,则其N/nk的值为100。从而将每个问题的TF、IDF计算出来,并计算出每个词语的权值w,保存在数据库中。
当问答库中的问题有更新时,再重新计算TF、IDF以及w,保证每次后续计算相似度时都是最新状态的数据。
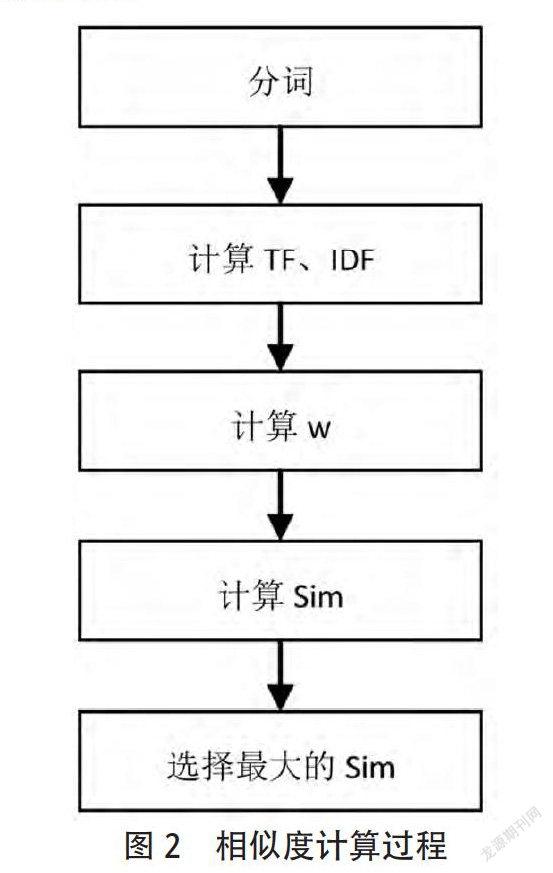
4.2问题相似度计算
当在用户界面输入用户问题时,系统将用户问句与知识库中的问题进行相似度比较,采用VSM算法进行文本相似度计算以及文本特征的提取。具体计算步骤如图2。
在这个算法计算过程中,文档中的项的顺序没有进行考虑,仅仅考虑的是文档的各项的权值。对数据值进行分析可知,一个词语在一个文档中不出现,或者在文档集每一个文档中都出现,其对于文本区分的贡献都为0。
4.3答案抽取
答案抽取是问答系统的最后阶段,这一阶段主要利用相似度值进行。
(1)按相似度值高低进行库中相关问题排序,将与用户问题相似度最高的问答表中的问题排在最前面。如用户问题:“什么时候去太白山比较适合”,算得与其相似度最高的值对应的问题是:“太白山适合什么时候去”,则将这个问题排在最前面。
(2)选出相似度值最高的问题,这个问题对应的答案也就是最贴近用户问题的答案。在数据库中“太白山适合什么时候去”对应的答案是“5月到10月”那么这个答案也就是回答用户问题“什么时候去太白山比较适合”的最佳答案。
5实验评测与分析
目前,对于一个问答系统的答案抽取效果评测有两个指标:准确率(Precision)与召回率(Recall)。对于这两个评测指标来说,不是所有的用户需要两个指数都要高,或者说在一般情况下,准确率和召回率双高并不是一件容易之事。对于需要结果集较小的用户来说,比较偏向于高准确率,而对于需要较大结果集的用户来说,则偏向于高召回率。
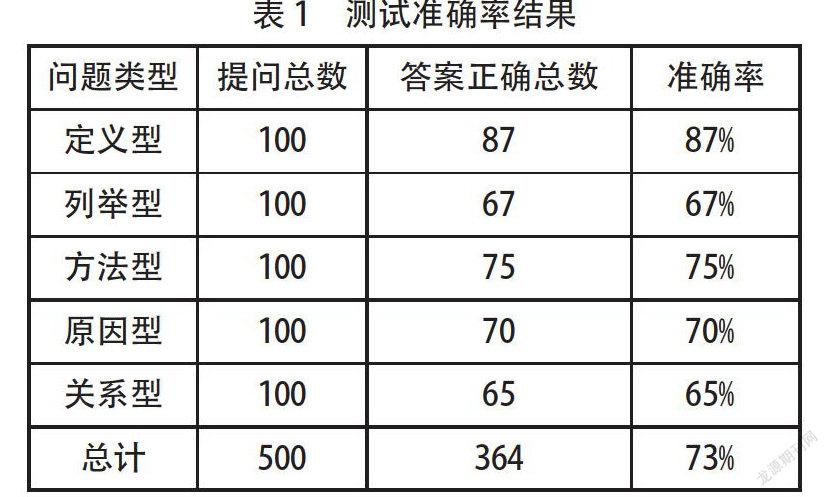
本自动问答系统通过实验评测,每类采用100个问题进行测试,通过测试,本系统的准确率结果见表1。
从上表结果来看,VSM算法能检索出较为准确的答案,定义型的準确率要高于其他几种类型,这是因为定义型的问题比较简单,并且在最初用关键词对问题进行分类,而只在特定的范围来进行抽取,这样防止了其他问题干扰,因而提高了准确率。同时,采用了同义词表,这也是提高准确率的原因之一。而关系型相对准确率较低,这个主要因素是问答库中数据不够全面引起,问题中各要素之间的关系也较为复杂,因而要不断扩充和完善问答库,将问题进行结构化处理,来提高回答问题的准确度。
6结束语
向量空间模型VSM的优点在于它把文档内容进行了一定的简化,将其表示为一些特征项的形式及其权值的向量,把对文档内容的处理转化为向量空间中的向量运算,从而很大程度上降低了问题的复杂度。但是,在有的情况下,简化过多通常会影响对于文档内容的理解,而丢失在自然语言理解中十分重要的信息。在文本相似度计算的过程中,由于考虑的仅是项的一些统计信息,未必能很客观地反应项的重要性,故在分析过程中有时会存在一定的偏差。因此除了计算方法上的应用以外,将问答库中数据进行分类,设计知识库中近义词库,进行必要的转换,并进行问题的结构化处理,也是提高系统效率和准确率的方法之一。
【参考文献】
[1]文勖.中文问答系统中问题分类及答案候选句抽取的研究[D].哈尔滨:哈尔滨工业大学,2006.
[2]黄新,徐小娟.基于ontology的智能答疑系统的研究[J].科学技术与工程,2007,7(12):3001-3003.
[3]张江涛,杜永萍.基于语义链的检索在QA系统中的应用[J].计算机科学,2013,40(2):257-260,300
[4]张华平,刘群.基于N-最短路径方法的中文词语粗分模型[J].中文信息学报,2002,16(5):1-7.
[5]苗夺谦,卫志华.中文文本信息处理的原理与应用[M].北京:清华大学出版社,2007.
[6]G.Salton,M.E.Lesk.Computer Evaluation of Indexing and Text Processing[J].Journal of the ACM,1968,15(1):8-36.
[7]刘亮亮,林乐宇.基于查询模板的特定领域中文问答系统的研究与实现[J].江苏科技大学学报(自然科学版),2011,25(2):163-168.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
中国新闻周刊(2021年26期)2021-07-27 04:02:12
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
中国交通信息化(2018年5期)2018-08-21 03:37:40
自动化学报(2017年7期)2017-04-18 13:41:02
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
