
基于用户用电量的时间序列
2019-09-09 08:14黄文思陆鑫薛迎卫
数码世界 2019年5期
黄文思 陆鑫 薛迎卫


摘要:合理线损预测是实现线损精益化管理的前提。准确的电力线损预测可以保证电力供应的稳定,降低用电成本,提高供电质量。本文通过对国内线损管理的研究现状以及现有线损计算方式的介绍和分析,考虑到配电网的网架结构特点和线损数据的时间相关性,将神经网络与时间序列预测模型相结合,在Spark上使用时间序列神经网络算法建立模型对售电量进行短期预测,使用某省电力公司线损数据进行模拟仿真,结果表明基于BP神经网络的时间序列预测模型可以有效地进行同期线损预测,对线损率预测具有决策性意义。
关键词:线损预测 BP神经网络 时间序列
前言
智能电网的发展给线损治理带来了新的机遇和挑战。在智能电表覆盖率完备的地区,智能电表采集数据计算同期线损,使以往复杂的配網线损计算变得简单明了。但受我国智能电网建设相对这一因素的影响,供电公司还普遍存在着智能电表等智能设备使用不全面的情况,使得统计电量工作大多需要人工完成,在很大程度上增加了统计电量的缺失率,继而导致了线损汇总数据不够精确,影响线损数据的适用范围和四分线损达标率。而随着信息技术的不断完善和大数据技术日趋成熟,为实现了运用历史数据和运营数据预测线损数据提供了有效的支持。本研究分析了现有的线损计算及预测方法,在此基础上结合当前智能电网的特点和发展提出了一种新型适用于配网环境的线损预测方法。
一、基于用户用电量的时间序列一神经网络线损预测模型
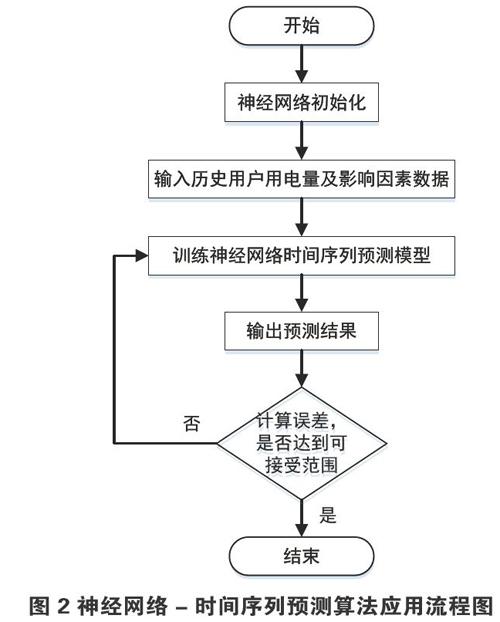
由于售电量具有明显的不确定性、复杂性、以及多方案性等特征,使得我们在对售电量进行预测时,需要综合考虑多种因素,常常面临着预测不准确的现。就目前而言,用于预测售电量的方法多为根据历史售电量数据的规律预测后分析后期售电量,根本不能全买考虑影响售电量的所有因素,使得其可操作性和实用性都处于一种相对较低的水平。针对上述问题,文章通过将时间序列算法与神经网络模型相结合的方式预测售电量,运用时间序列典型分解方法确定样本售电量序列中存在的趋势成分、周期性成分,并把售电量的主要影响因素作为BP神经网络输入,并通过所预测的电量计算线损率,最终实现对异常线损进行修复。为充分考虑售电量的多种影响因素,提高售电量预测精度,本文把BP神经网络和时间序列相结合来进行售电量预测,图1为本文建立的BP神经网络 时间序列的售电量训练模型:
(5)阈值更新。我们可以根据网络输出与期望输出两者的关系,预测出售电量,具体情况如下图2所示:
该模型在对样本数据实行多次模拟训练后,建立了以每日温度、每日类型、历史售电量以及预测电量等数据之间的对应关系,从而准确预测出售电量,可将其计算公式表示为:
Pl=PSu PSa
(2-5)
其中,Pl表示线损电量,PSu表示供电量,PSa表示售电量。从该公式(25)中我们可以得出在知道当日供电量之后,我们可以通过预测日供电量的方式,计算出日线损电量,通过BP神经网络 时间序列模型预测售电量后,可得到线损电量P1,结合线损率计算公式(2-6),就可以计算出某一区域的日线损率Lr。
Lr=PI/PSu
(2-6)
二、基于大数据平台的新型预测算法
大数据平台的建立,为业务系统大数据的开发、运用以及运行奠定了坚实的基础,主要包含数据整合、数据储存、数据计算、数据分析、平台服务安全管理以及配置管理等模块能提供各种业务应用的服务。当前,我们主要运用大数据平台的数据存储、数据计算、数据分析以及安全模块等木块开展线损预测,下面对其进行分别介绍[2]。其中数据存储的主要作用是对大数据进行存储,用海量、规模的数据满足计算需求。通常情况下,非结构化数据主要存储在分布式的文件系统中,半结构化数据主要储存在列式数据库或键值数据库中,结构化数据主要储存于行式储存数据库中具有极高的实时性全面性以及准确性。数据计算指的是运用多样化的大数据进行流计算、批量计算、内存计算以及查询计算,同时还可以计算分布式存储数据和内存数据,从而满足实时决策、预警等等需求。数据分析指的是对多样化数据进行加工、处理、分析以及挖掘的功能,为获取新的业务价值、制定正确的对发展规划提供可靠的参考依据。而安全管理则是指确保大数据环境下采集、储存、分析以及应用数据所涉及的身份验证、授权以及输入验证等环节安全的过程。例如,在对数据进行分析和挖掘时,常常会涉及到企业相关业务的核心数据,如果缺乏安全管理,就会有可能出现数据泄露,而控制访问权限等安全措施在大数据应用中尤为关键。
(一)spark平台
Spark平台与Hadoop相比,有着较高的准确性、安全性以及全面性,是目前大规模处理分布式数据的最有效平台。在传统的Hadoop框架中,需要对数据进行大量的磁盘I/O后才能进行信息处理,在进行信息处理过程中需要对数据进行大量的磁盘,运行效率相对较低,而基于内存的分布式计算框架Spark平台,则有效的解决了频繁的磁盘I/O问题。这主要是由于Spark平台可以实现计算节点将中间结果缓存与内存中,避免了反复迭代等高密度计算过程中的磁盘频繁I/O操作。Spark主要囊括了分布式文件系统、弹性分布式数据集以及容错机制等几个模块。
1.分布式文件系统
Spark平台继续使用了分布式文件系统HDFS,在极大程度上简化了数据的储存流程,使其可以进行大规模的数据处理,此外,HDFS系统中还使用了高容错性策略:首先,数据复写机制可以将同一份数据在不同的节点上产生副本,及时某一个节点发生故障,我们依然可以存取其他节点的数据。其次通过心跳机制检测节点的可用性。HDFS系统只有一个主节点(namenode)和多个从节点(datanode),主节点的作用是管理HDFS文件系统命名空间,而从节点的作用则是将数据以块为单位进行存储,并周期性的将心跳包发送给主节点,如果主节点不能获取集群上从节点的心跳包,则介意判断该节点已经思想,放弃对其进行I/O操作。
2.弹性分布式数据集(RDD)
在存储方面,Spark平台运用了以分布式共享内存为基础的弹性分布式数据集(Resilient Distributed Datasets,RDD)作为数据结构,同时兼容HDFS系统,可将HDFS系统中存在的海量数据作为数据源,并加载至RDD中进行数据处理同时,它还可以在内存中对必要的数据进行容错缓存,为高性能的迭代计算提供依据。在计算模型方面,Spark平臺有着更高的灵活性和更加丰富的操作符、操作符间的组合方式。RDD是一种分布式弹性数据集,将数据分布存储在不同节点的计算机内存中进行存储和处理。每次RDD处理数据的结果都会被存放在不同的节点中,在需要进行下一步数据处理时,可实现从内存中直接提取数据,从而省去了大量的I/O操作,这对于传统的MapReduce操作来说,更便于使用迭代运算提升效率。
3.Spark平台的容错机制
Spark平台有着极高的容错性,这主要是由于在只读权限的RDD数据结构中,当数据集的某一分片丢失时,Spark平台就会对原始的RDD提出新的申请,运用transformation操作对分片信息进行重新计算,lineage机制的主要作用是保存和记录RDD与transformation之间的操作,并把集中式元数据存储于主节点中,lineage机智的存在,可以实现对RDD数据的重新计算,并且只读权限的RDD还能够确保当需要重新执行lineage中已被执行过的某个操作,可以获得相同的计算结果。
(二)新型预测算法在大数据平台中的应用
基于spark的BP神经网络并行化方法,通过采用spark并行编程对BP神经网络的权值进行全局进化迅游,经过一定次数的迭代后,得到优化的神经网络初始权值,在使用并行的BP神经网络算法进行迭代,最终输出网络结构。在训练过程中,各个阶段均能进行多节点的并行处理,有效增强了BP神经网络的收敛速度,在提升训练质量和训练效率等方面均起到了至关重要的作用。
三、结束语
综上所述,基于用户用电量的时间序列 神经网络线损预测模型有着极高的准确性和实用性,能够有效地帮助我们判断实际线损是否存在异常,且能准确定位线损异常的原因和位置,是目前提升电网安全性和稳定的有效预测模型。与此同时,在同期线损数据急剧增加这一背景,我们还可以通过将该模型与大数据平台相结合的方式,在sIJark上使用时间序列神经网络算法对售电量进行并行预测,可保证数据的存储空间和运算效率。从预测结果可知,该模型对售电量预测精度较高,对线损率预测具有决策性意义。
参考文献
[1]刘晶,朱锋峰,林辉,等.基于相似日负荷修正算法的短期负荷预测[J].计算机工程与设计.2010.31 (06):1279-1282.
[2]李翔,欧阳森,冯天瑞,等.一种基于用电行业分类的中长期电量预测方法[J].现代电力.2015,32 (06):86-91.
[3]刘耀年,王卫,杨冬峰.基于模糊划分聚类的中长期用电量预测[J].东北电力大学学报.2004,24 (04):3942.
[4]张鑫,韦钢,周敏,等.灰色理论在城市年用电量预测中的应用[J].上海电力学院学报,2002,18 (02):9-12.
[5]张士强,王雯,王健.ARIMA模型在城市年用电量预测中的应用[J].电力需求侧管理.2010,12 《06):31-34.
猜你喜欢
现代经济信息(2016年27期)2016-12-16
时代金融(2016年27期)2016-11-25
电脑知识与技术(2016年26期)2016-11-25
商(2016年32期)2016-11-24
价值工程(2016年30期)2016-11-24
数字技术与应用(2016年9期)2016-11-09
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
科技视界(2016年20期)2016-09-29
企业导报(2016年8期)2016-05-31
