
基于Bi-LSTM-CRF模型的维吾尔语词干提取的研究
2019-09-05 12:33:36古丽尼格尔阿不都外力吐尔根依布拉音卡哈尔江阿比的热西提王路路
中文信息学报 2019年8期
古丽尼格尔·阿不都外力,吐尔根·依布拉音,卡哈尔江·阿比的热西提,王路路
(1. 新疆大学 信息科学与工程学院,新疆 乌鲁木齐830046;2. 新疆大学 新疆多语种信息技术实验室,新疆 乌鲁木齐 830046)
0 引言
维吾尔语是典型的形态丰富的黏着语。黏着语种的单词由词干和词缀组成,词干主要表达词的意义,而词缀提供语法信息(所属性,形态,复数)。作为维吾尔语自然语言处理中的基础性研究,词干提取的质量会直接影响维吾尔语言处理的其他任务,如词性标注、命名实体识别等[1]。除此之外,维吾尔语中词干与词缀相连接时,连接处由于结合的不规则性,会发生一系列的音系现象[2],这种音系现象对词干提取带来了一定的困难。
维吾尔语自然语言处理技术还处于发展初期[3],目前维吾尔语中的词干提取大致可以分成基于词典/规则的方法[4]、基于统计的方法[5]和基于神经网络的方法[6]。基于词典/规则的方法工作量较大,需要语言学家制定语言学规则并构造限制条件。这种方法虽然结果更加准确,但需要大量的语言学知识,受词干提取词典大小的限制,而且语言学规则只适用于常规词形变换,缺乏全面性。基于统计的方法是通过词的分布统计规律进行词干提取,能较好地处理OOV现象和一般构词规律构成的词形。基于统计学习的维吾尔语词干提取研究虽然有了初步的成果,但需要人工选择和提取特征,而且还存在着过度切分、不切分和歧义切分等问题。基于神经网络的方法是一种特征学习的过程,通过后向传播算法学习出最适合维吾尔语词干提取模型的参数。此方法通过自动学习数据中的特征表示来缓解人工选择和提取特征的过程中成本较大的问题,但仍然存在过度切分、不切分和歧义切分的问题。
为了解决以上问题,本文提出了基于Bi-LSTM-CRF神经网络的维吾尔语词干提取方法。该方法将采用BIO2标记,引入字符特征、音类特征以及语音特征作为候选特征。为了进一步证明模型的有效性,本文将分两组做实验对比:
(1) 将Bi-LSTM-CRF模型应用到维吾尔语词干提取上,并与CRF、LSTM、Bi-LSTM、LSTM-CRF模型做实验对比,验证Bi-LSTM-CRF模型能有效地解决词干提取时出现的过度切分、不切分和歧义切分等情况;
(2) 引入不同的候选特征,验证当逐步加入字符特征、音类特征以及部分语音特征组时,特征集对维吾尔语词干提取质量的影响。
1 相关工作
1.1 词干提取

除了维吾尔语,国内少数民族语言中属于黏着语的还有蒙古语、哈萨克语等。由于国内少数民族语言的词干提取技术发展得比较晚,因此基于词典/规则相结合的方法比较多。史建国等[7]利用词典和规则的方法对蒙古文进行词切分,得到了性能较好的斯拉夫蒙古文词切分系统;李婧等[8]采用基于规则、字典查找和最大匹配相结合的方法对哈萨克语进行词干提取,并提出了结合哈萨克语元音和谐规律、词干词性和词尾缀接顺序切分词尾的方法,使得词干提取正确率达95.26%;早克热·卡德尔等[9]首先构造了名词的有限状态自动机,并用最大熵模型给有限状态自动机加入了歧义词缀识别能力,建立了基于规则和信道噪声模型的元音和谐处理方法。随着统计学习模型在自然语言处理领域中的广泛应用,词干提取也从传统的方法逐步过渡到了统计的方法。赛迪亚古丽·艾尼瓦尔等[5]以N-gram为基准模型,根据维吾尔语构词规律,提出了融合词性特征和上下文词干信息的维吾尔语词干提取模型,由于语料库规模较小,模型依赖于上下文特征和词性特征,而且可能存在一些重复单词等原因,当语料库规模逐渐增大时,模型准确率提升较缓慢;那日松等[10]设计了两组对比实验,将蒙古文的分词问题转化为序列标注问题,使用了四词位标注集,利用CRF模型,以上下文词形和蒙古文连写的构形附加成分作为特征,实验结果表明,上下文作为特征的实验组比附加成分作为特征的实验组效果更好;李文等[11]将维吾尔语和蒙古语作为研究对象,介绍了基于最大后验概率模型非监督式形态切分方法,在非监督式切分的基础上,通过加入调参的方式,使模型更适用于特定的语言。实验结果表明,虽然切分的准确性提高了,但此方法只适合用于特定的语言,而且也有过渡切分的问题;姜文斌等[12]将维吾尔词语的层次结构引入到词法分析研究中,提出了维吾尔词法分析的有向图模型,对于音系现象又提出了基于词内字母对齐算法的自动还原模型,其词干提取的正确率达到了94.70%,但由于只根据从训练集中自动抽取的词干表和词缀作为当前切分词的递归穷举可能的候选结构,因此导致过多的候选,而且只限制于词干库表和词缀库表;哈里旦木·阿布都克里木等[6]提出了基于语素序列的维吾尔语形态切分方法,将单词切分成若干个语素(词根和词缀),从而缓解了数据稀疏问题。
1.2 CRF模型
条件随机场(Conditional Random Field,CRF)[13]是一种无向图模型,近年来已经广泛应用到其他自然语言处理任务中,如分词、词性标注、命名实体识别等。其结合了最大熵(MEM)和隐马尔可夫(HMM)的特点,通过考虑上下文中标签之间的相关性来防止HMM和MEM中的有限特征选择。除此之外,CRF可以通过全局特征归一化的过程获得全局最优,CRF链式结果如图1所示。
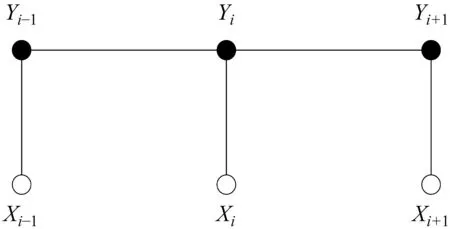
图1 CRF链式结构
现给定可观察序列W=w1w2…wn,与之相应的标记序列为Y=y1y2…yn,则条件概率定义如式(1)所示。
(1)
其中,fk为特征函数,λk为参数,Z(W)为规一化因子,使给定所有可能状态序列的概率之和为1。而观察序列需要搜索概率最大的Y*=arg maxp(Y|W)。
1.3 LSTM模型
循环神经网络(Recurrent Neural Network,RNN),是一种通过隐藏层节点周期性的连接来获得序列化数据中动态信息的神经网络,可以对序列化的数据进行分类。但是,RNN对长跨度时间可能会有梯度消失或爆炸的问题。为了解决长距离依赖的问题,Hochreiter S等[14]提出了一种改进的循环神经网络——长短时记忆网络(Long Short Term Memory Network,LSTM),LSTM可以选择性忘记历史信息以及更新存储的信息,这将有效地解决RNN的梯度消失或爆炸问题,LSTM网络结构如图2所示。
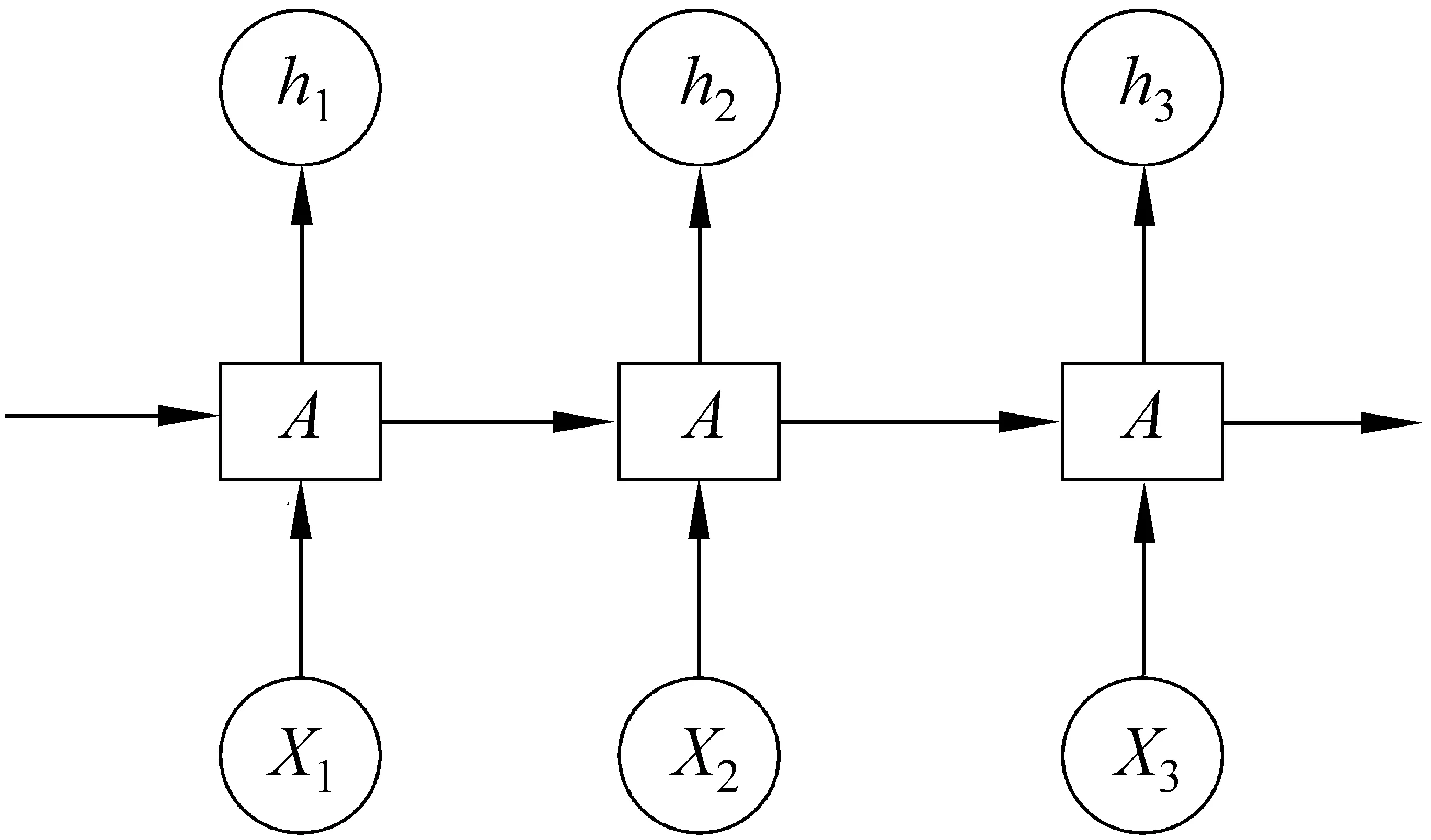
图2 LSTM网络结构
LSTM单元由三个门(遗忘门、输入门、输出门)和一个细胞状态组成,其结构如图3所示。
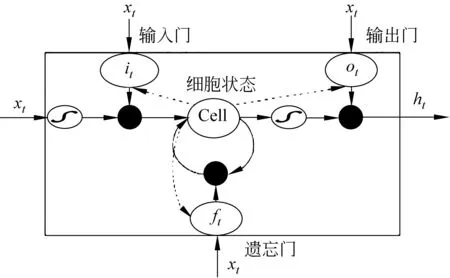
图3 LSTM单元模型结构
遗忘门决定历史细胞状态的保留信息,这由sigmoid函数来控制,它会根据上一时刻的输出和当前的输入来产生一个0~1的ft值,来决定上一时刻学到的信息是否通过以及通过多少,计算如式(2)所示。
ft=σ(Wf·[ht-1,xt]+bf)
(2)
输入门控制将新的信息中哪些部分保存到细胞状态中,首先用sigmoid函数来决定哪些值用来更新,而用tanh函数来生成新的后选值,并将这两部分生成的值进行结合并更新,计算如式(3)~式(5)所示。
决定输出门控制全部更新后的细胞状态中哪些部分被输出,首先通过sigmoid函数得到初始的输出,之后用tanh函数将Ct值映射到-1到1的区间,再通过初始输出值逐对相乘,最终得到输出,计算如式(6)、式(7)所示。
2 基于Bi-LSTM-CRF的维吾尔文词干提取
2.1 Bi-LSTM-CRF模型
Bi-LSTM-CRF模型[15]是由Bi-LSTM和CRF模型结合的模型,从Bi-LSTM输出的向量作为CRF模型的输入值,Bi-LSTM-CRF模型不仅能保留Bi-LSTM上下文信息,而且能通过CRF层考虑前后的标签信息。Bi-LSTM-CRF网络结构如图4所示。
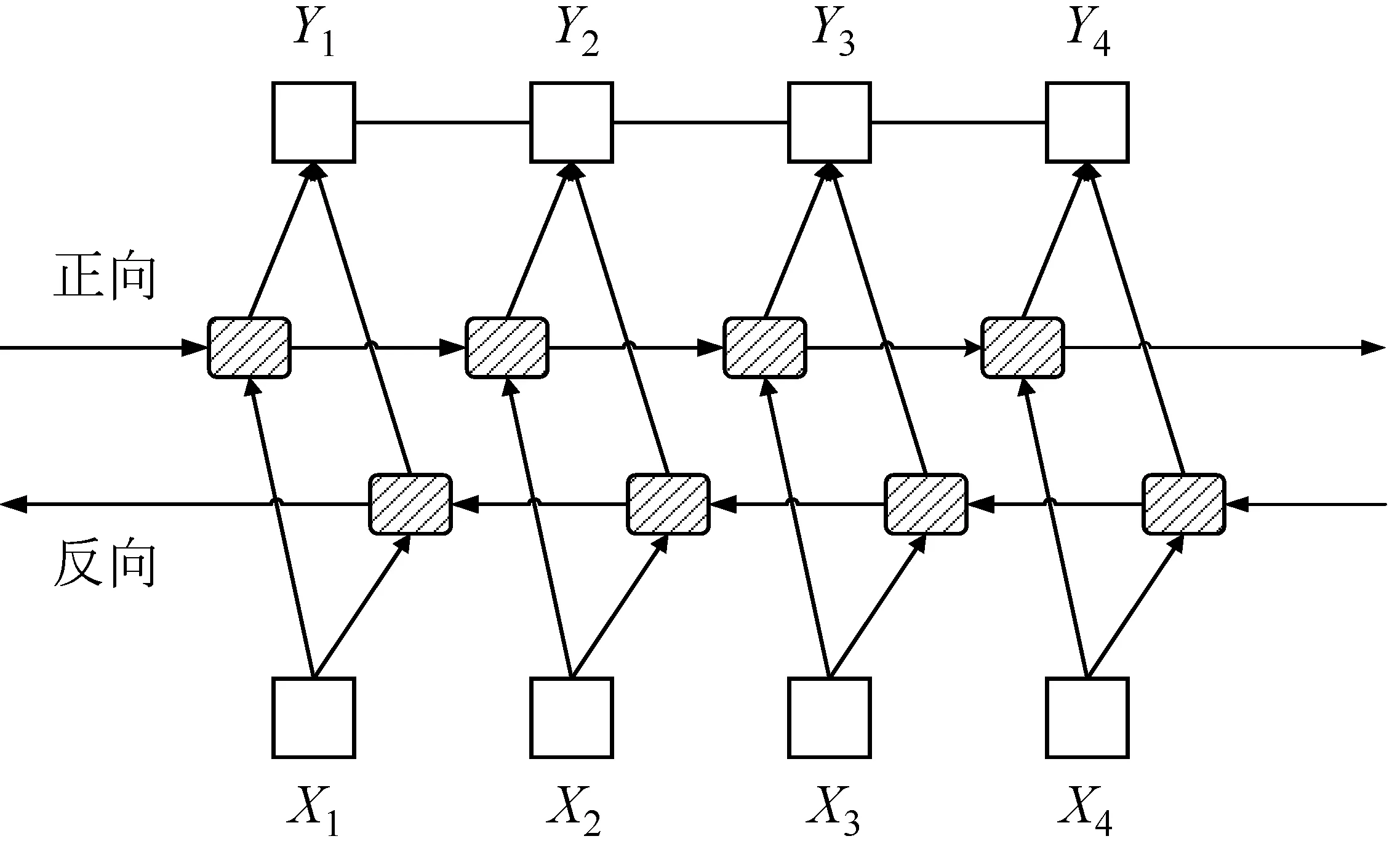
图4 Bi-LSTM-CRF网络结构图
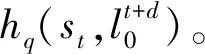
(8)
维吾尔语中词干和词缀拼接时,一般在词干或词缀中会出现音系现象(弱化、增音、脱落等),这将严重影响切分准确度,也成为了维吾尔语词干提取过程中的难点。由图5我们可以发现,Bi-LSTM-CRF模型克服了LSTM模型只记录上文信息、不考虑下文信息的缺点,将通过Bi-LSTM得到的两个隐藏层单元输出结果进行拼接,作为整体网络隐藏层输出,并将其输出结果输入到CRF层里,将维吾尔语词干提取转变成序列标注的过程。
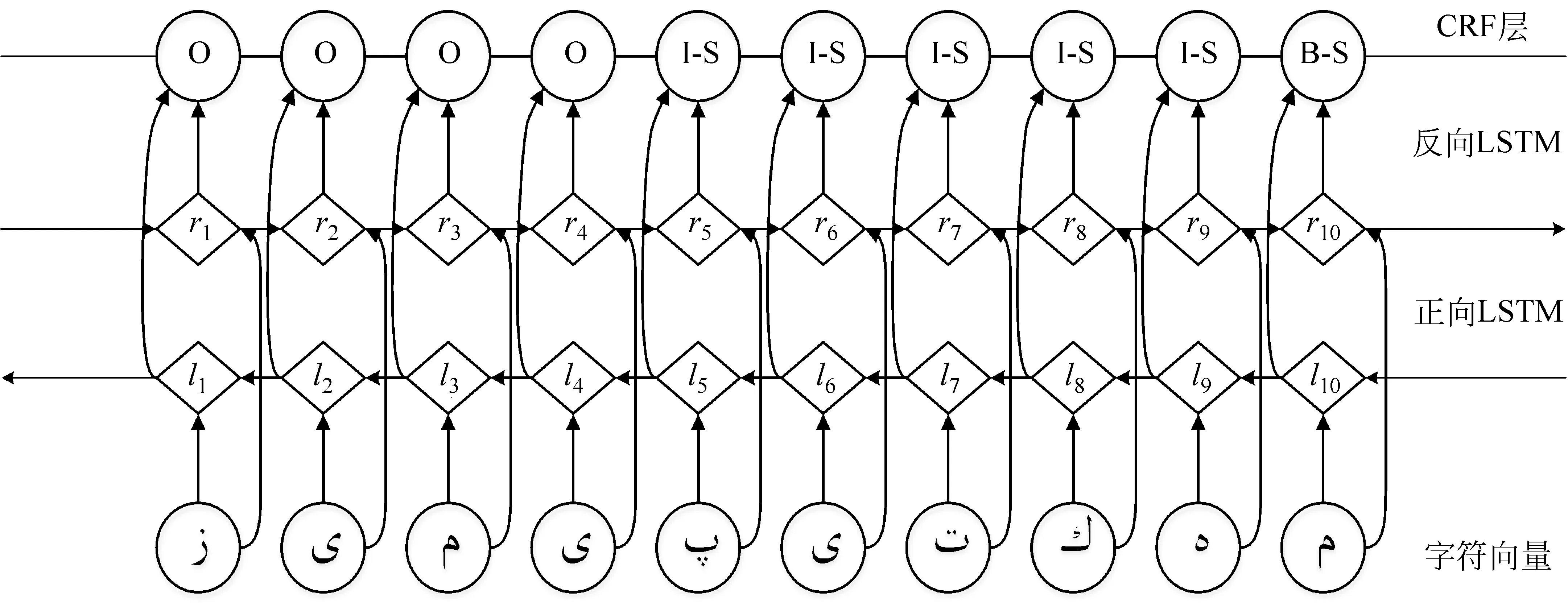
图5 基于Bi-LSTM-CRF模型的维吾尔语词干提取结构
2.2 特征选择与标记集
本文中我们考虑几种候选特征作为特征集合,确定哪一个特征对词干提取有较为显著的影响,选取候选特征时,我们参考了文献[16]提出的特征,分别为当前字符的字符特征C(字符本身)、音类特征S(当前字符为元音,则特征为V;当前字符为辅音,则特征为C)和语音特征P1、P2、P3(当前音类为元音时,则根据元音发音时横向舌位、纵向舌位和展圆情况进行分类;当前音类为辅音时,则根据发音时声带的振动情况、发音部位和发音方式进行分类)。

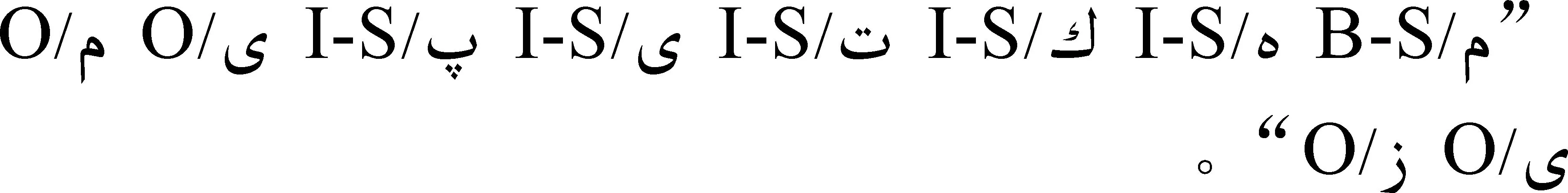
通过这种表示方法,将单词根据标注语料映射成由独立标记组成的功能块,即可将词干提取任务转换成序列标注问题。
3 实验数据与结果分析
3.1 实验数据
目前为止,由于维吾尔语词干提取公开的标注数据集或语料库还未见公开,因此本文将从天山网爬取新闻数据,并进行人工校对和人工提取词干(数据大小: 15万),按词长进行由长到短的排序,并选出其中最长的1万个单词进行预处理,采用交叉验证法对标记语料进行分割产生训练集、测试集和验证集(分割比为0.75∶0.15∶0.1),语料具体统计如表1所示。
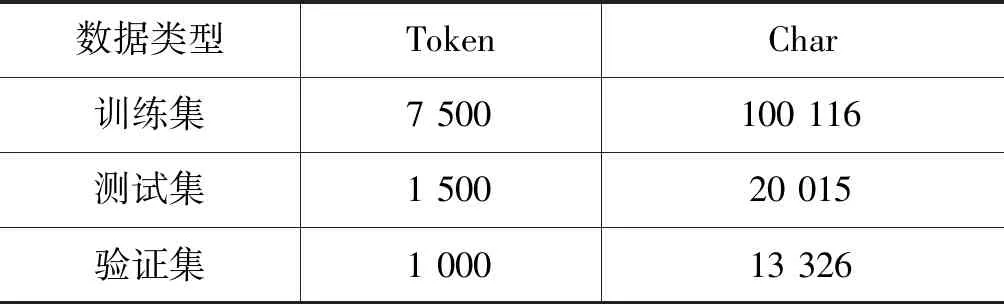
表1 语料统计表
标记集在数据集中的分布统计如图6所示。
LONG Jun-rui, SHAN Chan-juan, YANG Qun-di, LIU Xin-ying, WANG Jiu-sheng, MEI Chang-lin, XIONG Lin-ping
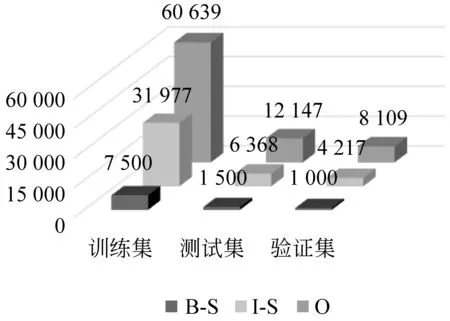
图6 标记集在数据集中的分布
数据集中最长的单词长度、词干长度、词缀长度和最短的单词长度、词干长度、词缀长度(由于数据是基于词的,因此只考虑了字符特征)如表2所示。
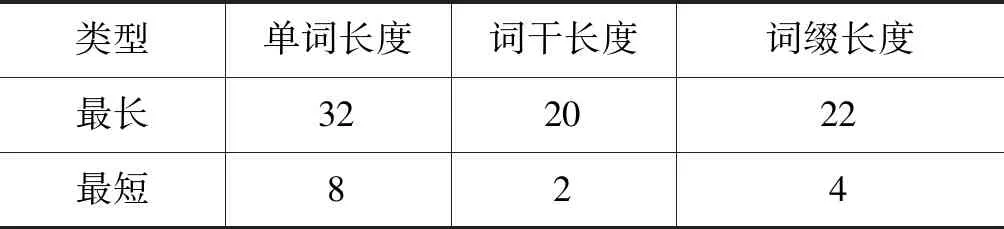
表2 单词、词干、词缀长度
数据集有以下特点:
① 包含的单词、词干和词缀长度比较长;
② 包含较多的外来词、不规则词;
③ 以字符(维吾尔文字母)作为最小的分割单位;
④ 由无重复的维吾尔语单词构成,没有上下文语言环境。
3.2 实验设计与结果分析
为了进一步验证模型和特征对词干提取的影响,在本节中分别设计不同模型、特征的对比实验,寻找最适合词干提取的模型和特征,确定最佳的提取效果。在实验过程中,将使用F值(F1)作为评测指标,衡量词干提取效果。
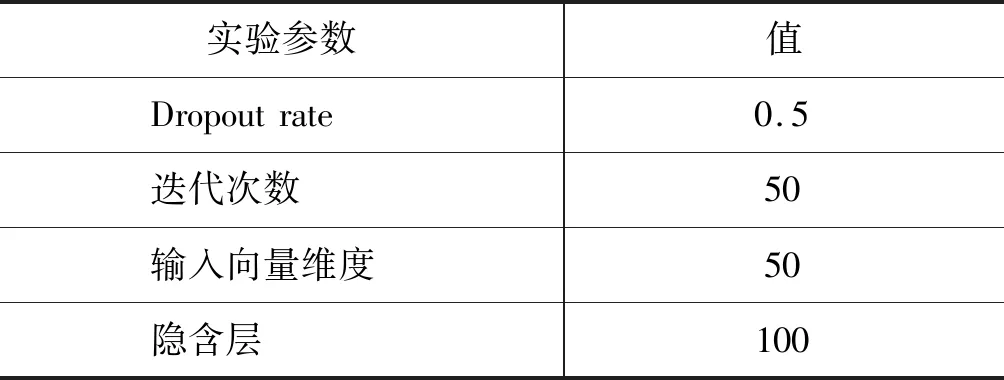
表3 神经网络超参数
3.2.1 不同模型的对比实验
本组实验中,将对CRF、LSTM、Bi-LSTM、LSTM-CRF和Bi-LSTM-CRF等模型分别做实验对比,其实验结果如表4所示。
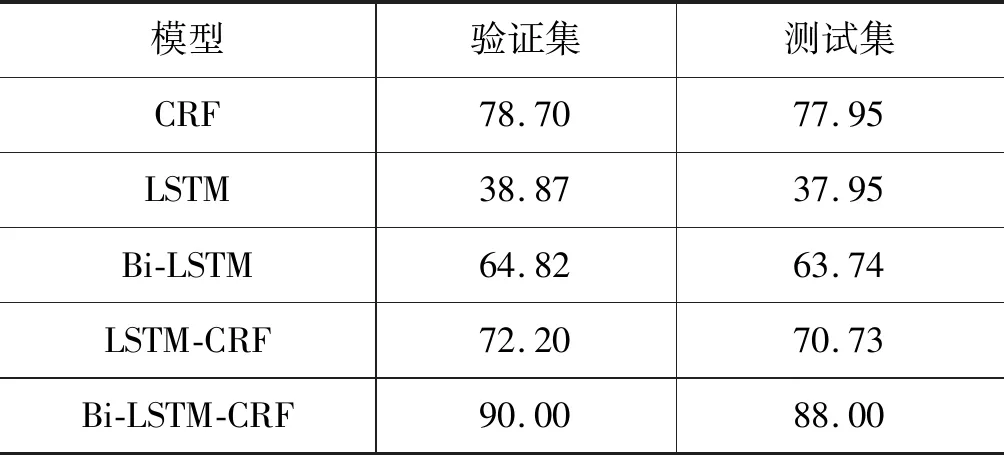
表4 实验结果(%)
(1) 从表中可见,Bi-LSTM-CRF模型的词干提取明显高于CRF、LSTM、Bi-LSTM和LSTM-CRF模型,F值分别提升了10.05、50.05、24.26、17.27个点。实验结果说明,Bi-LSTM-CRF模型比其他模型更加准确地识别了词干和词缀,而且也正确地切分了词干和词缀。
(2) LSTM-CRF模型和Bi-LSTM-CRF模型的识别效果都高于LSTM和Bi-LSTM,而且CRF模型也高于LSTM模型和Bi-LSTM,其实验结果说明,采用序列标注方法对维吾尔语进行词干提取时,对提取结果是有一定的帮助的。
(3) LSTM模型和LSTM-CRF模型分别低于Bi-LSTM模型和Bi-LSTM-CRF模型,其原因可能是通过双向的LSTM模型有效地考虑了上下文信息,并且对于单向的LSTM模型,双向的具有一定的互补性,因此对形态复杂的维吾尔语进行词干提取时,双向的神经网络明显优越于单向的神经网络。
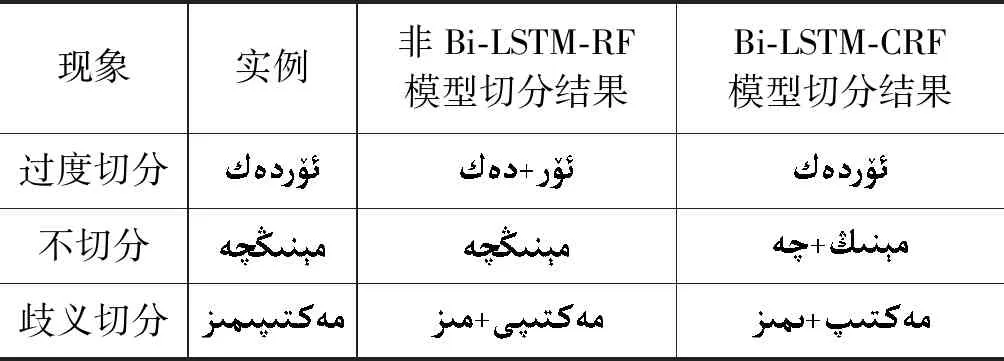
表5 维吾尔词干提取实例分析
3.2.2 不同特征的对比实验
在对比实验(1)的基础上将对CRF模型和Bi-LSTM-CRF模型引入手工提取的特征,如字符特征(C)、音类特征(S)、语音特征(P1,P2,P3)等(候选特征的输入维度为30),实验结果如表6所示。
(1) 当Bi-LSTM-CRF模型不加候选特征的F值比CRF模型加特征的F值提高了8.2个点,说明不加特征的Bi-LSTM-CRF模型词干提取的效果比加候选特征的CRF模型更好。
(2) 当输入所有候选特征、模型不同时,Bi-LSTM-CRF模型与CRF模型相比F值提升了9.33个点。
(3) 当模型相同、输入候选特征不同时,与不加特征的Bi-LSTM-CRF模型相比,F值分别提升了1.47、0.93、0.6和1.8个点,实验结果说明,通过神经网络模型进一步提高词干提取性能时,可以考虑加入候选特征。
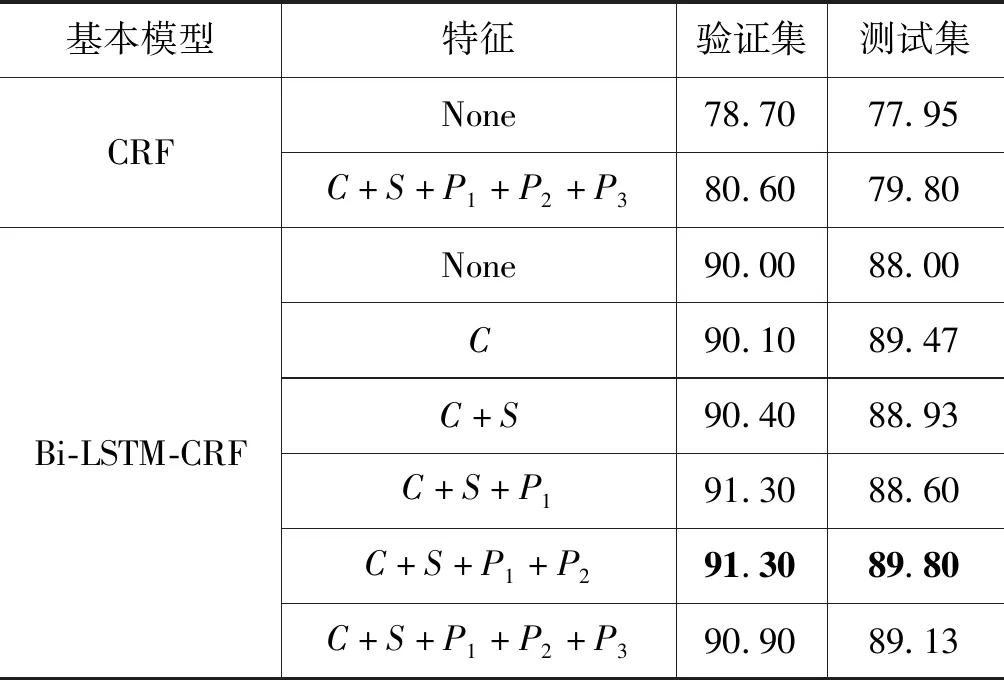
表6 实验结果(%)
(4) 有些候选特征对词干提取影响不同,例如,特征C+S+P1+P2组合时,其F值最高,提升了1.8个点,但当所有特征组合在一起时,其F值没有比特征组C+S+P1+P2提升的高。(网络模型参数参考表3)。
除此之外,通过分析实验结果发现以下两种情况对实验结果的准确率有较大的影响:

以上情况可能是由于在构建语料库中没有考虑词性特征或上下文语言环境所造成的。
4 结论
本文将维吾尔语词干提取看成序列标注问题,以字符为切分粒度来表征维吾尔语的构成机制,采用CRF、LSTM、Bi-LSTM、LSTM-CRF及Bi-LSTM-CRF模型对比维吾尔语词干提取效果和处理过度切分、不切分和歧义切分的能力,并在此基础上分析维吾尔语字符特点,引入字符特征、音类特征以及语音特征,对比几个特征组对维吾尔语词干提取影响。本文采用的基于Bi-LSTM-CRF模型在维吾尔语词干提取上的取得了较好的效果。实验结果表明:①Bi-LSTM-CRF模型能比较准确地识别维吾尔语中词干和词缀,有效缓解过度切分、不切分和歧义切分等现象; ②本文引入的候选特征对维吾尔语的词干提取是有效的,其特征集中特征组字符特征(C)、音类特征(S)以及部分语音特征(P1和P2)的提取效果最佳。
本文还有一些局限性,比如没有研究词干与词缀连接时所出现的音系现象或词干提取时还原原词干(由于音系现象,词干中的一些字母会发生变化)等问题。故在以后的研究中,考虑更多特征因素,通过改进模型来提高维吾尔语词干提取的效果。
猜你喜欢
红河学院学报(2021年4期)2021-11-19 08:59:14
现代职业教育·高职高专(2020年22期)2020-03-24 22:46:34
中文信息学报(2018年11期)2018-12-20 06:08:44
西夏研究(2017年1期)2017-07-10 08:16:55
自动化学报(2017年4期)2017-06-15 20:28:55
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12 01:16:14
语言与翻译(2015年4期)2015-07-18 11:07:45
中文信息学报(2015年5期)2015-04-21 10:41:55
中文信息学报(2015年3期)2015-04-21 08:33:49
语言与翻译(2014年3期)2014-07-12 10:32:09
