
基于置信度的藏文人名识别的主动学习模型研究
2019-09-05 12:33:36王志娟刘飞飞赵小兵
中文信息学报 2019年8期
王志娟,刘飞飞,赵小兵,宋 伟
(1. 中央民族大学 信息工程学院,北京 100081;2. 国家语言资源监测与研究少数民族语言中心,北京 100081;3. 好未来教育科技集团,北京 100080)
0 引言
命名实体识别(named entity recognition, NER)作为信息抽取的子任务,是自然语言处理任务的基础环节,是信息检索、知识图谱等研究的基础。经过多年发展,命名实体识别研究覆盖了英语、汉语、印地语、阿拉伯语、日语、西班牙语等多种语言。
命名实体识别的主要方法有规则、机器学习和深度学习三类[1-2]。根据标注语料的规模,机器学习又可以分为监督式机器学习(训练语料全部标注)、半监督式机器学习(训练语料部分标注)和无监督式机器学习(无标注语料)三种,其中,基于大规模标注语料的监督式学习方法的命名实体识别性能优于半监督和无监督方法,是常用的命名实体识别方法。

主动学习是机器学习的一个子领域,其主要工作是有针对性地选择一些信息量大的语料进行人工标注,进而通过较少的标注语料实现较好的模型学习效果,从而最大限度地降低语料标注成本[3-4]。目前主动学习方法已经成功应用于许多自然语言处理任务,例如,文本分类[5]、词性标记[6]、词义消歧[7]、自动翻译[8]、命名实体识别[9-12]等。
本文提出了一种基于置信度的藏文人名识别的主动学习模型,该模型用约33%的人工标注语料就可达到监督式学习模型的藏文人名识别效果。
本文的主要内容安排如下: 首先介绍了藏文人名识别的研究现状、面临的困难以及主动学习的原理,其次介绍了基于置信度的藏文人名识别的主动学习模型,然后是实验部分,最后是结论和展望。
1 相关工作
首先介绍藏文人名的识别研究现状,然后介绍主动学习的原理。
1.1 藏文人名识别现状
早期的藏文命名实体识别的研究主要采用基于规则的方法,Yu等[13]提出利用格助词、边界特征、词典等识别藏文命名实体的方法,Sun等[14]提出基于多特征的藏族人名识别方法,结合藏文人名词典匹配、边界特征、上下文特征、人名高频词等多个特征实现藏文人名的识别。
2014年之后,藏文命名实体的识别方法开始以基于监督式机器学习方法为主。加羊吉等[15]提出了最大熵和条件随机场相融合的藏文人名识别方法;华却才让等[16]提出基于感知机的藏文命名实体识别;康才畯等[17]提出了基于条件随机场的藏文人名识别方法;2017年,珠杰等[18]基于条件随机场以及触发词、虚词、人名词典、人名后缀等特征的不同优化组合实现了藏文人名识别。
目前藏文人名识别研究已经取得了较好的识别效果,不过还存在音译人名及与普通名词同形的藏文人名识别效果不理想的问题[15]。这些问题往往是由于训练语料覆盖面不够所致,而藏文是一种资源稀缺语言,大量语料的标注将需要更高的人力、物力和财力成本,对此本文提出了一种基于置信度的主动学习方法,该方法将选择那些信息量大、无冗余的语料进行人工标注,进而达到降低语料标注成本的目的。
1.2 主动学习原理
主动学习是半监督机器学习的特例,该方法主要用于构造有效训练集,由于训练集中通常包含大量的冗余样本,主动学习方法从大量未标注语料中通过一定的选择策略选择一定数量的语料进行人工标注,从而降低语料标注成本[3]。
主动学习方法可以由以式(1)所示的五个组件进行建模[19]。
A=(C,L,S,Q,U)
(1)
其中,C为分类器,L为已标注的训练语料;S为语料标注人员;Q为选择策略,用于从未标注的语料中选择信息量大的语料供人工标注;U为整个未标注语料。
主动学习方法主要分为两个阶段: 第一阶段为初始化阶段,利用已标注的语料建立一个初始分类器模型;第二阶段为迭代选择阶段,利用第一阶段构建的分离器标注未标注语料U,并按照某种选择策略Q从U中选取一定数量的语料交给标注者S进行标注,然后,将人工标注结果添加到已标注语料L中,重新训练分类器,直至满足停止标准为止[20]。
1.3 主动学习在命名实体识别方面的应用
目前,主动学习方法已被应用于命名实体识别任务中,Shen 等[9]提出了一种基于多特征的主动学习方法,该方法将信息性、代表性、多样性三种特征进行表示量化,通过融合这三种特征的选择策略减少了人工标注成本。实验显示: 在保证识别效果的前提下,该方法可以减少约80%的语料标注量。Yao 等[11]提出了基于信息密度的选择策略,该方法仅利用约1万个标注句子就实现了人工标注约13万句子的效果。
针对藏文人名识别中由于训练语料稀疏导致的识别效果不理想的问题,理论上可以通过增加训练语料规模解决。本文基于不确定主动学习算法,利用条件随机场作为藏文人名识别模型,选择模型标注结果中置信度较低的语料进行人工标注,进而可以在保证识别效果的前提下,大大减少语料的人工标注成本。
2 基于主动学习的藏文人名识别模型
藏文人名识别的主动学习过程,如图1所示。
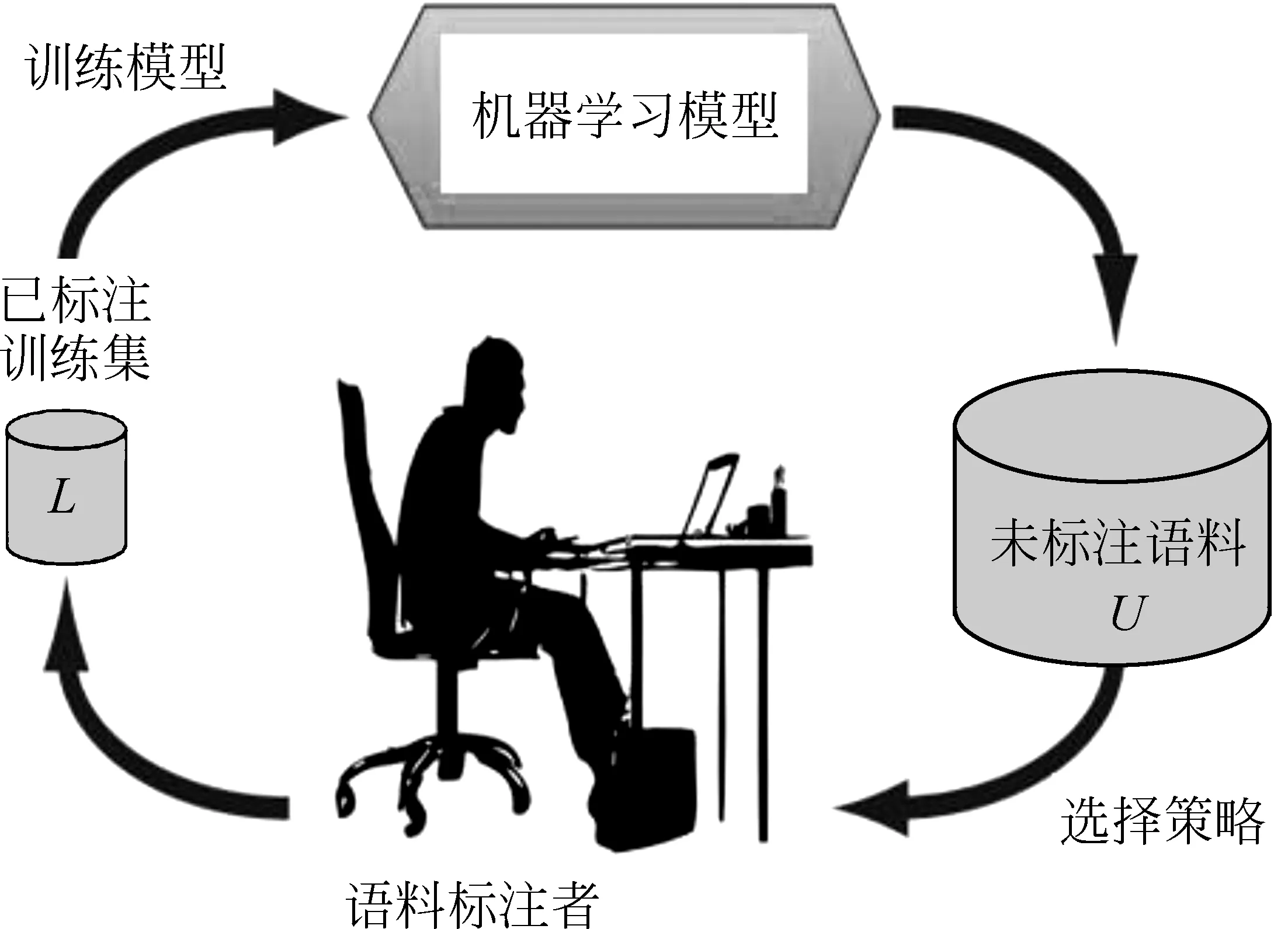
图1 主动学习原理
首先给定少量人工标注语料L和大量未标注语料U。然后按以下步骤训练基于主动学习的藏文人名识别模型。
第一步: 利用人工标注语料L训练一个基于CRF的藏文人名识别模型ML。
第二步: 用ML去标注大量未标注语料。
第三步: 在标注结果中按一定的选择策略选择若干不确定性高、信息量大的语料,交给人工标注。
第四步: 将人工新标注的语料添加到已标注语料L中,同时将其从未标注语料U中删除。
第五步: 判读是否满足主动学习结束条件,若满足,则结束;若不满足,则重复步骤一到五,直到满足主动学习结束条件。
因此,对于基于主动学习的藏文人名识别模型而言,选择策略和停止策略的设计至关重要,下面基于置信度和新旧模型标注结果的差异度分别介绍两种选择策略和两种停止策略。
2.1 基于置信度的选择策略
本文基于CRF模型识别藏文人名,对于给定的输入序列X,其标注结果为Y的条件概率为P(Y|X),该结果的范围为[0,1],0表示对标注结果没有信心,1表示完全确认标注结果[20],如式(2)、式(3)所示。
(2)
(3)
标注结果的置信度计算方法如式(4)所示。
Confidence(X)=P(Y|X)
(4)
本文基于句子的置信度选择需要人工标注的语料,具体选择策略有两种。
(1) 选择策略1
该选择策略的基本思想是每次迭代选择置信度最低的前m个句子进行人工标注,因此每次选择的句子数m是固定的。
(2) 选择策略2
该选择策略的基本思想是每次迭代选择置信度低于某个阈值的n个句子进行人工标注。该方法每次迭代选择的句子数可能不一样,随着迭代次数的增加,每次选择的句子数n会越来越少。
2.2 停止策略
本文提出了两种停止策略。
(1) 停止策略1: 基于置信度的停止策略。
该停止策略的基本思想是当所有待选语料的置信度均高于设定的阈值α时,主动学习停止。
(2) 停止策略2: 基于差异度的停止策略。
该停止策略的基本思想是将新、旧模型标注结果的差异度β作为停止依据,新、旧模型标注结果的差异度越小,说明新、旧模型性能的差异越小,当二者的差异小于一个足够小的数时,主动学习过程结束。
新、旧模型的差异度计算方法如下:
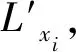
(5)
新旧模型的标注差异度计算如式(6)所示。
(6)
其中,diff(xi)表示第i个音节的标注差异情况,n表示模型标注的音节总数。理论上而言,当新、旧模型的差异度β为0或者小于一个非常小的数时,表示新、旧模型标注结果基本一致,主动学习可以停止。
2.3 基于置信度的主动学习方法
基于以上提出的选择和停止策略,有以下4种主动学习方法。
方法1选择策略1+停止策略1
该主动学习方法每次迭代选择固定数量(m个)的句子供人工标注,直到待选语料的句子置信度均高于设定置信度阈值α1为止。
方法2选择策略1+停止策略2
该主动学习方法每次迭代选择固定数量(m)的句子供人工标注,直到新、旧模型的标注结果的差异度小于设定阈值(β1)为止。
方法3选择策略2+停止策略1
该主动学习方法每次迭代选择置信度低于给定阈值(n)的若干句子供人工标注,直到待选语料的置信度均高于设定阈值α2为止。
方法4选择策略2+停止策略2
该主动学习方法每次迭代选择置信度低于给定阈值(n)的若干个句子供人工标注,直到新、旧模型的标注结果的差异度小于设定阈值(β2)为止。
以上参数均由实验确定。
3 实验
首先介绍实验方案,然后根据实验确定主动学习方法1~4中的各个参数,从标注效果、标注语料量和迭代次数三方面分析这四种主动学习方法的性能,最后比较主动学习方法和监督式学习的效果。
3.1 实验设计
本实验语料来自人民网、藏语广播网、阿坝新闻网的藏语版,语料覆盖新闻、政治、宗教、文化等多个领域,不仅包含大量藏族人名,还包含大量译名。实验语料一共1 500个文本,其中训练语料1 360个文本(人工标注语料100个文本、未标注语料1 260个文本)、测试语料140个文本,语料基本情况如表1所示。
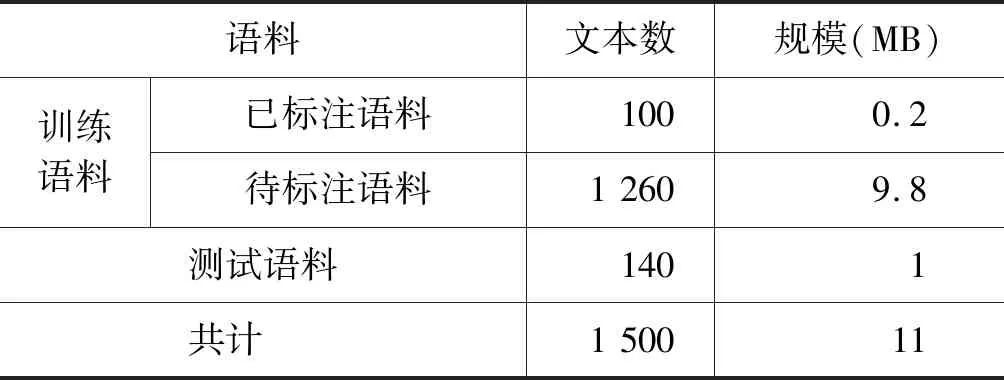
表1 实验语料基本情况
3.2 主动学习方法的参数确定
3.2.1 方法1的参数确定
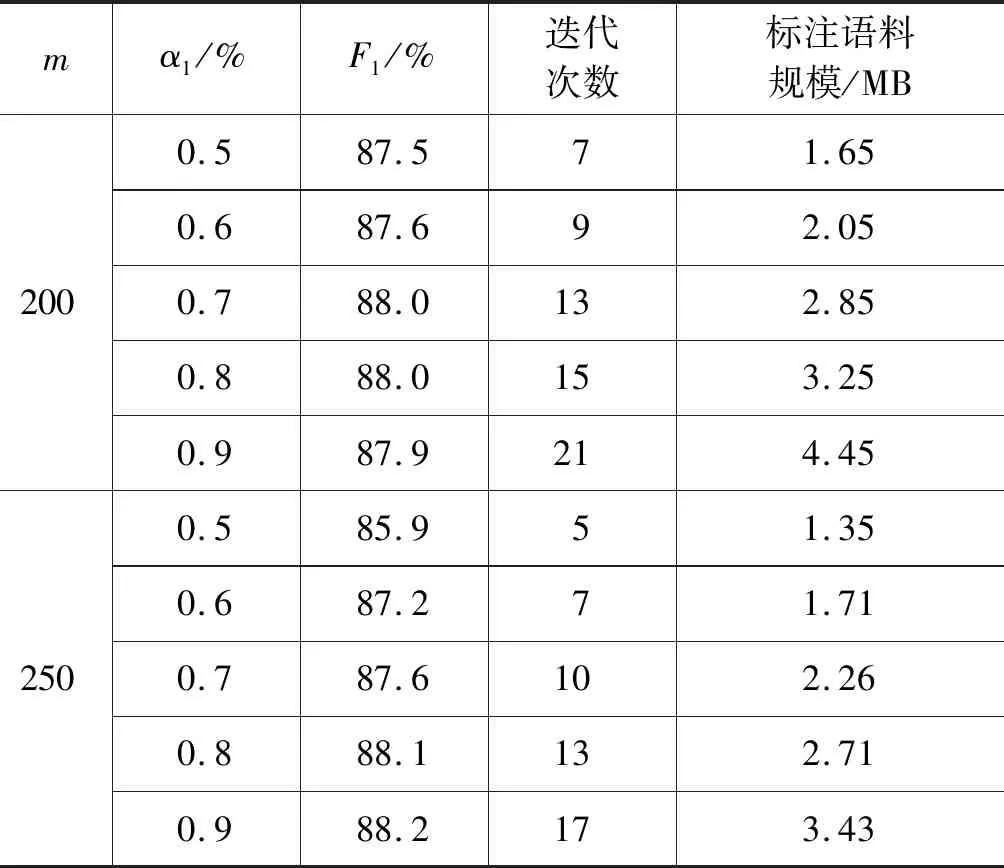
表2所示为当选择策略为每次迭代选择置信度最低的50、100、150、200、250句,停止策略为标注结果的置信度为0.5~0.9时藏文人名识别效果、主动学习迭代次数及语料标注规模。
由表2可见,选择m=50、α1=0.8时,藏文人名识别的F值可达到88.3%,主动学习迭代次数为63次,语料标注规模为2.57 MB。
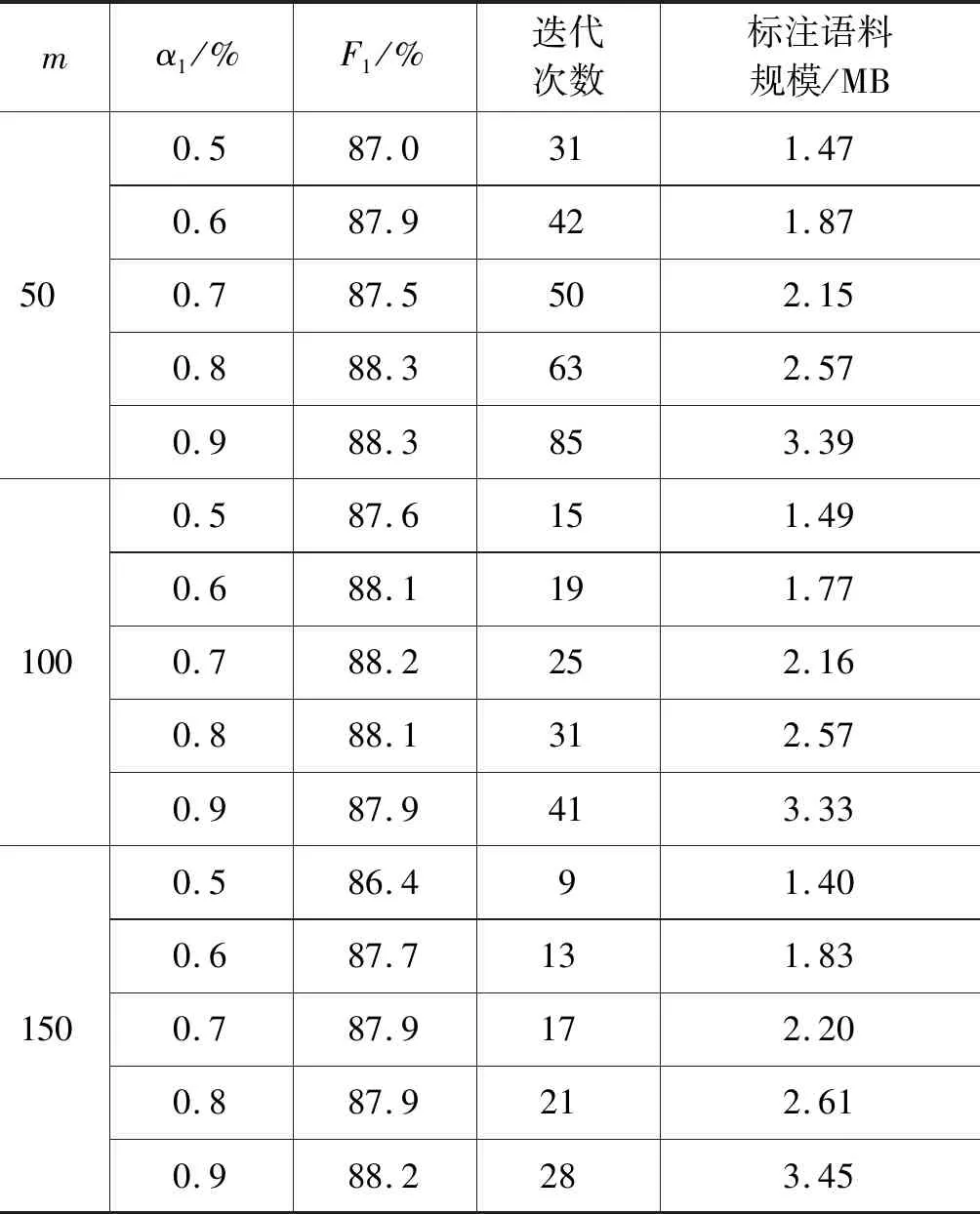
表2 方法1不同参数的藏文人名识别效果
续表
3.2.2 方法2的参数确定
表3所示为当选择策略为每次迭代选择置信度最低的50、100、150、200、250句,停止策略为标注结果的差异度为0.02%、0.01%、0.005%时藏文人名识别效果、主动学习迭代次数及语料标注规模。
由表3可见: 选择m=250、β1=0.01%时,藏文人名识别的F1值可达到88.1%,主动学习迭代次数为13次,语料标注规模为2.71 MB。
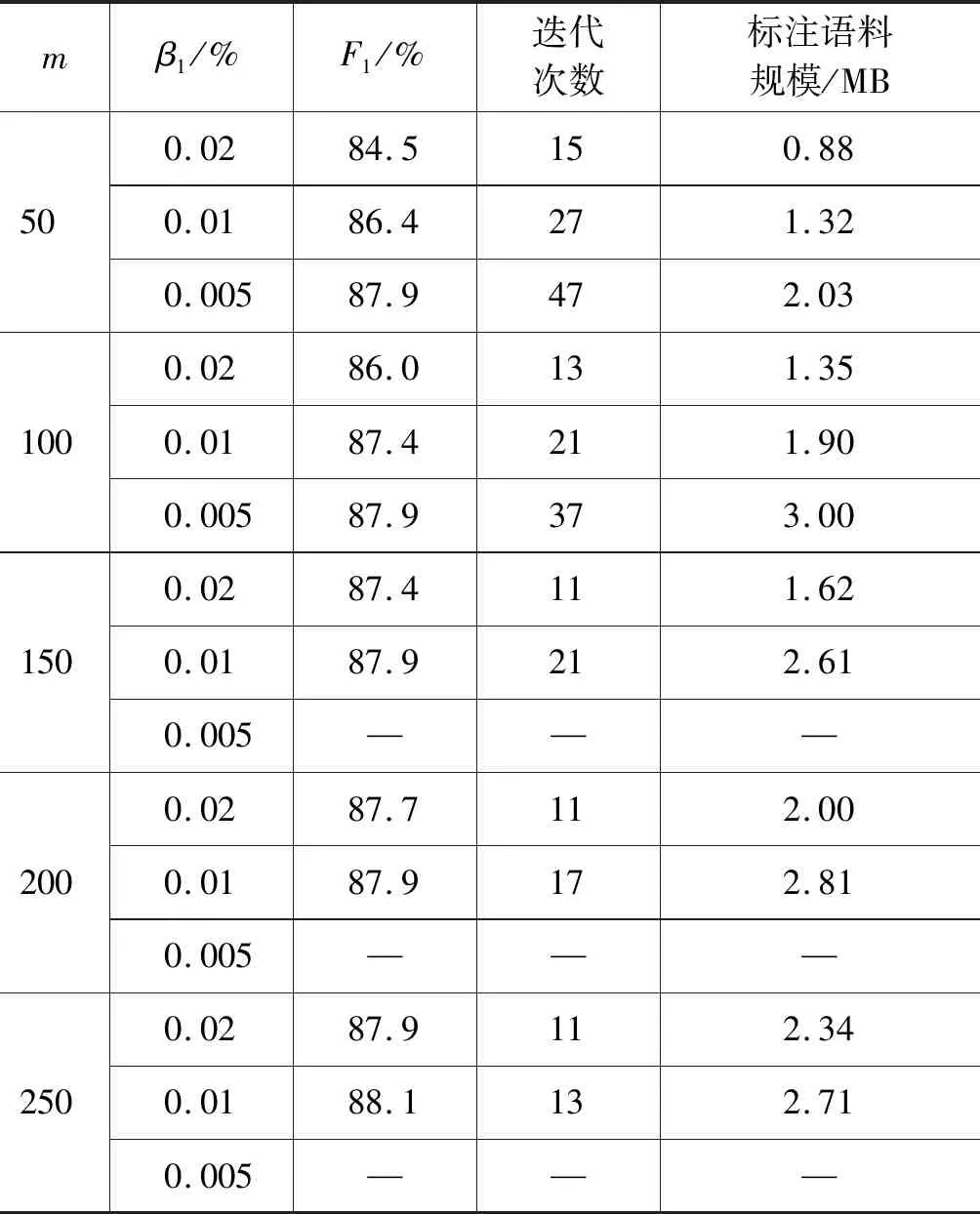
表3 方法2不同参数的藏文人名识别效果
3.2.3 方法3参数的确定
由于方法3的选择策略n和停止策略α2均基于置信度,因此二者的取值只能相等。假定选择策略和停止策略同等重要,令n=α2=0.5,此时的标注效果、标注规模及迭代次数如表4所示,可见,基于该主动学习方法,藏文人名识别的F1值为86.9%,主动学习迭代次数为18次,语料标注规模为2.05MB。

表4 方法3的藏文人名识别效果
3.2.4 方法4参数确定
表4所示为当选择策略的置信度阈值为0.4~0.7,停止策略的差异度为0.02%、0.01%、0.005%时对应的藏文人名识别效果、主动学习迭代次数及语料标注规模。
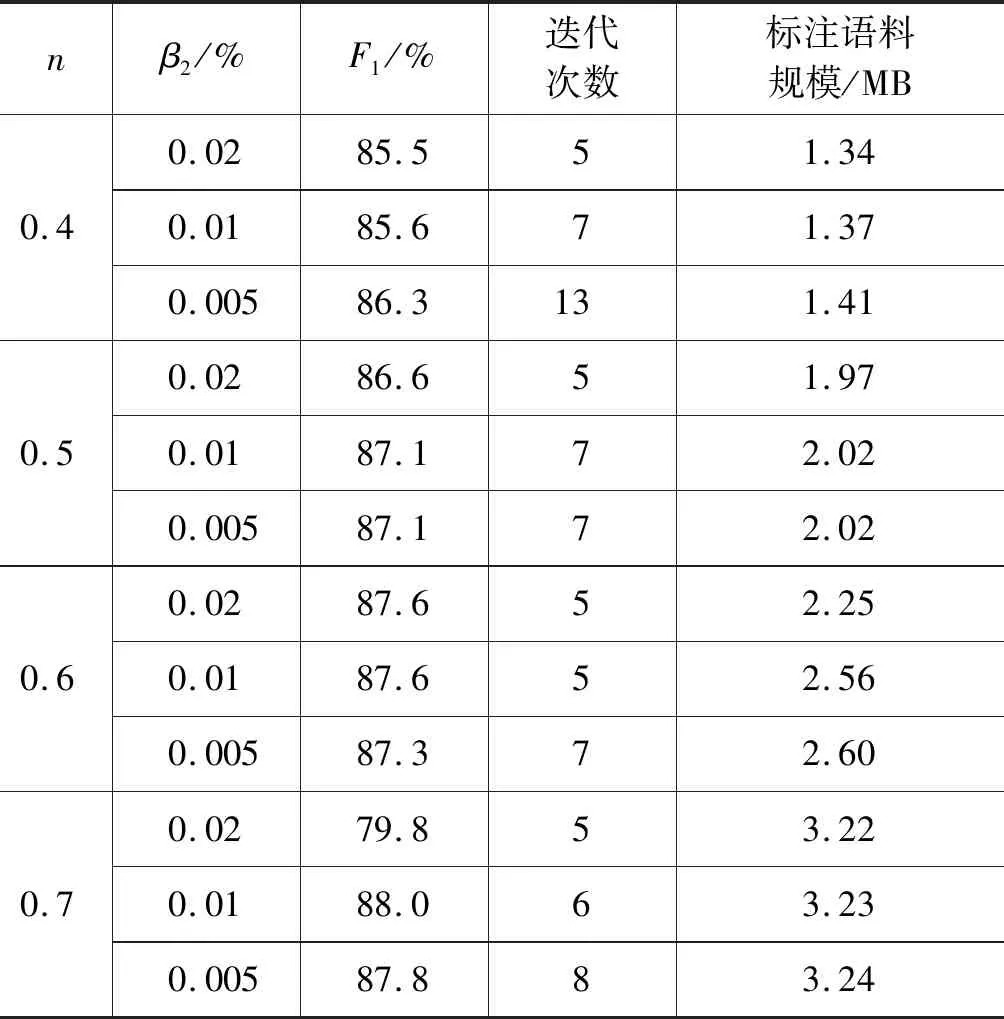
表5 方法4不同参数的藏文人名识别效果
由表5可见: 综合考虑识别效果、语料标注规模及迭代次数,选择n=0.7、β2=0.01%时,藏文人名识别的F1值可达到88.0%,此时,主动学习迭代次数为6次,语料标注规模为3.23 MB。
3.2.5 监督式学习方法与主动学习方法对比
表6是基于不同标注语料规模的监督式学习模型的藏文人名识别效果[21]。可见,当所有训练语料(10.26 MB)均已人工标注的条件下,藏文人名识别的F1值最高可达88.3%。
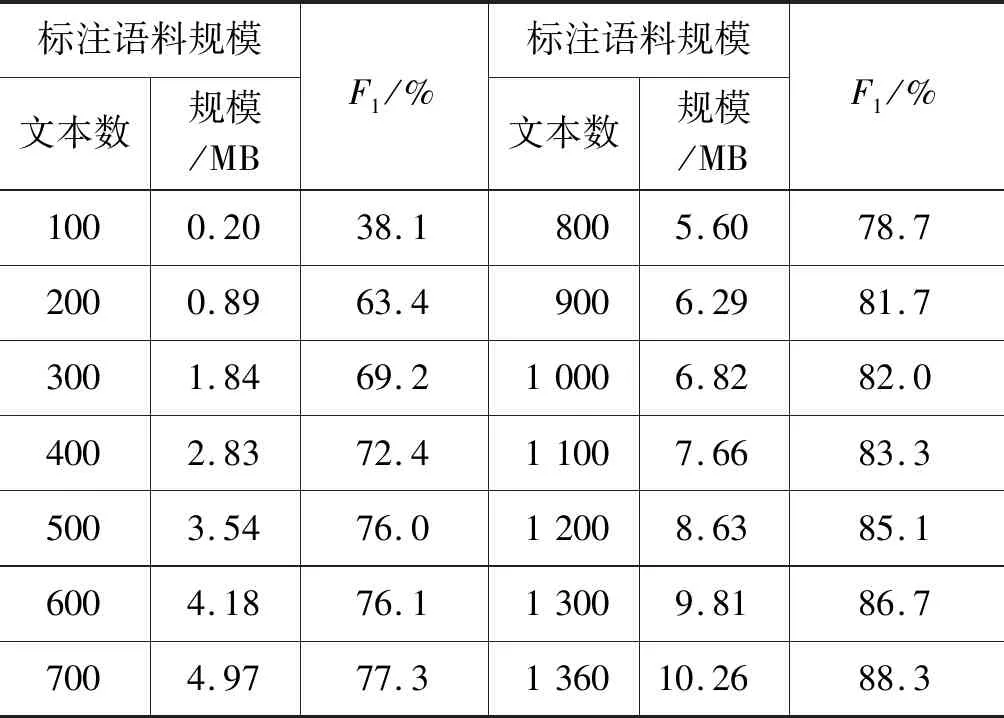
表6 语料规模对藏文人名识别效果的影响(基于CRF)
表7所示为藏文人名识别的监督式学习方法和主动学习方法的对比情况。
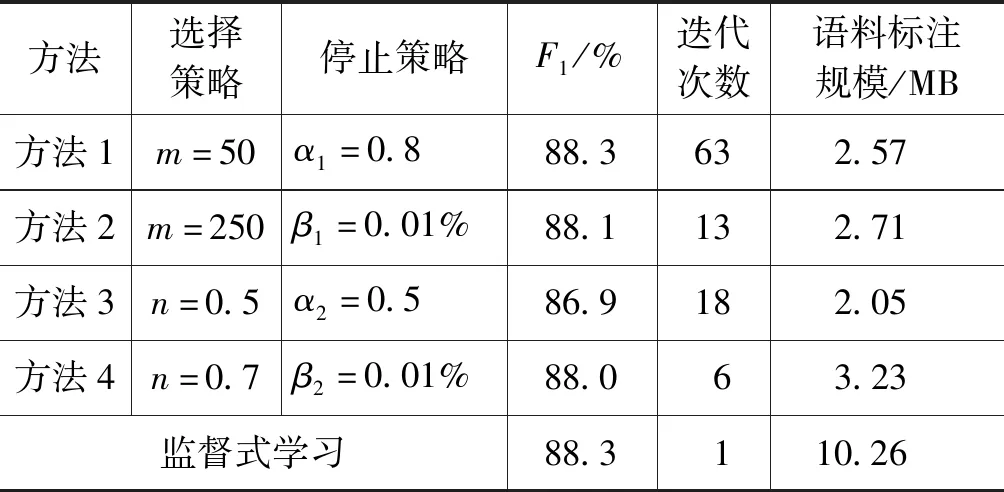
表7 监督式学习方法与主动学习方法对比
由表7可见:
(1) 主动学习方法可以基于较少的标注语料达到基于较多标注语料的监督式学习方法的识别效果。本文提出的主动学习方法1、2、4仅用约30%的人工标注语料就达到了基于10 MB标注语料的监督式学习方法的藏文人名识别效果。
(2) 主动学习方法的效果取决于选择策略和停止策略的设计,主动学习方法的评价指标除了F1值,还有循环迭代次数以及语料标注量。
主动学习方法1具有最好的识别效果(88.3%)以及最少的语料标注量(2.57 MB),但是方法1的循环迭代次数高达63次,语料标注周期过长;
主动学习方法2具有较好的识别效果(88.1%)以及较少的语料标注量(2.71 MB),但方法2的循环迭代次数为13次,语料标注周期相对也过长;
主动学习方法4所需的时间迭代次数最少,藏文人名的识别效果略低于方法1(方法4的F1值约为88.0%),但方法4的语料标注量最大(约3.23 MB)。
综合识别效果、迭代次数以及语料标注规模三个因素,我们选择方法4作为藏文人名的主动学习模型。
4 总结与展望
语料标注成本是资源稀缺语言自然处理研究面临的问题之一,主动学习方法通过选择一些信息大、不确定性高、无冗余的语料进行人工标注,进而在保证效果的前提下,大大降低语料标注成本。本文基于置信度提出了四种主动学习方法,实验证明: 主动学习方法4(每次迭代选择置信度低于0.7的句子进行人工标注,直到新、旧模型标注结果的差异度小于0.01%)可用3.23 MB的标注语料、在最少的迭代次数近似达到监督式学习方法10 MB标注语料的效果,人工语料标注量降低了约66%。
基于主动学习的藏文人名识别模型中,识别效果、迭代次数以及语料标注规模三个因素有的互为促进关系、有的互为制约关系,今后可以从这三因素的关系出发对选择策略和停止策略进行进一步优化设计,进而达到以最低的人力、时间成本获取大规模、高质量标注语料的目的。
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
布达拉(2020年3期)2020-04-13 10:00:07
西夏学(2019年1期)2019-02-10 06:22:34
计算机应用(2018年5期)2018-07-25 07:41:26
海外华文教育(2016年1期)2017-01-20 08:21:58
西藏大学学报(自然科学版)(2016年1期)2016-11-15 05:23:31
新闻传播(2016年17期)2016-07-19 10:12:05
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
轴承(2015年2期)2015-07-25 03:51:04
民族古籍研究(2014年0期)2014-10-27 08:24:34
