
基于特征选择和深度信念网络的文本情感分类算法
2019-09-04 10:14向进勇杨文忠吾守尔斯拉木
计算机应用 2019年7期
向进勇 杨文忠 吾守尔?斯拉木


摘 要:由于人类语言的复杂性,文本情感分类算法大多都存在因为冗余而造成的词汇量过大的问题。深度信念网络(DBN)通过学习输入语料中的有用信息以及它的几个隐藏层来解决这个问题。然而对于大型应用程序来说,DBN是一个耗时且计算代价昂贵的算法。针对这个问题,提出了一种半监督的情感分类算法,即基于特征选择和深度信念网络的文本情感分类算法(FSDBN)。首先使用特征选择方法(文档频率(DF)、信息增益(IG)、卡方统计(CHI)、互信息(MI))过滤掉一些不相关的特征从而使词汇表的复杂性降低;然后将特征选择的结果输入到DBN中,使得DBN的学习阶段更加高效。将所提算法应用到中文以及维吾尔语中,实验结果表明在酒店评论数据集上,FSDBN在准确率方面比DBN提高了1.6%,在训练时间上比DBN缩短一半。
关键词:深度信念网络;深度学习;特征选择;半监督的情感分类算法;受限波尔兹曼机;文本情感分类
中图分类号: TP391.1
文献标志码:A
英文标题
Text sentiment classification algorithm based on feature selection and deep belief network
英文作者名
XIANG Jinyong1,2, YANG Wenzhong1*, SILAMU·Wushouer2第三作者的名字书写,与文后文献17的写法不同,此处表述是否正确?请核实。英文作者的书写,在落款中,是姓氏大写,名字要小写,照此规定,中文姓名中,哪个是姓氏,哪个是名字,也请明确。回复:维吾尔族姓名中点后面的是父亲的名字
英文地址(
Abstract: Because of the complexity of human language, text sentiment classification algorithms mostly have the problem of excessively huge vocabulary due to redundancy. Deep Belief Network (DBN) can solve this problem by learning useful information in the input corpus and its hidden layers. However, DBN is a time-consuming and computationally expensive algorithm for large applications. Aiming at this problem, a semi-supervised sentiment classification algorithm called text sentiment classification algorithm based on Feature Selection and Deep Belief Network (FSDBN) was proposed. Firstly, the feature selection methods including Document Frequency (DF), Information Gain (IG), CHI-square statistics (CHI) and Mutual Information (MI) were used to filter out some irrelevant features to reduce the complexity of vocabulary. Then, the results of feature selection were input into DBN to make the learning phase of DBN more efficient. The proposed algorithm was applied to Chinese and Uygur language. The experimental results on hotel review dataset show that the accuracy of FSDBN is 1.6% higher than that of DBN and the training time of FSDBN halves that of DBN.
Key words: Deep Belief Network (DBN); Deep Learning (DL); Feature Selection (FS); semi-supervised sentiment classification algorithm; Restricted Boltzmann Machine (RBM); text sentiment classification
0 引言
如今,互聯网上社交媒体的数据量大幅度增长。个人和组织试图从这些大型数据集中提取有用的信息,以便作出更好的判断并提高客户满意度。例如,在决定是否购买产品或服务之前,客户会查看其他人对产品的评论。同样,产品的制造商也使用这些信息来提高产品的服务和质量。然而,由于网络上有大量的可用数据,人们手工的去标注这些数据是不现实的,因此,文本情感分类(确定文档中表达的情绪是积极的、中立的还是消极的)将对商业智能应用程序、推荐系统和消息过滤应用程序有帮助和益处。
为了构建一个准确的情感性分类器,在过去的几年里,许多研究者尝试将深度学习算法与机器学习算法相结合[1-4]。深度学习算法具有处理数百万个参数的能力,可以极大地提高模型预测的能力。其中一个典型的例子是Socher等[4]提出的基于情感树的递归神经网络训练,它能准确预测文本情感,准确率达85%以上;然而在有监督训练方法中需要大量的标记训练数据,手工标记这些数据常常是困难和费时的。
文献[5]中提出了半监督学习的新方法,它的目的是利用大量的未标记数据和标记数据构建文本情感分类器。文献[6]称半监督深度学习模型可以在获得良好的性能的同时避免上述问题。然而目前的深度学习算法对于大型应用程序来说计算成本很高。
此外,大多数分类算法使用固定大小的数字特征向量作为输入,而不是使用原始的变长文本文档,因此,有必要将一个文档语料库转换为一个矩阵,每个文档表示一行,每个词语表示一列,每一列表示词语在语料库中发生的情况。由于人类语言的复杂性,特征项的维度可能超过1万维度,而其中大多数是嘈杂的或冗余的。这将导致分类错误的数量和计算时间的增加。
为了克服上述缺陷,使学习阶段更高效、更准确,必须进行有效的特征选择,其目的是过滤训练集中出现的非必要特征项,只选择有意义的特征项。Forman[7]提出了多种特征选择的方法。结果表明,采用特征选择方法可以通过消除噪声特征来减少输入数据的维数,从而提高分类算法的性能,因此,本文提出的方法可以更快地训练出分类模型,减少内存消耗,并得到更高的结果精度。
1 相关工作
在本章中,介绍相关特征选择算法和半监督深度学习的理论背景。
1.1 特征选择
特征选择是通过选择相关特征的子集来简化模型构建的过程。它有两个主要角色:第一个作用是通过减少词汇输入的大小来提高分类器的训练过程的效率;第二个作用是通过过滤不重要的术语或噪声特征来提高预测精度,因此,可以缩短训练时间,也可以得到更好的模型表示。特征选择是一种比较常用的特征维数约减的方法,选择出更具有代表特征。特征选择的好坏对情感文本分类的效果有很大的影响。
基本上,特征选择技术可以分为三类:过滤技术、包装技术和嵌入技术。在学习算法之前,使用基于过滤的技术作为预处理步骤。根据一些标准对特征进行排序,如果它们的分数超过适当的预先定义的阈值,就会进行选择。包装器技术使用一种学习算法来选择和评估所有特性中的一个子集。嵌入式技术作为训练过程的一部分进行特征选择。
在这三种类型中,基于过滤的方法是最适合的,因为它简单、快速,并且独立于分类器。它具有良好的可扩展性,可以有效地应用于大型应用。文献[8-9]对特征选择的方法进行了研究,基于过滤器的技术有文档频率(Document Frequency, DF)[9-10]、信息增益(Information Gain, IG)[10]、卡方统计(CHI-square statistics, CHI)[11-12]、互信息(Mutual Information, MI)[13]等,在所有特征选择算法中,本文使用文档频率、信息增益、卡方统计、互信息作为基于特征选择和深度信念网络的文本情感分类算法(text sentiment classification algorithm based on Feature Selection and Deep Belief Network, FSDBN)框架中的特征選择方法,用实验证明哪种特征选择方法与深度信念网络(Deep Belief Network, DBN)结合可以取得最好的文本情感分类效果。
1.1.1 文档频率
文档频率方法的基本思想是:统计每个词的文档频率值,根据预先设定的最小文档频率值以及最大的文档频率值来除去一些没有代表的特征,如果特征t的文档频率值在最小和最大阈值之间,则保留此特征t;否则就删去此特征。这种方法理解与实现起来比较简单,适用于大规模数据集,阈值的设定可能会影响到特征选择的效果,从而影响到文本分类的效果。
1.1.2 信息增益
信息增益(IG)能够度量某个特征包含类别信息的多少,一个特征词的信息增益等于该特征出现前后的信息熵之差,通常会对某一文档、类别或是整个数据集来计算,根据IG方法的定义,某个特征的信息增益越大说明该特征对于分类就越重要。
信息增益的公式(1)如下,针对某个具体的类别ci,对于特征t的信息增益如式(1):
其中表示特征t不出现,那么特征t对于整个训练集的信息增益如式(2):
1.1.3 卡方统计
卡方统计(CHI)能表示两个变量的相关性,CHI兼顾了特征存在与特征不存在时的情况。根据CHI的定义以及公式可知特征与类别的CHI值越大,就表示这个特征就越重要。
文献[10]分别根据卡方统计(CHI)以及互信息(MI)的特征选择方法给语料中的中文特征词赋予了一定的权重。
有的研究人员也使用了改进的卡方特征选择技术[12]来避免卡方统计量的缺点“低频词缺陷问题”(它只统计文档是否出现词而不管出现几次)。这会使得它对低频词有所偏袒(因为它夸大了低频词的作用),甚至它会出现一些情况,一个词在一类文章的每篇文档中只出现一次,其卡方值却大过了在该类文章99%的文档中出现了10次的词,其实后面的词才是更具代表性的,但只因为它出现的文档数比前面的文档中词少了“1”,特征选择的时候就可能筛掉后面的词而保留前者)。
1.1.4 互信息
互信息(MI)是信息论中的一个概念,表示的是一个随机变量中包含另一个随机变量的信息量。在文本情感分析任务中,特征项跟情感类别之间的互信息量可以表示特征项推测出情感类别的能力,若特征项与情感类别的互信息为0,这就可以表示特征项不包含任何的特征信息,对文本情感分类没有任何的贡献。如果互信息越大,表示特征项包含的情感信息越大,类别间的区分程度也就越大。特征项t与情感类别C之间的互信息量计算公式(4)如下:
不管使用什么样的特征选择技术,最终的目的就是减少特征的空间,消除噪声从而提高分类器的性能。本文使用这四种特征选择方法与深度信念网络结合实现半监督的文本情感分类。
1.2 半监督深度学习
半监督深度学习是机器学习的一个分支,它利用少量的标记数据和大量的未标记数据。半监督深度学习算法的一个著名例子是深度信念网络(DBN),它是由Hinton等最近提出的。DBN是由限制玻尔兹曼机(Restricted Boltzmann Machine, RBM)构造的许多隐藏层组成的。该模型利用大量未标注数据,克服领域依赖和缺乏标注数据缺陷,同时获得良好的性能[14]。
1.2.1 受限玻尔兹曼机
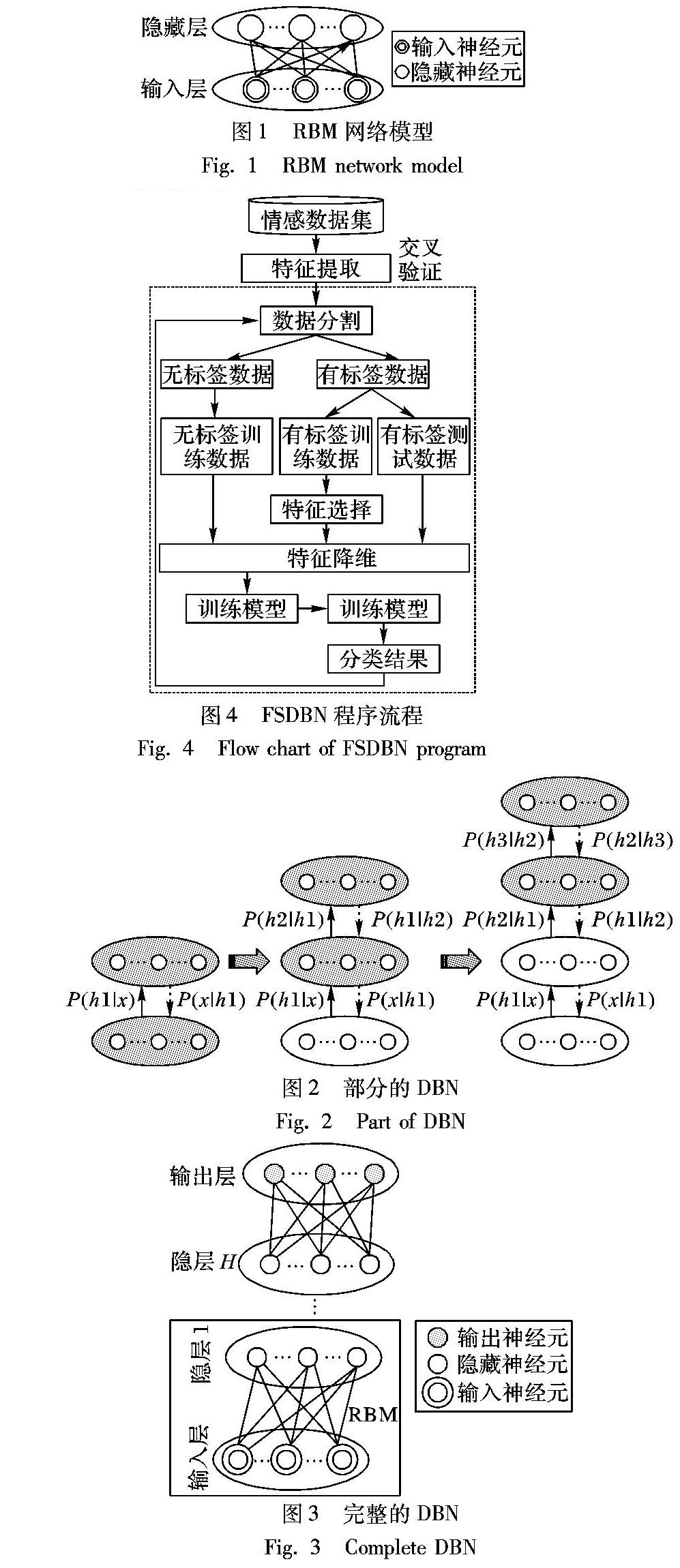
受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)是一种基于能量的生成随机模型,其目标是了解其输入集的概率分布。它由一个输入层(可见层)和一个隐藏层组成,通过对称加权连接,但同一层神经元之间没有连接。图1显示了RBM的网络模型。
为了训练一个网络模型,最广泛使用的算法被称为对比散度(Contrastive Divergence, CD)。训练RBM的目的是优化网络中的权向量,以最小化误差。为了在尽可能保持输入数据分布的同时降低网络的能量,在训练数据的对数似然时应用了随机梯度上升,关于方程的更多细节可以参阅文献[15]。
1.2.2 深度信念网络
為了获取更好的性能,一组受限制的玻尔兹曼机器可以定义为深度信念网络(DBN)。为了构建DBN,本文可以按照以下步骤[16]。
利用一组RBMs作为构建块,贪婪地分层无监督学习构造DBN。该学习算法有效地利用了未标记数据,在输入数据中提供了大量的模式,从而比随机数据产生更好的初始权值。
利用基于梯度下降算法的有监督学习方法,根据指数损失函数训练DBN。模型的权值通过标记数据来细化,目的是进行模式分类。
图2显示了具有一个输入层的DBN的贪婪分层无监督训练过程,即输入层x和三个隐藏层即从下到上分别是h1、h2和h3。较浅的颜色层代表已经过训练的层,而较深的颜色层则是经过训练的层从图中看不出来,请明确是否描述正确?。经过贪婪的分层无监督学习,h3(x)是x的表示。然后,在顶部添加一个输出层,并使用标记评论来细化权重,以提高识别能力。图3显示了完整的DBN。
作者说:图3与图2位置放反了。因此,调整图形的编号即可。
在文本情感分类研究中,DBN采用以词袋模型表示的矩阵作为输入。前几层期望从输入中提取低层次的特性,而上一层则需要提炼以前学过的特性模式,从而生成更复杂的特征。最后,在输出层预测评论的情绪傾向,无论是积极的还是消极的。
2 基于特征选择和深度信念网络的分类算法
本章将介绍基于特征选择的深度信念网络(FSDBN)的主要设计流程。图4是显示执行文本情感分类任务的框架。大多数任务与其他文本分类方法相似,分别包括特征提取、数据分隔、模型训练和测试。然而,在本文题注的算法中有两个新的任务,即特征选择和缩减。每个任务的细节如下所述。
2.1 特征提取
在文本情感分类应用中,需要将变长文档转换为适合于分类算法的固定大小的数字特征向量。对基于文本的输入进行特征提取的常用技术是词袋技术,该技术通过单词出现来描述文档,而忽略了单词的相对位置信息。有两个主要任务,包括特征定义和加权分数计算。在本文的模型中,本文算法将标记的词语应用为“特征”(中文使用结巴进行分词、维吾尔语提取unigram)。
想要提取特性,首先进行分词(中文使用结巴进行分词、维吾尔语提取unigram),然后把所有的特征生成一个字典,在一个文档中,如果该特征出现就赋值为1;否则为0。此外,根据每个词汇表降序排列的次数排序的前2%词汇表将被删除,因为它们中的大多数都是停止词(例如“的”“是”),或者它们可能是特定领域或通用的词(例如,酒店评论中的“酒店”)。从理论上讲,停用词可以出现在正训练数据集或负训练数据集中,而不带有任何情绪信息,这可能会增加分类错误率,因为它们的情绪含糊不清。在此过程之后,一个文档语料库就形成了一个二进制值矩阵,每个文档表示一行,每个特性或标记在语料库中表示一列。
2.2 数据划分
为了使得到的结果更加具有说服力,在中文文本情感分类中,本文选取谭松波博士收集整理的酒店评论语料、京东上获取的书集书籍评论语料、淘宝上获取的电脑评论语料。
为了验证模型FSDBN在维吾尔语文本情感分类中的有效性。相对于中文和英文来说维吾尔语的文本情感开放语料较少,本实验所使用的维吾尔语文本情感语料是由伊尔夏提·吐尔贡等[17]在这三个维文网站(Alkuy、TianShan、Putbal)上收集的评论数据,然后经过维吾尔族大学生进行手工筛选,最终形成了pos类5000多条句子以及neg类5000多条句子。
在这四个数据集中,本文选取3000个标签评论(即在每个数据集中,有1500个正面和1500个负面)。
由于所提出的分类器是一种半监督学习算法,利用未标记和标记数据构造分类器,因此,本文方法将数据集划分为三个集,包括未标记训练集、标记训练集和标记测试集。将每个3000个评论的数据集随机划分为10个大小相等的文档,同时为了交叉验证的目的,仍然在每份文档中保持平衡的类分布。在每一轮中,本文算法选择一份文档作为标记数据集,然后随机选择这份文档中的一半评论作为标记训练数据集,另一半作为标记测试数据集。其余9个折叠被用作未标记的数据集。
2.3 特征选择和特征约减
为了提高分类精度,本文的目标是通过特征选择和特征约减来消除可能导致分类误差的噪声特征。在本文的框架中,本文使用文档频率、信息增益、卡方统计、互信息特征选择来确定哪些特征与情感分类最相关,以获得最高的分类准确性。
本文提出的分类算法经过特征选择算法来选择前n%的特征来构建文本情感分类模型,而其他的则不用于分析。每个数据集的最佳n百分比值如表3所示见3.4节实验。值得注意的是,本文之所以使用带标签的训练数据集来进行特征选择,仅仅是因为该算法基于监督学习方法,并且避免了测试集出现过拟合问题。
2.4 模型训练和测试
本文框架中使用的情感分类模型是基于深度信念网络的。首先,学习算法使用无标记的训练评论执行贪婪的分层无监督学习;然后,利用基于梯度下降法的监督学习方法,通過带指数损失函数的训练来改进模型的权值;在完全构建预测模型后,利用标记数据对模型进行测试;最后的分类结果使用十倍交叉验证在F值方面的平均。第3章将介绍DBN的学习参数和结构。
3 实验以及讨论
在本章中,为了验证本文提出的FSDBN算法的性能,将其在准确率和训练时间方面与其他算法半监督学习算法[1,4,18-20]进行比较。
3.1 实验设置
本文实验的目的是评估本文提出的框架与5种半监督学习情感分类器在准确性以及训练时间方面的性能表现,这5种半监督的文本情感分类器分别是:深度信念网络(DBN)、混合深信念网络(Hybrid Deep Belief Network, HDBN)[4]、半监督谱学习(semi-supervised spectral learning)[18]、转换式支持向量机(Transductive Support Vector Machine, TSVM)[19]、个人/非个人观点(Personal/Impersonal Views, PIV)[20]。分类器具体概述如下。
谱学习利用数据矩阵特征向量中的信息检测结构,进行半监督聚类和分类。
TSVM利用未标记数据提高了支持向量机(Support Vector Machine, SVM)的泛化精度。与SVM类似,它使用带标记的训练数据学习了一个大范围的超平面分类器,但同时迫使这个超平面远离未带标记的数据。谱学习和TSVM方法是半监督情绪分类的两种基本方法。
PIV采用个人和非个人的观点构建半监督分类器。个人观点包括直接表达说话人对目标对象的感受和偏好的句子,而非个人观点则集中于对目标对象的陈述进行评价。
DBN是在第1章中提出的经典深度学习方法。
HDBN是RBM和卷积RBM(Convolutional RBM, CRBM)的混合深度网络结构,底层由RBMs构造,可以快速减少尺寸,提取输入信息;然后,使用CRBM在上层抽象更复杂的信息;最后,利用基于梯度下降法的有监督学习方法对整个网络进行了指数损失函数的微调。
同样,用于评估的5种文本情感分类器的数据集是酒店评论数据、书集书籍评论数据是书集?还是书籍?全文应该统一,请明确。回复:书集改为书籍、电脑评论数据以及维吾尔语评论数据。
3.2 参数设置
为了比较结果,本文提出的模型中使用的学习参数与文献[3-4,21]相同。在训练前的步骤中,本文对所有的隐藏层和输出层执行贪婪的分层无监督学习,epoch=30。在有监督学习阶段,将epoch设置为30,学习率为0.1,每个epoch设置为0.9。使用的DBN结构为100-100-200-2,表示三个隐藏层中的神经元单元数分别为100、100和200,输出层中的神经元单元数分别为2(正、负)。
3.4 实验结果
在从分类准确率和训练时间方面详细分析实验结果和分析结果之前,首先要论证特征选择和缩减对输入维数大小的影响。
不同的特征保留率对文本情感分类的准确性以及模型的训练时间有着一定的影响,在4个文本情感分析数据集上,特征保留率对文本情感分类准确性的影响。如表2所示。
从表2中可以看出使用不同的特征选择方法进行特征选择以及特征约减得到的F值不同。比如说使用文档频率方法在4个数据集上特征保留率为40%、40%、50%以及30%取得最好的分类效果。故根据表2可以得到表3 FSDBN模型在不同特征选择方法下的特征保留率。
使用特征选择可使得特征数目减少。它展示了本文提出的降维方法的性能,该方法可以过滤掉大多数无用的特征。表3显示了在4个数据集上以及4种特征选择方法特征减少到原特征的多少时文本情感的分类效果最好。
3.4.1 F值
采用半监督学习方法对4个情感分类数据集进行10倍交叉验证的分类准确性结果如表4所示。
实验证明了在三个数据集上本文提出的方法FSDNBN在准确率上都有所提升并且在两个数据集上的特征选择算法都是信息增益。
从表4可以看出,FSDBN在三个标记为粗体的数据集中执行了最好的精度结果。另一方面,DBN、HDBN和FSDBN可以在所有数据集中执行得很好。结果证明了深层架构在情感分类中的强大功能。
3.4.2 训练时间
DBN与FSDBN的训练时间(从执行特征提取到构建完整模型)结果如图65所示。比较而言,除了要训练的特性数量和网络结构外,本文在相同的环境和相同的参数设置中运行它们。对于要训练的特性数量,对于DBN,本文使用了完整的特性集,而不进行任何的特性选择和减少,但是对于FSDBN,本文采用了第2章中描述的方法。
表格(有表名)
表4 半监督文本情感分类算法的F值表4与图5是否存在重复表达现象,若存在重复表达,请只保留一种表达方式。正文中的引用文字部分和描述需作相应修改或删除。
在图65中,可以看到FSDBN在所有数据集中花费的训练时间比DBN少得多。FSDBN的平均速度可以提高2倍多,在使用维吾尔语评论数据集时几乎可以提高4倍。这是因为维吾尔语评论数据集比其他3个数据集具有更多的特性,因此,使用FSDBN,删除了更多的特征,这使得与DBN相比,训练时间更短,同时仍然保持了良好的准确率。
特别地,显著提高FSDBN训练时间的主要因素是它更简单的深层结构,它替换了几个隐藏层,但是增加了本文提出的特征选择方法。
根據实验结果,可以看出本文提出的FSDBN比其他半监督情绪分类算法更快、更准确。
4 结语
为了解决文本情感分类问题,本文提出了一种名为FSDBN文本情感分类算法,使用基于过滤器的特征选择技术替换了DBNs中的几个隐藏层,然后,过滤掉不必要的特性,只选择有意义的特性。实验结果表明,在特征选择和约简的辅助下,FSDBN的学习阶段效率更高。FSDBN的分类精度高于基本的半监督学习算法,如光谱学习、TSVM和个人PIV。此外,FSDBN的性能略好于其他深度学习算法DBN和混合深度信念网络(HDBN)。此外,还可以观察到,与传统的DBN相比,FSDBN花费的训练时间要少得多。在未来的工作中,计划将本文的算法并行化并在GPU平台上运行,以加速其计算。目标是解决现实世界中的大量问题,具有更好的标度能力,同时仍能保持良好的分类准确率。这里的特征选择方法只使用了文档频率、信息增益、卡方统计以及互信息,还可以使用其他的特征选择方法。
参考文献 (References)
[1] HINTON G, OSINDERO S, TEH Y. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7): 1527-1554.
[2] ZHOU S, CHEN Q, WANG X, et al. Hybrid deep belief networks for semi-supervised sentiment classification[C]// Proceeding of the 2014 25th International Conference on Computational Linguistic. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1341-1349.
[3] ZHOU S, CHEN Q, WANG X. Active deep networks for semisupervised sentiment classification.[C]// Proceedings of the 2010 23rd International Conference on Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2010: 1515-1523.
[4] SOCHER R, PERELYGIN A, WU J J. et al. Recursive deep models for semantic compositionality over a sentiment treebank [C]// Proceedings of the 2013 International Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2013: 1631-1642.
[5] DASGUPTA, S, NG V. Mine the easy, classify the hard: a semisupervised approach to automatic sentiment classification [C]// Proceedings of the 2009 47th International Conference on Annual Meeting of the Association for Computational Linguistics and Proceedings of the 2009/4th International Joint Conference on Natural Language of the Asian Federation of Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2009: 701-709.
[6] PANG B, LEE L, VAITHYANATHAN S. Thumbs up?: sentiment classification using machine learning techniques [C]// Proceedings of the 2002 International Conference on Association for Computational Linguistics on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2002: 79-86.
[7] FORMAN G. An extensive empirical study of feature selection metrics for text classification[J]. The Journal of Machine Learning Research, 2003: 1289-1305.
[8] YANG Y, PEDERSEN J O. A comparative study on feature selection in text categorization[C]// Proceedings of the 1997 14th International Conference on Machine Learning. San Francisco, CA: Morgan Kaufmann, 1997: 412-420.
[9] 周茜,赵明生,扈旻.中文文本分类中的特征选择研究[J].中文信息学报,2004,18(3):17-23.(ZHOU Q, ZHAO M S, HU M. Research on feature selection in Chinese text classification [J]. Journal of Chinese Information Processing, 2004, 18(3): 17-23.)
[10] 吴金源,冀俊忠,赵学武,等.基于特征选择技术的情感词权重计算[J].北京工业大学学报,2016,42(1):142-151.(WU J Y, JI J Z, ZHAO X W, et al. Weight calculation of affective words based on feature selection technique[J]. Journal of Beijing University of Technology, 2016, 42(1):142-151.)
[11] 周爱武,马那那,刘慧婷.基于卡方统计的情感文本分类[J].微电子学与计算机,2017,34(8):57-61.(ZHOU A W, MA N N, LIU H T. Emotional text classification based on chi-square statistics [J]. Microelectronics and Computer, 2017, 34(8): 57-61.)
[12] 裴英博,刘晓霞.文本分类中改进型CHI特征选择方法的研究[J].计算机工程与应用,2011,47(4):128-130.(PEI Y B, LIU X X. Research on improved CHI feature selection method in text classification [J]. Computer Engineering and Application, 2011, 47(4): 128-130.)
[13] BAGHERI A, SARAEE M, de JONG F. Sentiment classification in Persian: introducing a mutual information-based method for feature selection[C]// Proceedings of the 2013 21th International Conference on Electrical Engineering. Piscataway, NJ: IEEE, 2013: 1-6.
[14] BLIZER J, DREDZE M, PEREIRA F. Biographies, bollywood, boomboxes and blenders: domain adaptation for sentiment classification[C]// Proceedings of the 2007 International Conference on Association for Computational Linguistic. Stroudsburg, PA: Association for Computational Linguistics, 2007: 440-447.
[15] LOPES N, RIBEIRO B, GONALVES J. Restricted Boltzmann machines and deep belief networks on multi-core processors [C]// Proceedings of the 2012 International Joint Conference on Neural Networks Piscataway, NJ: IEEE, 2012: 1-7.
[16] 张庆庆,刘西林.基于深度信念网络的文本情感分类研究[J].西北工业大学学报(社会科学版),2016,36(1):62-66.(ZHANG Q Q, LIU X L. Research on text emotion classification based on deep belief network[J]. Journal of Northwest Polytechnic University (Social Science Edition), 2016, 36(1): 62-66.)
[17] 伊爾夏提·吐尔贡,吾守尔·斯拉木,热西旦木·吐尔洪太,等.维吾尔文情感语料库的构建与分析[J].计算机与现代化,2017(4):67-72.(TUERGONG Y, SILAMU W, TUSERHONGTAI R文献的书写中,是姓氏大写,名字取首字母大写,请明确中文姓氏中,哪个是姓氏,哪个是名字?, et al. Construction and analysis of Uighur affective corpus [J]. Computer and Modernization, 2017(4): 67-72.)
[18] KAMVAR S D, DAN K, MANNING C D. Spectral learning[C]// Proceedings of the 2003 International Joint Conference on Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 2003: 561-566.
[19] COLLOBERT R, SINZ F, WESTON J, et al. Large scale transductive SVMs[J]. The Journal of Machine Learning Research, 2006, 7: 1687-1712.
[20] LI S, HUANG C R, ZHOU G, et al. Employing personal/impersonal views in supervised and semi-supervised sentiment classification[C]// Proceedings of the 2010 48th International Joint Conference on Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2010: 414-423.
[21] RUANGKANOKMAS P, ACHALAKUL T, AKKARAJITSAKUL K. Deep belief networks with feature selection for sentiment classification[C]// Proceedings of the 2017 48th International Conference on Intelligent Systems, Modelling and Simulation. Piscataway, NJ: IEEE, 2017: 9-14.
猜你喜欢
计算技术与自动化(2022年2期)2022-07-04
现代电子技术(2016年23期)2017-01-12
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
电脑知识与技术(2016年25期)2016-11-16
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
电脑知识与技术(2016年15期)2016-07-04
