
基于K最近邻样本平均距离的代价敏感算法的集成
2019-09-04 10:14杨浩王宇张中原
计算机应用 2019年7期
关键词:集成
杨浩 王宇 张中原


摘 要:为了解决不均衡数据集的分类问题和一般的代价敏感学习算法无法扩展到多分类情况的问题,提出了一种基于K最近邻(KNN)样本平均距离的代价敏感算法的集成方法。首先,根据最大化最小间隔的思想提出一种降低决策边界样本密度的重采样方法;接着,采用每类样本的平均距离作为分类结果的判断依据,并提出一种符合贝叶斯决策理论的学习算法,使得改进后的算法具备代价敏感性;最后,对改进后的代价敏感算法按K值进行集成,以代价最小为原则,调整各基学习器的权重,得到一个以总体误分代价最低为目标的代价敏感AdaBoost算法。实验结果表明,与传统的KNN算法相比,改进后的算法在平均误分代价上下降了31.4个百分点,并且代价敏感性能更好。
关键词:代价敏感;最大化最小间隔;样本间距离;贝叶斯决策理论;集成
Abstract: To solve the problem of classification of unbalanced data sets and the problem that the general cost-sensitive learning algorithm can not be applied to multi-classification condition, an integration method of cost-sensitive algorithm based on average distance of K-Nearest Neighbor (KNN) samples was proposed. Firstly, according to the idea of maximizing the minimum interval, a resampling method for reducing the density of decision boundary samples was proposed. Then, the average distance of each type of samples was used as the basis of judgment of classification results, and a learning algorithm based on Bayesian decision-making theory was proposed, which made the improved algorithm cost sensitive. Finally, the improved cost-sensitive algorithm was integrated according to the K value. The weight of each base learner was adjusted according to the principle of minimum cost, obtaining the cost-sensitive AdaBoost algorithm aiming at the minimum total misclassification cost. The experimental results show that compared with traditional KNN algorithm, the improved algorithm reduces the average misclassification cost by 31.4 percentage points and has better cost sensitivity.
Key words: cost-sensitive; maximization of minimum interval; distance between samples; Bayesian decision-making theory; integration
0 引言
在機器学习研究过程中,经常存在着样本类别分布不均衡的情况,传统的分类器注重于提高分类的准确率,对不均衡数据集的分类结果更倾向于多数类[1],这种分类方式默认两种分类错误的代价是相等的。然而在很多领域,比如入侵检测、医疗诊断、欺诈检测等,少数类的误分类代价十分巨大,在此类情况中,人们主要关心少数类的分类准确率。传统的算法无法满足此类数据的分类需要,于是代价敏感学习的思想被提出并广泛应用,代价敏感学习方法是解决不均衡数据集分类问题的一个重要方法[2]。代价敏感学习是指对不同的误分类结果赋予不同的代价,得到一个在对未知样本进行分类时误分代价最小的分类器[3]。常见的误分类代价包括基于类别的代价和基于样本的代价。在基于类别的代价中,代价只与类别有关,而在基于样本的代价中,误分类代价与每一个样本有关,在现实场景中,基于样本的代价很难获得,一般使用基于类别的代价。
一直以来,代价敏感学习算法在国际上都是机器学习和数据挖掘领域的研究热点。现有的代价敏感学习方法分为两种[4]:一是基于特定算法的代价敏感学习方法,将优化目标变为得到期望代价最小的假设。例如在决策树算法中使用代价敏感的叶节点分裂准则以及代价敏感的剪枝策略[5]。二是代价敏感学习元方法,将使期望误差率最小的学习算法转变为得到期望代价最小的代价敏感学习算法,常见方法包括重采样法[6]、阈值移动法[7]、集成学习法[8]。这种方法具备良好的通用性,文献[9]基于贝叶斯风险最小化原理提出了一种可以将任意的分类器算法转化为代价敏感算法的MetaCost算法,根据样本属于每个类的概率及误分类代价之积选取出分类代价最小的类别作为样本分类结果,达到最小误分代价。目前,一些常见的分类算法,如支持向量机(Support Vector Machine, SVM)、决策树、神经网络和AdaBoost都有对应的代价敏感算法[10-13]。MetaCost算法可以将传统的分类算法转化为代价敏感学习算法,并且适用于任何数目的样本类别和任意代价矩阵。
但是,目前的代价敏感学习算法主要针对二分类问题,对于代价敏感的多分类问题的研究不多,一些常见的算法无法扩展到多分类场景中。K最邻近(K-Nearest Neighbor, KNN)分类算法作为一种成熟的算法,具有鲁棒性、概念清晰等优点,算法以K个近邻样本的投票数来对未知样本进行分类,可以直接扩展到多分类场景中。尽管KNN算法的优势十分明显,但是它的缺点也不容忽视。KNN算法基于空间向量模型(Vector Space Model, VSM请补充VSM的英文全称)模型,利用欧氏距离或余弦距离度量样本的距离,但权重不变,这与实际情况不符,一种改进的方法是加权KNN算法,根据样本点之间的距离来分配权重,权重的大小随距离的减小而增大[14]。同时KNN算法在K值的设定方面依赖于经验,存在着K值单一的情况,而Boosting算法可以集成多个具备不同K值的KNN分类器,有效解决了这一问题[15]。
针对上述问题,本文提出了一种用于不平衡数据集上的近邻样本删减策略以及基于近邻样本间距的代價敏感(Cost Sensitive based on average Distance of K-Nearest Neighbor, CSD-KNN)算法,并在此基础上对此算法按一定策略进行集成。首先,针对多数类的边界进行选择性删减,在新的数据集上算法得到样本点与K个近邻样本的距离,并计算出每一个类中样本与测试样本点之间的平均距离,以此作为输入进行代价敏感变换,得到期望代价最小的代价敏感分类器,最后在具备代价权重初值的AdaBoost算法上集成这种改进后的算法,使之误分代价最小。在UCI数据集上的测试结果表明改进后算法的平均误分代价更低。
1 近邻样本删减策略
不均衡数据集会弱化分类器对少数类的分类效果,对样本集的修改策略是重构数据集,调整样本分布,使得多数类与少数类的样本比例趋于1∶1。已有成果表明对分类结果有较大影响的样本处于样本边界[16],降低边界处的多数类样本密度比减少多数类的样本数量更为切实有效。受支持向量机最大化最小间隔形式化目标的启发,本文对多数类的边界样本进行筛选,减小边界处多数类样本的密度,加大多数类与少数类的样本间隔,降低分类结果受少数类样本稀疏性的影响。
定义样本与自身的距离为∞。算法的思想是:确保少数类样本的最近邻样本仍为少数类,即遍历少数类中的所有样本,判断其最近邻样本点是否属于少数类,若不是,则删除此样本的最近邻点,并继续对此样本进行判断,直到此样本点的最近邻样本也属于少数类。
2 代价敏感的改进算法——CSD-KNN
当样本被错分时会产生代价,分为两种情况:多数类误分为少数类的代价,以及少数类误分为多数类的代价。当样本正确分类时,代价值为0。传统的学习算法默认两种误分类情况是等价的,但是在实际情况中,两者必须区分开来。代价敏感思想基于期望代价最小的原则对分类器作出调整。MetaCost方法根据样本属于每一类的概率与其对应的误分代价值之积,得到一个具有最小期望代价的分类结果。本文改进了传统KNN算法中每个样本权重相等的弊端,基于每一类中近邻点与样本之间的平均距离将样本的误分代价值以函数的形式表现出来。假设待测样本Xi与邻近样本Xj(j=1,2,…,K)的距离为dij,为了便于说明,这里的dij取归一化后的数值,属性的归一化方法为:
将每一类中近邻样本与测试样本之间的平均距离作为具体的自变量因子,通过对数函数的形式表示基于距离的代价函数,距离越小,误分代价值越大,并且随着距离的缩小,样本的误分类代价值以指数形式上升。样本属性维度值w用来将对数函数的真数的值控制在0~1,避免出现负的代价值。通过样本属性维度值w样本属性维度值是希腊字母ω,还是英文字符w(式3中写的是小写w)?书写需要统一。将对数函数的自变量取值范围控制在0到1之间,避免函数值为负。样本属性维度值ω用来将对数函数的真数的值控制在0-1之间,避免出现负的代价值。现改为:通过样本属性维度值ω将对数函数的自变量取值范围控制在0-1,避免函数值为负。在这种思想的指导下构造出基于距离的代价函数如下所示:
其中:m为某一类近邻样本点的个数;α值为距离对样本分类的影响因子,值越小表明距离对样本分类结果影响越大;c为少数类与多数类误分类代价的比重。
基于最小风险的贝叶斯决策的形式化目标[17]为:
其中:R(yi|x)为样本x分类到yi中的风险构造函数,F(yi,yj)为类别yi误分为yj的代价,P(yi|x)为样本x属于类别yi的后验概率。
定理1 在KNN算法中,若K为近邻样本的数量,m为样本中某一类的总体数量,则样本属于该类的概率为m/K。
以样本比例逼近概率:V为K个样本点包围的最小超球的体积,m为数据集中类别yi的个数,得到类条件概率密度:
其中N为样本总数。
因此得到符合贝叶斯决策理论的代价敏感算法——CSD-KNN,表现形式为:
根据文中描述的分类器,具体的实现过程如算法1所示。
3 集成代价敏感的CSD-KNN算法
Boosting算法的基本思想是对每一轮迭代得到的分类器赋予不同的权重,使得分类器更注重分类难度大的样本,最终得到一个基分类器ht(x)的线性集合H(x)。计算方式为Ht+1(x)=Ht(x)+α*t*ht(x),下标的书写不规范,t和t+1是否应该为下标,请明确。回复:修改正确传统的Boosting算法的最大特点是随着迭代次数的增长,分类错误率以指数速度下降。将Boosting算法应用到代价敏感学习中,可以得到以错分类代价最低为目标的代价敏感分类器,代价敏感的Boosting算法是代价敏感学习方法中的一个重要组成部分。目前人们已经提出了AdaCost、AdaC3[18-19]等代价敏感Boosting算法,但是这些算法通过启发式策略向AdaBoost算法的加权投票因子中加入代价因子,有可能破坏算法的Boosting特性[20]。AdaBoost算法具备非对称学习能力,在算法进行迭代之前,根据样本类别赋予样本代价权重:
根据式(8)可以实现代价敏感的Boosting算法。本文对此过程进行了改进,在赋予样本初始化代价权重后,对代价敏感的基分类器进行训练,实验结果表明,集成改进后的代价敏感算法,减小了总体误分代价,代价敏感性更好。
程序后
4 实验结果与分析
实验测试数据集为UCI官网上的公开数据集(http://archive.ics.uci.edu/ml/index.php),在其中选取了5个典型的不均衡的分类数据集,实验中将非数字型数据用数值表示,并对所有数据进行归一化处理,使之成为能够被KNN算法加载的数据集。对每个数据集进行了10折交叉法,每次取其中9个数据集作为样本集,剩余1个数据集作为测试集,实验结果取其平均值。
4.1 度量标准
代价敏感的学习过程中,提高高代价样本的分类准确率显得更为重要,通过对少数类的召回率(Recall)、平均误分代价(AvgCost)和高代价错误率(记为High-rate)进行代价敏感性能比较,将多数类作为正例得到的混淆矩阵[21]如表1所示。
4.2 样本重采样实验
第一个实验是将数据集按照近邻原则进行删减,降低多数类样本的边界密度,使得样本分布趋于平衡。表2为样本集删减前后少数类的比重对比,其中的rate为少数类在整个样本中所占的比重,Before、Later为数据删减前后的样本数与维数的向量表示。
实验过后,少数类的比重rate较原先的数据集提升了近17个百分点,表2中的结果表明,删减过后的样本分布更加均衡,少数类和多数类的比例接近1∶1,近邻删减法可以有效降低多数类的样本密度。
4.3 算法性能对比
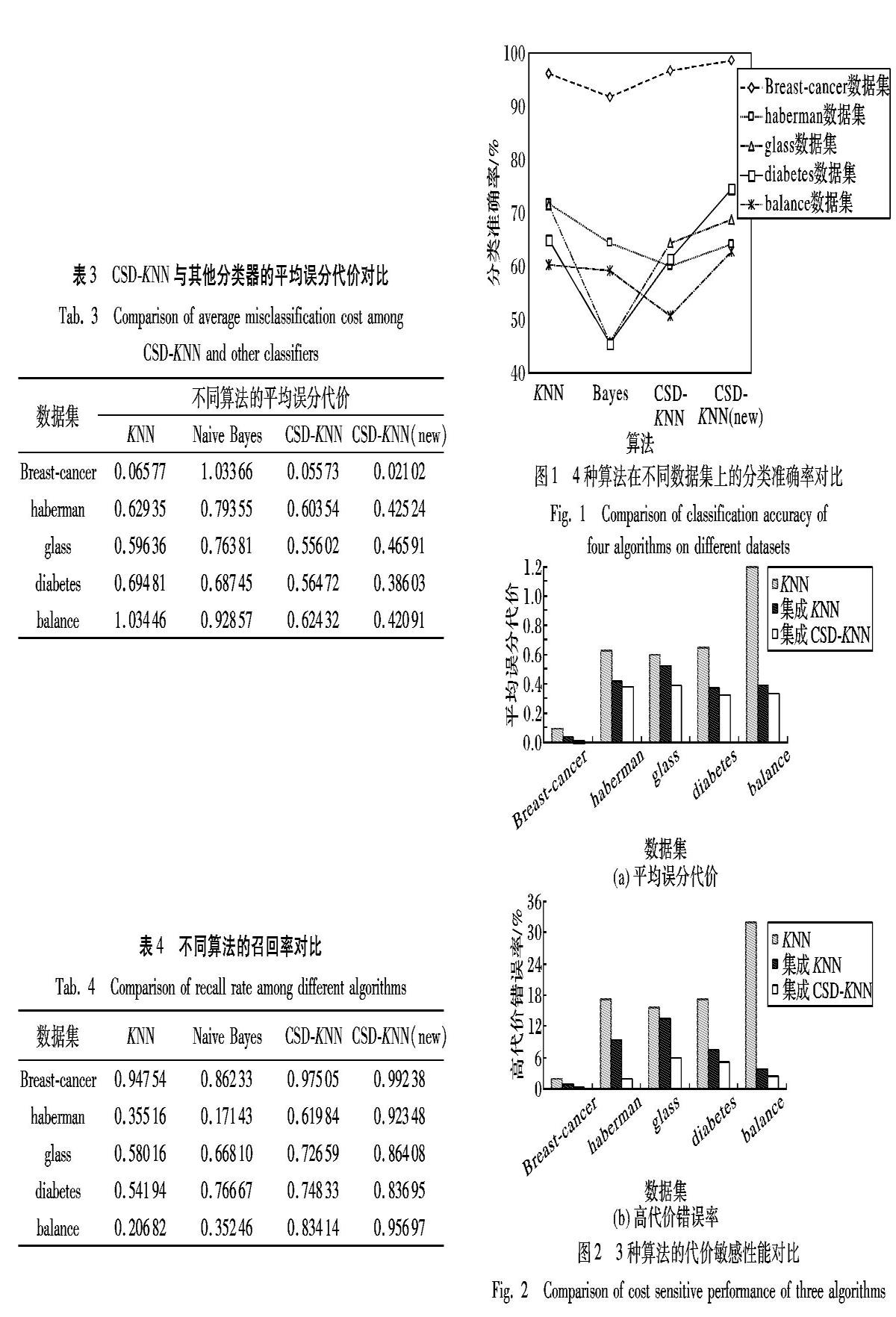
在第二个实验中,将CSD-KNN算法与传统的KNN和贝叶斯分类器进行代价敏感性能比较,并综合分析算法的分类准确率。整个实验中的数据是以K=5,α=0.5,误分代价比重c=3得出的数据,其中CSD-KNN(new)表示在按近邻策略删减之后的样本集上进行性能分析的结果。表4中的衡量指标为Recall值,少数类的召回率表示少数类的分類准确率,Recall值越大,表示算法对少数类的分类精确率越高。
相比KNN算法下降了12.33个百分点,对数据集应用近邻删减法和代价敏感改进,算法的平均误分代价下降了37.87个百分点。实验结果表明,与传统的KNN算法和朴素贝叶斯算法相比,改进后算法的代价敏感性能明显优于传统算法。
从表4中可以直观地看到,改进后的算法对少数类的正确分类更为注重,具备更强的代价敏感特性。改进后的算法是代价敏感的,并且根据KNN进行近邻删减后的数据集也可以提升算法的代价敏感性。
从图1中可以发现,CSD-KNN算法是一种牺牲了部分分类准确率达到对少数类的高召回率的代价敏感分类算法。相比KNN算法:改进后的算法的分类准确率降低了约6.4个百分点,对于整体的分类效果影响不大;而对于少数类的召回率提高了约25.4个百分点,性能明显优于传统的KNN算法。同时,基于样本删减策略的CSD-KNN算法可以有效提高算法的分类准确率,相比KNN算法,改进后算法的分类准确率提升了约0.8个百分点,同时召回率也明显提升。实验证明,CSD-KNN算法具备代价敏感性,并且对于整体分类准确率的影响也较小,而样本删减策略可以有效地减少分类错误。基于样本删减策略的CSD-KNN算法在性能上明显优于传统的KNN算法。
4.4 CSD-KNN算法集成测试
在第3个实验中,集成算法在调整权重之前,给每个样本赋予代价初值使得集成后的算法具备代价敏感性,将KNN算法与集成的KNN算法以及集成代价敏感的CSD-KNN算法进行性能比较,分析对代价敏感的基学习器进行集成能否得到代价敏感性能更好的集成算法,实验结果如图2所示。
实验结果表明,对权重赋代价初值可以得到代价敏感的集成算法,而相比集成KNN算法,对CSD-KNN算法进行集成的高代价错误率降低了4.01个百分点,证明对代价敏感的基分类器进行集成,对于降低平均误分类代价效果更好。
在整个实验中对于少数类的分类准确率,改进后的算法相比KNN算法提升了38.8个百分点,同时在整体性能上也优于原先的算法,而集成这种代价敏感的基分类算法使得算法的代价敏感性能更好,高代价错误率降低了14.01个百分点,平均误分代价降低了31.35个百分点。
5 结语
在实际的应用中,针对不同的类别情况赋予不同的代价显得更为可行,代价敏感学习算法在对不均衡数据集进行分类时性能实际意义明显优于传统的分类算法。本文提出的CSD-KNN集成算法不仅提出了一种应用于不均衡数据集的样本删减策略,同时还提出了一种代价敏感算法,通过不断的迭代使得分类器的错分代价降至最低,相比KNN算法,本文算法的高代价错误率和平均误分代价都显著降低了,同时整体分类性能更好。
需要指出,CSD-KNN算法在软件缺陷预测、文本分类、聚类分析等诸多领域有着良好的效果,但是本文研究也存在不足之处,在进行样本选择时,压缩样本数量、选取典型样本、大幅度减少样本集数量将是下一阶段的研究目标。
参考文献 (References)
[1] 熊冰妍,王国胤,邓维斌.基于样本权重的不平衡数据欠抽样方法[J].计算机研究与发展,2016,53(11):2613-2622.(XIONG B Y, WANG G Y, DENG W B. Under-sampling method based on sample weight for imbalanced data [J]. Journal of Computer Research and Development, 2016, 53(11): 2613-2622.)
[2] CHENG F, ZHANG J, WEN C. Cost-sensitive large margin distribution machine for imbalanced data classification [J]. Pattern Recognition Letters, 2016, 80: 107-112.
[3] CAO C J, WANG Z. IMCStacking: cost-sensitive stacking learning with feature inverse mapping for imbalanced problems [J]. Knowledge-Based Systems, 2018, 150: 27-37.
[4] PINAR T, LALE O, SINEM K, et al. A cost-sensitive classification algorithm: BEE-miner [J]. Knowledge-Based Systems, 2016, 95: 99-113.
[5] LOMAX S, VADERA S. A survey of cost-sensitive decision tree induction algorithms [J]. ACM Computing Surveys, 2013, 45(2): 16-50.
[6] 陈永辉,岳丽华.特征敏感的点云重采样算法[J].小型微型计算机系统,2017,38(5):1086-1090.(CHEN Y H, YUE L H. Point cloud resampling algorithm of feature-sensitivity [J]. Journal of Chinese Computer Systems, 2017, 38(5): 1086-1090.)
[7] 陈海鹏,申铉京,龙建武.采用高斯拟合的全局阈值算法阈值优化框架[J].计算机研究与发展,2016,53(4):892-903.(CHEN H P, SHEN X J, LONG J W. Threshold optimization framework of global thresholding algorithms using Gaussian fitting [J]. Journal of Computer Research and Development, 2016, 53(4): 892-903.)
[8] 李勇,刘战东,张海军.不平衡数据的集成分类算法综述[J].计算机应用研究,2014,31(5):1287-1291.(LI Y, LIU Z D, ZHANG H J. A survey of integrated classification algorithms for unbalanced data [J]. Application Research of Computers, 2014, 31(5): 1287-1291.)
[9] DOMINGOS P. MetaCost:a general method for making classifiers cost-sensitive[C]// Proceedings of the 5th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 1999: 155-164.
[10] 周宇航,周志華.代价敏感大间隔分布学习机[J].计算机研究与发展,2016,53(9):1964-1970.(ZHOU Y H, ZHOU Z H. Cost sensitive large interval distribution learning machine [J]. Journal of Computer Research and Development, 2016, 53(9): 1964-1970.)
[11] BAHNSEN A C, AOUADA D, OTTERSTEN B. Example-dependent cost-sensitive decision trees [J]. Expert Systems with Applications, 2015, 42(19): 6609-6619.
[12] GHAZIKHANI A, MONSEFI R, YAZDI H S. Online cost-sensitive neural network classifiers for non-stationary and imbalanced data streams [J]. Neural Computing and Applications, 2013, 23(5): 1283-1295.
[13] 付忠良.多标签代价敏感分类集成学习算法[J].自动化学报,2014,40(6):1075-1085.(FU Z L. Multi-tag cost sensitive classification integrated learning algorithm [J]. Acta Automatica Sinica, 2014, 40(6): 1075-1085.)
[14] 王茜,杨正宽.一种基于加权KNN的大数据集下离群检测算法[J].计算机科学,2011,38(10):177-180.(WANG Q, YANG Z K. An outlier detection algorithm for big data sets based on weighted KNN [J]. Computer Science, 2011, 38(10): 177-180.)
[15] FREUND Y, IYER R, SCHAPIRE R, et al. An efficient boosting algorithm for combining preferences [J]. Journal of Machine Learning Research, 2003, 4 (6): 170-178.
[16] 胡小生,钟勇.基于边界样本选择的支持向量机加速算法[J].计算机工程与应用,2017,53(3):169-173.(HU X S, ZHONG Y. Support vector machine acceleration algorithm based on boundary sample selection [J]. Computer Engineering and Applications, 2017, 53(3): 169-173.)
[17] 蒋盛益,谢照青,余雯.基于代价敏感的朴素贝叶斯不平衡数据分类研究[J].计算机研究与发展,2011,48(增刊I):387-390.(JIANG S Y, XIE Z Q, YU W. Cost-sensitive naive Bayesian unbalanced data classification [J]. Journal of Computer Research and Development, 2011, 48(Suppl I): 387-390.)
[18] SUN Y, KAMEL M S, WONG A K, et al. Cost-sensitive boosting for classification of imbalanced data [J]. Pattern Recognition, 2007, 40(12): 3358-3378.
[19] SUN Y, WONG A K, WANG Y. Parameter inference of cost-sensitive boosting algorithms [C]// Proceedings of the 4th International Conference on Machine Learning and Data Mining in Pattern Recognition. Berlin: Springer, 2005: 21-30.
[20] 曹瑩,苗启广,刘家辰,等.具有Fisher一致性的代价敏感Boosting算法[J].软件学报,2013,24(11):2584-2596.(CAO Y, MIAO Q G, LIU J C, et al. Fisher consistent cost sensitive Boosting algorithm [J]. Journal of Software, 2013, 24(11): 2584-2596.)
[21] 周志华.机器学习[M].北京:清华大学出版社,2018:30-33.(ZHOU Z H. Machine Learning [M]. Beijing: Tsinghua University Press, 2018: 30-33.)
猜你喜欢
农机使用与维修(2016年12期)2017-01-17
电脑知识与技术(2016年28期)2016-12-21
电子技术与软件工程(2016年20期)2016-12-21
科技视界(2016年23期)2016-11-04
科技视界(2016年23期)2016-11-04
科教导刊·电子版(2016年14期)2016-06-25
科技视界(2016年14期)2016-06-08
财税月刊(2016年2期)2016-05-17
