
柔性物流调度高空载率规避策略
2019-09-04 06:21:14许彤彤
阜阳师范大学学报(自然科学版) 2019年3期
郑 翔 ,孙 霞 ,许彤彤
(1.安徽理工大学 电气与信息工程学院,安徽 淮南 232001;2.阜阳师范大学 商学院,安徽 阜阳 236037)
数据显示占我国70%以上的货物是通过公路运输的,而物流货车空载率高达40%[1],这就使得物流运输效率低下。物流供应链的负载是产品,因而对其追踪非常重要[2]。
针对文献[1]中提出的问题,本文提出一种基于NBIOT技术的物流调度系统。用智能云平台实现终端设备监控,以及数据分析,这一过程可大大降低物流车空载率。降低空载率的思想是当物流车卸货后就给其装入货物使物流车保持满载状态。当物流车到达中转站后卸下一定量的货物,立即前往各个货源地装货。在这一过程中使用蚁群算法为物流车设计遍历货源地路线,因为算法本身都存在自身的缺陷,倘若使用基本蚁群算法,得到的路线并不是最优的。在此对蚁群算法进行优化,文献[3-7]提出的优化方法中均没有考虑到一个关键点,即在蚁群算法实现的初期,路径上存在的信息素量很少,这样就加大了蚁群算法搜索的盲目性,很容易使算法陷入局部最优。本文先对蚁群算法进行预迭代若干次,通过学习知道哪条路径上存在信息素。在正式迭代的过程中,路径上加入一定量的信息素。这样就可解决算法迭代初期的盲目性问题。实验证明该方法可以规避局部最优的情况,寻找到更优路径。
1 系统总体设计方案
传统的物流行业采取的方式是给每个物流车事先规定好行驶路线,到每个中转站后卸下一部分货物,待货物卸空以后空车返回。这样就造成了极高的物流空载率。或者是从起点到终点物流车是直达的,中途不停车卸货,这样就会占用过多的物流车资源。
作为本物流系统重要一环的物流车可看做系统终端,许多终端构成庞大的终端网。每个终端作为感知层都会采集物流车的位置信息。然后将此信息上传给华为云平台。华为云平台又可与私有云平台通信进行相应的信息交流。私有云平台通过Apache服务器、MySQL,和PHP来搭建,它将对从华为云平台获取的信息进行数据库构建[8-12]。当买家提交订单以后,卖家就会将买家和卖家的位置信息以及物流包裹的体积值提交至私有云平台建立数据库,当物流车到达一个中转站以后卸下相应的货物。这时私有云平台会根据卸下包裹的体积值计算出当前物流车空着的体积,然后在数据库检索与该物流车当前位置最近的几个卖家发货点,并且买家所处的位置也在该物流车途经的中转站内,即对卖家发货包裹的体积值进行累加,当总体积值刚好大于此物流车空着的体积时,选取累加最后一次之前所有的包裹(不含最后一次),这些包裹所处的位置就是物流车的取货点。为了对每个卖家点进行高效遍历,采用蚁群算法设计好物流车的遍历路线,私有云平台将此路线发送给物流车司机的移动终端。当遍历一圈以后回到中转站位置,此时物流车恢复满载状态。接着驶往下一个中转站,重复上一个中转站的过程,当到达终点时,将物流车卸空以后以相同的方式让物流车满载。物流车从终点到起点重复从起点到终点的过程。图1为系统总体设计图。
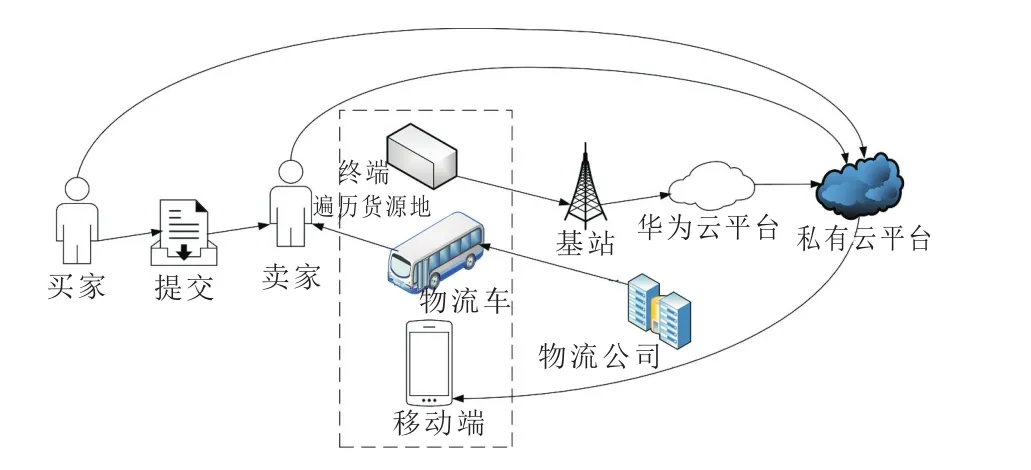
图1 系统总体设计图
2 终端设计方案
终端作为本系统至关重要的一部分,它是系统正常运行的关键。终端位于每个物流车上,它负责采集物流车位置信息。终端的控制中心采用ST公司设计的一款具有低功耗特性的开发板STM32L476RGT6。GPS模块采用 Air530,并将其天线置于车厢外。图2为终端硬件框图。
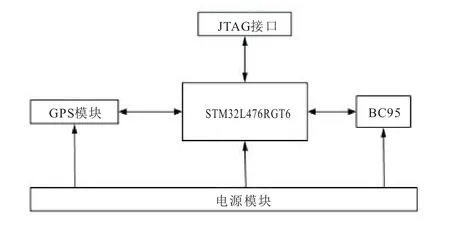
图2 终端硬件框图
3 为物流车遍历货源地设计行驶路线
3.1 用蚁群算法解旅行商(TSP)问题
蚁群算法(ant colony optimization,ACO)是由Marco Dorigo在1992年提出的[13]。它是一种自适应算法,其动态更新特性能很好解决TSP(traveling salesman problem)问题[14-16]。具体过程:首先可以把m个蚂蚁随机放置在n个货源地,根据(1),(2)式算出状态转移函数从而确定行驶路线,将每条路径上的起始信息素定为τij(0),并且将遍历过的货源地装入禁忌表tabuk中,将所有需要遍历的货源地放在一个集合C中,蚂蚁在一次周游货源地过程中,待访问货源地属集合allowed。
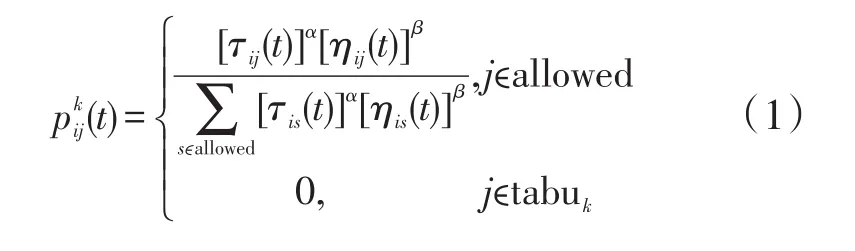

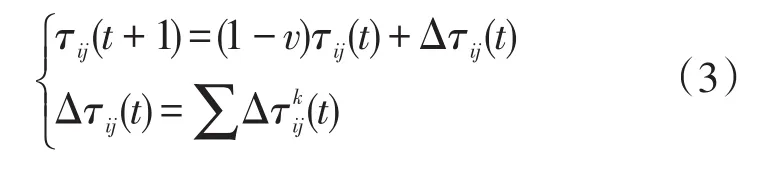
v为挥发因子,Δτij(t)表示所有在一次遍历过程中经过i→j路径的蚂蚁释放的信息素量,表示第k只蚂蚁在一次遍历中经过i→j路径释放的信息素量,具体如(4)式所示。

Q为信息素素总量,Lk为第k只蚂蚁循环一周走的路径长度,随着信息素矩阵迭代更新,逐渐收敛于最短路径。
3.2 粒子群算法
1995年提出了粒子群算法(particle swarm optimization,PSO)[17]是一种基于群体智能理论的全局优化方法[18-20]。他们通过观察鸟群的飞行行为,以此受到启发。通过搜索自身的最佳位置和群体最佳位置,使自身不断向最佳位置靠拢,从而达到寻优的目的。粒子一般有两种状态,运动速度和位置。PSO进化规则如(5)所示。
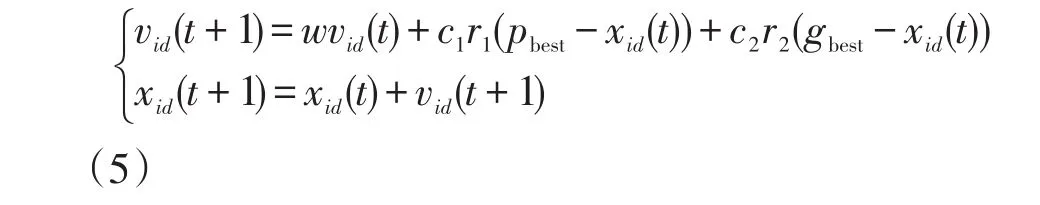
其中:d表示粒子维度;xid表示第i个粒子位置;vid表示第i个粒子速度;pbest表示粒子自身最优状态;gbest表示整个粒子群最优状态;w表示粒子的惯性权重;c1,c2分别为学习因子;r1,r2均为[0,1]的随机数。
4 算法改进
在蚁群算法中起关键性因素的就是信息素,而在迭代的初期路径上的信息素很少,这时在路径寻优的过程中信息素指导意义就不大,蚂蚁在很大程度上还是在随机摸索。为了凸显粒子群算法的学习作用,采用粒子群算法优化蚁群算法可以得到好的效果,将蚁群算法中的蚂蚁也变成会学习的蚂蚁,在迭代初期就给其加入一定量的信息素,避免路径寻优的盲目性。优化思想如下:
(ⅰ)先取一个蚂蚁数量较大的蚂蚁总群,蚂蚁数量为M,将其分成n个数量均为m的蚂蚁子群(舍弃多余的蚂蚁)。每个蚂蚁子群看成粒子群的一个粒子,这些粒子可记为δ1,δ2,……,δn。
(ⅱ)现随机取一个蚂蚁子群,对其使用基本蚁群算法,迭代X(此时X取10)代后得到最优路径ℓbest1,以此类推最优路径分别 ℓbest2,ℓbest3,…,ℓbestn再从中挑选出最优路径,记为ℓbest。将每个蚂蚁子群在路径上释放的信息素总量都定为Q,根据(6),(7)式分别算出子群最优和总群最优路径片段上的信息素量。

(ⅲ)将每个子群最优路径上信息素取平均值

Δτ′ave(i→j)(t)是子群信息素量平均值。
(ⅳ)假设货源地的数量为n,然后从蚂蚁总群中随机取数量为n只蚂蚁进行蚁群算法。将n只蚂蚁随机分配至个n货源地,然后根据式(1)计算i→j的状态概率选择概率,根据概率大小选择下一个访问的货源地。i→j路径上信息素量计算公式
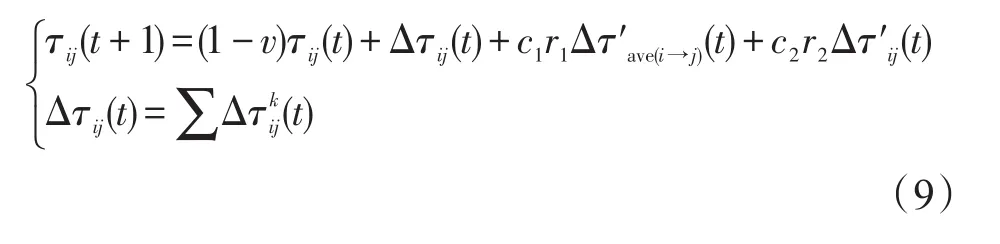
5 仿真与分析
5.1 实验中参数的确定
参数的选取对寻优结果影响很大,在这里进行合适参数选取。现已将蚁群分成数量为n的小蚁群,即n个粒子,每个粒子是一组五维参数域,可设为p(α,β,v,c1,c2),分别对每组参数进行基本蚁群算法,得出单个粒子的最优pbest,和粒子群的最优gbest,我们将粒子群最优对应的参数作为该改进算法的参数。如表1所示为具体参数设置。

表1 参数设置
5.2 实际场景仿真
在物流车遍历各个货源地的过程中就需要为其设计出合适的路线,以使其在用时最短最高效的情况下遍历各个货源地使物流车达到满载的状态。本实验将对17个货源地使用改进后的蚁群算法进行路线图设计。改进前后的最优路径如图4,而改进前后的全局最优解随迭代次数变化情况如图5。改进前后的路径长度分别为882.45和874.80。
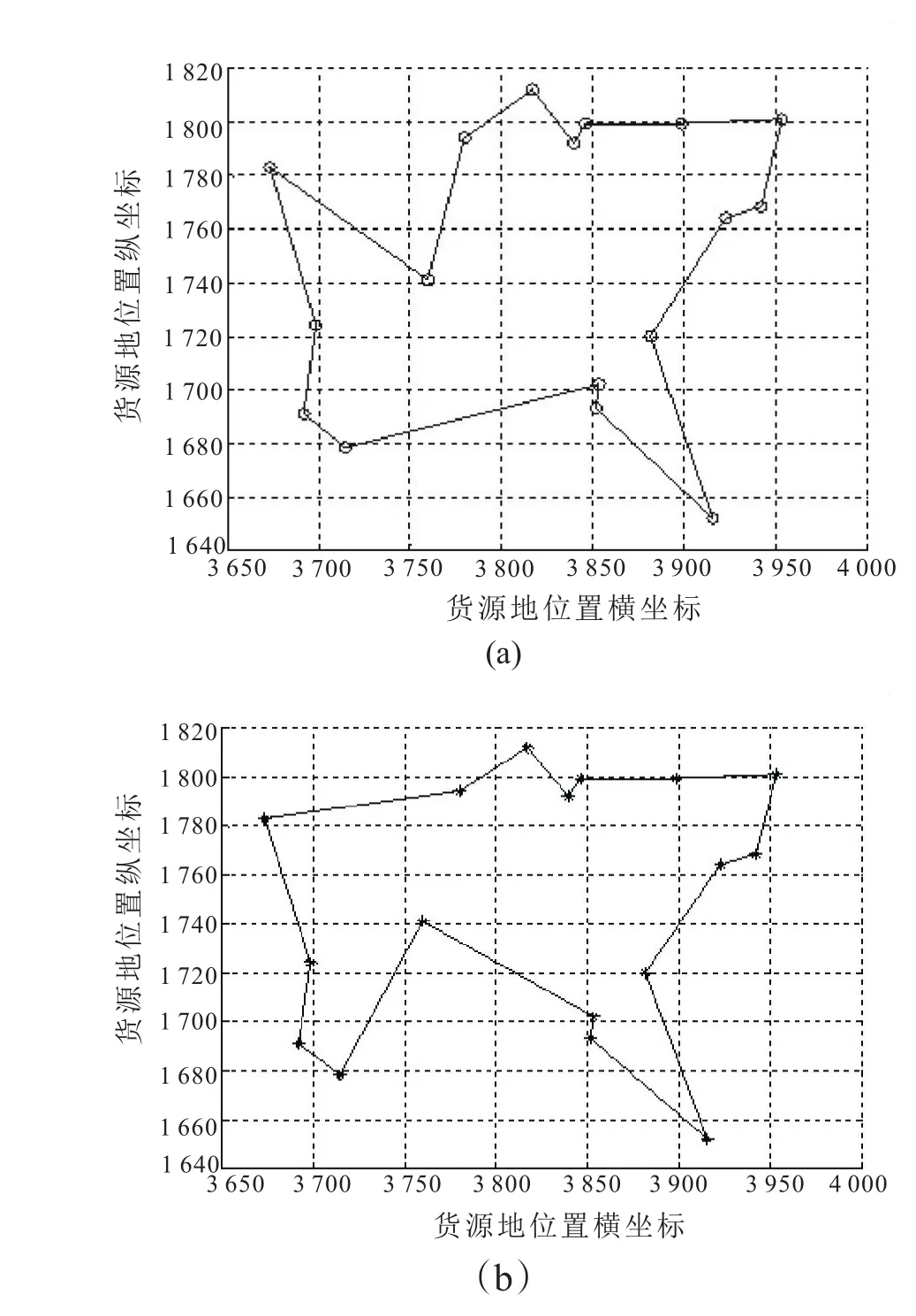
图4 最优路径图 (a)基本蚁群算法;(b)改进后算法
5.3 仿真结果分析
一种算法在迭代次数足够大时,倘若其没有陷入局部最优,它就能够找到真实最优解。因此实验中采用极端操作对改进前后的蚁群算法在寻优方面作对比。将两种算法的迭代次数都设置为5 000次。由图4可以看出基本蚁群算法显然已经陷入了局部最优,在迭代足够大的次数之后找到的最优解和真实最优解相比还是有差别的。从图5可看出基本蚁群算法迭代2 300次左右找到其最优解,而改进后的蚁群算法在迭代500次就找到了其最优解。所以不论从寻优精度还是从收敛速度方面看,改进后的蚁群算法都要远远优于基本蚁群算法。
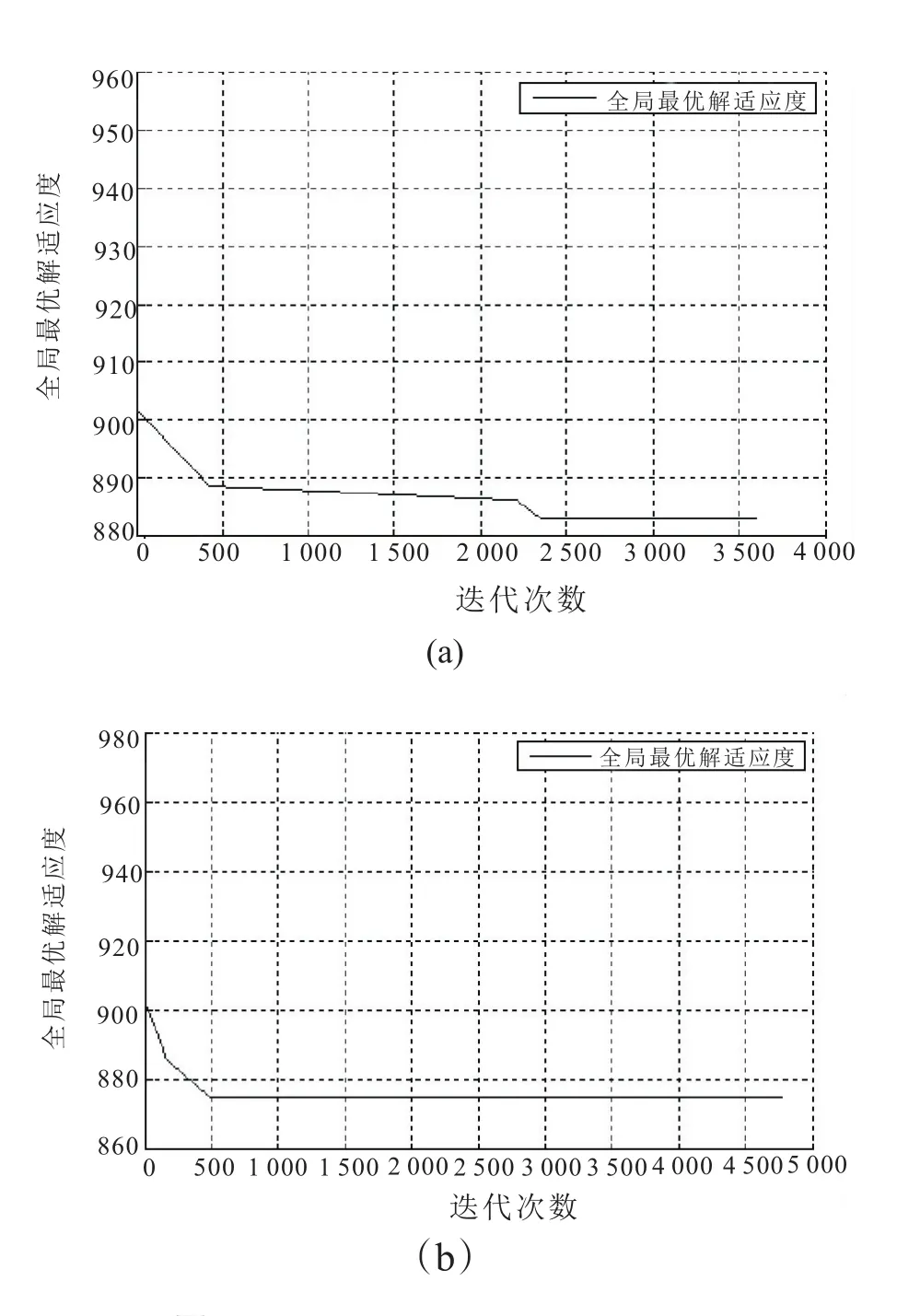
图5 全局最优解随迭代次数变化图
6 小结
本文提出了一种针对当前公路物流车空载率高的解决办法,对文章提及的一整套降低空载率的操作流程做了直观清晰的阐释。降低空载率的关键就是物流车在每次卸货后都会遍历货源地把车装满,蚁群算法能很好的满足这一要求,但是常规的蚁群算法有很大的局限性,在实际应用中不能使物流始终按照最优路线行驶,所以在前人的研究基础上对该算法进行了改进,提出了一种思想,可以在蚁群算法初期给其提供一定量的信息素来避免其路线寻优盲目性。文章涉及的物流调度思想在现实的物流运输中非常具有应用价值。
猜你喜欢
数学年刊A辑(中文版)(2022年1期)2022-08-20 08:50:50
数学年刊A辑(中文版)(2021年4期)2021-02-12 01:21:00
减速顶与调速技术(2020年2期)2020-11-16 00:57:32
中国化肥信息(2020年9期)2020-03-29 02:33:54
国际贸易(2018年2期)2018-04-04 02:16:06
少儿科学周刊·儿童版(2017年5期)2017-06-29 01:27:44
学苑创造·A版(2017年3期)2017-04-27 13:17:17
哈尔滨师范大学自然科学学报(2015年1期)2015-04-19 06:55:30
数学年刊A辑(中文版)(2014年5期)2014-11-01 05:43:34
农村百事通(2014年6期)2014-10-14 10:45:53
