
基于句法与语义特征分析的朋友关系挖掘
2019-09-04 06:21:10王娜娜张顺香
阜阳师范大学学报(自然科学版) 2019年3期
王娜娜,张顺香
(安徽理工大学 计算机科学与工程学院,安徽 淮南 231001)
目前,越来越多的网民选择通过注册微博与他人进行互动,使得微博文本中存在大量人物间的社会关系,而挖掘朋友关系能够更好地加快社会网络的发展。从海量微博文本中挖掘朋友关系,可以为广大用户提供社区服务,帮助用户构建和扩展“朋友圈”,以及为商家建立信息推荐系统实现盈利模式或者扩展潜在客户等。
然而,如何从海量微博文本中挖掘朋友间存在的社会关系成为目前亟需解决的问题。一个有效挖掘微博朋友关系的方法需要考虑:如何获得更为全面的朋友关系特征描述词;由于人物关系类型繁多,如何提高抽取准确率;当微博语句中实体对超过一对时,如何确定人物实体对等问题。
针对上述问题,本文提出一种基于句法与语义特征分析的朋友关系挖掘方法。其主要目的是提高微博中朋友关系挖掘的准确性和高效性。流程图主要分为2部分,具体挖掘流程如图1。
(ⅰ)有效扩展朋友关系描述词库。首先,针对朋友关系得到其关系描述词之一。然后,综合《知网》和《同义词词林》的相似度计算结果,得到较为准确的朋友关系描述词库。
(ⅱ)面向文本数据实现朋友关系挖掘。在步骤(ⅰ)的基础上,对筛选后的微博文本运用核心谓词、依存句法以及语义分析等特征进行处理,从微博文本中挖掘出朋友关系。
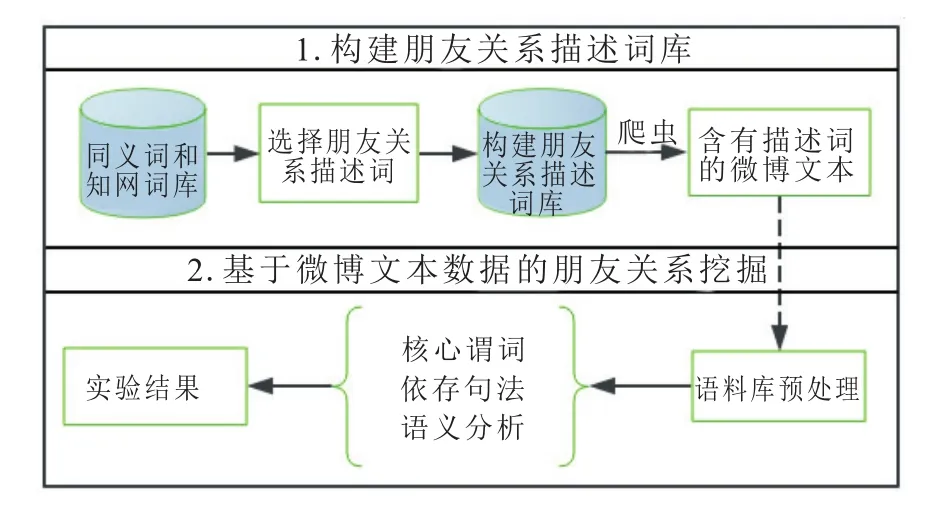
图1 人物朋友关系挖掘过程
1 相关工作
人物关系抽取属于实体关系抽取的一部分,实体关系抽取的主要目的是通过相关技术挖掘出现在同一文本中的两实体间存在的语义关系。即实体关系抽取方法可用于人物关系抽取方法中。近年来,在解决实体关系抽取过程中,国内外常采用的方法主要分为三类。
(ⅰ)基于模式匹配的人物关系抽取方法是构造若干基于词语、词性或语义的模式集合并存储起来,将预处理文本与模式集合中的模式进行匹配。潘云等人引入标签传播算法实现未标记人名对的关系匹配,提出一种利用中文在线资源构建中文人物关系抽取系统的方法[1]。孔兵等人通过提取特定关系实体上下文信息及句子的结构特征对特定关系单独训练分类模型的人物关系抽取方法[2]。Choi等人提出一种基于依赖核的支持向量机(support vector machines,SVMs)的社会关系提取系统[3]。Vo等人提出一种基于子句的文本文档中的信息提取框架[4]。
(ⅱ)基于自动训练的人物关系抽取方法是通过特定的机器学习算法,在标注的语料上建造分类模型,再将其应用到未标注的语料中。黄卫春等人通过计算初始关系元组的关系描述词的信息增益值来确定元组上下文位置以及创建合适的关系抽取模板,利用模板实现Web人物关系的自动提取[5]。Agerri等人开发了 NERC(named entity recognition)系统,能有效使用各种类型的简单词表示其特征[6]。王宏斌等人通过自动调整训练集中实例样本的权重和计算辅助训练样本的迁移能力来提高训练语料质量,间接提高命名实体识别的准确率[7]。郭剑毅等人通过枚举的方式寻求最优的复合核函数参数,并结合多核融合方法和SVM方法对实体关系进行抽取[8]。
(ⅲ)基于知识库的人物关系抽取方法是一种将众多不同领域的知识结合起来进行人物关系的抽取。Zhou等人通过构造丰富的语义关系树,并提出一个对上下文敏感的卷积树核,达到关系抽取的目的[9]。Li等人将词语位置的信息增益与基于HowNet的语义计算相结合[10]。郭喜跃等人在传统方法基础上融入了依存句法关系、核心谓词、语义分析等特征[11]。珠杰等人借助具有丰富人物关系语料的互动百科,提出堆叠降噪自动编码器(stacked denoising autoencoders,SDAs)的人物关系抽取方法[12]。Tao等人提出一种新的基于判别局域对齐(discriminative locality alignment,DLA)子空间学习算法。同时,引入了类似手写汉字识别技术(similar handwritten Chinese character recognition,SHCCR)[13]。
通过对上述各种关系抽取方法的对比分析,本文将实体关系抽取中采用的多种技术有选择性的运用到微博朋友关系挖掘中,提出一种基于句法与语义特征分析的朋友关系挖掘方法。该方法综合运用核心谓词、依存句法以及语义分析等特征进行挖掘,实验结果证明朋友关系抽取的准确率明显提高。
2 构建朋友关系描述词库
本章提出构建朋友关系描述词库的方法,进而达到扩充朋友关系描述词集合的目的。
2.1 微博文本数据预处理
本文在进行朋友关系挖掘前,首先对微博文本数据进行预处理。主要包括删除微博文本中“@”符号、删除符号“#”及符号中的内容、将微博文本中的繁体字转换为简体字、过滤表情符号等。
2.2 构建朋友关系描述词库
为了提高朋友关系挖掘准确率,本文提出综合知网和同义词词林的词语相似度计算方法[14],其中,相似度取值为0~1。对于任意词语T1和T2,依据其在知网和同义词词林中的分布情况,计算出其相似度分别为S1和S2;同时,为S1和S2分别赋予权值 λ1和 λ2,且满足 λ1和 λ2,根据式(1)计算出综合知网和同义词词林的词语语义相似度。
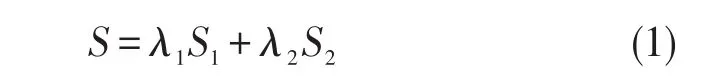
通过采用上述方法进行试验,本文将S=0.7设置为阈值,对朋友关系描述词扩充前后进行了比较。
根据上述的讨论,可以设计算法1来帮助分析本文如何对朋友关系词库进行扩充。

images/BZ_61_278_1051_1187_2055.png
3 朋友关系识别
本章提出朋友关系识别的方法,主要采用哈工大语言技术平台(language technology platform,LTP)对微博文本数据进行朋友关系识别。
3.1 判定核心谓词
大量实验数据表明语句中实体与核心谓词的距离与其他谓词距离存在显著差异,即间接反映出实体间存在一种关系特征。图2所示,例如语句“张勇和李俊成为密友,他们相处的很和睦且经常一起打球”。在图2中,ROOT表示根节点即核心谓词“成为”,谓词还包括“相处”、“打球”,通过公式(2)计算得出,各实体和核心谓词间平均距离为3,与其他谓词间平均距离为5。
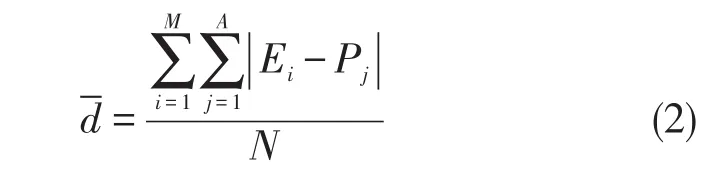
其中,M表示微博语句实体的个数,A表示语句中谓词个数,N表示执行的总次数,Ei表示实体在句中的位置,Pj表示句子中某一谓词的位置。
3.2 依存句法分析
依存句法分析是用来确定句子的句法结构或句中词汇间的依存关系[15],主要通过分析词语之间的搭配关系,进而获得各成分之间存在的联系。本文将核心谓词与依存句法关系作为朋友关系抽取时的一种句法特征,通过核心谓词判定人物实体对。图3所示,例如语句“马云在以色列演讲时表示现在与比尔·盖茨成为非常亲密的好朋友。”其中,“马云”和“比尔·盖茨”表示人物实体,且“以色列”表示地名实体,并与“在”形成介宾关系,核心谓词为“成为”,进而得出实体关系对为(马云,比尔·盖茨)。

图2 核心谓词实例
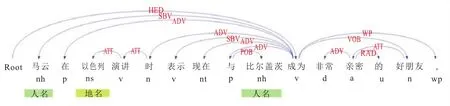
图3 依存句法分析实例
3.3 语义分析
语义分析是指根据语句的句法结构以及句中各实词的词义,预测出能够表达语句意思的某种形式化表示[16]。其主要表现为“谓语—角色”的结构形式。图4所示,例如“张强经常和王娟在微博互动,他们通过互粉成为好友。”该句中谓词是“互动”,动作的施事者(A0)为“张强”,动作的影响者(A1)为“好友”,该句话表明动作实施者带来的影响是成为“好友”。
3.4 综合句法与语义特征
本文在传统人物关系抽取基础上采用哈工大语言处理技术进行改进,进而得到获取更多含有句法、语义特征的语句,具体做法如下。
(ⅰ)语句结构。选择语句中包含人物关系对的微博文本。
(ⅱ)核心谓词。本文根据实体和核心谓词在语句中位置,计算出各实体与核心谓词、其他谓词的距离,并将实体和核心谓词的距离作为关系抽取的特征。当语句中实体对超过一对时,选择与核心谓词距离最近的两个不同实体位置作为本次研究对象。
(ⅲ)依存句法分析。获取语料库中每对实体对之间存在的依存句法关系。
(ⅳ)语义分析。在进行上述操作后,选择哈工大语言处理技术对语句进行语义分析[17],并将分析结果作为朋友关系抽取特征。
图5,例如“王总和张总变成彼此最好的朋友,并且经常合作。”采用传统方法在分词、词性、上下文语境方面,根据特征词“合作”,推断出“王总”、“张总”属于合作关系;本文在传统人物抽取关系的基础上增加了核心谓词、依存句法、语义分析等提取特征,推断出该句核心谓词ROOT为“变成”,两人物实体分别为“王总”、“张总”,通过分析得到表示该句实体对关系为朋友关系。
本章先对微博文本数据进行预处理,接着依次判定核心谓词、依存句法分析、语义分析[18]等操作,综合使用这些方法对微博语句进行分析,显著提高朋友关系抽取的准确率。

图4 语义分析实例
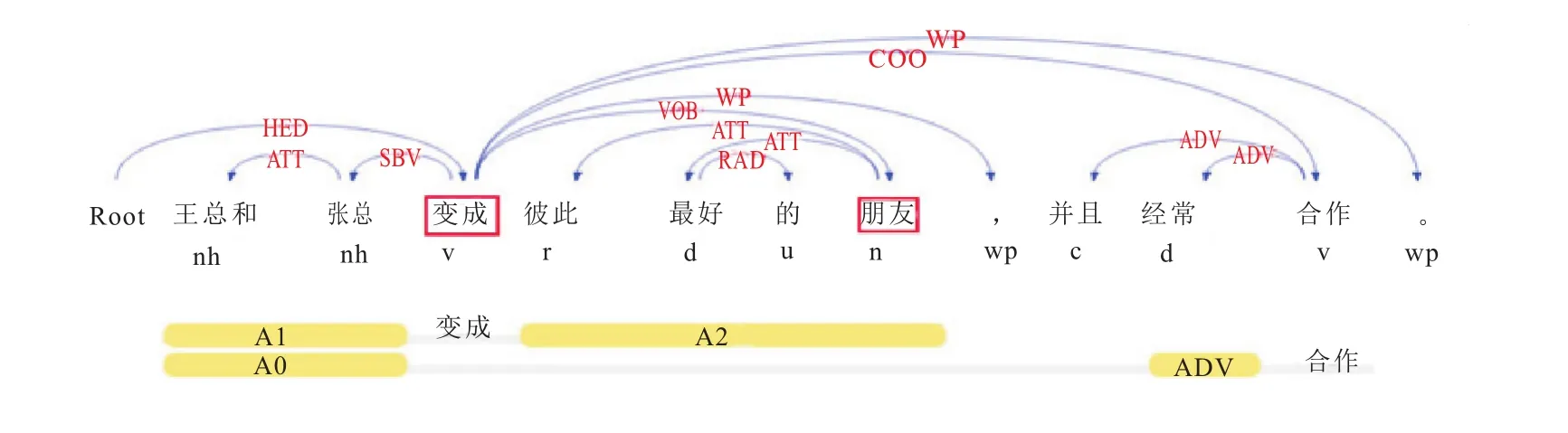
图5 基于句法、语义特征的人物关系实例
4 实验结果
4.1 实验评价指标
本次实验目的是针对微博中朋友关系进行数据抽取。实验评价指标主要包括三方面[19],即准确率P、召回率R以及F1指数。

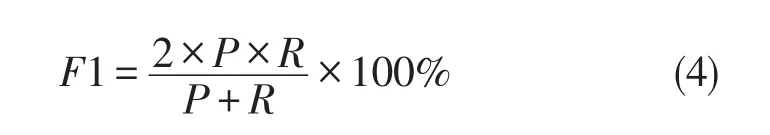
其中,C是正确挖掘的实例个数;T是挖掘出的所有实例个数;S是实验数据集中所有实例个数。
4.2 实验分析
从微博上爬取关于话题“朋友”的微博[20],随机抽取该微博话题下的2 000条微博评论进行朋友关系挖掘,并计算出人物关系对中属于朋友关系的准确率P、召回率R和F1值。实验分为A、B、C、D四组,分别对应核心谓词和依存句法组、语义分析和依存句法组、核心谓词和语义分析组以及语义分析、依存句法和核心谓词组,具体实验结果如图6。

图6 朋友关系挖掘实验结果对比图
由图6可以得到基于微博的朋友关系实验评价结果,A组、B组、C组以及D组实验结果准确率P分别为 68.36%、68.75%、67.97%、69.05%,其中,A组、B组和C组差别不明显,D组实验在综合A组、B组、C组实验特征后,准确率P明显高于A组、B组、C组,朋友关系的挖掘效果更加显著。说明本文提出的方法在挖掘基于微博的朋友关系方面能提供有效的帮助。
实验结果表明,在微博中挖掘朋友关系时,仅仅考虑部分特征不能够提高实验结果的正确率,即需要对语句进行综合考虑,本文将核心谓词、句法依存和语义分析等特征联系起来,通过上述的实验,证明了该方法的有效性。
5 小结
针对如何提高微博中朋友关系挖掘的准确率,本文提出一种基于句法与语义特征分析的朋友关系挖掘方法。实验结果证明,该方法能有效提高挖掘效率和准确性。在未来,朋友关系识别方法可以结合深度学习应用于多种领域,如实体关系挖掘、情感分析、用户推荐等方面。
猜你喜欢
中华诗词(2021年3期)2021-12-31 08:07:22
大连民族大学学报(2021年2期)2021-07-16 05:41:42
——论胡好对逻辑谓词的误读
现代哲学(2020年5期)2020-11-30 17:00:36
新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50
西夏研究(2020年2期)2020-06-01 05:19:12
中华诗词(2018年3期)2018-08-01 06:40:40
中华诗词(2018年11期)2018-03-26 06:41:32
作文评点报·低幼版(2017年44期)2017-11-16 08:24:58
外语学刊(2016年4期)2016-01-23 02:33:55
语文知识(2014年4期)2014-02-28 21:59:52
