
关联规则在健康文本信息挖掘中的应用
2019-09-04 06:21:08白玲玲韩天鹏
阜阳师范大学学报(自然科学版) 2019年3期
白玲玲,韩天鹏
(1.中共阜阳市委党校 教务处,安徽 阜阳 236034;2.阜阳师范大学 计算机与信息工程学院,安徽 阜阳 236037)
关键字:数据挖掘;文本挖掘;关联规则;Apriori;TF-IDF
可穿戴和智能设备的使用以及融合技术的发展促进了健康领域的各种研究。在应用过程中平台生成并保存了大量健康数据,用户可以有效地获取健康信息。此外,对于持续保持健康的生活方式促进医疗保健和健康需求的增加。在医疗保健行业,随着生活习惯的改变,寿命的延长会导致人口老龄化以及慢性疾病护理等,已成为社会问题[1]。在我们的老龄化社会中,大多数老年人患有慢性病,医疗保健和促进健康是他们生活方式的重要因素[2]。在智能健康平台中,使用电子病历[3]和个人健康记录建立医疗保健大数据,并提供基于客户的服务[4-5]。利用公共数据和开放API,医疗保健大数据中心可视化医疗统计信息并分析大数据,以提供医疗支持信息,医疗支持分布,疾病统计和医疗管理支持[6]。企业已经开发出多种基于物联网的智能健康设备,如智能手表、健康带和血糖监测设备[7]。
本文提出了一种利用文本挖掘从健康大数据中提取关联特征信息的方法。该方法从Web收集的健康文档中提取关联特征信息并向用户提供信息。
1 相关研究
1.1 相关大数据技术
大数据分析技术用于从结构化数据,半结构化数据和超出一般数据库管理系统处理范围的非结构化数据中提取和分析有意义的知识和潜在价值[7]。术语结构化数据是指固定字段中保存的数据,包括关系数据库,半结构化数据是指包含元数据和模式的数据,尽管它们不保存在固定字段中,非结构化数据参考未保存在固定字段中的数据,包括文本、视频、语音、图像和多媒体[8]。大数据的定义有时包括其准确性和价值,这取决于指数增加的数据处理类型。大数据分析技术包括现实挖掘[9]、文本挖掘[10]、意见挖掘[11]、社会网络分析[12]和聚类分析[13]。
社交网络的大数据分析用于分析对象之间的关系或关联。结合数学图论,利用在社交网络中个人的识别,可以分析网络中特定人的重要性级别,以及网络中的整体连接性。因此,该方法用于监视社交网络中有影响力的成员,然后可以应用与其相关的信息[14]。大数据中的聚类分析用于计算数据的相似性,以便聚集密切相关的数据。为了确定相似性,使用距离或相关系数。聚类分析方法分为分层和非分层类型。分层方法用于测量单个对象之间的距离,然后组合闭合对象,从而创建树结构[15]。非层次方法用于设置簇的数量,并将与簇的其他成员最相似的对象设置为簇的中心点;群集结果可能会根据设置[16]而有所不同。
1.2 医疗保健大数据信息简介
在美国,使用医疗组织,政府和健康保险公司的综合Health 2.0建立了医疗保健大数据。使用社交网络和云计算,可以收集、保存、集成和管理医疗保健数据。Pillbox由美国国家医学图书馆作为公共服务运营,提供基于医疗保健的大数据药物搜索服务[17-18]。基于大数据,它提供有关用户正在使用的药物的准确信息。一年内发布了超过100万份关于药物的投诉。要解决这个问题,它的成本约为50美元。基于数据的大型药物搜索服务每年可节省约5 000万美元[19]。当用户输入药物的颜色、形状、大小、数量、名称和生产代码时,Pillbox使用其药物搜索引擎提供药物的搜索结果。通过分析Pillbox中收集的信息,可以对当前流行病的来源,污染速度和分布以及其他信息进行大数据分析[20]。
目前,云经常被用于从大数据中提取信息[21]。它们用于可视化网站、博客、新闻和社区文档中的关键字或概念。强调具有高重要性的词然后提供给用户。根据内容的特征,它分为数据云和文本云。通常,数据云用于呈现数字信息,文本云呈现单词。
2 基于健康大数据的文本挖掘提取关联特征信息
信息提取的两个步骤是首先将健康文档收集作为原始数据及其预处理,其次是创建候选语料库。在健康文档收集步骤中,从基于HTML5的URL和页面中提取诸如新闻媒体的代码,分类代码和文档编号之类的信息。使用提取的信息,收集健康文档的文本数据作为原始数据。收集了10 000份健康文件作为原始数据。在收集的原始数据中,排除了1 296个具有低相关性和低置信度的文档。结果,使用了8 704份文件。在最后的8 704个文档中,7 425个文档被用作训练集来提取关联特征信息,剩下的1279份文件用作性能评估的测试集。在候选语料库创建步骤中,通过基于N-gram的形态分析,停止词删除,标记和多义词的分析,将原始数据预处理为候选语料库。
为了收集原始数据,使用数据挖掘工具R 3.4.1的rvest包来删除网页的健康文档。为了提取所收集文档的特征,使用了用于查找重复关键字的典型方法。文档中反复出现的关键字可能非常重要。要提取重复的关键词,有必要进行形态分析,将句子分解为小单位。文档的形态分析结果用于创建语料库。在研究中,进行了n-gram形态分析,被用作典型的自然语言处理方法。
2.1 健康大数据中加权语料库的构成
从形态上分析健康文档以允许其分离成各种单词组合。在预处理的单词组合中,提取术语频率-反向文档频率(term frequency inverse document frequency,TF-IDF)值。具有高 TF-IDF 值的单词预计在文档中是重要的。TF-IDF是从一组多个文档中提取具有高重要性的单词的方法。单词的术语频率(TF)值越高,该单词越重要。确定单词TF的最简单方法是使用文档中单词的频率计数。在仅基于TF的重要性评估中,文档中经常使用的单词“看”,“偶数”,“说”,和“看到”被评估为重要。为了解决该问题,还评估单词的逆文档频率(IDF)的重要性。IDF是在文档集中至少找到一次单词的文档率的倒数。
Web文档具有少量文本,并且针对相同主题的文档经常根据社交环境使用类似主题来编写。因此,与收集的文档集中的共同主题或兴趣相关的单词的TF-IDF值较低。在健康大数据中,“风险”是一个通常在语料库中发现的词,因此其重要性被评估为低。为了克服这个问题,提出了TF-CIDF。在TF-C-IDF方法中,在单词重要性评估中考虑标题标签,散列标签和文档的强调标签。标题标签包括文档的标题。从形态上分析该头行,然后提取核心关键词。散列标记“#”是清楚地表示文档中包含的感兴趣的内容的单词,并且被提取为核心关键字。强调标记用于格式化或强调HTML5中的一段文本。核心语料库是使用title标签,散列标签和强调标签提取的一组核心关键字。在评估从健康文档中提取的单词的重要性的过程中,单词在核心语料库中涉及的程度被认为是权重。
在所创建的核心语料库中,如在公式(1)中那样计算在单词x被扫描n次的情况下的权重。此公式显示从标题标记,哈希标记和强调标记中提取的核心语料库中单词的权重。如果在核心语料库中找到从10个文档中提取的候选语料库的单词3次,则其权重为1+3/10。
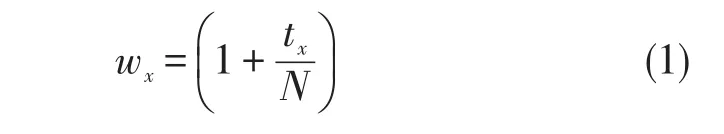
式(1)中,tx表示核心语料库中的单词x的频率计数,N表示文档的总数。
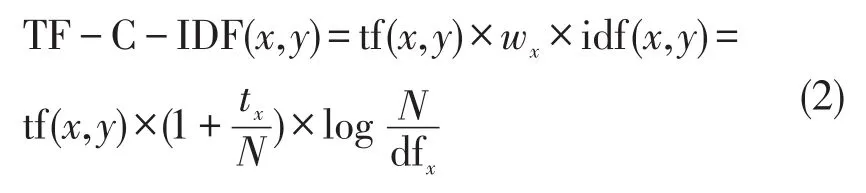
其中:tf(x,y)表示文档y中的单词x的频率;idf(x,y)表示在文档y中至少找到一次单词x的概率的倒数;并且dfx是至少一次找到单词x的文档的数量。式(2)将基于公式(1)的核心语料库的权重应用于TF-IDF。
2.2 文本挖掘关键词之间的关联分析
Apriori挖掘算法[22]用于分析关键字的关联。在每个文档中设计用于关联分析的事务,并且使用从健康大数据语料库中提取的关键字来创建项目。表1列出了每个文件中设计的健康交易。交易ID是凭证编号。使用TF-C-IDF值大于1的关键字创建项目。设计的健康事务以CSV格式保存,以便进行关联分析和高效计算。

表1 每个文件中包含的健康事务
Apriori算法用于查找事务中关键字的关联。它从大数据集中的数据关系中找到关联规则。根据关键词的频率,找到它们的关联规则。在扫描关键字的频率之后,创建候选集。满足最小支持的关键字用于重复创建新的候选集。对于关联分析,使用了数据挖掘工具Weka 3.8.1。在Apriori算法中,最小支持是大于2的值。根据创建的关联规则,分析候选语料库的潜在关联并找到关联关键字。表2显示了健康文档中的一些关联关键字。在表中,规则R0001表示{疲劳,失眠}=>{抑郁},其中,如果规则n的置信度高且其大于1,则该规则是有意义的。
2.3 提取关联特征信息
TF-C-IDF和关联关键字的值用于提取关联特征信息,该关联特征信息由与所收集文档的高度相关联的关键字组成。关键字根据其TF-CIDF值以高优先级顺序对齐。基于对齐的关键字,高关联关键字用于创建关联特征信息。表3显示了从健康大数据中提取的关联特征信息。Rank表示按照使用TF-C-IDF计算的重要性值的降序排序的关键字的优先级。单词“抑郁症”的TF-C-IDF值最高19.753,并且该单词与文档关键词“疲劳”,“失眠”和“心理”相关联。“抑郁症”:{{疲劳&&失眠=抑郁},{疲劳&&精神=抑郁},{精神=抑郁}}。这表明“抑郁症”在健康大数据中非常重要,与吸烟、“疲劳”、“失眠”和“心理”相关的关键词非常重要。使用相关的特征信息,可以向用户推荐有关吸烟,血液循环和肺部疾病的文件。
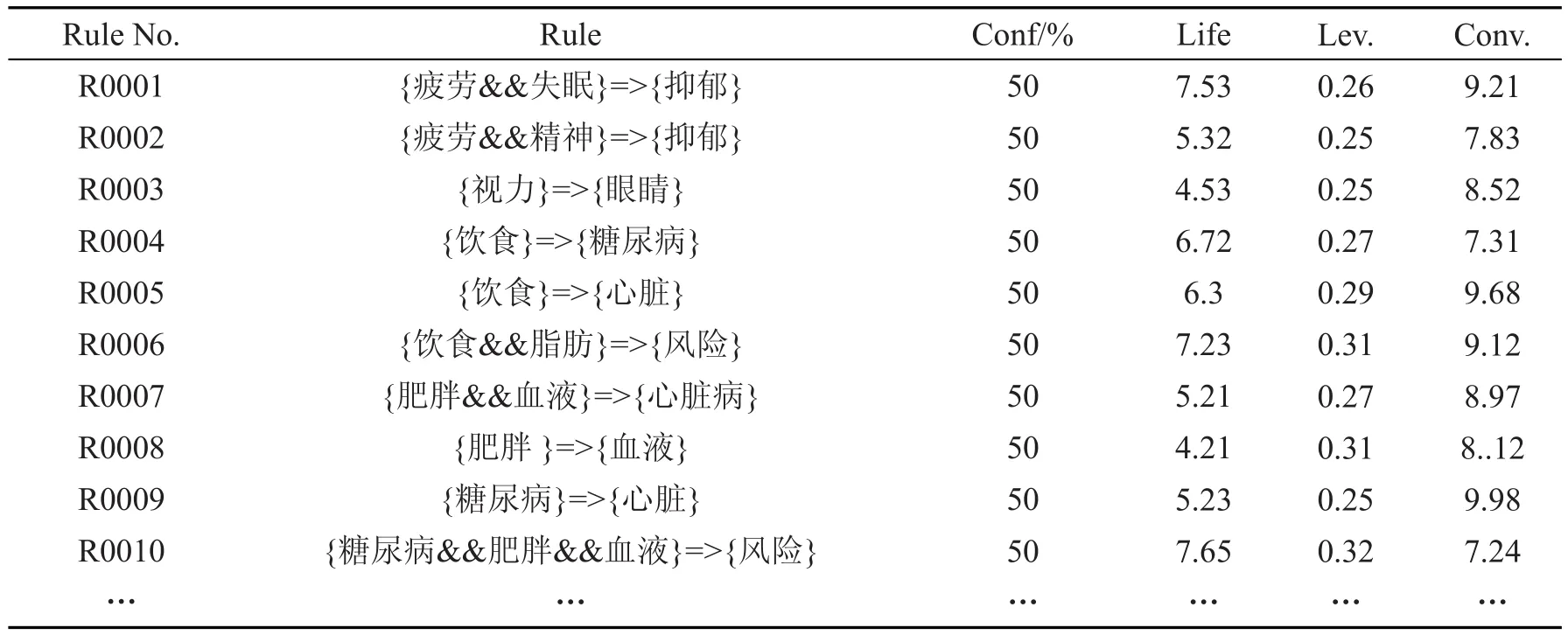
表2 健康文档中的部分关联关键字

表3 健康大数据中提取的部分关联特征信息
3 配置和性能评估
3.1 关联特征信息提取的配置
从收集的健康文档中提取关联特征信息,从文档集中提取代表性或关联关键字。可以根据健康文档的收集时段或范围灵活地改变关联特征信息。抓取和WebBot收集互联网上提供的健康文件的文本数据。收集的文件包括10 000份健康和医疗文件。使用收集的健康文档,执行基于形态分析,停用词删除,标记和多义词分析的预处理过程。基于预处理的健康文档,创建候选语料库和核心语料库,然后将其保存到数据库中。扫描候选语料库的逐字TF。为了提取关联特征信息,计算候选语料库的IDF和TF-IDF。将核心语料库的扫描结果用作权重,然后计算候选语料库的TFC-IDF。在计算的TF-C-IDF的基础上,创建了交易,并且使用Apriori算法来提取关联关键字。使用TF-C-IDF和关联关键字,提取关联特征信息。
3.2 实验结果评估
在结果评估中,考虑健康文件的TF,TF-IDF和TF-C-IDF值,比较F-度量和效率。使用精确度和召回率计算F-度量,其用于比较考虑TF,TFIDF和TF-C-IDF值的重要性评估结果。Recall表示实际找到的文档与与关联特征信息相关的文档的比率。精度是指基于关联特征信息从文档搜索得到的相关文档的比率。效率是提取的关联特征信息中关键字和停用词的数值。在公式(3)中,E表示测量效率的等式。Wn表示关键字的总数,Nstop表示提取的关联特征信息中涉及的停用词的计数。
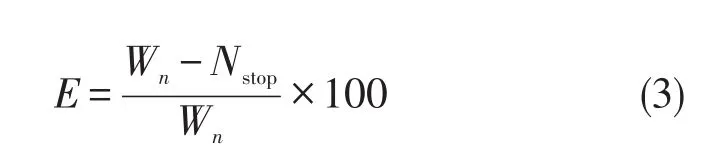
对性能评估,考虑TF,TF-IDF和TF-C-IDF,使用每个权重提取关联特征信息。图1展示了应用每个权重时关联特征信息的精度、召回率、F-度量和效率值。
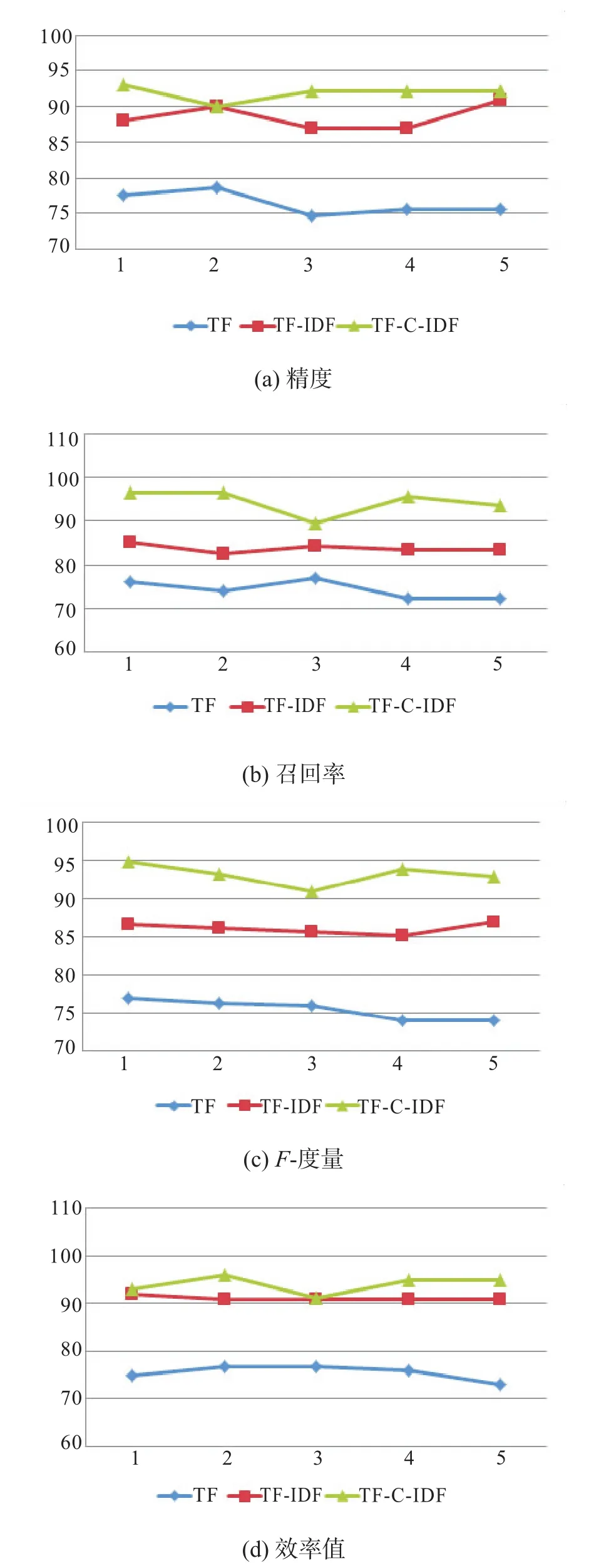
图1 关联特征信息的精度、召回率、F-度量和效率值
图1(a)中TF-C-IDF的精度要明显高于TF,与TF-IDF相比较,一般情况下精度要优些;图1(b)中 TF-C-IDF 召回率最高;图 1(c)中 F-度量值TF-C-IDF最优;图1(d)显示TF-C-ID效率值要好于TF和TF-IDF。通过四个指标的比对,可以看到TF-C-IDF在提取关联特征信息上要优于TF和TF-IDF。因此,所提出的TF-C-IDF方法具有较高的性能。
4 小结
为了有效管理和使用健康文件,本文提出了一种利用健康大数据文本挖掘提取关联特征信息的方法。关联特征信息主要存在于健康大数据中的核心关键字及其关联关键字。对于健康文档的收集,使用分析网页的方法,仅能将文本作为原始数据进行删除。N-gram方法对收集的作为原始数据的健康文档进行形态学分析,并且在预处理之后创建候选语料库和核心语料库。评估单词重要性的代表性方法是找到文档中重复出现的单词。如果重复出现的单词被选为重要单词,则相关单词也会被评估为重要单词,为了解决这个问题,通常应用TF-IDF。鉴于健康文件的特征,在多个文件中发现了诸如眼睛,心脏,脂肪和抑郁症之类的词语,因此在基于TF-IDF的重要性评估中这些词语的重要性较低。为了解决这个问题,本研究使用了TF-C-IDF,其中应用了基于核心语料库的权重。核心语料库由使用标题标签,散列标签和文档强调标签提取的核心关键字组成。高度重要的单词被分类为关键字集,并且在每个文档中创建了事务。使用Apriori数据挖掘算法分析事务中关键字之间的关联。使用创建的关联关键字和TF-C-IDF的值,提取关联特征信息。最后,比较了各方法的TF和TF-IDF值的F-测量和效率值。本文提出的TF-C-IDF的平均值优于其他方法。
猜你喜欢
华人时刊(2022年1期)2022-04-26 13:39:28
中国新闻周刊(2021年26期)2021-07-27 04:02:12
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
动漫界·幼教365(大班)(2019年10期)2019-10-28 01:54:09
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
语言与翻译(2015年4期)2015-07-18 11:07:45
智能计算机与应用(2011年4期)2012-05-15 02:24:18
电脑迷(2012年4期)2012-04-29 06:12:13
