
基于人工智能的语音识别系统及应用研究
2019-08-30 06:40:28房爱东张志伟谢士春
宿州学院学报 2019年8期
房爱东,张志伟,崔 琳,谢士春
宿州学院信息工程学院,安徽宿州,234000
语音识别(Speech Recognition)是通过对一种或多种语音信号进行特征分析,实现对声音信号匹配、辨别的技术。语音识别技术是生物识别技术的一种。因个体的声带、口腔、舌头、嘴唇、软腭、咽腔、肺容、鼻腔、牙齿等发声控制器官各不相同,发音频率各异,音色、音强、音长、音高各不相同,形成独具一格的个体语音特色[1]。这些不同要素又由90余种特征组成,共同表现出频率、节奏、波长、强度等不同声音个性特征。世界上没有发自两个人的完全相同的语音,所有的声纹都或多或少有区别,观察描述、辨析识别这些细小差异是语音识别技术需要解决的问题。
1 语音识别技术
语音识别技术是继指纹识别技术、DNA 识别技术之后的可以进行大面积应用的第三种新型识别技术。目前我国科研机构已经能够对十亿级库容的语音进行“1:N”秒级别的检索识别。美国贝尔实验室的研究报告显示,语音识别对诸如词语“I、YOU、HE”等单词识别的准确率可以达到96%~98%[2]。随着人工智能技术的快速发展和广泛应用,语音识别的准确率必定会得到大幅提升。
说话人的辨识和确认是语音识别的两种基本技术。对个体的语音进行采集、建模和数化是语音识别技术的首要工作,只有采集了社会公众的语音集合的全样本后,在获取个体音源语音检材时,才能够把全样本语音集合与个体语音样本进行自动比对,快速确认个体的真实身份。语音可以进行远程的采样和识别,因而对个体的身份确认具有方便快捷的优势。中国科技大学、清华大学、厦门大学和中科院声学所等科研院所,已经成功研制出识别速度快、辨识准确率高的不同语音识别系统。目前,公安机关已经把语音识别技术广泛应用于办案过程并已取得显著效果。
2 语音识别系统
2.1 语音识别系统的原理
语音与人体的其他各种生物特征相似,具有唯一和不可复制性[3],世界上不存在语音完全相同的两个个体。语音识别技术就是从个体的语音信号中提取语音特征进行建模与数化,把全样本语音集合与个体语音样本进行自动比对进而进行身份识别等的判断 ,语音识别系统原理如图1所示。

图1 语音系统原理图
2.2 语音识别系统的四个模块
2.2.1 预处理模块
把采集到的模拟语音信号转换为数字语音信号,这是进行语音识别的第一步。采集语音信号、进行A/D(模/数)转换是预处理模块的主要功能,语音识别系统预处理模块同时具有波形编辑处理功能和(D/A转换)回放功能。
2.2.2 参数分析模块
提取语音参数,语音参数的提取要能准确地反映个体的发音特征。经过比较、分析若干种语音参数在辨识个体语音辨识率有效性基础上,在参数分析模块TDSI系统中使用音调曲线、偏相关和音长参数作为个体语音特征参数,在参数分析模块TISI系统中加入正交线性预测参数和长时间平均谱作为个体语音的特征参数[4]。
2.2.3 训练模块
把所提取的语音参数作为个体建立训练模块。因为测试语音的时间长度与训练语音的时间长度有差异。本文在训练模块TDSI系统中应用线性压扩技术,把训练语音调整到15帧(0.02秒/帧);在训练模块TISI系统中应用长时间平均技术,把训练语音调整到1帧(0.02秒/帧)。
2.2.4 识别模块
把模板库中的语音模板和被测试语音进行比对,应用模板匹配技术,依据“最佳邻近准则”锁定与测试语音相匹配的个体。本文在语音识别系统识别模块中应用了参数加权欧氏距离聚类方法,计算出被测试语音和模板中语音之间的距离(表征近似程度的数学参量),在识别模块TISI系统中应用多阶段识别策略,即率先在库中粗识别,遴选出N个相似度高的个体语音,进而在N个个体内进行细识别,最终筛选出最高相似度的个体语音。
3 语音识别步骤
3.1 特征参数的提取
特征参数是用来对物质和现象特性进行表征的参数信息。在日常言语中 ,每个人的语音特征和言语习惯等信息是独具特色的,可提取这些参数并对语音进行归类分析。因为每个个体的语音参数具有稳定性和难以更改性,即便所在地点场景不同、时间跨度不同,被分析者的这些被提取的语音参数也不会发生变化。因而语音特征参数能够完全有别于其他人,确保了身份识别的正确性。语音分析中有如下几种方法用于语音参数的提取[5]。
(1)语音频谱。用语音频谱描绘被提取个体的生理结构,主要体现在每个人的发声器官上。个体的发声器官在医学构造上没有完全相同的,具有独一无二的特性。基础发声器官以鼻腔、气管和声道等为主,基于个体的基础发声器官来提取这些参数,对这些参数进行分类、筛选进而捕捉测量个体的语音短时频谱特征。通过对这些数据的分析可以找到被测个体的发声激励源及发音生理结构,找到有别于其他个体其生理器官的特性。被测个体的语音习惯性动作是短时频谱及其基本轮廓重点关注的两个方面。
(2)线性预测。语音参数的线性预测是基于“过去”的一些语音抽样,运算“当前”的语音参数是在数学模型基础进行的,通过这种方式获取的语音参数用于运算语音特征。提高运算效率、降低实现成本完全可通过带有预测性质的运算来完成,表现一种特殊的语音不需要很多的参数就能实现。
(3)小波特征。小波特征参数通过运用小波技术获取语音特征信息。能够接受分辨率的改变是小波技术的优点,小波技术要求语音参数稳定性交叉,但能够和时频域兼容表征。目前小波特征技术已非常成熟,能够准确快捷地获取被测个体的语音特征信息,得到广泛应用。
3.2 模式匹配识别
基于在已经获取被测个体语音特征参数基础上做更进一步的深度分析与精确判断是模式匹配识别需要完成的工作。模式匹配识别是一种比对操作:把没有识别处理的语音特征参数与模型库中的语音特征参数进行比照。对比结果以相似度的高低形式标示,相似度距离以数据或表格形式呈现。相似度距离有一个范围,把相似度距离合适的一个值作为门限值,以此筛选出最佳结果,最后的结果由语音识别系统输出[6-7]。目前常见的较为成熟的模式匹配识别判断有两种模型。
(1)矢量化模型。通过对语音参数建立矢量,对被检测个体的语音特征进行矢量化处理。如需对被检测人语音特征进行识别,把被检测个体语音特征参数处理成可以表示个人信息的语音矢量并提供相应的语音规范标准。
(2)随机模型。一个人的语音在不同地点和环境下是变化的,其变化范围和变化的概率大小具有不确定性,需要建立随机模型,随机模型把被检测个体的语音参数集中归类建立语音参数模型,在建立语音参数模型时充分考虑到传输概率、转移概率等因素。在训练过程中获取状态转移概率矩阵、符号输出概率矩阵等。当被检测个体的语音信息发生状态转移时,系统能及时识别语音信息发生状态转移时的最大概率,从而对该被检测人的语音模型做进一步分析判断。
4 实验测试
4.1 识别过程
构建语音识别模型,通过语音识别系统对语音进行识别如图2所示。语音识别过程分为以下若干步骤:
(1)对采集的原始声音做相应技术处理,例如分帧、预加重、加窗等;
(2)计算梅尔频率倒谱系数,输入特征矩阵I(n×r),r为帧数;
(3)通过深度神经网络进行逐层前向计算,得到输出矩阵O(m×r);
(4)找到输出矩阵中列向量的最大输出概率值,构建含有r个元素的马尔科夫链Hr=(h1,h2,...,hr);
(5)将上述步骤中得到的Hr值输入语音识别模型,然后对语音识别模型进行分析,进而确定最高概率的对应路径以获得相关文字信息,最后将识别结果输出。

图2 语音识别系统
4.2 数据分析
实验共采用4个实验组,每个实验组含测试样本1个、待匹配样本20个。在每个实验组的20个待匹配样本中,其有1个来自于和本组测试样本来源相同的说话人的语音采样,其余19个均为不同的说话人提供的语音样本。实验使用深层循环神经网络与混合高斯隐马尔科夫模型相结合的混合模型(图3)进行语音识别。获得语音的特征值后,通过深层循环神经网络把语音特征值接近纯语音。随后把深层循环神经网络输出的语音特征值输入到混合高斯分布的隐马尔科夫模型进行比对,得出最终识别结果。

图3 混合模型结构
采用DNN-HMM混合语音识别模型与GMM-HMM传统语音识别模型对语音识别的准确率进行比较,实验结果如表1所示。由表1数据得出结论,DNN-HMM语音识别系统对于单个词语进行识别的准确率达到96.6%,而GMM-HMM语音识别系统则仅有 79.8%,前者的识别质量明显高于后者,其他情况下也有相近结论。但在个别条件下,例如有噪声干扰时,DNN-HMM语音识别系统的识别率不足80%,需要不断研究提高。
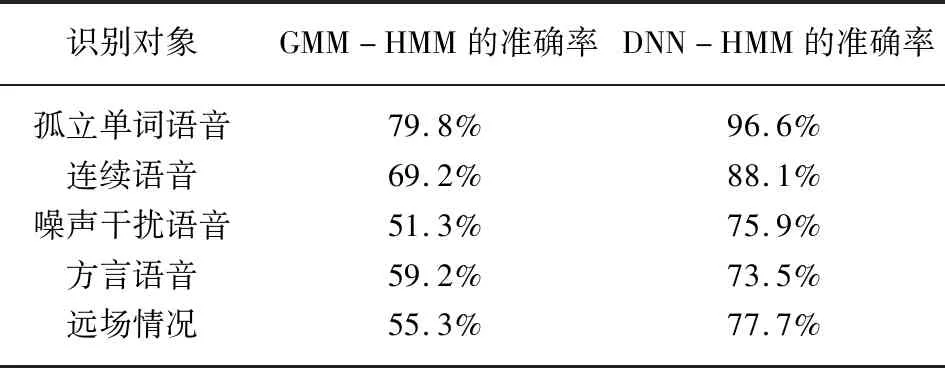
表1 DNN-HMM语音识别模型与GMM-HMM实验对比
5 结 语
基于人工智能的语音识别系统对语音信号进行分析处理,通过具有自主性的演算,精准地提取特征参数并识别筛选出精确的语音特征数据,误差小精确度高,经提取分析处理的语音特征的可靠性更高、可利用性更强。于人工智能的语音识别系统对在语音信息进行识别处理过程中出现的差错能通过人工计算与人工智能自行纠正并加以改进,智能语音识别的出错率降低、容错率上升,具有广阔的发展、应用空间。因此,智能语音识别系统相较于传统语音识别系统具有无法比拟的优点,而且智能语音识别系统的技术发展难度比传统语音识别系统明显降低,未来可以通过人工智能和语音识别系统的进一步融合 ,进一步增强智能语音识别系统的功能,拓展其应用领域。
猜你喜欢
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
劳动保护(2019年7期)2019-08-27 00:41:02
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
制造技术与机床(2017年11期)2017-12-18 06:46:39
学习月刊(2015年22期)2015-07-09 03:40:48
中学科技(2015年1期)2015-04-28 05:06:12
