
基于CURE聚类算法改进的原型选择算法①
2019-08-22 02:31孙元元张德生
计算机系统应用 2019年8期
孙元元, 张德生, 张 晓
(西安理工大学 理学院,西安 710054)
1 引言
K近邻分类器(KNN)[1]是用于分类任务的最常用和最著名的技术之一,其简单易操作性被人们广泛应用于文本分类、图像处理、手写数字识别等方面. 然而K近邻分类器存在计算量大、内存开销大的特点,目前已经有许多改进方法. 其中最主要的技术有两种:原型生成和原型选择. 原型生成PG (Prototype Generation)[2]是通过生成人造数据来代替原始数据,使其能够填充原始数据集中没有代表性样例的区域. 原型选择PS (Prototype Selection)[3]是对整个数据集进行约简,在保证不降低甚至提高分类精度等性能的基础上,获取具有较高分类贡献的同时能够反映原始数据集的分布状况具有一定代表性的原型子集.
目前,研究学者已经提出了许多原型选择算法,最著名的两个方法是压缩和剪辑策略. 在1968年,Hart[4]最早提出的原型选择算法是压缩最近邻CNN (Condensed Nearest Neighbor),该算法主要针对整个数据集,尽可能多的约简数据集的样例,只保留贡献率最高的边界样例,但该算法分类精度却有所降低,而且计算过程非常依赖原样例扫描的顺序. 在1972年,Tomek[5]提出了基于K近邻规则的剪辑算法ENN(Edited Nearest Neighbor),该算法旨在有效排除原始训练集中的噪声数据和重叠数据,但该算法是基于剪辑策略的算法,并没有删除对分类没有重要贡献的内部样例点,因此其数据约简率比较低. 之后,基于ENN的一系列改进算法被提了出来. 在2009年,Fayed和Atiya[6]提出了一种新的压缩算法—KNN模板约简算法TRKNN (Template Reduction for KNN),该算法的基本思想是定义一个最近邻居“链”,然后根据链上的每一段距离,设置一个阈值来将其划分成保留的压缩数据集和要移除的数据集.在2010年,Ougiaroglou[7]等提出了一个基于聚类的原型选择算法PSC (Prototype Selection by Clustering),该算法首先使用K-means聚类算法将整个数据集划分成不同的簇,然后在每一个簇中选择代表样例. 对于同类簇集,最靠近簇中心的样例被保留下来; 对于不同类簇集,不同类边界的样例被保留下来; 保留下来的样例作为最终的原型进行分类. 在2014年,Li和Wang[8]提出了一个基于二叉最近邻树的原型选择算法BNNT (the Binary Nearest Neighbor Tree),该算法首先建立一个二叉最近邻树,当二叉树位于一个类的内部时,生成一个中心点代替树的所有节点被保留; 当二叉树位于多个类的边界时,拥有不同类标签同时在树中直接相连的原型被保留下来,保留下来的所有样例点作为原型集进行分类. 在2016年,Li[9]等人提出了基于自然邻居和最近敌人的原型选择算法,该算法利用自然邻居过滤噪声模式并平滑类边界,再使用基于最近敌人新的冷凝方法来减少原型的数量,该编辑算法和冷凝算法的结合去除内部冗余样例,保留了边界样例,有效地减少了数据集的数量. 在2017年,朱庆生[10]等人提出基于自然邻居和最小生成树的原型选择算法2NMST(Prototype Selection Algorithm Based on Natural Neighbor and MST),该算法使用自然邻居做数据预处理,然后基于设定的终止条件构建Prim最小生成树,生成一些具有代表性的内部原型,并保留边界原型. 在2018年,黄宇扬[11]等人提出了一种面向K最近邻(KNN)的遗传实例选择算法. 该算法采用基于决策树和遗传算法的二阶段筛选机制,先使用决策树确定噪声样本存在的范围; 再使用遗传算法在该范围内精确删除噪声样本,可有效地降低误删率并提高效率,采用基于最近邻规则的验证集选择策略,进一步提高了遗传算法实例选择的准确度; 最后引进基于均方误差(MSE)的分类精度惩罚函数来计算遗传算法中个体的适应度,提高有效性和稳定性. 同年,王熙照[12]等人提出基于非平稳割点的样例选择方法.依据在区间端点得到凸函数的极值这一基本性质,通过标记非平衡割点度量一个样例为端点的程度,然后选取端点程度较高的样例,从而避免样例之间距离的计算. 同时,进化算法已经应用于原型选择算法的,Acampora G[13]等人首次提出将“后验”算法,即SPEA2应用于原型选择问题,以明确处理KNN时间和空间复杂度两个目标,并在分类和降低性能之间提供更好的权衡.
上述提到的所有算法虽然在存储空间和时间复杂度上都有了较好的改进,但仍具有较低的分类准确率和较高的原型保留率. 针对目前原型选择存在的问题,本文在CURE算法的基础上对其进行改进,从而提出一种新的原型选择方法PSCURE. 同时针对CURE聚类算法改进有两方面,一方面是异常点剔除方法的改进. 原CURE算法很难确定异常点,本文使用共享邻居密度计算每个原样例周围的密度,再根据密度特征值进行去噪; 另一方面是代表点选择的改进. 原CURE算法挑选的代表点容易集中在图形最长的两端[14],而本文使用最大最小距离来选取代表点,使代表点具有分散性,由此提出了一种新的原型选择算法. 本文的结构如下:第2部分主要介绍共享邻居密度和最大最小距离,以及CURE的相关知识; 第3部分提出基于CURE聚类改进的原型选择方法及计算; 第4部分针对所提出算法PSCURE进行数值实验.
2 相关工作
为了更好的理解本文算法,本章介绍了涉及到的3种重要算法:共享最近邻密度,最大最小距离和CURE聚类算法.
2.1 共享邻居密度
共享邻居是两个样例数据共同拥有的近邻个数,基本思想是如果两个样例点拥有的近邻个数越多证明两点越相似,根据共享邻居的相似性得知每个点的局部密度,即共享邻居密度.
定义1[15](共享邻居). 对于数据集X中的任意点i和j,点i和点j的K-最近邻居集合分别是Γ(i)和Γ(j),点i和点j的共享邻居是它们的公共邻居集,表示为

定义2[15](SNN相似性). 对于数据集X中的任何点i和j,它们的SNN相似性定义为

其中,dij是点i和j之间的距离. 仅当点i和点j出现在彼此的K邻居集中时才计算SNN相似性,否则,点i和点j之间的SNN相似性为0. 式(2)的非零部分通过以下形式表示,从中可以清楚地观察到SNN相似性的含义,即:

等式右端的左边部分表示点i和点j的共享邻居的数量,右边部分是从点i和点j到所有共享邻居的距离的平均值的倒数,它表示在一定程度上围绕两点的密度.通过同时检查共享邻居和此两点的密度,SNN相似性可以更好地适应各种环境.
在定义任意两点的SNN相似性之后,我们使用该相似性来计算点i 的局部密度ρi.
定义3[15](SNN局部密度). 设点i是数据集X中的任意点,L(i)={x1,x2,···xk}是与点i具有最高相似度的K个点的集合. 点i的局部密度定义为与点i具有最高相似度的K个点的相似度之和,即
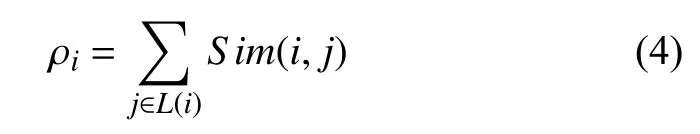
基于共享邻居密度包含了数据点的局部邻域信息的特点,当一个点邻域中的数据点分布较密时,该点的密度就相对较大,反之较小.
根据上述定义计算数据集中的每个数据对象的共享最近邻密度值,然后按照共享邻居密度值对数据对象进行升序排列,画出密度递增曲线. 根据假设,数据集中的噪声点与正常点相比分布相对稀疏,因而其密度较小,那么在密度递增曲线上,噪声点和正常点之间存在一个拐点,在该拐点之前的数据点为噪声点,而在此之后的点为正常点. 利用共享邻居密度去噪算法的伪代码如下:

算法1:利用共享邻居密度去噪的算法输入:数据集X,近邻数K输出:去噪后的数据集找出所有点的K-最近邻∀i,j∈X For If 两个点i和j不是互相在对方的K最近邻中 Then number(SNN(i,j))←0 Else number(SNN(i,j))←共享的近邻个数End If similarity(i,j)=number(SNN(i,j)) *( 1/(1/number(SNN(i,j)) *sum(dist(i,p))+dist(j,p)))ρi density=sum(similarity(i,j)) //局部密度End for den_threshold=computer_denthr(density)//remove noise points∀i∈X For If density(i)<=den_threshold X.delete(i) End If End for
在算法1中,getKnn(i,X)表示在数据集X中寻找i的K个近邻,number()表示两个样例中的共同的邻居,也就是共享邻居个数,如果两个样例不是互相在对方的K最近邻中,定义这两个样例的相似度为0,否则根据式(1)计算共享近邻个数. 通过式(3)计算共享近邻的相似性similarity(),再根据相似性通过式(4)求出数据集中每个样例的密度,这里的密度主要是根据一个样例与周围K近邻的共享近邻的相似性之和定义,computer_denthr()确定密度阈值,从而去除数据集中的噪声点.
2.2 最大最小距离
最大最小距离算法也称小中取大距离算法[16]. 本文使用欧式距离,已知N个样本X1,X2,···,XN,算法描述:
(1) 给定θ,0<θ<1(一般θ=1/2),计算每个特征的平均值生成一个中心点,计算离该中心点最近的数据集中的点作为第一代表点Z1;
(2) 计算所有样例到Z1的距离Di1,选择距离第一个代表点Z1最远的样例点作为第二个代表点Z2,距离表示为D12;
(3) 计算其余样例点到Z1,Z2之间的距离,并求出他们中的最小值,即Di=min(Di1,Di2),i=1,2,···,N;
(5) 以此类推计算每个样例点i到已确定的所有代表点j之间的距离Dij,并求出Di0=maix(min(Di1,Di2,···,Dij)),若Di0>θ·D12,则继续建立代表点,否则结束寻找. 利用最大最小距离选取代表点算法的伪代码如下:

算法2. 最大最小距离选取代表点θ输入:数据集X,阈值输出:代表点集合center point=[每个特征的平均值]center[0]=距离point最近的点 //第一代表点center[1]=距离center[0]最远的点 //第二个代表点D12=get_distance(center[0],center[1])//计算所有代表点max_min_distance=0 θ∗D12 While max_min_distance>index=0 For i in range(len(X)) min_distance=[] For j in range(len(center)) distance=get_distance(X[i],center[j]) min_distance.append(distance) End For min_dis=min(dis for dis in min_distance) If min_dis>max_min_distance max_min_distance=min_dis index=i End if center.append(X[index])End While Return center
2.3 CURE层次聚类算法
CURE (Clustering Using REpresentative)算法[17]采用了一种自底向上的层次聚类算法,最突出的特点是利用代表点而不是中心点代表一个类,利用代表点计算一个类与另一个类之间的距离. 代表点是指能够代表这个类的形状、密度和分布的一些数据点,基本的思想是:所有数据点在最初都是一个簇,然后不断合并,直到最后的簇个数为指定的数目. 详细步骤如下:
(1) 抽样过程:从原始数据对象中选取一个随机样例D;
(2) 划分过程:对样例D进行划分,一般按数量均匀划分;
(3) 初始化过程:设置参数,参数一是要形成的簇数K,参数二是代表点(代表该簇的点)的数目m,参数三是收缩因子alpha;
(4) 聚类过程:对每个划分挑选代表点进行聚类;第一个代表点选择离簇中心最远的点,而其余点选择离所有已经选取的点最远的点;
(5) 剔除离群点:第一阶段删除在聚类过程中增长非常缓慢的簇; 第二阶段在聚类结束时含数据对象明显少的簇.
3 基于CURE聚类算法改进的原型选择
基于聚类的原型选择的动机是快速执行通过聚类挑选出有代表性的内部点和边界点,为了实现这一点,本文针对CURE层次聚类算法中对噪声点不易判断性,使用了共享邻居密度计算每个样例的密度,根据密度增值曲线对整个样例集确定密度阈值,进而确定噪声点.
在此使用人造数据集Flame people[18]对此算法进行说明. 图1(a)中表示该人造数据集的密度增值曲线,其中红色断点处是我们确定的噪声点和正常点之间的拐点. 图1(b)中展示了利用算法1识别噪声点之后的结果,其中“+”为识别出的噪声点.
另一方面,针对CURE选择代表点的局限性,利用最大最小距离选择代表点的方法代替CURE算法挑选代表点的算法,使得代表点能够尽量分散,从而更好地代表该簇. 在此利用随机产生的数据说明该情况. 图2(a)是利用CURE算法挑选出代表点的图示,其中圆圈点为代表点,可见代表点集中在两端,不能很好地反应数据的形状和分布信息. 图2(b)中是利用算法2挑选的代表点,可以观察到,代表点分散在每个边缘地方,并选择了适当的中心点来做代表点,满足分散点的特性,较好的描述了数据集的分布情况.

图1 利用共享邻居密度确定噪声点

图2 CURE与最大最小距离代表点选取结果
PSCURE算法的主要步骤如下:
(1) 针对原始样例集S={X1,X2,···,XN}使用算法1对原始样例集S 进行去噪处理,得到去噪后的样例集S′;
(2) 针对样例集S′使用算法2替代CURE聚类算法步骤(4)挑选代表点的方法,所得到的代表点生成最终原型集PS;
(3) 使用最终的原型集PS进行KNN分类.
为了测试本文基于CURE算法改进的原型选择算法效果,使用了合成数据集pathbased[19]和Flame people[18]进行评估. 图3(a)展示了pathbased原始数据集的分布情况,图3(b)通过共享近邻的密度对整个样例集进行去噪处理,其中图中的“+”表示应用该算法识别的噪声点,直观地可以看出噪声点周围的密度相对其它数据集点的密度较低,图3(c)通过最大最小距离改进的CURE层次聚类算法针对数据集进行聚类,可以看出该算法将该数据集准确的划分为三个类,保留其聚类完成后的所有代表点,图3(d)所示,该算法保留了一些靠近中心的样例点和簇边界点,得到的原型最大程度的代表了整个数据集.
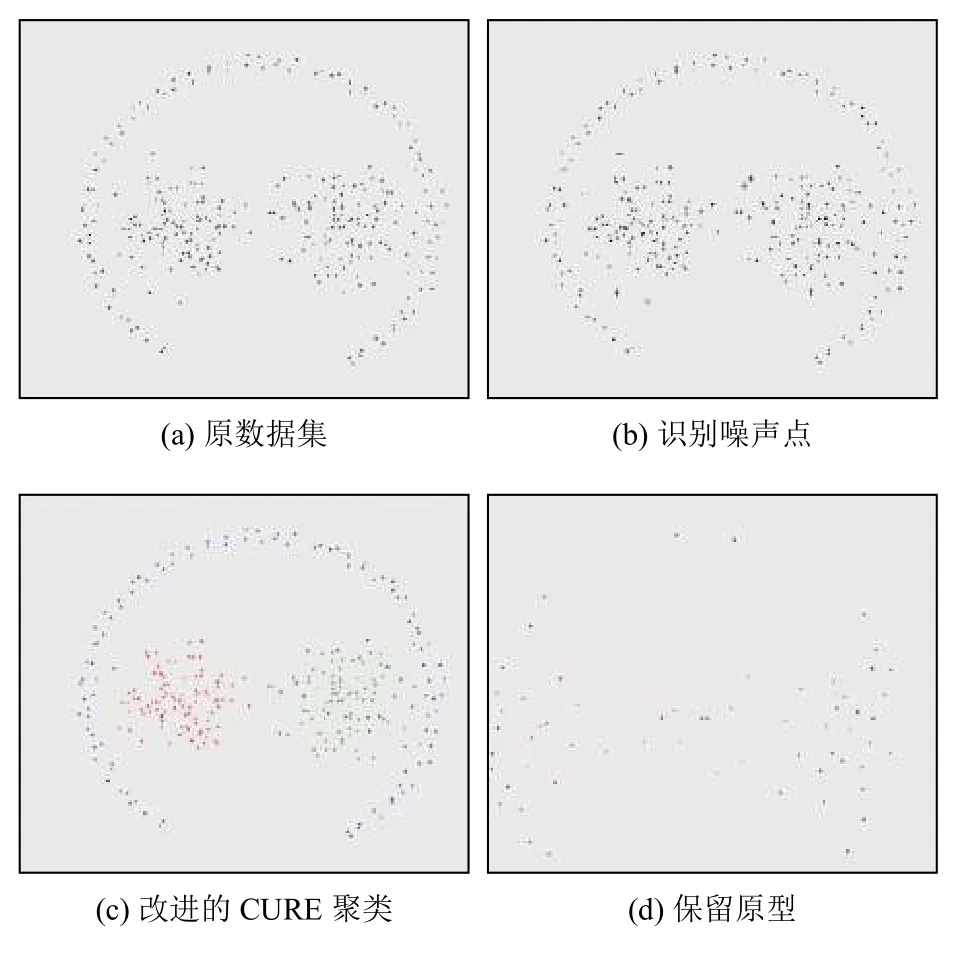
图3 PSCURE原型选择算法在Pathbased数据集上的展示
同样,图4展示了所提算法在合成数据集Flame people上的结果,图4(a)展示了Flame people原始数据集的分布情况,图4(b)图检测出局部密度最低的两个点作为噪声点,即图中的“+”; 图4(c)通过改进的CURE聚类算法精确的识别该数据属于两个簇,针对两个簇保留聚类过程所用的代表点作为最后的原型集,即图4(d)展示,该代表点除了包含内部点之外,还包含两簇之间的边界点.

图4 PSCURE原型选择算法在Flame people数据集上的展示
4 实验结果及分析
为了评估PSCURE原型选择算法的有效性,该章节利用该算法与传统的KNN[1],经典的CNN[4]、ENN[5]和最新的TRKNN[6]、PSC[7]、BNNT[8]和2NMST[10]算法在原型选择的个数及分类准确率方面进行了实验比较. 为了达到这个目的,从UCI上下载10个数据集,数据集的描述如表1所示.
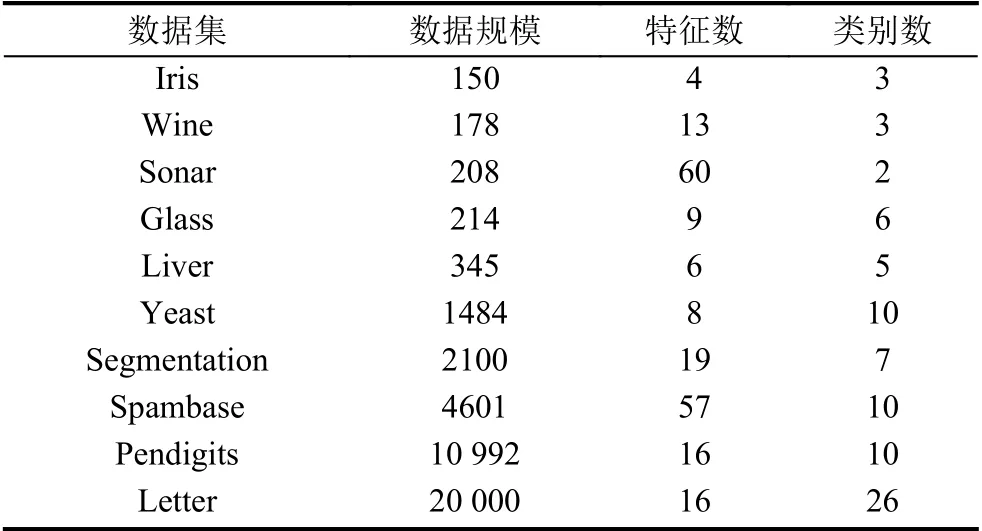
表1 UCI数据集
4.1 实验设计
本文使用10折交叉验证将数据集划分为训练集和测试集,取平均值作为最终的测试结果. 在KNN实验中,选择K=3、5、7中分类准确率最高的值作为最终分类准确率,距离度量采用的是欧氏距离. 为了精确度量算法的性能,本文使用分类准确率和样例的保留率两个主要的考察指标. 分类准确率表示针对测试样例集利用分类器正确分类的样例数与测试集总样例数的比值. 保留率表示训练数据集经过该算法处理之后保留下来的数据子集与训练集中样本个数的比值. 为了方便我们把这两个指标分别记为Acc和Str. 公式分别如下:

其中,n1表示测试集个数,n2表示训练集个数,|Pr|表示被正确分类的样例个数,|PS|表示算法最后保留下来的样例集个数.
4.2 实验结果
针对表1给出的UCI数据集中的数据,本文首先利用PSCURE算法与传统的KNN算法和基于聚类的原型选择PSC做比较,表2列出了这3个算法的准确率和保留率,同样,图5展示准确率和保留率之间的比较,从实验结果可以看出KNN算法对于整个样例集没有进行约简,因此保留率是100%,在没有缩减的情况下准确率为77.65%. PSC算法跟传统的KNN算法进行比较,降低了样例数量,平均保留率为38.67%,但在准确率上较传统的KNN算法低于10.91%. PSCURE算法的准确率为81.66%,高于PSC算法的同时,更高于传统的KNN,但PSCURE算法的平均保留率仅有16.97%,大大约简了数据,提高了效率. 因此PSCURE算法有效的提高了分类算法的准确率和原型缩减率.
为了更进一步验证PSCURE算法的有效性,PSCURE算法与CNN,ENN,TRKNN,BNNT相比(见表3),PSCURE算法对几乎所有数据集有更高的或差不多的分类准确率,但却有较低的保留率. 与2NMST相比,PSCURE算法在数据集Sonar、Wine、Glass、Yeast、Segmentation、Letter上有较高的分类准确率且有较低的保留率. 从图6可以看出,本文所提算法的平均分类准确率最高,但平均保留率最低. 从平均结果来看,PSCURE算法在样本保留率和分类准确率方面都有明显的优势.
5 结束语
KNN在大规模数据集下具有过高的时间和空间复杂度而限制了其应用,为了解决该问题,本文提出了基于CURE聚类算法改进的原型选择,该算法可以保证在分类准确率不降低情况下,缩减原始数据集样例数,从而提高分类效率. 本文在CURE算法基础上进行改进,挑选代表点来对KNN进行原型选择. 具体地,使用共享邻居密度对整个样例集进行噪声点处理,使用最大最小距离代替CURE聚类算法代表点的选择,最后利用挑选的代表点集进行KNN分类. 实验结果表明PSCURE算法比其他原型选择算法能筛选出较少的原型,但能获取较高的分类准确率.

表2 PSCURE算法与KNN、PSC的准确率和保留率
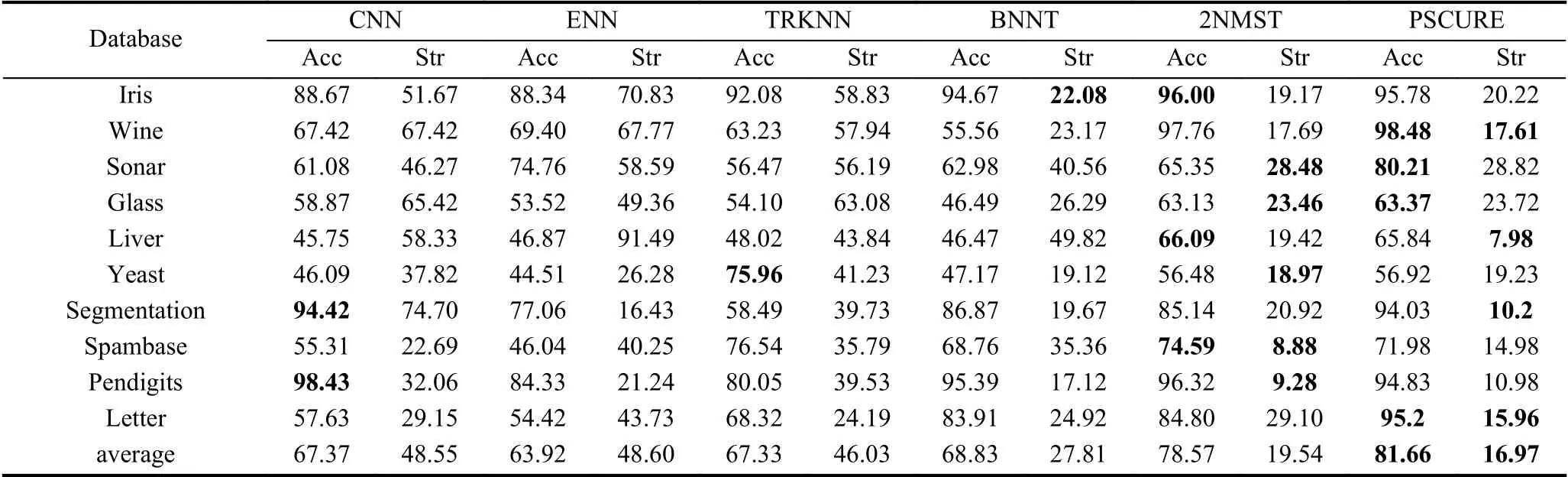
表3 算法PSCURE和CNN、ENN、TRKNN、BNNT、2NMST的准确率和保留率的比较结果

图5 表2中平均准确率和保留率的散点图

图6 表3中平均准确率和保留率的散点图
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
计算机应用与软件(2021年7期)2021-07-16
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
小资CHIC!ELEGANCE(2021年45期)2021-01-11
健康体检与管理(2021年10期)2021-01-03
英美文学研究论丛(2018年2期)2018-08-27
小天使·二年级语数英综合(2017年12期)2017-12-05
