
气象文本推荐研究
2019-08-16 01:18王慕华王阔音
计算机应用与软件 2019年8期
梅 钰 唐 卫 王慕华 王阔音
(中国气象局公共气象服务中心 北京 100081)
0 引 言
气象服务作为普通大众最常接触的公共服务,要求具备实时、准确、精细的特点。现有的气象产品一般是通过气象数据获取、数值模型计算得到预测结果,最后将预测结果转换为文字(辅以图形及表格)向公众发布。其中,后台的数值预测通过预测算法不间断运行得到预测结果,而前台的预报文本则需要通过人工编写校对生成。虽然人工参与可以保证预报的准确性以及权威性,但人工生成效率有限,且人无法像机器一样连续工作,从而导致一些预报不能实时发布,制约了气象服务质量的提升。目前,气象文本自动生成的主要应用场景是给定数值数据,直接生成气象文本[1],即全自动生成;主流方法是基于模板的方法,即针对不同气象信息构造文本模板,后续通过“填空”的方式生成预报内容,该方法的最大问题是模板有限,只能表达固定信息,且有时信息不够准确,生成的文本内容在灵活性和丰富性上也较差。因此,本文提出了一种半自动生成方案,给定部分气象文本,生成扩展的预报文本的方法,即根据人工输入推荐候选内容,相当于以人机结合的方式进行文本生成。这样既可以提升人工进行文本生成效率问题,也可以保证预警信息的准确性,扩充预报思路,具有良好的实用性。
进行气象文本推荐,一种简单的实现思路可以采用基于搜索的方法,即收集历史气象文本,针对每对句子(前半句和后半句),构建从前半句到后半句的映射字典,在推荐时通过检索前半句给出后半句集合。这种方法存在两个问题:一是同样输入,对应的候选句集合太大,来自不同地区、不同单位的文本内容存在差异,所含的气象数值不同;二是对于未出现的用户输入句,无法给出推荐结果。
从自然语言处理角度来看,气象预警文本推荐可以看作是一个典型的文本生成问题(NLG)[2-4]:利用文本的上下句的语义逻辑关系进行预测。本文所提方法分为两步:第一步是对原始文本中的气象要素(如时间、地点、温度、风速等级)进行实体抽取、数值替换,得到模板文本。模板文本相当于只保留了预警内容的描述框架。第二步基于模板文本构建文本生成模型,用于文本推荐。其中,生成模型采用基于神经网络的Seq2Seq模型,该模型可以有效解决上述基于搜索方法的不足,既可以对候选文本进行排序减少推荐量,也可以对用户的新输入进行推荐。
为了研究气象文本推荐,我们选取预警文本作为实验数据,主要原因是预警文本数量大且获取容易。预警文本是国家气象部门针对可能带来灾害性后果的天气情况作出的提前告警,图1给出了一篇完整的气象预警文本。图2给出了气象预警文本推荐的应用示例:左侧是气象预报员编写的预警内容,右侧是系统推荐的下一句预警文本。对于第一个样本,用户输入“受冷空气影响”,系统会推荐可能性较高的下一句预警文本,这里给出了top-3的结果。其中,空格表示用户可以输入时间、地点、温度、风速等具体气象要素,这些要素对于特定的预警事件,取值不同。用户基于推荐文本进行修改后,生成最终预警文本。预警文本推荐一方面可以减少用户输入,另一方面也可以对预报生成进行提示,从而帮助提升预警文本攥写的准确性。

图1 预警文本示例

用户输入系统推荐结果样例1:受冷空气影响1. 预计风力逐渐加大至级2. 起将有雷阵雨3. 预计最低气温在℃左右样例2:密切关注天气尽量减少户外活动
图2 预警文本推荐示例
文本到文本的生成是目前自然语言处理的热门研究方向,具体可以分为文本摘要[5-7]、文本复述[8-10]等细分方向。文本生成的传统方法有规则式的生成方法、抽取式的生成方法。近年来,随着深度学习的发展,尤其是神经机器翻译技术的成熟,相关工作使用序列到序列的模型[11]来解决文本生成任务,如诗歌生成[12-13]、对话机器人[14-16]。此外,工业界也推出实际的写作程序,应用于新闻写稿[17]、气象预报生成[18]等领域。现有气象文本生成工作集中在将数值转换为文本,而我们研究的气象预警文本推荐侧重于对用户已输入文本进行扩展。
本文的主要贡献如下:
(1) 首次提出了气象文本推荐问题,构建了研究数据集。通过对天气网的预警内容进行数据采集,构建了预警文本数据集。
(2) 探索了对气象文本进行气象要素抽取的方法。首次定义了气象要素抽取任务,评估了CRF模型[19]在要素抽取任务上的效果。
(3) 提出使用基于神经网络的序列到序列的模型(Seq2Seq)来解决预警文本生成。实验表明基于Seq2Seq模型的预测效果在BLEU值上可以达到12.21,具有一定的实用性。
1 问题定义
1.1 问题描述
气象文本推荐的目标可以认为是构建一个推荐系统,该系统接收用户的句子输入S,输出关联句子T。推荐系统处理的数据形式为句对(类似于机器翻译中的对齐文本[11])。具体地,我们对S和T的限定如下:(1)S和T是进行了气象要素替换后的模板文本。之所以使用模板文本,是因为用户在编辑具体内容时需要根据气象预测情况填入实际的气象数据。(2)S和T为逗号隔开的子句,且S和T要出现在气象文本的同一句话中(句号隔开)。
根据第(1)条,推荐系统处理的文本为模板文本,即需要将文本中的气象要素进行替换。气象要素是指描述气象信息的必要内容,比如时间、地点、类别等。实际上,这里的气象要素对应的是自然语言处理中的实体。另外,气象文本也会涉及量的描述,如“降水量在50毫米以上”,类似“50”的数值也需要替换。具体地,文本要抽取的气象要素以及气象数值示例如表1所示。
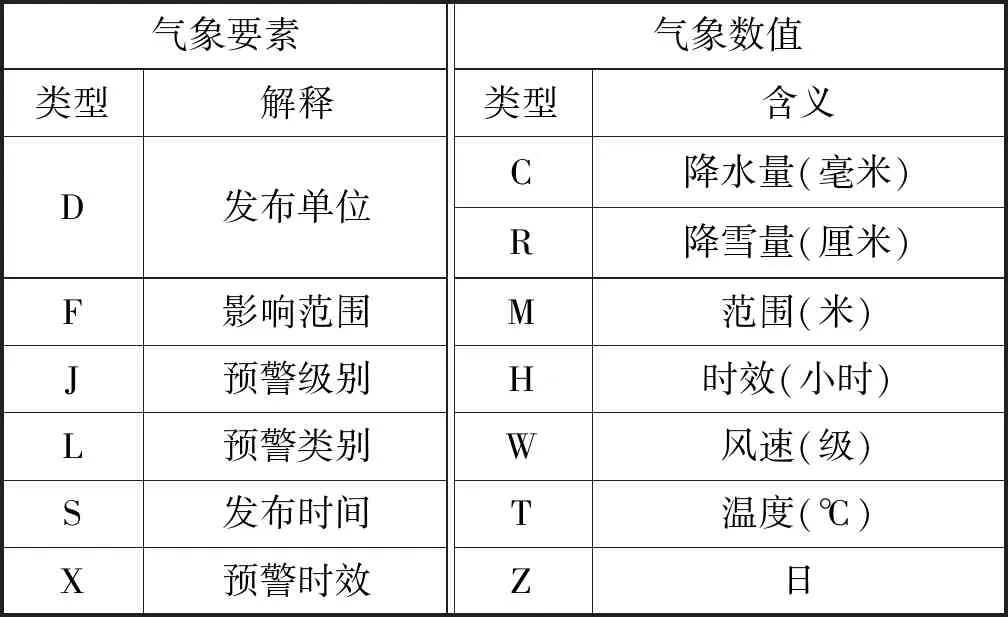
表1 气象要素、气象数值类型示例
表2给出了原始文本经过抽取替换得到的模板文本。其中,“密云气象台”是一个发布单位的实体,在模板文本中,使用实体类型“D”来替换。

表2 原始文本VS模板文本示例
根据第(2)条,句对的构建通过抽取文本中所有相邻的子句来完成。以图1中的预警文本为例,基于该预警文本生成的句对如表3所示。
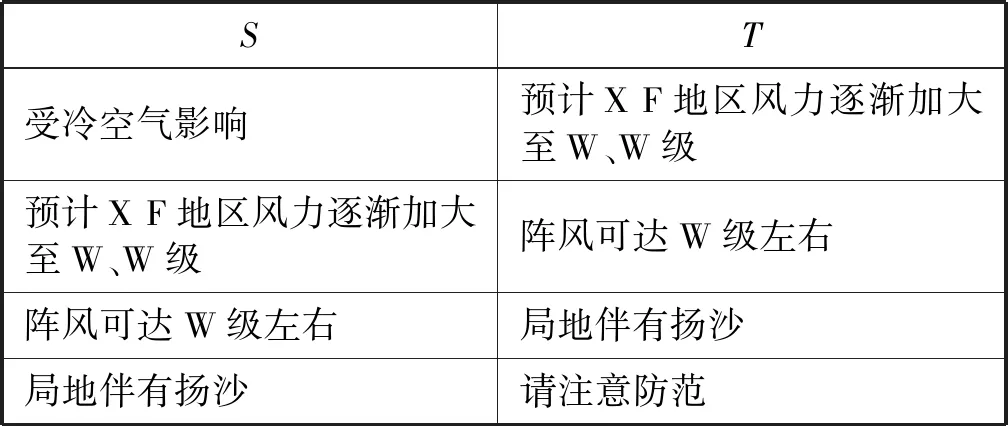
表3 基于图1预警文本生成句对
1.2 数据集构建
为了开展文本推荐研究,需要构建对应的数据集。具体地,我们爬取了天气网下气象预警栏目的内容。下载过程分为2步:(1) 通过构建翻页下载链接,即“https://www.tianqi.com/alarm-news/”+页数,下载得到预警导航页面;(2) 对导航页面中的链接进行抽取,选择“发布类型”的链接进行二次采集,获取预警文本。图3给出了数据下载的示例。

图3 预警导航页面
通过对200个导航页进行轮询下载,最终获得了3 760条预警文本,我们称对应的数据集为ALERT数据集。
2 方法设计
构建气象文本推荐系统分为两步:一是进行文本转换,即将原始文本转换为模板文本;二是基于模板文本构建推荐模型。以预警文本推荐为例,整个处理框架如图4所示。
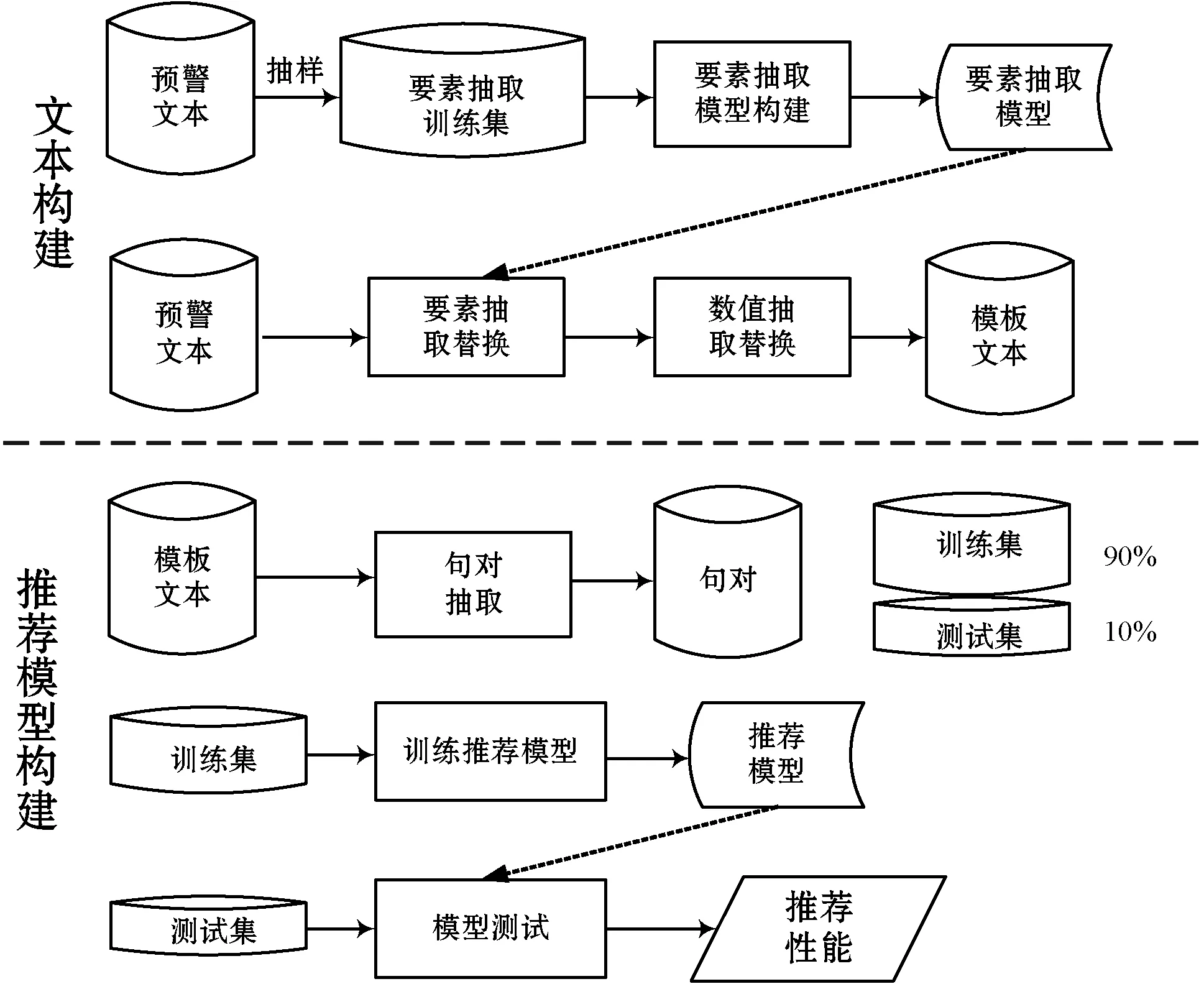
图4 气象文本推荐研究框架
2.1 文本转换
2.1.1要素抽取模型构建
气象要素抽取可以认为是一个命名实体识别问题。目前主流命名实体识别方法是基于统计的CRF模型。因为是统计模型,所以该模型在训练时需要标注数据。由于包含气象要素的预警文本相似度很高,所以要素抽取可能不需要太多的标注。为此,我们从ALERT数据中抽取了1 500条进行人工标注,选取其中的1 200条用于模型训练,300条用于效果评估,对应的数据集分别为ALERT-Train和ALERT-Test。
具体地,我们采用字符级别的标注方法。图5给出了标注示例,“12-14日”为预警时效实体类型,所以相关字符的标签为“X”。

图5 要素抽取的人工标注样例
训练使用目前主流的Stanford-NER工具。该工具提供了基于CRF的实体抽取模型。我们使用前面提到的ALERT-Train训练模型,使用ALERT-Test测试效果,得到的性能测试结果如表4所示。
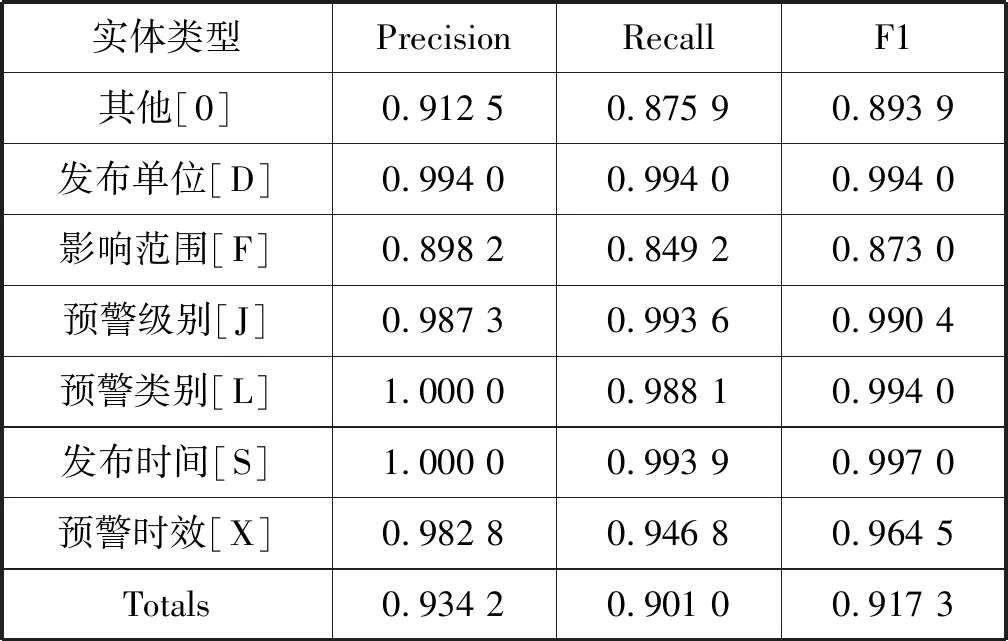
表4 气象要素抽取的测试性能
从测试结果来看,发布单位[D]、预警级别[J]、预警类别[L]、发布时间[S]的F1值都超过了0.99,说明这些要素在内容表达上相对固定,而影响范围[F]的准确率相对较低(0.87),说明地点表达相对多样。
2.1.2要素抽取替换
我们使用2.1.1节训练得到的要素抽取模型来处理ALERT中的所有预警文本。将抽取出的气象要素替换为类型符号,比如将“发布单位”实体替换为“D”、“影响范围”实体替换为“F”,替换示例如表2(左侧)所示。值得注意的是,要素替换只会替换气象要素实体。
2.1.3数值抽取替换
预警文本也会涉及气象数值,这些数值对不同预警事件来讲,参考性不大,也需要替换。如“降水量在50毫米以上”,需要将其中的“50”进行替换,替换之后的句子为“降水量在C毫米以上”。
具体地,我们使用正则表达式进行抽取,上述例子应用的正则表达式为“(d+)毫米”。同样地,我们使用数值类型符号进行替换,替换的示例如表2(右侧)所示。
2.2 推荐模型构建
2.2.1句对抽取
输入的预警文本往往包含多个句子(句号隔开)。根据1.1关于问题的定义,预警文本推荐任务只处理相邻子句。所以句对生成的过程如下:(1) 按照句号分割预警文本;(2) 对(1)中每句话,按逗号分割句子;(3) 对于(2)中的句子,如果句子由括号结尾,把括号中的内容独立为一个新子句;(4) 对于(1)-(3)产生的所有子句,将返回相邻的子句文本作为句对。句对抽取的示例如表3所示。
2.2.2推荐模型
推荐模型针对输入句S,返回扩展句T。从输入输出来看,预警文本推荐可以看作是机器翻译问题,相关的机器翻译方法都可以拿来进行尝试。采用目前基于神经网络的序列到序列(Seq2Seq)翻译模型来构建推荐模型[20-21]。Seq2Seq模型由两部分构成,一是编码阶段的“Encoder”,二是解码阶段的“Decoder”。Encoder、Decoder一般使用基于RNN的神经网络。RNN网络可以将变长输入序列转换为固定维度的向量,也可以从固定维度的向量输出变长序列。
1) RNN网络。一个RNN网络[22]按照顺序对输入序列x={xi}进行处理,不断更新内部的隐藏状态。对每个位置的输入xi,RNN会更新计算隐藏状态hi。在每个位置,基于隐状态hi,RNN可以产生关于输出yi的条件概率。这里输入到RNN单元的xi、hi是固定维度的向量,yi是词汇表中的特定词。具体地,RNN网络包括2个重要函数:状态更新函数f(·)以及输出函数g(·)。常见形式如下:
hi=f(hi-1,xi)=δ(Uxi+Whi-1+b)
(1)
g(yi|hi)=O(Vhi+c)
(2)
式中:δ(·)为激活函数tanh,O(·)为概率输出函数softmax。由于原始RNN不能很好地解决长时依赖问题,神经网络研究领域提出了多个针对RNN的改进版本,比如LSTM以及GRU[22]。
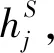
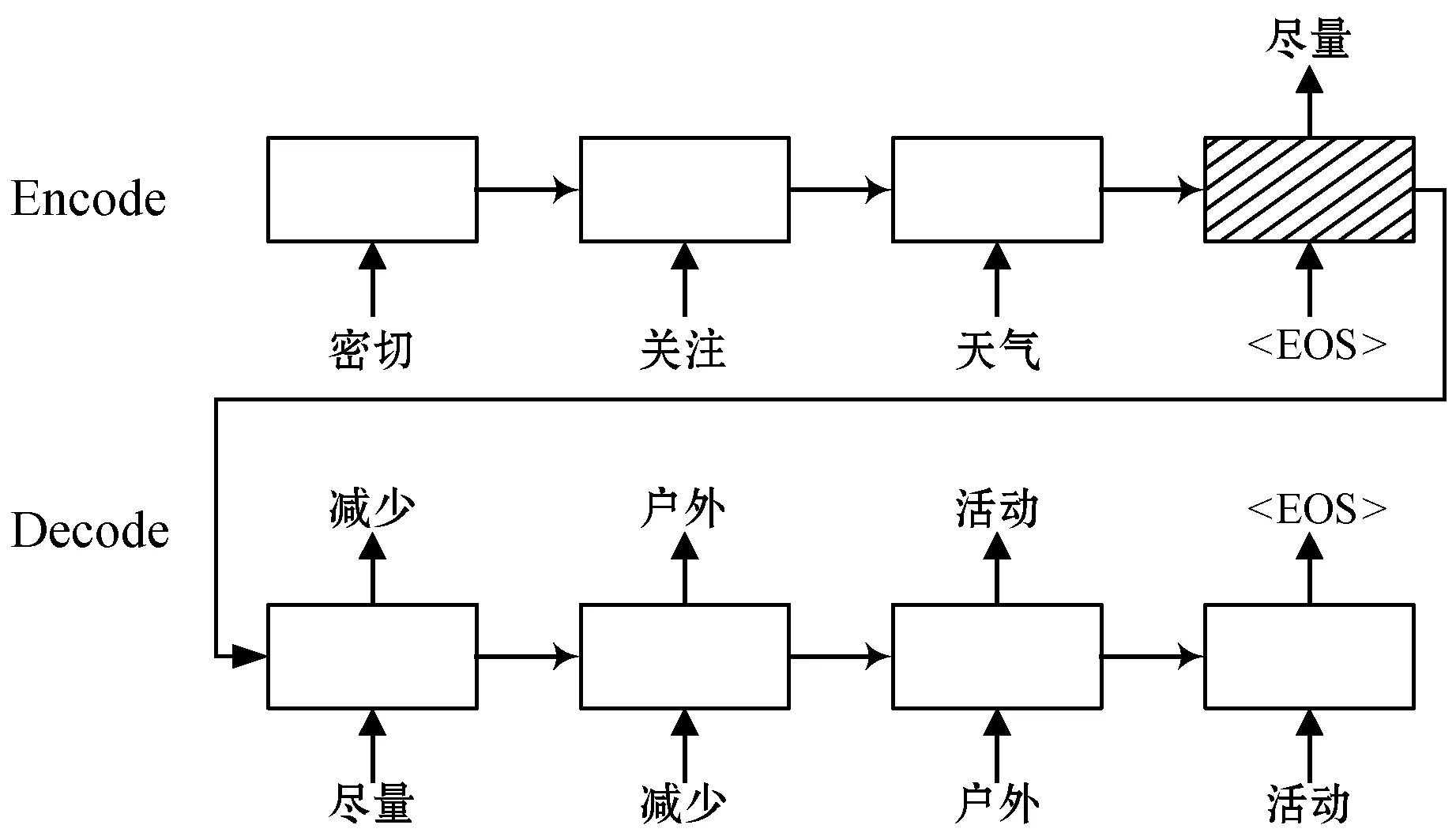
图6 预警推荐算法的示意图
从概率角度来看,Seq2Seq模型可以看作是用于估计条件概率P(T|S),S和T的长度可以不同。P(T|S)的计算如下:
式中:函数gDecoder(·)是解码器的输出函数(softmax函数),该函数能计算输出词Tj的概率。函数fEncoder(·)、fDecoder(·)是编码器和解码器的状态更新函数。
Seq2Seq模型的参数学习通过最大化如下目标函数来实现:
式中:θ是模型参数,每一组
3) Seq2Seq模型实现细节。Seq2Seq作为基础框架,其具体编解码过程有多种选择,在机器翻译领域也有很多变种。针对气象预警文本的推荐,我们的实现方案包括:
(1) 使用GRU作为RNN的实现。
(2) 不使用attention机制。主要原因包括3点:① 在预警文本推荐中,句子的长度较短,基于attention来解决解码时长范围依赖的需求不大;② 预警文本推荐的2句话在整体上存在逻辑表达关系,但在单个词上的对齐关系较弱,attention作用有限;③ 引入attention也会引入额外参数,增大过拟合的风险。
(3) 对输入句子进行反转。主要原因是为了缩短输入句S前面的词到输出句T前面词的平均距离。在机器翻译中,该方法可以有效提升翻译质量。
具体的算法流程同文献[21]一致。
3 实验及分析
3.1 实验设置
本文使用google-seq2seq的工具进行实验。具体地,对ALERT数据集进行句对抽取,共获得14 593个句子对。随机选取其中的90%作为训练集来学习参数,10%作为测试集进行结果验证。句子长度的统计信息如表5所示。

表5 S、T句子长度统计信息
选择机器翻译常用的BLEU和ROUGE作为评价指标,通过比对模型生成句以及标准答案句的差异,对推荐句的效果进行评价。
句子使用Jieba进行分词,词的表示(embedding)也作为参数进行学习,训练集中S的词表大小为827,T的词表大小为696;输入句S和输出句T使用独立的词表以及独立的embedding矩阵。
关于词的embedding学习,由于涉及参数较多,我们使用从中文wiki预训练得到的embedding来初始化。具体地,中文wiki学习到的词向量为300维,使用PCA将词向量进行降维,该向量作为embedding的初始向量。对于未出现在wiki中的词,使用随机初始化。
在参数选择上,需要尽可能地拟合训练集,因为测试集和训练集的数据分布差异较小。对于embedding.dim参数(PCA的输出维度),我们尝试了{4,8,16};对于Encoder、Decoder,我们尝试了{num_layers:1,num_unit:8}以及{num_layers:2,num_unit:4}。最终使用的Seq2Seq模型的参数设置如表6所示。实验在一台GPU上运行,总共迭代了约15万次。
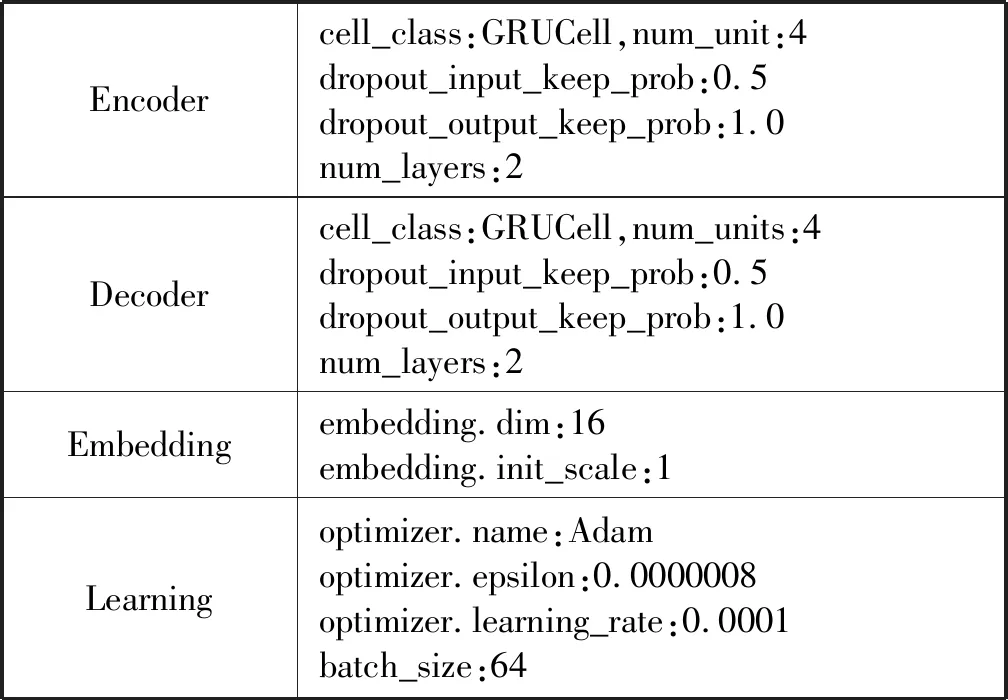
表6 Seq2Seq模型的参数设置
3.2 结果分析
最终的测试性能如表7所示。
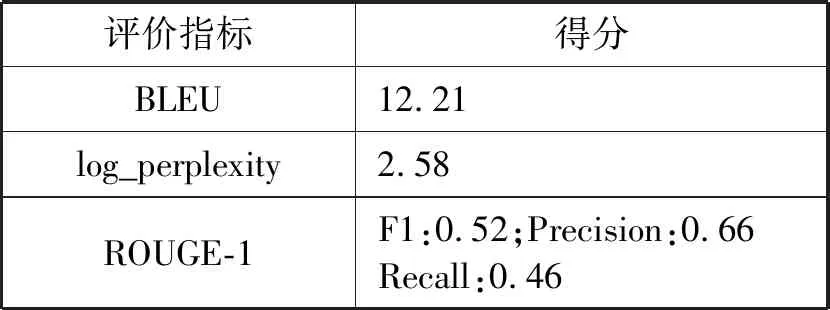
表7 Seq2Seq模型的性能指标
图7-图10给出了随着迭代的进行,学习到的Seq2Seq模型在测试集上的性能得分(BLEU、ROUGE-1/F、ROUGE-1/Precision、ROUGE-1/Recall),步长为10 000。从图中可以看到,模型已经收敛。
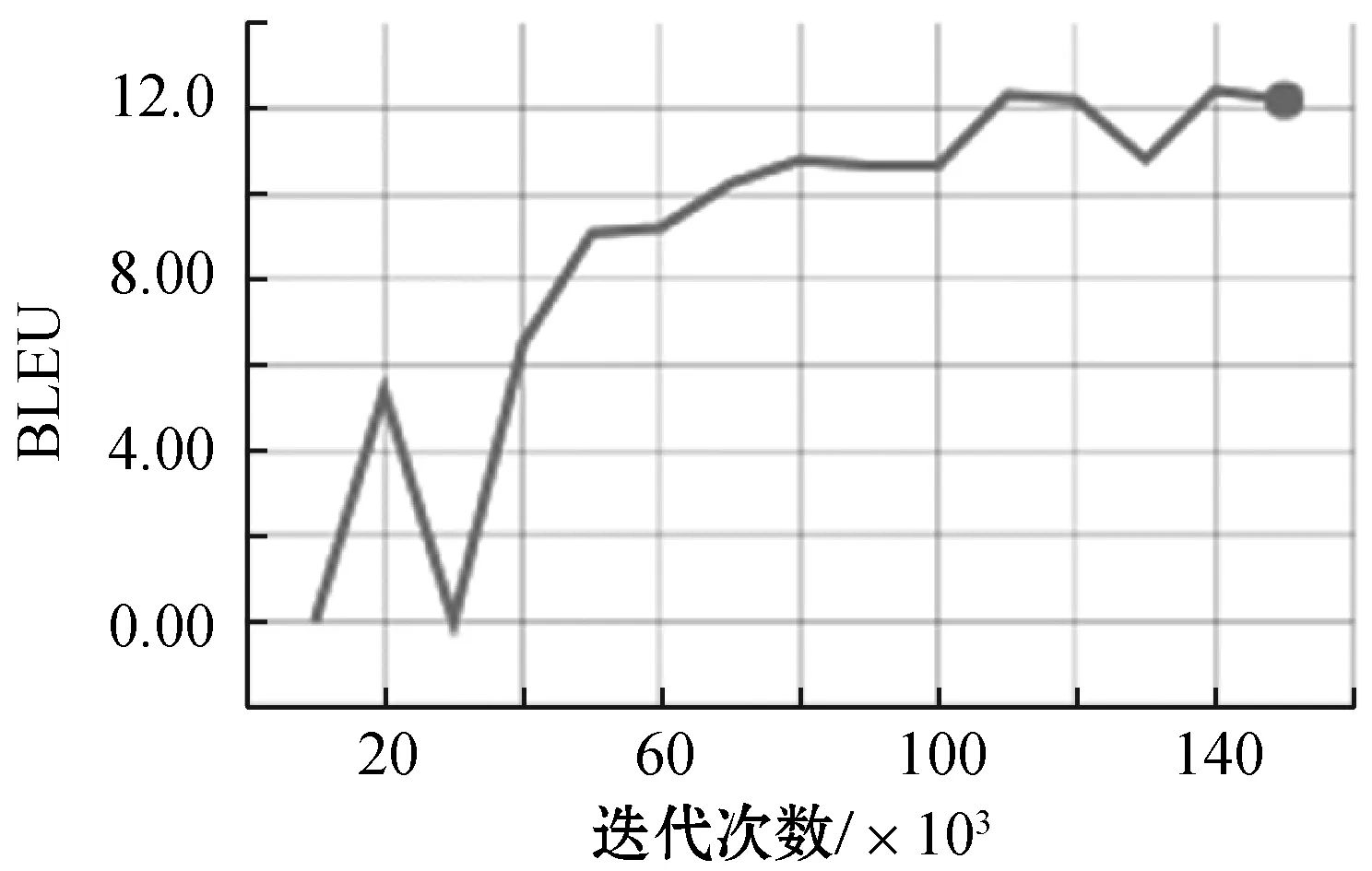
图7 BLEU值
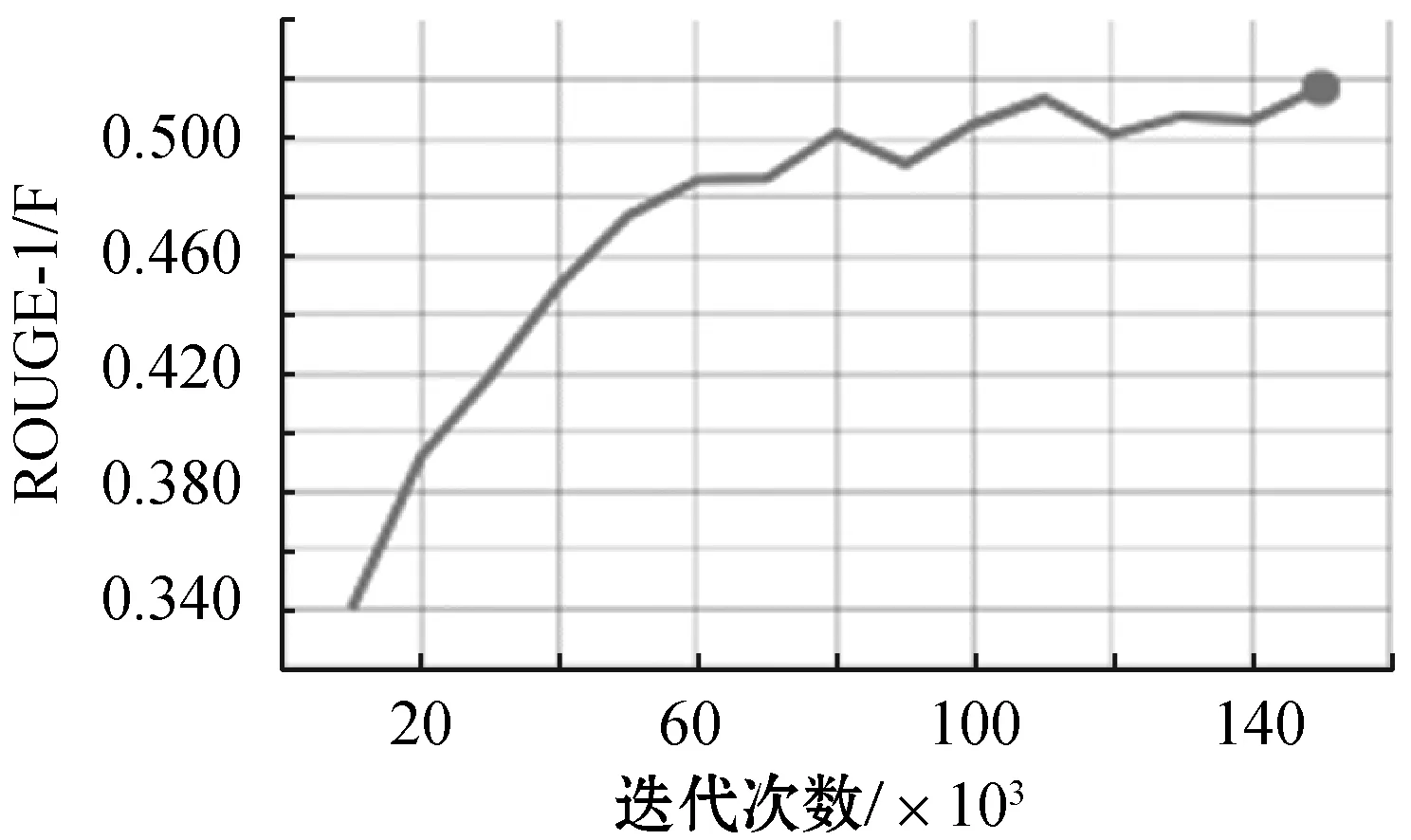
图8 ROUGE-1/F值

图9 ROUGE-1/Precision值
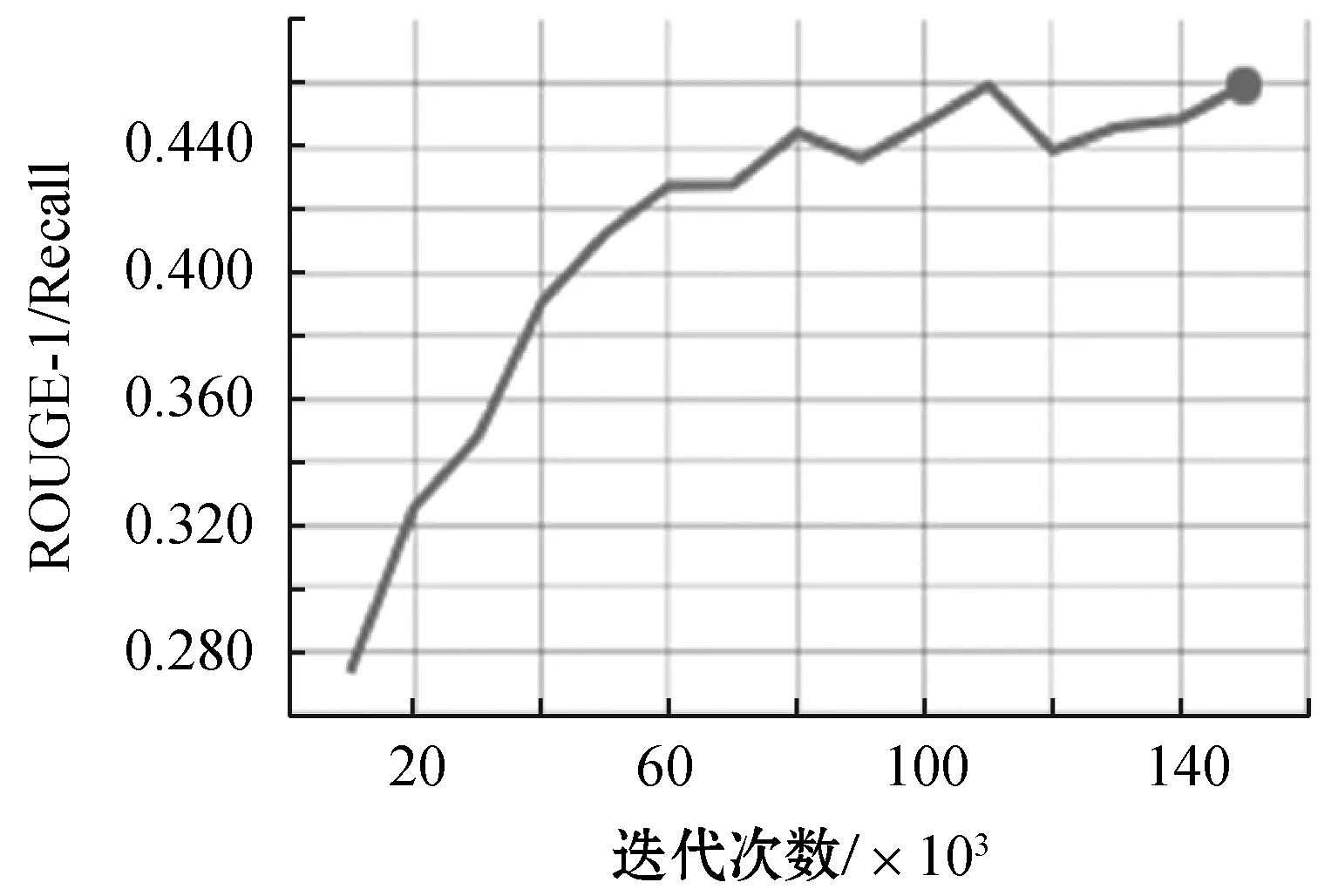
图10 ROUGE-1/Recall值
表8给出了对于预警文本推荐,模型生成的得分最高的推荐结果与标准答案的样例。从表中可以看到,对于编号1~3的样本,模型生成句与原始参照句基本一致,说明Seq2Seq模型在句子生成上的优势。对于编号为4的样本,模型生成句虽然与标准答案不完全一致,但所含的内容词也反映了答案的意思。
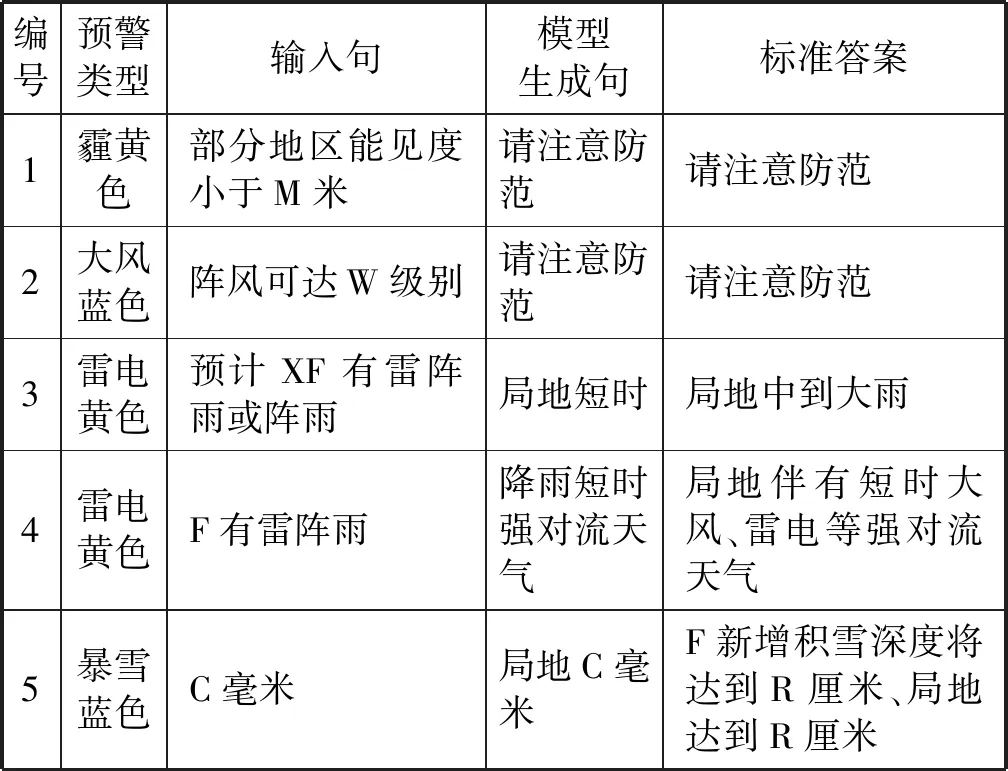
表8 输入句、模型生成句与标准答案示例
一个有意思的样本是样本5,模型生成句为“局地有C毫米”,而标准答案是“F新增积雪深度将达到D厘米、局地达到D厘米”。显然,模型生成句表达了降水,而标准答案表达为降雪。针对该预测错误进行分析,得到这两句话所在的完整预警文本如表9所示,抽取的句对如表10所示。
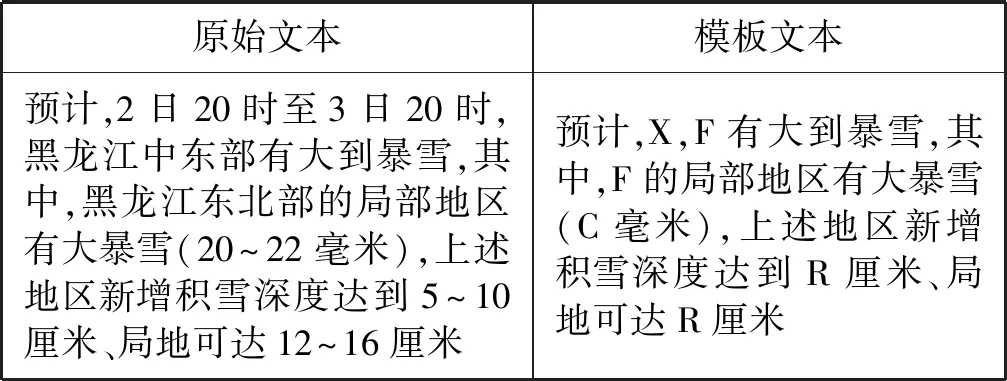
表9 样本5所在的完整预警文本
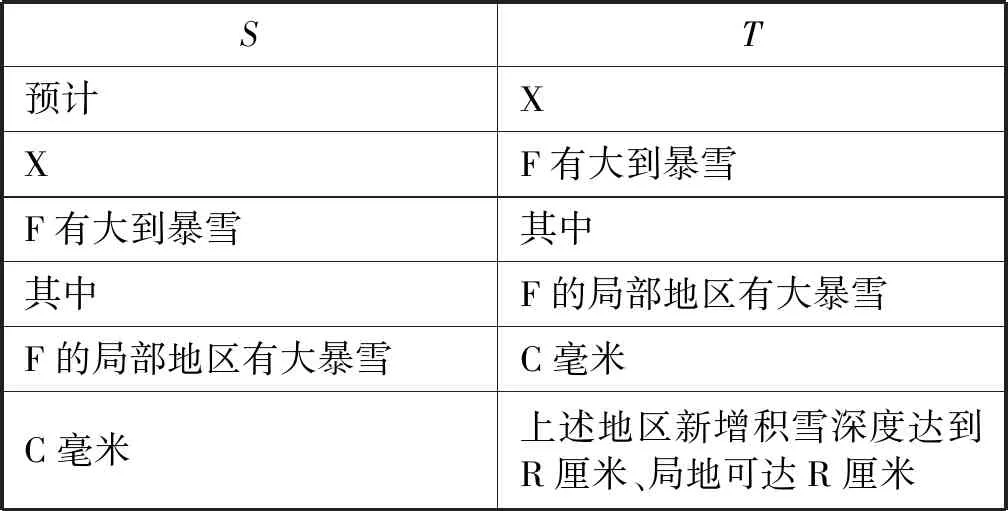
表10 样本5抽取的句对
“C毫米”是从括号文本中抽取出来的单独子句。因为对于降水预警文本,“C毫米”也是一个常见的短语,所以根据“C毫米”,模型会输出和降水相关的下半句。
这个现象说明,目前使用基本Seq2Seq模型不考虑预警文本的背景信息(即“预警类型”、“预警级别”等),仅使用当前句子信息来预测下一个句子,会造成预测结果与实际结果的偏差。融合预警类型信息进行推荐还需要进一步研究。
4 结 语
本文对气象文本推荐问题展开研究,在预警文本上实现了基于Seq2Seq模型的文本推荐系统。首先,进行气象要素抽取,将历史预警文本转换为模板文本;然后,从模板文本中抽取句对;最后,基于句对构建推荐模型。其中气象要素抽取使用基于CRF的抽取方法完成。测试结果表明,气象要素抽取对“影响范围[F]”类型的抽取精度(F值)相对较低,其他类型的抽取范围精度较高。预警文本推荐使用基于神经网络的Seq2Seq模型,并且针对气象预警文本生成的特殊性,对Seq2Seq模型的组件进行了定制。实验结果表明,本文方法进行文本推荐的BLEU值上可以达到12.21,具有一定实用性。此外,我们对其中一些预测错误的情况进行了分析。未来会把预警类型和预警级别作为上下文向量,引入到预警文本推荐中。
猜你喜欢
作文周刊·小学一年级版(2022年24期)2022-06-18
包装工程(2022年1期)2022-01-26
成都信息工程大学学报(2021年3期)2021-11-22
意林原创版(2021年7期)2021-08-03
领导决策信息(2018年46期)2018-04-20
现代农业科技(2016年22期)2017-03-24
现代农业科技(2016年21期)2017-03-06
小说月刊(2014年11期)2014-04-18
对联(2011年6期)2011-09-18
