
一种基于K均值聚簇的虚拟机分类与部署方法
2019-08-14 10:02李俊雅牛思先
计算机应用与软件 2019年8期
李俊雅 牛思先 程 星
1(济源职业技术学院 河南 济源 459000)2(百色学院信息工程学院 广西 百色 533000)3(郑州大学计算机学院 河南 郑州 450001)
0 引 言
云计算技术的出现使得大规模数据中心的建立可以更好地满足社会对于计算能力的巨大需求[1]。然而,这种大规模云数据中心正在消耗庞大的电力资源,进而导致的高能耗和巨量的碳排放问题。研究表明[2],2013年,全球数据中心的总体电力消耗约4.35千兆瓦特,并且以每季增长速率15%递增。云数据中心的高能耗会导致一系列问题,包括:能量浪费、较低的投入产出率、系统稳定性以及带来温室效应的碳排放[3]。
另一个关键问题是如何在确保服务质量QoS的前提下降低数据中心能耗。云系统中的QoS通常以服务等级协议SLA的形式表达。然而,目前数据中心的资源利用率仅为50%左右,较低的资源利用率会导致巨大的能量浪费,改善主机资源利用率将有助于降低能耗。但是,一味改进主机资源利用率反过来会影响系统的QoS交付。因此,对于云数据中心而言,必须均衡地考虑能耗降低和SLA违例问题,设计高能效的部署方法。
为了降低能耗和SLA违例,实现数据中心的高能效,本文设计一种新的虚拟机部署算法,算法将根据处理负载,以自适应的方法设置三个门限值,将主机划分为具有不同负载的四种类型,包括:低载主机、轻量负载主机、正常负载主机和重载主机,并通过设计的虚拟机迁移选择算法对低载主机和重载主机进行虚拟机迁移,同时维持轻量负载主机和正常负载主机不变,以此在能耗降低和性能保障上作出均衡。
1 相关研究
目前,云数据中心的能耗管理方法分为三种:动态性能扩展DPS方法[4-6]、基于门限值的启发式方法[7-11]和基于历史数据统计分析的决策方法[12-14]。DPS方法中,系统组件可动态调整其性能以节省能耗,如逐渐降低CPU的频率或电压。DPS可在资源未充分利用的情况下大幅降低能耗。采用DPS方法的关键技术是动态电压/频率调整DVFS,DVFS可分为三类:基于间隔的DVFS、基于任务内的DVFS和基于任务间的DVFS。基于间隔的DVFS方法利用过去时段的CPU利用数据预测未来的利用率,并调整CPU性能,该方法在多核系统中比较最优在线算法具有更好的性能。相比而言,基于任务内的DVFS方法区分不同的任务并将其分配至不同速率的CPU上,该方法在负载提前预知的情况下表现得简单而高效,但不适用于负载变化的云系统。基于任务间的DVFS方法利用程序的结构知识,在任务内调整处理器频率进而节省能耗,但全局数据中心的能耗仍然较高。
基于门限值的启发式方法通过设置门限改善资源利用率,进而降低能耗并确保系统交付的QoS。文献[7]提出一种单门限方法ST,ST设置一个利用率门限值以确保所有主机的CPU占用在该门限以下,以此控制虚拟机迁移,其能耗节省优于DVFS。文献[8]提出双门限值方法DT,包括上门限和下门限,并确保所有主机的CPU占用处于两个门限值之间。对于CPU占用未处于两个门限值之间的主机,则需要进行虚拟机迁移。文献[9]基于双门限DT设计了一种改进PSO算法MPSO,该算法可以减少活动主机的数量和虚拟机迁移次数,以此降低能耗。文献[10]研究云数据中心的能效问题,并提出基于DT的虚拟机选择算法,该算法重点考虑了CPU占用率和资源满意度。文献[11]提出一种静态三门限虚拟机部署算法,在考虑能效的情况下将最优门限间隔设置为40%,实现了能效优化。以上基于门限值的启发式方法尽管可以节省大量能耗,但在未知可变的负载状况下显得并不适用。
基于历史数据统计分析的决策方法是改进数据中心能效的有效方法。文献[12]提出一种自适应双门限算法,该算法通过利用近期负载数据特征预测资源占用情况。文献[13]利用权重线性回归预测未来负载并优化资源分配。文献[14]通过虚拟机部署预测改进数据中心能效,但所考虑的负载类型为单一计算密集型,且仅考虑了能耗降低,而未考虑能量使用效率,即忽略了性能保障和SLA违例降低问题。尽管基于历史数据统计分析的决策方法可以大幅降低能耗,但已有工作未考虑负载类型,且仅考虑虚拟机部署过程中的能耗降低,而未考虑SLA违例等性能因素,全局提高能效。
2 优化算法设计
2.1 自适应门限值部署模型
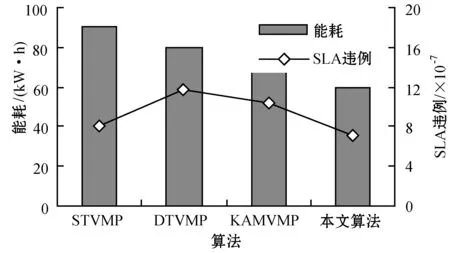
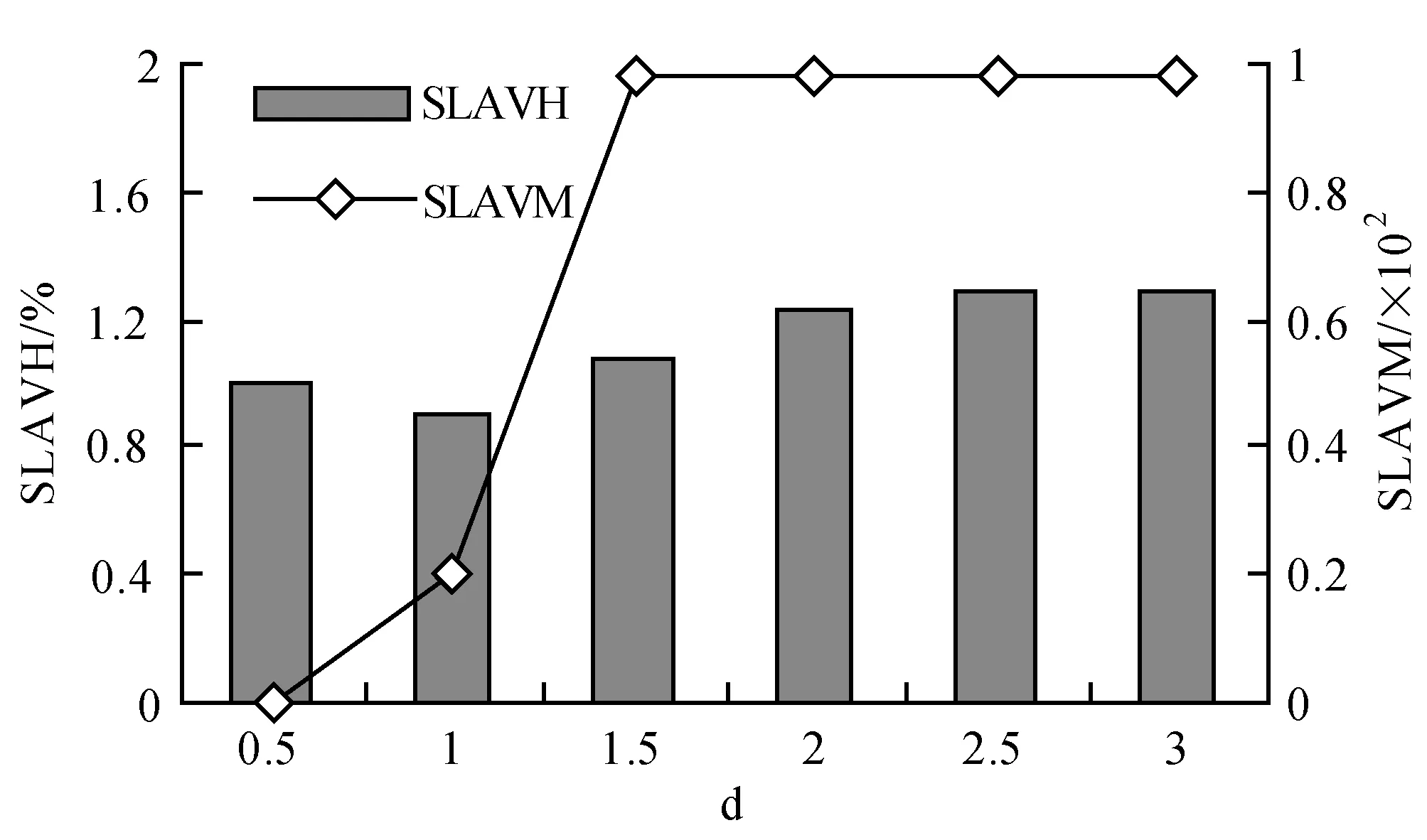
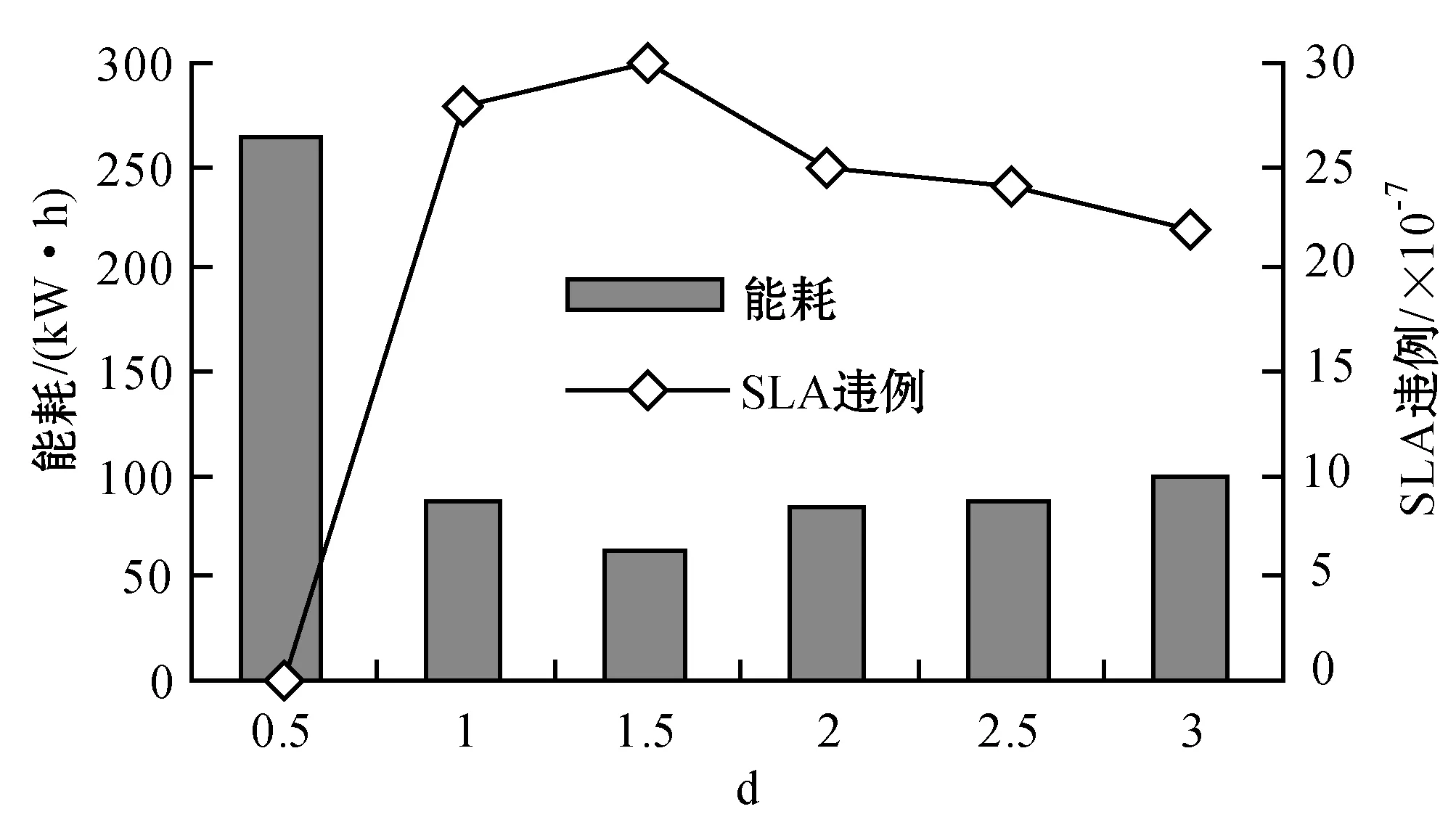
为了解决高能耗问题,将数据中心的主机基于CPU利用率进行划分,设置三个CPU利用率的门限值为Ta、Tb和Tc,且0≤Ta 图1 自适应三门限值下的处理流程 该模型重点需要解决两个问题:① 如何决定三个门限值的具体大小;② 如何在重载主机上选择需要迁移的虚拟机,以适应于计算密集型任务和I/O密集型任务的需求。以下分别进行讨论。 提出一种基于中档四分位的K-均值聚簇算法KMI计算三个门限值的大小。令H={h1,h2,…,hM}表示云数据中心中M个主机的集合,令D={U1,U2,…,Un}表示数据集,且Ut∈D(1≤t≤n)表示时间t时主机hf∈H的CPU利用率。算法1给出KMI算法的伪代码。 算法1KMI Input:D,k,d Output:Ta,Tb,Tc 1.R=Cluster(D,k) //K-均值聚簇算法 2.fori=1 toR.lengthdo 3.MRi=(max(Ri)+min(Ri))/2 4.MR[i]=MRi 5.endfor 6.IQR=TQ3(MR)-TQ1(MR) 7. 计算Ta、Tb、Tc 算法1详细说明:算法输入参数包括CPU利用率数据集D、聚簇数量k和预定义的合并因子d,算法输出为三个CPU利用率的门限值Ta,Tb,Tc。KMI算法的步骤1利用K-均值聚簇算法将D划分为k个簇:表示为{R1,R2,…,Rk},使得: 1)Ri={Upi-1+1,Upi-1+2,…,Upi}∈D 2) 0=P0 3)Ri∩Rj=∅,对于1≤i,j≤k。 步骤3中,对于每个簇Ri,算法获取的中位值为: MRi=(max(Ri)+min(Ri))/2 1≤i≤k (1) 式中:参数max(Ri)表示簇Ri的最大值,min(Ri)表示簇Ri的最小值,步骤4可以获得簇i的中位值MRi,该过程可产生MR={MR1,MR2,…,MRi,…,MRk}。算法在步骤6可获得集合MR={MR1,MR2,…,MRi,…,MRk}的四分位差为: IQR=TQ3-TQ1 (2) 式中:TQ3为MR的第三个四分位,TQ1为MR的第一个四分位。式(2)的目标是得到集合MR的IQR。算法在步骤7通过以下三个公式分别计算三个门限值为: Tc=1-d×IQR (3) Tb=0.9×(1-d×IQR) (4) Ta=0.5×(1-d×IQR) (5) 式中:d表示合并因子,描述系统进行虚拟机合并的积极程度。d值越小,能耗越小,SLA违例越高,反之亦然。 考虑数据中心的执行负载为计算密集型任务或I/O密集型任务。当一个应用任务的完成时间主要由CPU的速度决定时即认为是计算密集型任务;当一个应用任务的完成时间主要由等待输入输出操作完成时间决定时即认为是I/O密集型任务。换言之,此时将花费更多时间等待数据而非处理数据。这种情况下,CPU和内存将消耗更多能量。 1) MRCU算法:CPU利用率与内存利用率之比最大化算法。若某一主机由于计算密集型任务成为重载主机,则利用MRCU算法进行迁移虚拟机选择。MRCU算法选择迁移的虚拟机v需要满足: 2) MPCU算法:当主机由于执行I/O密集型任务发生重载时,为了降低潜在的SLA违例,可利用CPU利用率与内存利用率之积最小化算法MPCU处理。MRCU算法选择迁移的虚拟机v需要满足: 若主机由于I/O密集型任务出现重载,此时CPU和内存将消耗大部分能量,即CPU因素和内存因素具有同等重要性。式(7)将选择具有最小CPU利用率与内存利用率之积的虚拟机迁移,由于此时迁移能耗较少,对应的由虚拟机迁移带来的性能下降也有所减少,从而可以降低SLA违例。MPCU算法在选择迁移虚拟机时也同步考虑了CPU因素和内存因素。 基于三门限值和重载主机的虚拟机迁移选择,本节设计一种考虑同步降低能耗和SLA违例的虚拟机部署算法,并命名为最大能效算法VPME。过程如算法2所示。 算法2VPME Input:vmlist,hostlist,Ta,Tb,Tc Output:allocation of virtual machines 1. vmlist.sortByDeseasingUtilization() 2.for(vm:vmlist)do 3. minEnergyEfficiency=min,allocatedHost=∅ 4.for(host:hostlist)do 5.if(host meets the requirements of vm)then 6. CpuUtilize=getUtilizationAfterVm(host,vm) 7.if(Ta≤CpuUtilize≤Tb) then 8. power=host.getPower() 9. powerDiff=powerAfterAllocation-power 10. firstSlaBefore=getSlaTimePerActiveHost(host) //第一次SLA违例计算 11. firstSla=firstSlaAfterVM-firstSlaBefore 12. secondSlaBefore=getSlaMetric(host.getVmList() //第二次SLA违例计算 13. SLA=fristSla×secondSla//通过式(8)计算SLA违例 14. EnergyEfficiency=1/(powerDiff×SLA) //计算能效 15.if(EnergyEfficiency>minEnergyEfficiency)then //寻找满足虚拟机分配具有最高能效值的主机 16. minEnergyEfficiency=EnergyEfficiency 17. allocatedHost=host 18.if(allocatedHost≠null)then 19. allocated the Vm to host 20. return allocation of virtual machines 算法2详细说明:算法输入为虚拟机列表vmlist、主机列表hostlist以及三个门限值Ta、Tb、Tc,算法输出为虚拟机的分配结果。步骤1中,VPME算法首先按CPU利用率将所有虚拟机降低排列。步骤3对最小能效值进行初始化,并将已分配的主机集合初始化为空集,以备后续分配的更新。然后,对于数据中心的每台主机(步骤4),检测是否当前主机在可用CPU和内存大小上能够满足虚拟机的请求(步骤5)。若满足,进行虚拟机分配后获取该主机的CPU利用率(可见步骤6的变量CpuUtilize)。步骤7将维持该主机为轻量负载主机。步骤8-步骤9计算虚拟机分配前后该主机的功能差值。步骤10-步骤11计算虚拟机分配前后第一次的SLA违例(第一次SLA违例定义可参见实验部分式(9))。步骤13计算虚拟机分配前后第二次的SLA违例(第二次SLA违例定义可参见实验部分式(10))。步骤13计算SLA违例(见式(8)),步骤14计算能效值(见式(13)),步骤15-步骤17寻找满足虚拟机分配具有最高能效值的主机,步骤19完成虚拟机分配。算法时间复杂度为O(M×N),M为主机数量,N为虚拟机数量。 虚拟机部署优化是对2.4节执行虚拟机部署后的优化过程,过程如算法3所示。 算法3虚拟机部署优化过程 Input:Ta,Tb,Tc,hostlist Output:migrationMap 1.for(host:hostlist)do 2.if(utilization≥Tc)then //若为重载主机 //则迁移虚拟机至拥有最高能效值的主机 3. overUtilizedHosts=getOverUtilizedHosts() 4. vmsToMigrate=getVmsToMigrateFromHosts(overUtilizedHosts) 5. migrationMap=getNewVmPlacement(vmsToMigrate) 6.elseif(utilization //若为轻载主机,维持不变 7. lowUtilizedHosts=getLowUtilizedHost() 8. vmsToMigrateB=getVmsToMigrateFromLowHosts(lowUtilizedHosts) 9. migrationMapB=getNewVmPlacement(vmsToMigrateB) 10. migrationMap.addAll(migrationMapB) 11.returnmigrationMap 算法3详细说明:算法输入为三个门限值Ta、Tb、Tc、主机列表hostlist,算法输出为虚拟机迁移后的重部署结果。步骤3-步骤5通过利用虚拟机迁移选择算法(2.3节)在重载主机上选择需要迁移的虚拟机,并将其迁移至拥有最高能效值的主机上。步骤6-步骤9将维持正常负载主机和轻量负载主机不变。步骤10选择低载主机上的所有虚拟机迁移至拥有最高能效效值的主机上。算法3的时间复杂度为O(M),M为主机数量。 考虑到实验的可重复性,利用CloudSim工具包[15]搭建云数据中心环境。实验模拟了一个包括800台物理主机的数据中心,由HP Proliant G4和HP Proliant G5两种主机类型组成,数量各400台。主机具体参数如表1所示。虚拟机特征参考Amazon EC2的VM类型建立,具体描述如表2所示。 表1 机类型 表2 虚拟机类型 实验中的测试负载数据利用现实负载CoMon项目中的PlanetLab提供的负载数据,负载流数据参数如表3所示。 表3 负载数据特征/CPU利用率 两种主机类型不同负载状况下的能耗情况如表4所示。 表4 不同CPU利用率下的能耗 云数据中心拥有两种类型的SLA违例:单个活动主机的SLA违例SLAVH和由于虚拟机迁移导致的SLA违例SLAVM。本文将该指标综合定义为: SLAV=SLAVH×SLAVM (8) SLAVH表示PH的SLAV时间与PH活动时间的比例,即: 式中:M表示PHs的数量,Tsj表示PHj所经历的CPU100%占用从而导致SLA违例的总时间,Taj表示PHj在活动状态下经历的总时间。 SLAVM表示由于迁移所导致的虚拟机性能下降与虚拟机请求的总体CPU能力间的比例,即: 式中:N表示虚拟机数量,Cdi表示由于迁移导致的虚拟机i的性能降低估算,Cri表示在其生命周期内虚拟机i请求的总体CPU能力。实验中将Cdi估算为虚拟机i所有迁移中CPU利用的10%。这意味着每次迁移可能导致SLA违例。一次动态迁移的时间长短取决于虚拟机使用的内存总量和可用的网络带宽。 虚拟机i带来的性能下降为: (11) 能效指标包括两个方面:能耗和SLA违例。基于前文定义,能效EE定义为: 式中:ppower表示能耗,ISLA表示SLA违例指标。EE值越高,能效越高。 实验1观察三门限的设置对于性能的影响。分别与基于单门限的虚拟机部署算法STVMP[7]、基于双门限值的虚拟机部署算法DTVMP[10]及基于平均绝对中位差的多门限值算法KAMVMP[14]进行比较。单门限值设置为0.7,双门限值设置为0.2和0.8,三门限值由本文的KMI算法产生,算法中的d值设置为1,测试负载以计算密集型任务为主,因此,利用MRCU算法进行迁移虚拟机选择,即本文算法=KMI-MRCU-1,1代表d值。实验比较分析了能耗、SLA违例、SLAVH、SLAVM、虚拟机迁移量以及算法得到的能效值等性能指标,结果如图2-图4所示。总体来看,单门限值算法的性能是最差的,主要原因是单门限值仅设置了CPU利用率的上限,会导致很多主机利用率较低,静态功耗较多。双门限值同时设置了CPU利用率的上下限,可以避免部分主机利用不充分的问题,但上下限的区间跨度仍然较大,难以适应动态的负载需求。KAMVMP算法虽然是基于多门限值思想,但仅是以最小化能耗为目标的,其能效并不一定最优。且其虚拟机迁移选择是基于内存最小原则设计的,无法适应于不同类型的负载执行。综合比较,本文算法具有更高的能效(能耗和SLA违例)。 图2 能耗与SLA违例 图3 两种类型的SLA违例 图4 能效与VM迁移量 实验2测试执行计算密集型任务时d值的变化对算法性能的影响。选取3/3/2011数据集合作为计算密集型任务的测试数据。测试算法=KMI-MRCU-d,d的取值范围为[0.5,3],递增步长为0.5,结果如图5-图7所示。由图5可知,d=2时能耗最小,但d=1时SLA违例最小。同步考虑到能耗与SLA违例(即能效),并结合图7中的EE指标,d=1时算法具有最优能效。总体来看,过高的d值反映出虚拟机具有更高的合并积极性,能耗与SLA违例指标均表现出先降低后升高的趋势,因此d值的选取至关重要。 图5 能耗与SLA违例 图6 两种类型的SLA违例 图7 能效与VM迁移量 表5将本文算法KMI-MRCU-1与同类型算法进行系统比较,同样选取能耗、SLA违例、SLAVH、SLAVM、虚拟机迁移量以及算法得到的能效值等性能指标。对比算法为非功耗感知算法NPA(以满载形式执行所有任务)、动态电压/频率调整算法DVFS、THR-MMT-1算法[12]、THR-MMT-0.8算法[12]、MAD-MMT-2.5算法[12]、IQR-MMT-1.5算法[12]及KAM-MMS-2算法[14]。指标中,能效EE越高越好,而能耗、SLA违例、SLAVH和SLAVM则越小越好。对于虚拟机迁移量,过多或过小的迁移量均不利于能效的提高。NPA未采用任何能量优化机制,能耗是最高的,DVFS通过降低CPU性能可以降低部分闲置能耗。NPA和DVFS均未涉及虚拟机迁移,因此其他性能指标均以“-”表示。 表5 计算密集型任务下的性能系统比较 综合来看,本文算法KMI-MRCU-1比较其他几种算法,在能效、能耗、SLA违例、SLAVH、SLAVM以及虚拟机迁移量等指标上均有5~10倍的性能提升,其原因可概括为:1) THR-MMT-1、THR-MMT-0.8、MAD-MMT-2.5和IQR-MMT-1.5均还是双门限值框架,而KMI-MRCU-1是基于自适应三门限值的,多门限值的效率更高;2) 四种比较算法更侧重于虚拟机部署过程的能耗优化,而本文算法考虑的是能效的最大化;3) 对于重载主机的发现,四种比较算法均利用历史数据的统计分析进行计算,而本文算法则是通过基于历史数据的K-均值聚簇方法计算的;4) 对于迁移虚拟机的选择,四种比较算法均只考虑CPU或内存利用率的单一因素,而本文算法则同时考虑了这两个因素。 与KAM-MMS-2算法比较,本文算法仍是更优的,原因在于:1) KAM-MMS-2算法仍仅是考虑能耗优化的,不是能效;2) 对于计算密集型任务,本文采取的重载主机发现与迁移选择机制更优。 实验3测试执行I/O密集型任务时d值的变化对算法性能的影响。选取22/3/2011数据集合作为I/O密集型任务的测试数据。测试算法=KMI-MPCU-d,d的取值范围为[0.5,3],递增步长为0.5,结果如图8-图10所示。由图8可知,d=0.5时能耗最小,而d=3时SLA违例最小(d=0.5时算法部署失效)。同步考虑到能耗与SLA违例(即能效),并结合图10中的EE指标,d=2时算法具有最优能效。对于I/O密集型任务,能耗较计算密集型任务更少,但SLA违例更高。 图8 能耗与SLA违例 图9 两种类型的SLA违例 图10 能效与VM迁移量 表6对I/O密集型任务下对算法性能进行了系统比较。同样地,本文算法在各个性能指标上也拥有更好的效果。其原因可参见表5的注释。 表6 I/O密集型任务下的性能系统比较 为了降低数据中心能耗与SLA违例,提出了一种基于三门限值的高能效虚拟机部署优化算法。算法基于历史数据集,设计了一种中档四分位的K-均值聚簇方法以产生主机CPU利用率的三个门限值;然后,依据三个门限值,将主机划分为低载主机、轻量负载主机、正常负载主机和重载主机四种类型;最后,为了对重载主机实施虚拟机迁移,分别针对计算密集型任务或I/O密集型任务设计了两种虚拟机迁移选择方法。结果表明,所提算法不仅可以有效降低能耗,而且SLA违例也较低,具有更高的能效。
2.2 自适应三门限值取值机制
2.3 重载主机上虚拟机迁移选择
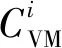

2.4 能效最大化的虚拟机部署
2.5 虚拟机部署优化
3 仿真实验
3.1 实验环境搭建




3.2 SLA违例指标

3.3 能效指标
3.4 实验结果








4 结 语
猜你喜欢
锦绣·上旬刊(2022年2期)2022-05-16防爆电机(2021年3期)2021-07-21电脑知识与技术(2020年32期)2020-12-29现代营销·理论(2019年10期)2019-09-10家用电器(2019年6期)2019-09-10奋斗(2018年4期)2018-05-14汽车与安全(2017年4期)2017-12-07投资北京(2017年1期)2017-02-13北京汽车(2016年5期)2016-11-10专用车与零部件(2016年2期)2016-04-11
