
考虑能耗和准时的混合流水线多目标调度
2019-08-07 03:17:30周炳海刘文龙
上海交通大学学报 2019年7期
周炳海, 刘文龙
(同济大学 机械与能源工程学院,上海 201804)
符号说明:
CD—单位时间延迟交货成本
CI—单位时间库存成本
Eijk—工件i在第j个加工阶段机器k上的能耗
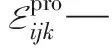
Ejk—第j个加工阶段第k台机器的能耗
pi—工件i的总体加权交货惩罚
Pjk—第j个加工阶段第k台机器的功率
Pijk—工件i所在第j个加工阶段第k台机器的功率
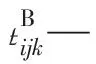
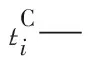
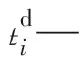
tjk—第j个加工阶段第k台机器耗时
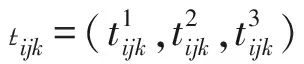
tiljk—第j个加工阶段第k台机器上工件l正好排在工件i后的加工时间
πjk—第j个加工阶段第k台机器上被指派的加工任务集合,πjk={πjk(1),πjk(2),…,πjk(njk)}
σπjk(r-1)πjk(r)—当σπjk(r-1)πjk(r)=1时,表示第j个加工阶段第k台机器上被指派的第(r-1)和第r个加工任务中执行1次开关机
φjkir—当φjkir=1时,表示工件i在第j个加工阶段第k台机器上被指派的加工任务集合中排第r位
上标
idel—闲时
off—关机
on—开机
pro—加工
set—换模
混合流水线调度问题(HFSP)是传统流水线调度问题的一种推广,具有很强的工程背景,广泛存在于化工、汽车、纺织、半导体等领域.HFSP同时具有流水线作业和并行机两者的综合特征:工艺流程复杂、不确定性大、求解调度问题难度高,在数学领域属于非确定性多项式(NP-hard)问题.因此,研究HFSP具有重要的学术意义和应用价值[1].
在现实环境之中,由于人为因素和市场波动,HFSP 的生产参数往往是不确定的,可以通过模糊集理论进行描述[2].Hong等[3-4]首次将离散模糊概念从流水线系统推广应用于研究HFSP问题,并在此后继续推广到了连续模糊领域.Pinedo等[5]提出与工件加工次序相关的换模时间可能会占据生产中机器20%的有效工作时间.
近年来,受到全球变暖和高环保要求等因素的影响[6],耗能占全国可消费能源总量 72.8%[7]的制造业开始集中关注如何在提升生产效率与减少能源消耗之间寻求一个平衡点,以达到绿色生产的目标.相关研究人员开始将研究内容聚焦于具有节能意识的调度目标上[8].Dai等[9]针对HFSP提出一个节能模型,可以同时优化最大完工时间和能源消耗.Luo等[10]在此研究基础上提出电价变动模型,基于高低电价优化电力成本.然而,目前对于考虑能耗的混合流水线在生产中的不确定性及与工件加工次序相关的换模时间约束问题的相关研究较少,缺乏可以参考的研究依据.
因此,本文以最小化系统能耗和准时交货惩罚作为双优化目标,使用模糊数描述加工时间和交货期.同时,考虑换模时间与工件加工次序相关及并行机不相关两种约束,对HFSP开展研究.最后,通过理论分析和数值实验验证改进型双目标差分进化算法的可行性和有效性.
1 问题描述
同时考虑换模时间与工件次序相关及并行机不相关两种约束的HFSP可描述如下:n个工件在流水线上进行s个阶段的加工,每个阶段至少有1台机器且至少有1个阶段存在并行机;同一阶段的各机器加工同一工件所需的加工时间不同且互不相关,所需的换模时间与加工的上一个工件种类相关;在每一阶段,各工件均要在其中任意1台机器上完成1道工序.已知工件各道工序在各机器上的处理时间,要求确定所有工件的排序以及在每个阶段机器的分配情况,使得某种调度指标最小[1].HFSP 示意图如图1所示,其中ms表示阶段s并行机数量.为了更加有效地描述HFSP,现做如下假设:① 工件的加工一旦开始不可中断;② 1台机器同一时刻只能加工1个工件;③ 1个工件同一时刻只能在1台机器上加工;④ 工件可在每阶段的任意机器上加工.
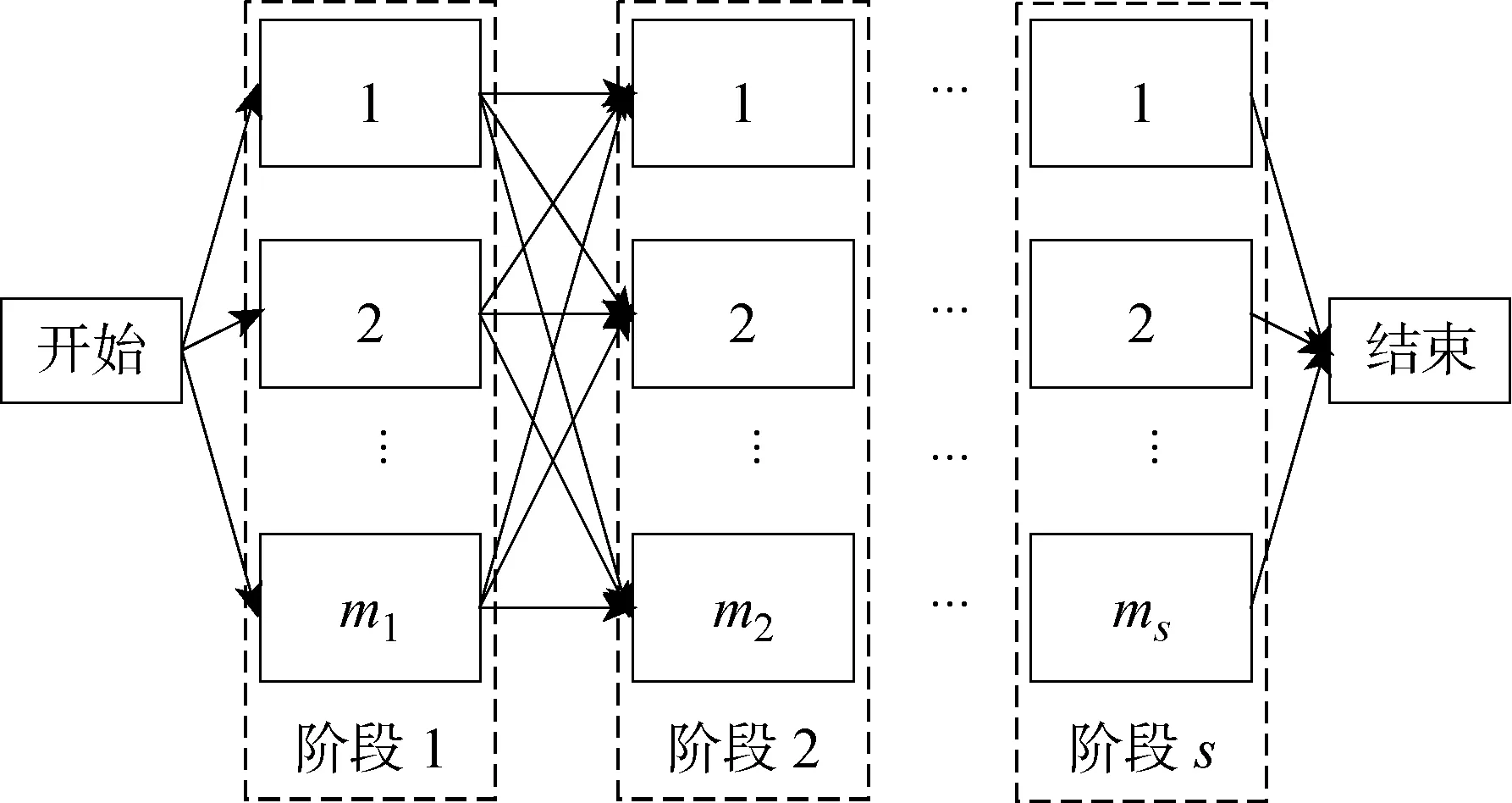
图1 HFSP示意图Fig.1 Illustration of HFSP
根据问题描述和问题假设对系统问题的建模如下:
minF=(f1,f2)
(1)
(2)
(3)
式中:
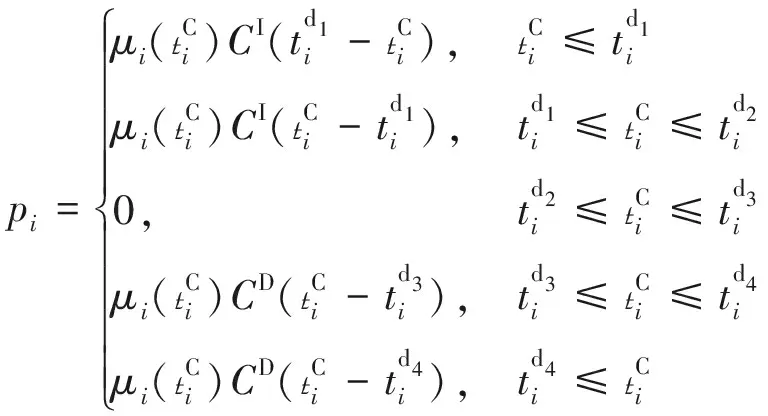
(4)
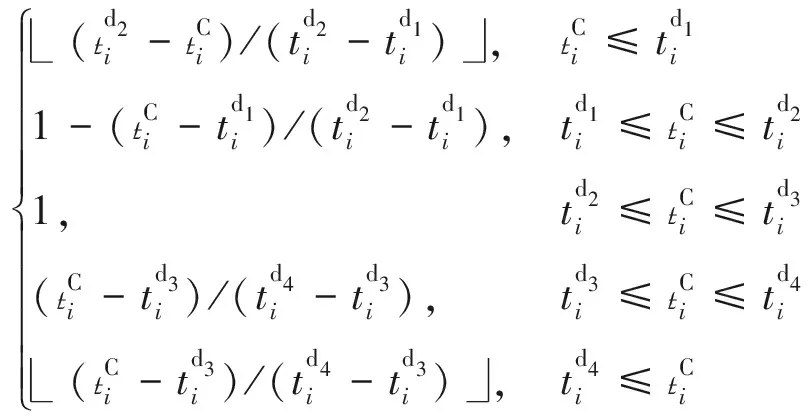
(td2i-tCi)/(td2i-td1i),tCi≤td1i1-(tCi-td1i)/(td2i-td1i),td1i≤tCi≤td2i1,td2i≤tCi≤td3i(tCi-td3i)/(td4i-td3i),td3i≤tCi≤td4i (tCi-td3i)/(td4i-td3i),td4i≤tCiìîíïïïïïïïïï
(5)
(6)
(7)
(8)
(9)
σπjk(r-1)πjk(r)=
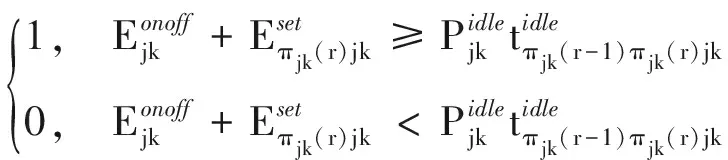
(10)
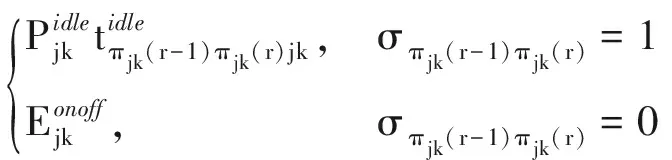
(11)
(12)
(13)
s.t.
(14)
(15)
(16)
(17)
(18)
(19)
l=1,2,…,ni=1,2,…,nj=1,2,…,s



当r=1时,设
模型中,式(1)为模型的目标;式(2)和(3)为目标函数;约束(14)表示每个优先级位置只能对应1个工件;约束(15)表示任一阶段每个工件只能由1台机器加工;约束(16)表示每一工件在进行下一道工序前必须完成当前工序;约束(17)表示每个工件在任一阶段上的加工完成时间小于其完工时间;约束(18)表示同一阶段调度排列中排位越靠前的工件开始处理的时间越早;约束(19)表示同一阶段分配在同一机器上的排位靠后的工件必须等排位靠前的工件加工完后才可进行加工.
2 改进型双目标差分进化算法
采用传统的解析方法并不能求解中大规模的调度问题.目前,国内外研究人员均基于启发式算法对此类调度问题进行研究.Storn等[11]于1997年提出的一种非常有效的优化算法——差分进化(DE)算法,已经被广泛地应用于各工程领域.本文基于DE算法提出一种改进型双目标差分进化(MODE)算法,使用非支配排序以及拥挤距离评价策略比较与排序可行解.同时,引入优质解挑战机制[12]以及混沌搜索策略以保证算法的全局搜索能力.提前设置以下初始参数:种群规模(Q);解的寿命(L);解的年龄(A);最大循环次数(Y).MODE算法的具体步骤如下.
步骤1编码.根据模型特点,采用双染色体形式表示可行解的编码.编码的每一个元素包含一个工件在1个阶段中的机器指派情况和待加工次序.例如,一个HFSP中有5个待加工工件和3个阶段,各阶段中的机器数分别为2、1、3,一个可行解的编码可写成:
编码首行的3个元素表示工件1分别在3个阶段的1,1,3号机器上加工,且在各机器上的排序分别是1,2,1.
步骤2初始化阶段.引入了NEH(Nanaz, Enscore, Ham)启发式方法[13]初始化MODE算法,建立基于NEH和随机生成的混合方法产生初始种群.首先,利用NEH启发式方法构建一个基础可行解,再通过成对交换方法生成Q/2个可行解,剩余Q/2个可行解随机生成.
步骤3基于反向的搜索.反向学习(OBL)是由Tizhoosh[14]为机器智能的种群初始化提出的一种方法.对初始种群Q0反向学习后可以得到反向解集,将该解集与Q0合并后共同评估选择得到新解集.OBL的应用能够有效地提高群体的多样性,避免算法陷入局部最优.
步骤4差分变异.使用DE/current-to-best/1策略以精英解针对新解集的每一个解xi生成其变异解νi.变异解经过与原解的交叉操作得到试验解,通过比较适应值决定是否替代原解.差分变异过程完成后得到的解集将再次经过反向学习得到新解集,与原解集合并后利用非支配排序和拥挤距离计算得到新种群及作为领导解集的最优Pareto前沿.其中,以拥挤距离最小的解作为精英解.
步骤5挑战机制.为避免陷入局部最优解,1次循环内领导解集中的每个优质解都需要比较当前年龄值(未更新迭代数)和寿命,判断其是否需要接受挑战.一个解每经过1次差分变异或混沌搜索,若被更新,则其对应年龄值置0,寿命重置为初始年龄;否则,其年龄值加1.一旦达到寿命限制,启动对该解的挑战机制.为了生成更具多样性和竞争力的挑战解,每次该算法都将从以下两种邻域搜索策略中随机选取一种用于生成挑战解,生成的挑战解分别为GPBX-α[12]和下式:

(20)
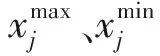
与经过多代进化的“年老”优质解相比,挑战解难以立即具备足够的竞争力,故较难在挑战机制中获胜.因此,对失败的挑战解再进行一次差分进化操作给予第2次挑战机会.挑战解一旦通过比较适应值战胜对应优质解,则取代优质解并为挑战解设置初始年龄值和寿命;若2次挑战均失败,则优质解的年龄值减1,并允许其进入下一次循环.
步骤6混沌搜索.在每次MODE算法循环的末尾引入混沌搜索,以彻底探索解空间.由于其独特的周期规律、固有的随机属性等特点,混沌搜索能够有效地更改粒子的位置,从而有助于提高算法的多样性.
利用下式将解向量连续化后计算每个维度对应的混沌数以构建混沌序列:
(21)
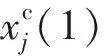
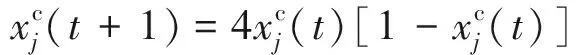
其中:t为混沌迭代数,t=1,2,…,10.同样地,混沌解若战胜对应原解,则取代原解并为混沌解设置初始年龄值和寿命.
步骤7算法终止判断.若算法迭代次数达到规定上限Y,则输出当前的最优Pareto前沿及其适应值;否则,进入步骤4.
3 数值实验与分析
所有算法都在MATLAB(2016a)环境下编程实现,并在主频为 3.2 GHz,内存为8 GB、Intel(R) Core(TM) i5-4570 CPU的PC机上进行数值实验,实验分析和结果如下.
3.1 评价指标
对于多目标优化问题,仅将获得的最优Pareto前沿及算法运行时间(CPU)作为评价指标不足以评判算法的性能优劣.因此,为了更为有效地判断得到的最优Pareto解的性能,还将选用Pareto解的个数(NS)、世代距离(GD)、解间距(SP)作为比较各算法的性能指标.其中,GD越小,表明算法收敛性越好;SP越小,表明算法多样性越佳.
3.2 参数设置
测试算例中,有n=20,40,60共3个水平.每个水平各自对应2个阶段数和机器数,共有12个组合.由于研究考虑的是确定性的调度问题,所以每次计算的初始阶段都会随机生成完整的测试数据:工件加工时间的模糊数最可能值服从[10,120]的均匀分布;模糊上下限取最可能值的75%与125%;加工功率服从[3,7]的均匀分布;工件的换模时间服从[10,20]的均匀分布;换模功率服从[2,6]的均匀分布;机器的开机时间服从[5,10]的均匀分布;关机时间服从[2,7]的均匀分布;开机功率服从[2,6]的均匀分布;关机功率服从[1,5]的均匀分布;闲时功率服从[2,6]的均匀分布;每个工件交货期的可能值表示为
将n=20,s=3,m=5的算例组合记为n20s3m5.数值实验中,将n=20,40,60的3类问题分别记为小、中、大规模问题.
3.3 数值实验分析
将MODE算法与带精英策略的非支配选择遗传算法(NSGA-II)、强度帕累托进化算法(SPEA2)进行对比实验,以测试问题的求解性能.这两种经典算法在解决多目标问题上都具有较好的求解性能.由于此问题的真实Pareto前沿难以得到,故采用以下方法获得近似前沿:各算法独立运行多次并记录每次获得的Pareto解集,从Pareto解合集中集结新的Pareto解集作为近似前沿.
MODE算法的参数设置对于其表现和效率有着重要的影响,实验采用田口方法确定各参数值,以保证算法的高效性.首先进行正交组合,然后测试各组参数以确定最优组合.据测试,当交叉率CR=0.7,第1个权重因子W1=0.6,第2个权重因子W2=0.4,可行解的初始寿命L=8时,MODE算法能以较高的质量对问题进行求解.MODE算法以及NSGA-II、SPEA2算法的参数设置如表1所示.
由于算法的单次运行结果具有一定的随机性,所以分别用上述3种算法对各算例进行20次独立数值实验,结果如表2所示.
由表2可知,当问题规模较小时,SPEA2与NSGA-II的解的个数、世代距离以及解间距性能指标都十分接近,略劣于MODE的相应性能指标.但是,在运算时间上,NSGA-II以及SPEA2所需要的运行时间略优于MODE;当问题规模逐渐变大时,MODE相对于NSGA-II、SPEA2在解个数、世代距离和解间距方面的优势逐渐扩大,其相对较大的运算时间也在可接受范围内.其中,MODE在Pareto解个数上的优势意味着有更多备选决策可供从业人员选择.
图2以n20s3m5,n60s7m15两个算例为例,表明了在小、大两种规模下各算法之间的Pareto前沿比较情况.由图2(a)可知,当问题规模较小时,NSGA-II、SPEA2求得的解集互有支配,并且都被MODE求得的解集所支配,但在部分位置差距较小;而随着问题规模的扩大,如图2(b)所示,MODE的Pareto解集基本支配了NSGA-II与SPEA2的 Pareto 解集,且分布更为均匀.数值实验对比结果证明了MODE算法的有效性.而MODE算法的优秀求解能力应该归功于算法基于DE算法的多个改进之处,其中包括基于NEH算法得到优质初始解、优质差分进化策略带来更好的邻域挖掘能力、挑战优质解更易于跳出局部最优解、反向学习和混沌搜索策略保证算法的全局搜索能力.

表1 不同算法的参数设置表Tab.1 Parameter settings of different algorithms
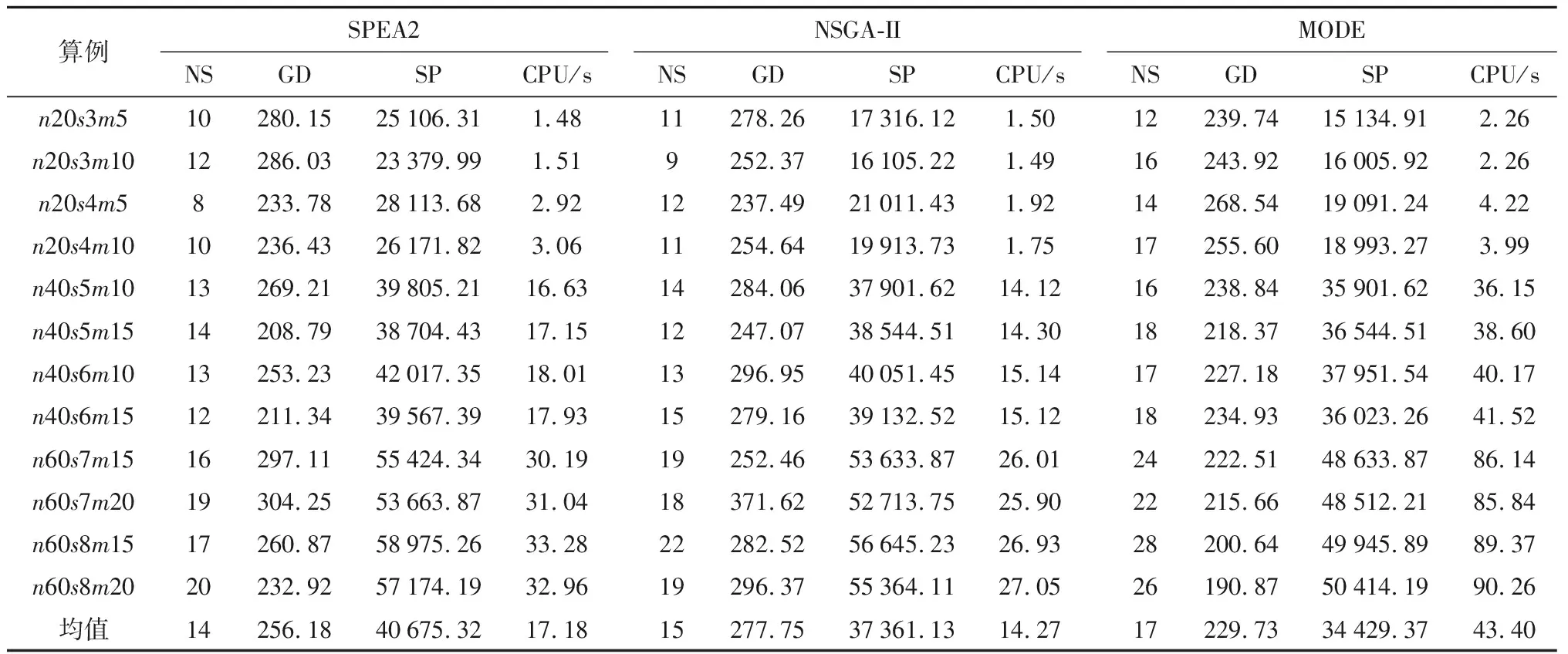
表2 不同规模调度问题的数值实验结果Tab.2 Experimental results for different instances
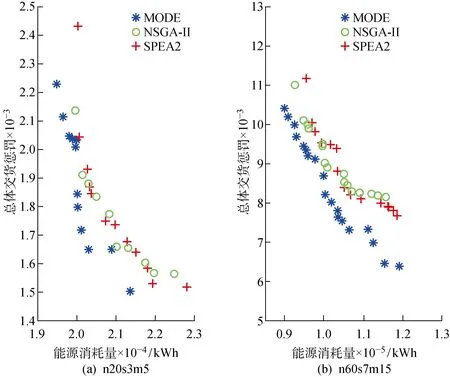
图2 两个算例下的Pareto解集Fig.2 Pareto solutions for two instances
4 结论
(1) 针对考虑并行机不相关、换模时间与工件加工次序相关两种约束的混合流水线系统,以保证准时交货和降低生产能耗为双调度目标,使用模糊数描述加工时间和交货期以处理系统的不确定性.
(2) 以差分进化算法为基础,引入NEH启发式方法构建高质量初始解,建立优质解挑战机制避免种群陷入局部最优,通过反向学习和混沌搜索探索全局解空间,提出改进双目标差分进化算法.
(3) 仿真实验验证MODE算法的有效性和较好的求解性能,丰富解决此类调度问题的理论方法.
(4) 未来的研究可在本文基础上考虑有限缓冲区,增加研究的复杂性和现实意义.
猜你喜欢
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
新世纪智能(数学备考)(2021年5期)2021-07-28 06:19:46
制造技术与机床(2019年7期)2019-07-22 03:42:06
电影(2018年8期)2018-09-21 08:00:06
现代机械(2018年1期)2018-04-17 07:29:48
焊接(2015年9期)2015-07-18 11:03:52
小猕猴智力画刊(2015年4期)2015-04-28 23:55:53
信息安全研究(2015年3期)2015-02-28 20:17:57
太空探索(2014年1期)2014-07-10 13:41:50
