
基于Self-Attention和Bi-LSTM的中文短文本情感分析
2019-08-05 01:42吴小华魏甜甜范婷婷
中文信息学报 2019年6期
吴小华,陈 莉,魏甜甜,范婷婷
(西北大学 信息科学与技术学院,陕西 西安 710127)
关键字:情感分析;字向量;自注意力机制;双向长短时记忆网络
0 引言
随着自媒体及社交平台的发展,社会焦点问题和突发事件讨论、电商商品评价等信息在网上广泛传播,产生大量短文本信息。例如,微博头条、微信留言、时事新闻的用户评论、电商买家评论等。对短文本进行情感倾向性分析,并从中抽取有价值的信息,一直以来受到工业界和学术界的普遍关注[1]。
文本情感分析是指对带有情感色彩的主观性文本信息进行分析、处理、归纳总结并判断其情感倾向[2]。短文本情感分析主要针对微博、电商买家评价、时事新闻评论等主观性短文本进行情感分类。1990年Jeffrey L Elman提出循环神经网络(recurrent neural networks,RNN)模型,这种网络结构被证明在处理时间序列数据方面更加有效[3]。1997年Hochreiter等提出并实现了长短时记忆网络(long short-term memory,LSTM),通过加入“门”的机制控制信息的传递改善了标准RNN的梯度消失或爆炸问题[4]。近年来,one-hot[5]、LDA[6]、CBOW及 Skip-gram神经语言模型[7]、Word2Vec[8]等词向量化表示方法的提出,为神经网络等深度学习模型处理自然语言奠定了基础,此后大量学者开始将深度学习应用于自然语言处理领域。但上述方法都是基于词的映射方式。由于中文词语之间无明显分割符,词向量映射方法的性能很大程度上依赖于分词的准确性。例如,“他说的确实在理”,有“他/说/的/确实/在理”和“他/说/的确/实在/理”等多种不同切分方式,从而会产生各种类型的语义歧义问题。针对中文无天然分隔符问题,2015年,许云等提出一种不需分词的n元语法文本分类方法,有效降低了数据稀疏带来的影响,提供了在深度学习模型中短文本预处理更高效的方案[9]。刘龙飞等提出基于字向量卷积神经网络的微博情感倾向性分析算法。实验证明,使用字级别的文本向量作为原始特征会优于使用词向量作为原始特征[10]。
上述方法虽在一般文本分类中取得了良好效果,但传统的深度学习模型将所有特征赋于相同的权重进行训练,无法较好地关注稀疏特征短文本中对情感类别贡献较为关键的特征。2014年,Google Mind团队首次提出Attention内容注意力机制进行图像识别。它可以聚焦于图像中局部较为重要的区域,能充分提取图像中区别他类的关键特征,有效提高,图像识别精度[11]。2016年,Bahdanau等将注意力机制应用到自然语言处理(natural language processing,NLP)领域进行机器翻译,在翻译准确率上较传统神经网络模型有较大提高[12]。2017年,谷歌提出一种自注意力机制(self-attention mechanism)用于机器翻译取得了比普通神经网络模型更好的性能。这种自注意力机制所需依赖参数少,使模型能够更好地学习文本特征。但由于缺乏足够位置信息,翻译结果中仍会出现某些词序错误现象[13]。Pavlopoulos等提出深层注意力机制,将其应用到审核用户评论,取得了比RNN更好的效果,证明了注意力机制在除机器翻译外的其他方面的有效性[14]。2018年Zhao等提出基于LSTM-Attention模型的文本分类方法,使用分层注意力来分别选择重要的词语及句子,依据较为关键的词语及句子进行分类,模型鲁棒性得到进一步提高,但是这种将词语和句子分开选择的做法忽略了语境信息[15]。2018年,江伟等从短语特征出发,提出了其于注意力机制的双向循环神经网络的短文本表示模型,在斯坦福情感树库数据集的5分类任务上取得了目前最好的准确率53.35%。但双向循环神经网络无法保留长距离依赖信息,且使用标准的Attention模型需要人工初始化较多参数,泛化能力较弱[16]。Yao等提出基于Attention的BiLSTM神经网络,定性捕捉其中有用的语义信息。从句子的两个方向学习语义特征对短文本进行情感分析,在斯坦福树图数据集与电影评论数据集上实验,证明该模型较无注意力模型的LSTM性能提高3%[17]。上述文献中结合注意力机制和相关优化的循环神经网络模型在一定程度上提高了分类的准确性,改善了循环神经网络模型对词语平均加权表示所造成的信息损失,以及难以在小规模数据集上训练的问题。由于短文本为片段性的描述说明、观点评论或情感抒发,区别于普通文本具有较鲜明的特性[18]:①短文本长度短小,包含内容较少,具有较强的数据稀疏性,造成短文本词向量表示不准确; ②以微博头条、用户评论为代表的短文本语言偏向口语化,非规范化。同时,还可能有错别字,缩写等噪声部分。若使用普通加权的特征表示方法,噪声会影响模型性能; ③微博头条、用户评论等短文本信息通常会夹杂着网络流行语等能显著表明情感倾向的成份。一般的分词工具面对日益繁多的的网络新词,分词性能较差。这些特性造成了一般文本情感分析模型在短文本领域性能较弱,故提高短文本情感识别精度,从中挖掘出更准确、更有价值的信息是非常有必要的。
本文针对传统词向量性能依赖分词的准确性及普通序列模型无法关注短文本稀疏特征中最关键特征的问题,在传统双向长短时记忆网络(bi-directional long short-term memory,BiLSTM)基础上引入了自注意力机制,提出一种基于字向量表示的Self-Attention和BiLSTM的中文短文本情感分析方法。注意力机制模仿人的视觉机理聚焦于句子中对类别区分度更为关键的特征,并动态调整特征权重,可以建模特征的依赖关系而不用考虑其在输入或输出序列中的距离[19]。而Self-Attention仅需关联单个序列的不同位置以计算序列的表示。输入和输出序列中。任意位置之间的路径更短,更容易获取文本内部依赖关系,在短文本领域表现出更广阔的前景,本文实验结果也表明了该方法的有效性和可行性。
1 相关工作
1.1 字向量表示方法
由于神经网络模型只能接受数值输入,所以就需要将字符文本进行数值化表示。文本数值化表示方法一般有向量空间方法、主题模型方法及Google提出的Word2Vec等,这些文本表示方法都需要对文本进行分词处理后将词语映射到多维空间中。由于中文语言的灵活性、复杂性等特点,某些句子人工断句困难,导致基于分词的向量化方法有其局限性。故本文在短文本处理过程中使用字向量表示方法,常用汉字数量较词语数量低几个数量级,也可以在一定程度上降低矩阵维度及稀疏性。同一文本其词向量和字向量表示结果区别较大。例如,“我的研究方向是短文本情感分析”。这句话如果表示为词向量形式为“我/的/研究/方向/是/短/文本/情感/分析”,而字向量表示形式为:“我/的/研/究/方/向/是/短/文/本/情/感/分/析”。
1.2 LSTM模型
LSTM是1997年Hochreiter等针对RNN的梯度消失和梯度爆炸问题而提出的改进模型[4]。它在原始RNN模型之上加入“门”来控制信息的传递,可在一定程度上避免梯度消失与爆炸问题,获取文本语义的长距离依赖信息。模型内部主要包括输入门it、遗忘门ft、输出门ot和记忆单元Ct等部分,具体结构如图1所示。

图1 LSTM-Cell内部结构图
首先,LSTM必须通过“遗忘门”决定将上一个Cell单元中哪些信息抛弃。它由sigmoid完成,通过接收上一时刻输出与本时刻输入的加权和计算出一个0到1的数,0表示完全抛弃,1表示全部保留。其计算如式(1)所示。
ft=σ(Wf·[ht -1,xt]+bf)
(1)
输入门控制Cell单元需要加入哪些信息,其计算过程如式(2)、式(3)所示。
输出门控制哪些信息用于此时刻的任务输出,其计算过程如式(4)、式(5)所示。
其中,Wi,Wf,Wo分别为输入门、遗忘门、输出门的权重矩阵;bi,bf,bo为输入门、遗忘门、输出门的偏置矩阵;σ、tanh为激活函数。
1.3 Attention模型
注意力机制来源于人的视觉处理过程,通过浏览全部信息来获得视觉注意力焦点,提取句子所表达信息的主要部分来获取句子中对于当前任务的关键信息。
Attention函数本质上是一个由诸多Query和Key-value组成的映射函数。其计算过程主要分为以下三步:
(1) 将query和每个key进行相似度计算得到相应权重,如式(6)所示。
f(Q,K)=QKT
(6)
(2) 使用softmax函数对权重进行归一化,如式(7)所示。
ai=softmax(f(Q,K))
(7)
(3) 将权重和相应的键值value进行加权求和得到最后的Attention值,如式(8)所示。
Attention(Q,K,V)=∑aiV
(8)
其中,Q代表查询,K-V是文本向量键值对。
2 基于Self-Attention机制的BiLSTM模型
为了关注短文本中对于分类任务更关键的信息,本文提出基于字向量表示方法结合Self-Attention机制和BiLSTM的短文本情感分析算法(character-SATT-BiLSTM)。利用改进后的算法能够更完整保留稀疏特征的短文本的信息,以便更好地提取短文本中对分类任务更重要的特征。基于Self-Attention机制的BiLSTM算法包含字向量输入层、双向长短时记忆网络层、Self- Attention层、Softmax层。其模型图如图2所示。

图2 基于Self-Attention机制的BLSTM模型图
2.1 任务定义
对于短文本t={w1,w2,…,wi},其中wi为文本中第i个字,短文本情感分析就是对短文本t进行特征提取分析,判断其所属的情感极性。考虑到一般情况下中性情感意义不大,故本文只将情感划分为两个极性,即:正向情感(Positive)和负向情感(Negative)。例如,“什么破酒店呀,位置太偏僻了!”,利用模型判断此评论情感为正向或负向。
2.2 文本向量化表示层
传统的词袋模型通常是基于统计学的文本表示模型,将句子仅仅看作是词语的集合,用词语的频率和概率进行统计,忽略了句子原来的结构信息。且由于短文本的特点导致此类特征均不突出,甚至会出现不可用的情况。主题模型较适用于长文本,对包含词语较少的短文本效果较差。Word2Vec虽已经取得了较好的效果,但这种方法对分词准确度要求较高同时,需要大量训练语料进行长时间训练。故本文考虑到字特征粒度更小的优点,采用字向量表示方法将每个字作为信息的基本单位,使用skip-gram算法以字为单位在大规模数据集上训练,将其映射为300维的字向量作为模型的输入。skip-gram算法的计算如式(9)所示。
(9)
其中,θ为模型参数集合;w表示字向量;c表示w的语境,即以w为中心,前后k个字所组成的集合;P(c/w)表示字w出现时某一语境c出现的概率;D表示所有字和它的语境c组成的集合;vm和vc表示w和c的列向量;算法训练的目的是寻找最优参数集合θ。
2.3 双向长短时记忆网络层

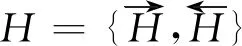
(10)
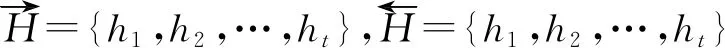
2.4 Self-Attention层
在权重调整层采用自注意力机制,传统的注意力模型需要依赖部分外部信息,是一种与外部信息对齐的思想,而自注意力机制只需要对自身信息训练来更新参数。如式(11)所示。
(11)

2.5 模型训练
(12)
3 实验
本文在字向量表示方法的基础上结合Self-Aattention 机制和BLSTM网络进行短文本情感分类。将训练文本采用字向量化表示,输入模型迭代训练,最后输出为预测值。实验环境如表1所示。

表1 实验环境
3.1 实验数据
数据集采用中文信息学会推出的中文倾向性分析评测(Chinese Opinion Analysis Evaluation,COAE) 2014年任务四微博文本数据集和酒店评论数据集,数据标注均由数据提供平台完成。COAE 2014数据集总共有40 000条微博数据,已人工标注10 000条数据。其中,带有积极情感的数据5 132条,带有消极情感的数据4 868条;酒店评论数据集选自中科院计算所谭松波提供的酒店评论语料,包含已标注的3 039条正向情感数据,2 813条负向情感数据。本文在已标注数据集上采用五折交叉验证进行多次实验,尽可能地降低随机性对实验结果的影响。部分数据样例如表2所示。

表2 实验数据样例
3.2 评价标准
本文采用国际通用评价标准准确率(Precision)、召回率(Recall)、F值(F-Measure)[19]对实验结果进行评价。准确率指分类器正确分类样本在数据集中的比例,它反映了分类器对分类样本的正确识别能力;召回率反映了分类器可以检测出来的所有正确样本占数据集中此类样本的比例;F值是准确率和召回率的调和均值,当α=1时,即最常见的F1值。其相关计算如式(13)~式(15)所示。
其中,TP、TN、FP、FN含义为表3所示。

表3 混淆矩阵表
3.3 实验参数设置
深度学习模型的参数设置非常关键,本文实验主要参数与参数值如表4所示。
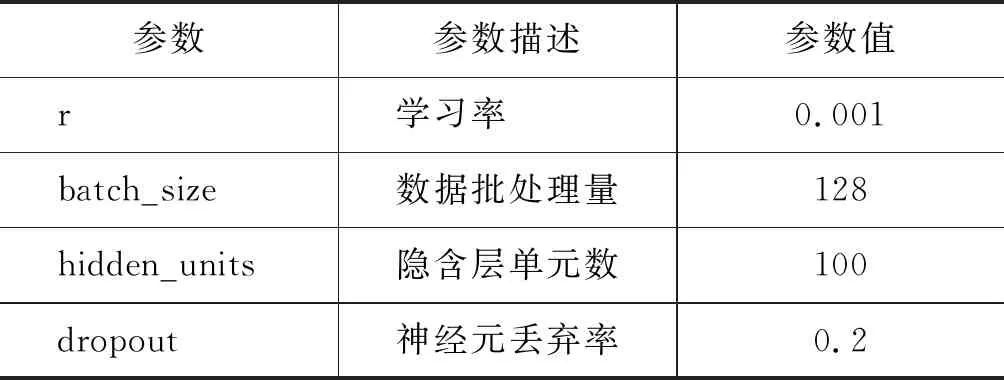
表4 实验参数表
3.4 对比实验设置
为了证明模型的有效性,将本文提出的字向量表示方法结合Self-Attention和BiLSTM的模型与下列目前较好的情感分析模型在相同环境下进行对比实验。模型中词向量或字向量分别使用Word2Vec和skip-gram算法在本文数据集上进行预训练得到,为了保证对比实验单一变量原则,均采用同一类预训练的词向量或字向量。
(1) LSTM。虽然LSTM是在RNN的基础上加入门限控制,但是几乎所有使用LSTM的论文其LSTM模型结构与参数设置均有某些不同,本对比实验使用的是Zaremba等描述的网络结构作为标准模型[21]。
(2) BiLSTM。采用Zaremba等描述的LSTM网络来构建BiLSTM网络模型。基于词的文本向量表示,结合双向长短时记忆网络捕捉句子的上下文情感语义信息。
(3) ATT-BiLSTM。Wang等提出的情感分析模型[22],在BiLSTM网络中引入Attention机制,采用BiLSTM提取文本序列化信息,Attention内容注意力机制依据特征对分类任务的重要程度区别表示。
(4) Word2Vec-ATT-BiLSTM。江伟等提出的基于Word2Vec对文本向量化表示方法,结合Attention和BiLSTM模型的短文本情感分析算法[16]。
(5) Word2Vec-SATT-BiLSTM。使用Word2Vec对文本向量化表示,结合Self-Attention和BiLSTM的短文本情感分析算法。
(6) character-SATT-BiLSTM。本文提出的使用字向量表示方法对文本向量化表示,结合Self- Attention和BiLSTM网络的短文本情感分析算法。
3.5 实验结果与分析
本文算法与其他对比算法分别在相同数据集上的实验结果如表5、表6所示。

表5 COAE数据集实验结果
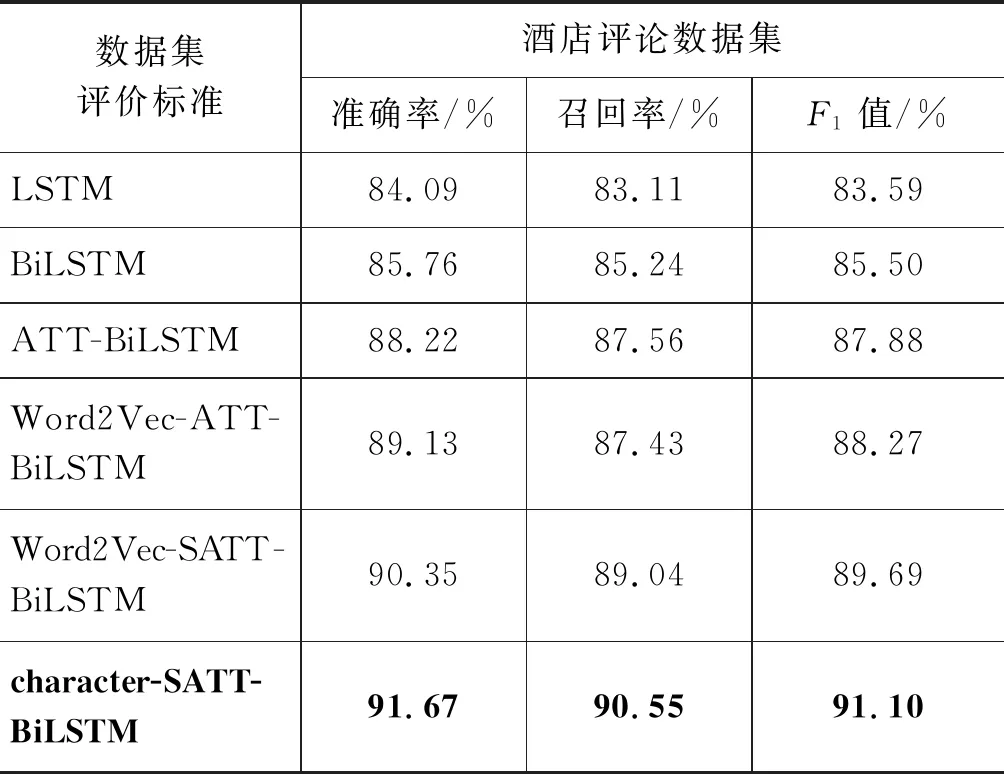
表6 酒店评论数据集实验结果
(1) 通过对比LSTM和BiLSTM算法的实验结果可知,BiLSTM由于增加了后向传播单元可以同时考虑上下文信息,通常较单向LSTM更优。
(2) 通过对比BiLSTM和ATT-BiLSTM算法的实验结果可知,通过加入注意力机制,能很大程度上获取句子的局部信息,模型准确率、召回率、F1值分别提高了2.46%、2.32%、2.38%。
(3) 通过对比ATT-BiLSTM和Word2Vec-ATT- BiLSTM算法的实验结果,表明使用Word2Vec词向量表示能保留词语之间的语义信息,降低语义信息丢失,有一定的性能提升。
(4) 通过对比算法Word2Vec-ATT-BiLSTM和Word2Vec-SATT-BiLSTM算法在两个数据集的实验结果可知,Self-Attention机制相比标准的Attention有不错的性能提升。因为Self-Attention可以减少普通注意力机制的外部参数依赖,在文本中通过关联单个序列的不同位置以计算序列的表示来获得更加准确的句子内部关键特征,同时输入和输出序列中任意组合位置之间路径更短,学习远距离依赖性就更容易,结合BLSTM提供的位置信息来建模序列前后关系,是自注意力机制与普通神经网络在短文本情感分类领域结合的探索,算法最终的F1值提高了1.42%。
(5) 通过对比算法Word2Vec-SATT-BiLSTM和character-SATT-BiLSTM的实验结果可知,因本文使用的数据集均为评论性文本数据,有内容短、用词随意性强等特点。故本文利用字级别的文本向量表示方法可以更加细粒度的提取到短文本稀疏特征,更完整的保留某些细节信息,利用Self-Attention对局部关键特征进行捕捉。同时,也可以降低分词错误产生的噪声影响,在两类数据集上的F1值分别较Word2Vec-SATT-BiLSTM算法提高1.15%和1.41%。本文方法在COAE 2014数据集上的准确率、召回率、F1值高于文献[23]的最好性能;在酒店评论数据集上的F1值优于文献[24],充分证明了本文算法的有效性。
4 结论
本文提出了基于Self-Attention机制的BiLSTM短文本情感分析算法。通过字向量对短文本向量化表示,利用BiLSTM提取短文本的上下文特征,引入Self-Attention机制对特征重要程度动态调整,在两类数据集上实验证明了字向量表示方法的基于Self-Attention和BiLSTM算法在短文本情感分类方面的有效性。
然而,本文算法主要考虑了短文本特征稀疏性问题,后期工作将会考虑对其他特征建模,提高算法性能。由于BiLSTM等序列模型属于递归模型,并行能力较弱,后期将在此方面做进一步改进。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
甘肃教育(2020年22期)2020-04-13
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
阅读与作文(英语高中版)(2013年12期)2013-12-11
