
基于正则化GRU模型的洪水预测①
2019-07-26 03:17段生月王长坤张柳艳
计算机系统应用 2019年5期
段生月,王长坤,张柳艳
(南昌航空大学 信息工程学院,南昌 330063)
我国是世界上洪水灾害频繁且严重的国家之一,洪水灾害不仅范围大、发生频繁、突发性强,而且损失大.特别是近年来,受全球气候变化和人类活动影响,极端天气事件和人为突发水事件明显增加.为了防治洪涝灾害,我国投入了大量的人力、财力与物力,建设了一批又批防洪工程,大大加强了我国抗灾御洪的能力.与此同时,我国还加强了非工程防洪措施.其中,洪水预报就是预防洪水灾害的重要非工程措施之一,也一直是专家学者关心的课题.因此提高洪水预测的准确性,减轻洪水带来的一系列灾害,对整个流域的防洪安全有着非常重要的意义.一般来说洪水预测有3 种不同的方法,经验法、统计法以及模型方法,但水文系统中多变量之间的非线性关系[1]远非传统方法能解决.随着科学技术的快速发展,如何把最新的科学技术引入到水文预报中,提高水文预报精度,成为大家的关注点.随着人工神经网络[2]等非线性科学技术在各个行业的广泛应用,为解决上述问题提供了机遇.
目前国内已有很多学者尝试将人工神经网络引入到洪水预测中.兰州理工大学的李晓丽等[3]提出了不确定,确定支持向量机在洪水预测模型中的应用,该算法利用数据间的关系去掉冗余的信息,简化算法运算,从而提高了洪水预测的精度;晋中市水文水资源勘测局的梁存峰等[4]提出了基于混沌自适应模型在洪水预测中的研究,该模型亦可在数据较少的情况下,取得精度较好的预测结果;福建省南平市水利局的金保明[5]在闽江十里庵流量预测中应用BP神经网络,将反向传播BP神经网络模型应用于洪水预测,并且预测精度符合要求;何勇、李妍琰[6]提出改进粒子优化 BP神经网络的洪水智能预测模型研究,以BP神经网络为基础,提取水位站往年平均径流量作为洪水属性,采用POS 算法对BP神经网络的各个参数进行优化,得出最优的BP神经网络预测适应度值,提高了预测的效率.以上算法都是比较传统的神经网络算法,虽然在一定程度上提高了洪水预测精确度,但是精度依旧不是特别理想.
本文提出一种基于正则化GRU神经网络的洪水预测模型来提高洪水预报精度,选用relu 函数作为整个神经网络的输出层激活函数[7-9],将弹性网正则化引入到GRU模型中,对网络中输入权重w实施正则化处理,以提升GRU模型的泛化性能.并将该模型应用于外洲水文站每月平均水位的拟合及预测,实验对比表明,弹性网正则化改进后模型的拟合效果和预测效果明显提高,该方法计算出的均方根误差较小,预测拟合程度较高.
1 GRU模型简介
传统的人工神经网络又被称为前馈神经网络FNN,是一种最简单的神经网络,包含输入层、隐藏层这种模型在处理序列数据时只能利用当前时刻的信息,无法利用历史信息.Elman 在1990年提出了循环神经网(Recurrent Neural Network,RNN),其隐藏层之间的节点也是有连接的,因此隐藏层的输入不仅包括当前时刻输入层的输入还包括上一时刻隐藏层的输出.理论上,RNN 能够对任何长度的序列数据进行处理,但是在实践中,当相关信息和当前预测位置之间的间隔不断增大时,RNN 就会丧失学习远距离信息的能力.这是因为RNN 通常使用的是BPTT 反向传播算法对网络进行优化,但是BPTT 无法解决长时依赖问题,因此该算法会带来神经网络梯度消失问题和梯度爆炸问题.
为了解决RNN网络的梯度消失和梯度爆炸问题,研究人员在优化学习算法和配置网络的技巧方面提出了较多的改进方法.文献[10,11]中介绍 Schimidhuber H 于1997年提出了长短期记忆单元(Long Short-Term Memory,LSTM),用于改进传统的RNN模型.LSTM神经单元是由一个或多个存储器外加三个自适应乘法门组成.它通过输入门、输出门和遗忘门来控制信息的流动和传递,通过对输入的信息进行剔除或增强到神经细胞单元中实现对细胞状态的控制,使得LSTM 可以记忆、更新长距离的信息,从而实现对长距离信息的处理.受LSTM模型门机制启发,Stanford在2014年提出了GRU模型,GRU网络将LSTM 结构中的输入门和遗忘门结合成一个单独的更新门,合并了记忆细胞和隐含状态,同时也做了一些调整.已有研究结果表明,GRU模型的性能与LSTM 相当,但计算效率更高,参数更少.整体的GRU神经网络结构如图1所示.

图1 GRU神经网络结构示意图[5]
GRU中各个门的表达式如下:
GRU 更新门表达式:

GRU 重置门表达式:

GRU 输出部分表达式:

式(1)中zt表示更新门,Wz是更新门的权重矩阵,ht-1表示上一个神经元的输出,xt表示本次神经元的输入,s是sigmoid 函数用来激活控制门.更新门的作用是帮助模型决定要将多少过去的信息传送到未来,或者前一时间步和当前时间步的信息有多少是需要继续传递的,模型通过复制过去信息以减少梯度消失的风险.式(2)中rt表示重置门,Wr表示重置门的权重矩阵,从本质上说,重置门主要决定有多少过去的信息需要被遗忘.
2 改进GRU模型
2.1 正则化技术
在深度神经网络中,随着层数以及各层神经元个数的增加,模型中参数的个数会以极快的速度增长.当网络参数个数过多或训练数据集很小时,神经网络模型往往会出现过拟合问题.所谓过拟合,就是模型在训练数据上拟合效果好,但是它在验证集上效果很差,即模型泛化能力差.目前,防止过拟合的一般方法是增大训练数据集,但当数据集有限时,防止过拟合的方法则是在训练数据集中加入正则化技术.现在我们主要讨论一些旨在改善过拟合的正则化方法.
正则化的方法就是在模型cost函数中加入某种正则项或几种正则项的组合,表达式如下:

式中,l(·,·)为模型中损失函数,用来评价模型的泛化性能;λρ(w)为正则项,λ为正则化可调参数,用来控制正则项与损失函数之间的平衡关系,w为模型中待估参数.在正则项中,ρ(w)具有多种不同的表达形式,常用的是L1范数和L2范数.当选取不同的范数罚正则项,整个模型会有不同的泛化方向.L2正则化会对待估参数w进行一定程度压缩使之正态分布,但并不能将其压缩为零,因此不能产生稀疏解.而L1正则化将待估参数w的先验分布约束为拉普拉斯分布,从而使模型具有稀疏性[12],进而控制模型的过拟合问题,但是由于参数值大小和模型复杂度成正比;若L1范数较大,最终可能影响模型的预测性能.为了克服不同范数正则项的缺点,这里引入弹性网正则化,也就是将L1范数和L2范数线性组合作为一个正则项.
本文将弹性网引入到GRU模型中,对网络中输入权重w实施正则化处理,以提升GRU模型的泛化性能,模型如下:

其中,λ为正则化可调参数用于平衡原有损失函数与正则项之间的关系.通过式(7)可知,修改正则可调参数λ1和λ2可得到不同组合的正则项,当λ1=0和λ2=0时,为普通的GRU模型;当λ1≠0和λ2=0时,为L1正则化网络;当λ1=0和λ2≠0时,为L2正则化网络;当λ1≠0和λ2≠0时,为弹性网正则化网络.
2.2 正则化GRU模型的洪水预测步骤
由于GRU 在训练过程中,容易出现过拟合现象,而正则化方法通过限制网络中权重的大小,可以对一些因子施加惩罚,以够弥补网络本身的不足.所以这里利用正则化方法来优化GRU模型,从而实现对外洲站水位的预测.GRU 改进模型构建步骤如下:
步骤1:将时间序列的水文数据进行预处理,采用极差法使数据标准化,首先计算指标值的最小值和最大值,然后计算极差,通过极差法将指标值映射到[0-1]之间,公式为:
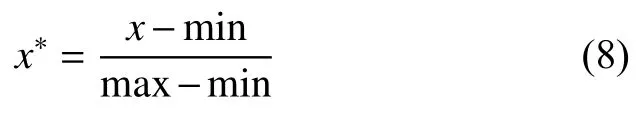
步骤2:将时间序列水文数据集F0={f1,f2,f2,f3,···,fn},划分为训练集和测试集,分别表示为Ftr={f1,f2,···,fm}和Fte={fm+1,fm+2,···,fn},满足约束条件m<n和m,n∈N.设置分割窗口长度(batch-size)取值为L,分割后的模型输入为:

其中,1 ≤p≤L;p,L∈N.
隐藏神经元的输出值定义公式为:

X 经过隐藏层后的输出可表示为:
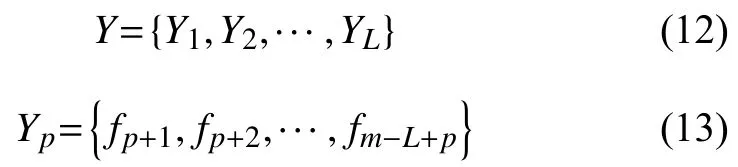
其中,1 ≤p≤L;p,L∈N.
选用均方误差作为误差计算公式,训练中的损失函数定义公式为:
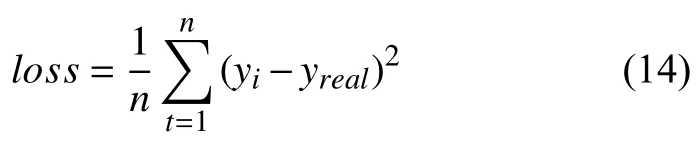
损失函数是用来评估神经网络目标输出和实际输出差距的函数,函数值越小说明实际输出与目标输出的差值越小,也就说明权值越合适.将损失函数与正则项之和设置为目标函数,给定网络初始化的学习率以及训练步数,如式(7)再应用Adam 优化算法实现目标函数的最小化并不断更新网络权重,从而得到最终的隐藏层网络.
步骤3:预测过程采用迭代的方法.理论输出P的最后一行数据:

将Pf输入隐藏层后,输出结果表示为:

则m+1时刻的预测值为ym+1,然后将Pf后的数据与ym+1合并成新的一行数据:
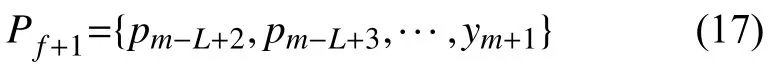
将Pf+1输入隐藏层,则m+2时刻的预测值为ym+2,以此类推,得到的预测序列为:
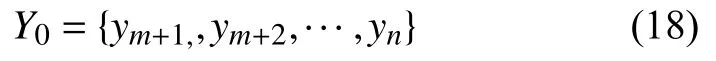
步骤4:对Y0作z-score反标准化,得到最终的与测试集Fte对应的预测序列为Yte,通过计算Yte和Fte的偏差定量的给出模型的拟合与预测精度.
3 实验与分析
3.1 实验设置
本实验环境为:硬件配置CPU i7-7700K,GPU Gtx1060,运行内16 GB;软件配置CUDA9.0、cudnn7.1;操作系统Ubuntu16.04;语言python3.6;框架tensorflow.
本实验的代码参数设置如下:输入层神经元个数设为数设为3,输出层神经元个数设为1,其中的隐藏单元的数量选取为10,每批数据量的大小batch_size设为10,通过调节λ值得到三种正则化网络模型:L1正则化网络、L2正则化网络和弹性网正则化网络.对比每组的RMSE 来确定最佳参数配置,最终确定三种模型中正则化可调参数 λ分别为λ1=0.02、λ2=0.004 和λ1=0.0043、λ2=0.38.本文针对江西省赣江外洲水文站1954年到2002年每月平均流量、平均水位、月份数据进行分析,将次月平均水位作为输出变量,其他3个指标作为模型的输入变量[13-16].以1954年到1997年各月平均水位作为训练数据,对1998年到2002年共60个月的平均水位数据进行预测.
3.2 实验性能评价指标
为了验证本文所验证的预测模型的可行性以及有效性,本文所采用的精度评定标准来自于中华人民共和国水利部《水文情报预报规范》(SL250-2000)[17],一次预报的误差小于许可误差时,为合格预报.合格预报次数与预报总次数的百分比为合格率.本文结合《水文情报预报规范》的有关规定设置水位许可误差为0.2 m.合格率QR的表达公式如下:

其中,m是预报的总次数、n是合格预报(预报误差小于许可误差)的次数;当QR ≥85.0%时,为甲级精度;7 0.0% ≤Q R ≤8 5.0%时,为乙级精度;6 0% ≤Q R≤70.0%时,为丙级精度.
采用均方根误差RMSE(Root Mean Square Error)来定量的评价模型的预测性能,RMSE通过计算预测值对观察值的平均偏差程度来反映模型的预测性能,值越小预测效果越好.公式定义如下:

3.3 实验结果分析
通过对上文中每种模型结构及参数的确定,共得到四种不同的GRU模型.为了比较这四种网络模型预测性能,将四种模型分别对外洲站水文数据做训练及预测,每组的误差统计见表1.
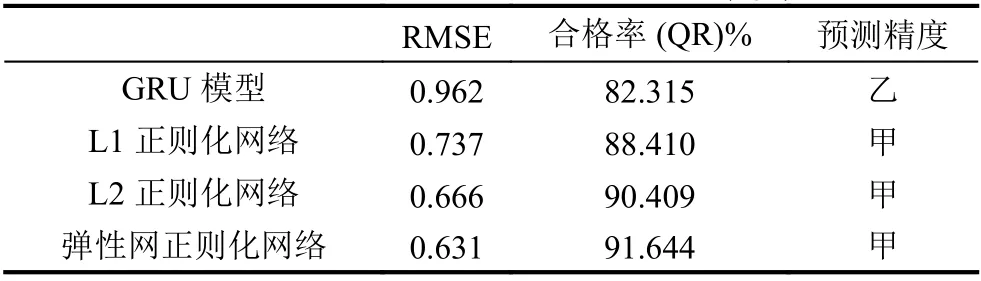
表1 几种预测模型RMSE 值和合格率(QR)统计表
由表1 可以看出3 种正则化GRU模型的RMSE的值均比普通GRU模型的RMSE值小,L2正则化网络的RMSE 比L1正则化网络稍小一些,弹性网正则化GRU模型的RMSE是实验中最低的,仅为0.631.三种正则化GRU模型的合格率均比普通GRU模型大,L2正则化网络的合格率比L1正则化网络的合格率大一些,实验中弹性网正则化GRU模型的合格率QR 最高为91.644%,相比普通的GRU模型合格率提高了9.3%.以上的验证表明改进的GRU神经网络对水文时间序列的验证是有效的,弹性网正则化GRU模型预测结果更加准确,误差更小,所以在洪水预测预测方面,弹性网正则化GRU模型预测值更接近洪水实测值,是一种有效可靠的预测方法.
这里选取各自最小RMSE的实验预测结果图,如图2-图5所示.

图2 GRU模型预测结果图(λ1=0,λ2=0)

图3 L1正则化网络预测结果图(λ1=0.02,λ2=0)

图4 L2正则化网络预测结果图(λ1=0,λ2=0.004)

图5 弹性网正则化网络预测结果图(λ1=0.0043,λ2=0.38)
4 结论
本文使用正则化GRU模型对水文站往年每月平均水位进行预测,通过比较三种正则化方法对GRU模型的改进,发现用弹性网正则方法优化GRU模型后合格率提高了9.3%,预测精度从乙等升到了甲等.由于洪水预测受到多方因素以及突发因素的影响,本文所使用的神经网络训练数据资料有限导致模型预测精度不是非常高,有待结合更多相关影响因子来进行研究处理.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
华南师范大学学报(自然科学版)(2021年5期)2021-11-09
上海师范大学学报·自然科学版(2018年3期)2018-05-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
天津诗人(2017年2期)2017-11-29
神州·上旬刊(2017年9期)2017-10-15
太空探索(2016年7期)2016-07-10
华人时刊(2016年16期)2016-04-05
少儿科学周刊·儿童版(2015年7期)2015-11-24
少儿科学周刊·儿童版(2015年7期)2015-11-24
