
基于面部表情的学习者情绪自动识别研究*
——适切性、现状、现存问题和提升路径
2019-07-19 08:48陈子健朱晓亮
远程教育杂志 2019年4期
陈子健 朱晓亮
(1.华中师范大学 国家数字化学习工程技术研究中心,湖北武汉 430079;2.贵州财经大学 信息学院,贵州贵阳 550025)
学习者情绪不仅作用于认知加工过程中的注意、记忆、决策等各个环节,而且影响学习者的学习动机和兴趣[1]。准确感知学习者的情绪状态,对实施个性化教育,提升学习绩效都尤为重要。在传统的课堂教学环境中,教学经验丰富的教师善于通过情绪外部表现(如,面部表情、姿态表情和语调表情),来判断学生的情绪状态,以辅助自己的教学决策。但是在互联网、人工智能、大数据等技术裹挟下的科技革命正在冲击着传统教育的生态[2],当前的教学环境已不再局限于学校的课堂教学,虚拟的数字化学习环境,正在成为当前教育生态的重要组成部分。
赋予数字化学习环境中的计算机识别、理解和表达情绪的能力,成为情感计算、人工智能、人机交互等多个研究领域共同追逐的目标。虽然这是一项挑战性的工作,但是在计算机视觉、人工智能、情感计算等新兴技术的支撑下,这一目标正在日益变成现实。计算机可以通过识别学习者外显的面部表情,来判断学习者内隐的情绪状态,从而获得识别、理解学习者情绪的能力,在此基础上,可以进一步实现计算机与学习者的情绪交互。
一、学习者情绪识别适用的情绪表征方法
与情绪(Emotion)相关的术语,主要有情感(Affect)、感受或感情(Feeling)。严格来讲,情感是情绪、感受或感情这类现象的笼统称谓。情绪特指情感性反应的过程,侧重指向非常短暂但强烈的体验。感受或感情指的是情绪的主观体验,是情感性反应的内容。确定情绪的表征方法是学习者情绪识别的前提。
目前,情绪心理学研究领域采用的情绪表征方法,大致可分为两类:分类表征方法和维度表征方法。分类表征方法将情绪分为几种彼此独立、有限的基本情绪;复合情绪由基本情绪变化混合而成。基本情绪也是在日常生活中发生频率最高的情绪类别。美国心理学家Paul Ekman 通过研究发现:六种基本情绪(高兴、生气、惊讶、恐惧、厌恶和悲伤)的面部表情、生理和行为反应具有跨文化一致性[3]。因此,这六种基本情绪也就成为情绪识别领域广泛研究的对象。维度表征方法则将情绪视为高度相关的连续体,并用某个维度空间中的点来表征情绪。在情绪识别领域,采用维度表征方法的研究者,大多数采用效价性和唤醒度两个维度表征情绪。效价性用于表示情绪是正向还是负向,变化范围从“不高兴”到“高兴”;唤醒度则用于表示兴奋或冷淡的程度,其变化范围从“瞌睡”或“厌倦”到“特别兴奋”。
分类表征方法和维度表征方法各有优缺点(如表1所示),适用于不同的领域。分类表征方法简洁、易懂,更符合人们的日常体验,也有利于对特定情绪类别进行检测和识别,但也存在难以处理复合情绪的问题。维度表征方法可以在几个连续的刻度上,对情绪进行标定,有利于机器情感模拟。但机器情感模拟,也需要解决情绪和维度空间坐标之间的相互转换问题。另外,心理学的研究表明,维度之间存在相互关联,特别是在描述每个维度的值中存在着重复和内部关联性上[4-5]。学习者情绪识别更适合采用分类的情绪表征方法,因为其主要目标是识别出频率较高、影响学习绩效的情绪类别,从而为教学决策提供依据。

表1 两种情绪表征方法的对比
二、基于面部表情的学习者情绪识别的适切性
一个完整的情绪体验过程,由认知层面上的主观体验、生理层面上的生理唤醒、表达层面上的外显行为这三种层面的活动共同构成[6]。相应地,情绪识别的研究者主要通过主观体验测量、生理测量、外显行为分析三种方式开展相关研究。主观体验测量是用标准化的量表来测量被试者的情绪体验,难以保证结果的客观性,这种事后测量的方式也无法实现实时性的情绪测量。通过生理测量识别情绪是借助心电仪、肌电仪、皮肤电反应仪、脑电仪等专用设备,监测被试的生理信号,利用不同情绪在生理信号方面的差异实现情绪识别。但是,生理测量并不适用于学习者的情绪识别,因为监测学习者生理信号通常需要通过传感器与学习者皮肤进行物理连接,这样会对学习者造成干扰,并且需要较为昂贵的专业设备。这种方式多用于实验室情境,难以推广应用。目前,一些穿戴式智能设备也可以监测部分生理信号,例如,智能手环和智能手表可以采用光电测量心率,但其准确性容易受汗水、肤色、光照和晃动等因素影响。这两款产品的设计初衷也仅针对户外健身和医疗保健,难以监测学习者情绪识别所需的其它生理信号。
情绪的外显行为包括语音表情、姿势表情和面部表情。基于语音表情的情绪识别是从语音参数中提取声学特征用于情绪识别,但是相关研究显示,部分情绪的语音表情的声学特征并不存在显著差异性。例如,难以通过语音表情分辨害怕和惊喜、厌倦和悲伤[7]。用于表达情绪的身体姿态称为姿态表情,例如,紧握的拳头、耷拉的脑袋。基于姿态表情的情绪识别面临的问题是,学术界对于姿态表情是否与特定的情绪存在一一对应关系尚存在争议。情绪研究的先驱Darwin 认为,有些身体运动与姿态会对应特定的情绪[8];而情绪研究的代表人物Paul Ekman则认为,姿态表情仅能提供情绪强度信息,特定的姿态表情和情绪间不存在一一对应关系[9]。例如,紧握的拳头可以用于表达愤怒,也可用于表达兴奋、激动。
面部表情是表达情绪的最主要、最自然和最直接的通道[10]。心理学家Mehrabian 通过研究发现:情绪表达=7%的言词+38%的语音表情+55%的面部表情[11]。因此,面部表情也是用于情绪识别的一种主要数据类型。Scherer 等分别对基于语音表情和基于面部表情的基本情绪识别方法的正确率做了统计对比分析,如表2所示。基于面部表情的情绪识别方法的平均正确率,比基于语音表情的情绪识别方法的平均正确率高大约15%。作为一种在特定情境中的情绪识别,基于面部表情的学习者情绪识别,有其自身的优势:(1)面部表情是表达情绪的最主要通道,能客观反映学习者真实的情绪状态;(2)基于面部表情的情绪识别可以实现无接触式的数据采集,可最大限度地减少对学习者的干扰;(3)面部表情数据采集可以通过低成本的摄像头实现,也便于整合到各类智慧学习系统中,有助于技术的推广应用。
部分研究者融合面部表情和其它多种类型数据识别学习者情绪,以期提高识别准确率,但是这种基于多种类型数据的学习者情绪识别方法,能够普及应有的前提是降低对学习者的干扰和技术的应用门槛,否则只能局限于实验室情境。

表2 通过面部表情和语音信号识别基本情绪的正确率对比[12]
三、情绪面部表情识别的研究现状
基于面部表情的学习者情绪识别,是通过对学习过程中的面部表情的检测和识别,来获取学习者的情绪状态信息的。面部表情识别包括人脸检测、表情特征提取、表情分类三个核心环节,其中人脸检测算法和分类算法已经相对成熟,当前研究的重点主要在于如何有效地提取面部表情特征。在学习者情绪面部表情识别的相关研究中,部分研究是借助工具软件提取面部特征,如:Microsoft Kinect Face Tracker[13]、CERT(Computer Expression Recognition Toolbox)[14]、FaceTracker(源自NevenVision 公司的面部特征跟踪SDK)[15]等。但是这类工具软件并不是专门针对面部表情识别开发的,或者在性能上还达不到要求。到目前为止,我们还没有发现功能完善的适用于学习者面部表情识别的工具软件。
虽然,国内外研究者在面部表情特征提取方面做了大量探索性工作,但是,面部表情特征提取受到诸多因素的影响,如个体差异、环境、姿态等。目前,面部表情的特征提取算法还处在不断的探索和研究阶段。因此,本文重点对面部表情识别领域的特征提取算法进行了梳理和分类,来分析不同类别算法的特点及局限性,以期为探索适合学习者面部表情特征提取算法提供借鉴,从而推动学习者面部表情识别的发展和应用。
(一)传统的计算机视觉方法
1.基于静态图像的表情识别
基于静态图像表情识别的特征提取算法,大致可分为两类:几何特征提取和外观特征提取。几何特征是指通过测量距离、形变、曲率和其它几何属性来表征面部表情,代表性的方法包括:主动形状模型(Active Shape Models,ASM)和主动外观模型(ActiveAppearance Models,AAM)。ASM 通过对训练样本的面部特征点组成的形状向量进行统计建模,同时,利用特征点所在轮廓线方向上的灰度信息,建立起反映灰度分布规律的局部灰度模型。在搜索面部表情特征点位置的过程中,局部灰度模型作为目标函数,用于确定特征点的移动方向和位置,通过迭代方式,确定特征点最优位置,最终得到由特征点组成面部表情几何形状(如图1所示)。

图1 面部表情的几何特征表征示意图
AAM 是对ASM 的改进,其建立了全局灰度模型用于特征点搜索,以提升精确度。另外,尺度不变特征转换(Scale-Invariant Feature Transform,SIFT)作为一种局部特征描述算子,也可以在面部图像中检测出特征点,通过求解特征点及其有关角度和方向,来提取面部表情几何特征。Wang、江河等采用ASM 提取面部几何特征,并利用支持向量机作为分类器,来检测学习者是否产生困惑[16-17]。韩丽等利用AAM 检测面部特征点,然后依据特征点,自定义表情特征,识别倾听、疑惑、理解、抗拒和不屑五种面部表情,用于教学效果的评价[18]。
总的来看,基于静态图像几何特征的面部表情识别,只利用了面部器官的几何形变信息,忽视了面部的纹理、皱褶等蕴含的信息,所以,对于面部肌肉运动幅度小的自然面部表情,识别准确度较低。
外观特征提取是指基于图像像素的特征提取,采用领域专家设计的图像特征描述算子,从像素所蕴含的信息中提取面部表情特征,反映的是面部表情底层的信息。常见的特征描述算子有:Gabor 小波、局部二值模式(Local Binary Patterns,LBP)、方向梯度直方图(Histogram of Gradient,HOG)等。Gabor 小波变换是利用一组滤波器对表情图像进行滤波,检测多尺度、多方向的面部局部纹理特征,而且对于表情图像的光照变化不敏感。LBP 以中心像素的灰度值作为阈值,通过阈值标记中心点像素与其邻域像素之间差别的方式,来提取图像纹理特征,具有旋转不变性和灰度不变性等优点。HOG 首先对图像进行分割,然后计算和统计图像局部区域(Cell 和Block)的方向梯度直方图,来提取面部表情特征。
较为经典的案例有:Whitehall 等利用Gabor 小波变换提取面部外观特征,检测学习者专注度[19]。Happy 等提取学习者面部表情的LBP 特征,检测学习者的警觉程度和情绪状态[20]。童莹从对传统的HOG特征出发,提出了空间多尺度HOG 特征[21],但忽略了特征之间空间排列信息的缺点。从这些研究中可以看到,外观特征是从底层像素中提取特征,适用于低强度的自然面部表情和微表情的检测与识别。但是外观特征提取方法本身也存在局限性,比如,Gabor 小波变换需要计算大量的小波核函数,产生的高维特征向量不利于算法实时性,也易造成了信息冗余。LBP 特征提取也存在计算量大的问题,同时受邻域灰度值变化影响较大,对噪声敏感。
总体来说,外观特征提取在面部表情识别领域仍具有重要应用,主要针对现有的外观特征提取算法进行改进,或是与其它类型的特征提取算法进行融合。
2.基于动态图像序列的表情识别
面部表情的产生是一个动态过程,基于动态图像序列的表情识别提取动态特征识别面部表情,大致可分为光流特征、几何动态特征和外观动态特征三类。面部表情光流特征是利用序列图像间像素强度的时域变化和相关性,来确定像素点的“运动”,用于表征脸部形变和变化趋势。Anderson 等在人脸跟踪的基础上提取面部光流特征,识别视频中的六种基本情绪面部表情[22];Liu 等则提出了主方向平均光流特征这个概念,具体来说,在微表情视频序列中抽取主方向,对面部区域进行分割,并计算分块中的平均光流特征,再对微表情进行识别[23]。但是,光照不均和脸部非刚性运动等因素,都将影响面部表情光流特征的提取,建立可靠、快速、鲁棒的光流算法,仍然面临很大的挑战。
几何动态特征以面部特征点定位为基础,具体来说,需构建面部表情的几何形状特征描述,跟踪几何形状的时域变化,实现面部表情识别。Tie 等通过多个粒子过滤器跟踪视频中的26 个面部特征点,构建了人脸网状模型,提取形变特征识别面部表情[24]。Cheon 等提出差分AAM,并结合流型学习(Manifold Learning)跟踪面部几何形状的变化,用于识别面部表情[25]。Pantic 等利用粒子滤波器跟踪视频中15 个面部特征点,并结合时序规则检测面部动作编码系统(FACS)中的27 个面 部动作单元(Facial ActionUnits,AU),依据FACS 中定义的特定表情和AU的映射关系识别表情[26]。Niese 等则融合光流特征和几何特征,识别六种基本情绪面部表情[27]。虽然,几何特征对静态图像表情的识别准确率较低,但几何动态特征具有可以跟踪面部形变过程的特点,计算量小,对光照变化不敏感,常用于图像序列的表情识别。
为了表征脸部皱纹、沟纹、皮肤纹理的细微动态变化,一些研究者尝试将二维静态图像外观特征描述算子扩展到三维空间,用于提取面部表情的外观动态特征。例如,采用LBP-TOP(Local Binary Pattern Histograms from Three Orthogonal Planes)特征描述算子,提取面部表情的动态外观特征。动态图像序列除了二维静态图像的X,Y 两个维度,还有一个时间维度T。LBP-TOP 特征描述算子在X-Y 平面上计算LBP 值,用于表征表情图像帧的纹理特征;在XT 和Y-T 计算LBP 值,用于表征纹理的动态变化。例如,Zhao 等、Wang 等分别采用LBP-TOP 特征识别基本情绪面部表情和微表情[28-29]。相关研究中类似的动态外观特征描述算子还有3D-HOG[30-31]、LPQTOP[32-33]、3D-SIFT[34]等。但是这类外观动态特征描述算子在学界还存在争议,相关研究显示,这种人工设计的特征描述算子,很难提取到面部表情图像帧之间的时域特征[35-36]。
(二)深度学习的方法
深度学习(Deep Learning,DL)作为人工智能领域重要的机器学习算法,已经在语音识别、图像识别、自然语言处理等诸多领域,取得了突破性进展,受到了学术界和工业界的高度关注。传统的机器学习依赖于人工特征提取,特征的选择对机器学习算法的性能存在巨大的影响。可以说,深度学习赋予计算机表征学习(Representation Learning)的能力,即计算机可以自我构建对事物的描述,形成概念,从而实现特征的自动提取(特征学习)[37]。利用深度学习提取面部表情特征的方式与人的视觉系统的信息处理方式相一致,即,首先提取低层的特征,然后逐层地将低层特征组合成高层特征。
1.基于静态图像的表情识别
用于静态图像面部表情识别的深度学习代表性算法是卷积神经网络(Convolutional Neural Networks,CNN)。一个基本的CNN 由卷积层、池化层和全连接层组成。卷积层通过内部包含的多个卷积核(滤波器),在输入图像上进行特征提取;池化层则被用于降低数据维度。CNN 的首层卷积层提取图像低阶特征,比如,边、角、曲线等,后续卷积层在前一层卷积层提取到的特征基础上,进一步提取特征。通过卷积层与池化层的堆叠,实现高阶特征提取,最后通过全连接层连接分类器。CNN 的架构设计是图像识别任务中的核心环节,其中AlexNet 和VGGNet 是两种在往年的ImageNet 大规模视觉识别挑战赛中获得冠军的CNN 架构,如图2所示。这两种网络架构在图像识别领域仍具有广泛的应用前景,在静态图像面部表情识别领域尤为突出。利用CNN 识别面部表情的流程,如图3所示。

图2 两个广泛应用的CNN 模型的网络结构

图3 CNN 识别面部表情流程图(图中表情实例来自数据集CAS(ME)2)
研究者提出了各种不同的基于CNN 的面部表情识别方法。例如,Hamester 等设计双通道的CNN识别面部表情,其中一个CNN 子网的第一层采用预置权重的Gabor 滤波作为卷积自编码器,两个CNN 子网提取的特征在融合后被用于识别面部表情[38]。Liu 等提出由多个CNN 子网组成的集成式CNN,用于面部表情特征自动提取和分类[39]。Liu Y 等则融合人工设计的特征(CBP,中心二值模式)和CNN 自动提取的特征识别面部表情[40]。曹晓明等则融合静态图像的面部表情、脑电波和学习日志三种模态数据,训练CNN 模型判断学习者参与度[41]。但是,已有研究在所设计的CNN 中所有卷积核的权值系数是随机初始化的,需要在标注的样本数据集上训练CNN 模型,调节卷积核的权值系数,才能有效地提取面部表情特征,因此,需要大量的训练数据用于模型的训练。
2.基于动态图像序列的表情识别
利用深度学习方法识别动态图像序列的面部表情,不仅需要提取单帧图像的空域特征,而且还需要提取图像帧之间的时域特征。单帧图像的空域特征提取可以通过CNN 实现,而提取序列时域特征的代表性算法则是循环神经网络(Recurrent Neural Network,RNN)。RNN 的基本结构也是由输入层、隐藏层和输出层构成,不过隐藏层中每个神经元的输入,除了当前时刻的信息输入外,还有着前一时刻该神经元的输出,所图4所示。RNN 的这种架构,使其具有类似人的记忆功能,对处理时间序列数据具有独特的优势。建构CNN-RNN网络,同时提取面部表情的空域和时域特征,可以提升识别的准确性。Ebrahimi 等利用CNN 提取面部表情序列帧的空域特征,然后将所有帧的空域特征送入RNN,提取表情序列的时域特征,结合空时域特征识别面部表情[42]。Zhang 等从表情图像序列中选择代表帧图像,利用CNN提取代表帧的空域特征,同时利用RNN 提取所有表情序列帧的面部特征点的时域特征,最后融合两种特征识别面部表情[43]。
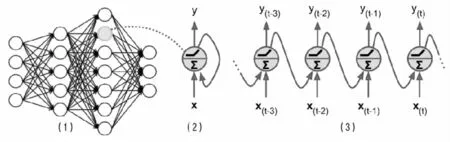
图4 循环神经网络示意图
RNN 模型的训练采用BPTT(Back-Propagation Through Time)算法反向传播误差,通过随机梯度下降(Stochastic Gradient Descent)算法调节网络参数,使得损失函数值达到最小。但是随着序列长度增大,RNN 在训练过程中会出现梯度消失问题,从而丧失学习序列时域特征的能力。为了解决这一问题,长短时 记 忆 网 络(Long Short Term Memory Networks,LSTM)对RNN 的神经元进行进一步改造,增加记忆单元(Memory Cell)存储每个时间点的神经元状态值,并通过“遗忘门”、“输出门”、“输入门”,对记忆单元中的信息,进行移除或添加操作。LSTM 的记忆单元,使得网络训练时的误差以常数形式在网络中传递,防止梯度消失,从而实现对长序列数据的特征学习。实际的案例有卿粼波等将CNN 学习到的面部表情空域特征输入LSTM 网络,学习面部表情时域特征,识别群体情绪面部表情[44]。Kim 等则利用CNNLSTM 学习到的空时域特征,识别微表情[45]。
四、存在的问题与提升路径
(一)学习者情绪面部表情识别研究现存问题
因为基本情绪是日常生活中发生频率最高的情绪类别,所以,目前情绪面部表情识别研究领域,主要关注于基本情绪面部表情的识别研究,商业与娱乐是其主要的目标应用领域。基本情绪只是人类情绪类别中的冰山一角,并不是学习情境中发生频率高的情绪类别。但是,由于受基本情绪理论的影响,部分学习者情绪面部表情识别的相关研究,多为针对基本情绪面部表情的识别[46-48]。而实际上,研究者通过统计分析发现,在学习情境中出现频率较高的情绪类别并不是基本情绪,而是疑惑、厌倦和挫败等情绪类别[49-50]。因此,学习者情绪面部表情识别,应重点研究这几类发生频率较高的情绪识别,以及提高识别的准确率,为优化学习支撑服务提供依据。
现有相关研究中的面部表情,可分为两种类型:扮演的面部表情和自然的面部表情。因为面部表情识别研究需要大量的面部表情样本数据,而较大规模地采集学习者情绪自然面部表情的难度较大。所以,部分研究者招募学生,以学习者情绪面部表情原型为基础,在实验室情境中扮演相应的面部表情,形成供研究使用的表情数据集。例如,Kaliouby 等的研究就是识别六类扮演的学习者情绪面部表情[51]。Lin等在研究学习者情绪面部表情识别时,在扮演的面部表情数据集上验证模型效果[52]。首先,学习者扮演的面部表情通常肌肉运动幅度大,特征较明显,持续时间可控;而学习者情绪自然面部表情则呈现肌肉运动幅度小、特征不明显、持续时间短的特点。其次,扮演的面部表情和自然的面部表情在时间和空间模式上也存在差别[53]。在早期的探索性研究阶段,为了推进相关研究的开展,研究识别扮演的学习者情绪面部表情无可厚非,但从推动研究应用的角度,后续应该着重研究自然的学习者情绪面部表情识别。
针对学习者情绪面部表情的识别问题,不同研究者提出不同的识别算法,构建面部表情识别模型,并通过实验对模型的性能进行评估。大多数的相关研究,主要采用识别准确率评估模型的性能,但是,当测试数据集中于不同类别的表情样本并呈现分布不均匀时,仅仅使用准确率并不能全面客观地评估模型的性能。例如,由90%的正样本和10%的负样本组成的测试数据集,即使模型将所有的样本都识别为正样本,识别的准确率也只达到90%。因此,在评估学习者情绪面部表情识别模型时,应该采用多种评价指标,全面评估模型的性能,比如,混淆矩阵、ROC 曲线等。另外,现有相关研究采用研究者自己创建的面部表情数据集,测试评估模型的性能,同时,创建的数据集并未公开发布。这样使得不同研究的识别方法无法在同一数据集上比较并识别性能,研究结果的可重复性受到限制,这不利于学习者情绪面部表情识别研究的发展。
(二)学习者情绪面部表情识别研究的提升路径
1.面部表情数据库的共建共享
创建大规模的自然学习者情绪面部表情数据库,是推动学习者情绪面部表情识别研究和应用的关键环节。首先,数据库的创建应有助于不同识别算法采用相同的数据集测试和评估模型的性能,能比较不同方法的优劣,从而促进学习者情绪面部表情识别的发展。其次,基于深度学习方法的面部表情识别,已经表现出优秀的性能,但其本质上是一种数据驱动的识别方法,在构建的深度神经网络中,存在许多训练参数,需要通过大量的表情样本数据,来调节网络参数(又称模型训练)。大规模的自然学习者情绪面部表情数据库的创建,是一项耗时耗力的工程,数据的采集和预处理、数据标注等都需要花费大量的人力和物力。共建共享的创建方式,可以更快地推进数据库的创建,扩充数据库的容量,更好地为相关研究提供大数据的支持。
2.融合多种特征的识别方法
真实学习情境中的自然学习者情绪面部表情,通常面部肌肉运动幅度小,特征表现不明显,具有部分微表情的特性。单一类型特征表征的识别方法,准确率较低,难以满足实用性要求。面部表情产生时会伴随着眉毛、眼睛、鼻子、嘴巴等单个或多个面部器官的形变(即几何特征),同时也伴随有脸部皱纹、沟纹、纹理等的变化(即外观特征)。可见,面部表情的产生是一个动态的过程,其经历开始、峰值和结束三个阶段。因此,面部表情不仅带有空间域特征,还具有时间域特征。针对自然学习者情绪面部表情特征所表现出的复杂而不明的特点,我们需要提取多种类型的面部表情特征进行表征,全面地获取面部表情的特征信息,才能有效地提升面部表情识别的准确性,推动学习者情绪面部表情识别技术的实用化。
3.结合人工设计特征和自动学习特征的识别方法
特征提取是学习者情绪面部表情识别的核心步骤,包括人工设计特征和自动学习特征两种类型方法。人工设计特征是指通过设计特征描述算子,显式地提取表情特征;自动学习特征则是利用深度学习的方法,从面部表情样本中逐层学习表情特征,最终得到抽象的表情特征。两种方法都有其优点和局限性,人工设计特征利用特征描述算子,直接从表情实例中计算并提取特征,提取的特征可解释性强;但是,提取的特征的好坏,依赖于专业知识、经验和运气,全面提取表情特征信息的难度较大。自动学习特征能从大量表情训练样本中,挖掘出用于表情识别的有效的、抽象的、深层次的特征;但是,这种方法需要足够多的训练样本数据,才能实现有效的特征提取。因此,结合人工设计特征和自动学习特征两种特征的提取方法,取长补短,融合两种方法的优势,是促进学习者情绪面部表情识别发展的可选途径。
五、思考与展望
以计算机视觉、人工智能、情感计算等新兴技术为支撑,计算机可以通过识别学习者外显的面部表情的方式,来判断学习者内隐的情绪状态,从而获取识别、理解学习者情绪的能力。本研究在对情绪心理学研究领域的两类情绪表征方法,进行对比分析的基础上,确定学习者情绪识别适用的表征方法,并对基于面部表情的学习者情绪识别的适切性进行阐述。
当前,学习者面部表情识别研究的核心问题,是如何有效提取面部表情的特征。因此,本研究将面部表情的特征提取方法,分为传统的计算机视觉方法和深度学习方法两大类,梳理不同特征提取方法的特点及局限性,可以为探索适合学习者面部表情识别的特征与提取算法提供借鉴,从而推动学习者面部表情识别研究的发展和应用。针对学习者情绪面部表情识别相关研究中存在的问题,后续研究应该更为关注在学习情境中发生频率较高的情绪面部表情识别,而非对基本情绪面部表情的识别;应该关注真实情境中自然面部表情识别,而非实验室情境中扮演的面部表情识别;应该结合基于专家知识的人工设计特征方法和数据驱动的自动学习特征方法,全面有效地提取学习者面部表情的本质特征,从而提升识别的准确性。
赋予计算机识别学习者情绪面部表情的能力,是一项充满挑战性的任务,但也具有广阔的应用前景。尽管当前的研究还处于探索阶段,一些研发的技术应用也还不够完善,但是随着研究的继续深入和相关技术的成熟,势必将对教育产生深远影响。对于课堂教学环境,面部表情识别可以用于监测学习者情绪状态,帮助教师进行教学决策,辅助教学效果的评价。而对于在线学习环境和各种智能教学系统,面部表情识别也有着广泛的应用前景:(1)能够完善学习者模型的构建,使之不仅包括学习者基本信息和认知层面的属性特征,还能涵盖学习者情绪状态属性,为实施智能化、个性化的教学提供依据;(2)能够通过面部表情监测学习者情绪状态,并以此为依据实现机器情感模拟,解决学习过程中的情感缺失问题;(3)能够丰富学习行为分析的途径,可以与学习平台的日志数据相结合,共同分析学习者行为。
学习者情绪作为一项重要的教学反馈信息,得到国内外研究者的普遍重视。在学习过程中,通过面部表情识别,实时地获取“知识点—情绪”形式的反馈信息,判断学习者对当前学习内容是否感兴趣、是否理解,有助于智慧教学系统的构建。基于面部表情的学习者情绪识别研究的应用,依赖于准确、实时、鲁棒的面部表情识别算法设计。未来研究的趋势,首先,将继续探究从人脸图像中有效地提取表情本质特征的方法,缩小面部表情的类内特征差异和扩大类间特征差异,以提高识别的准确性。其次,继续探究鲁棒的(Robust)面部表情特征提取算法的设计,降低环境及个体差异、面部遮挡等因素对面部表情特征提取的干扰。再次,未来将继续探究实时性的面部表情识别与算法设计,提升学习者面部表情检测和识别速度,满足实时性需求。最后,融合多种模态的数据识别学习者情绪,也是重要的研究方向之一。例如,融合头部姿态估计、视线跟踪、面部表情、生理信号,来识别学习者情绪。但基于融合多模态数据的学习者情绪识别研究的应用,需要依赖于数据采集与监测技术的发展,需要降低数据采集、监测技术的应用门槛,并减少对学习者的干扰。
猜你喜欢
学生天地(2020年15期)2020-08-25
意林·少年版(2020年2期)2020-02-18
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
湘潮(上半月)(2019年3期)2019-05-22
电子制作(2018年19期)2018-11-14
风流一代·青春(2018年2期)2018-02-26
风流一代·青春(2017年6期)2018-02-14
风流一代·青春(2017年5期)2018-02-14
