
大数据流式计算框架的任务调度优化方法研究
2019-07-17 06:40梁秋红郝雅萍
中州大学学报 2019年3期
梁秋红,郝雅萍
(1.运城广播电视大学 成教部,山西 运城 044000;2.朔州师范高等专科学校 教务处,山西 朔州 036000)
随着计算机科学技术的快速发展,物联网、社交网络等在各个领域都得到广泛的应用,每天都会产生海量数据,人们已经逐步进入了大数据时代。大数据时代如何高效处理海量数据已经成为当前工业界以及学术界重点研究的方向。大数据的计算模式包含批量计算、流式计算、交互计算、图计算等,以批量计算、流式计算为主[1-2]。批量计算一般处理存储在数据库中的海量数据,适合应用在实时性较低的环境下,常见的有Hadoop生态系统;流式计算以数据流的方式计算进入到内存中的工作节点,只要数据源保持活动状态,就会持续不断地生成数据且无需进行存储,适用于实时性要求较高且处理窗口局部数据的应用领域中。流式大数据平台可以显著提升在线数据密集型应用的用户体验,广泛应用在各类实时性非常严格的行业领域中,例金融银行、股市分析等[3]。
1 Storm模型框架
一个完整的Storm分布式系统由4类节点组成,分别为:
(1)主控节点。用户会将拓扑作业提交给主控节点,直接将任务分配给工作节点,提供状态获取接口。
(2)工作节点。它是Supervisors运行的后台节点,完成Nimbus分配任务的监听动作,属于分布式部署。
(3)控制节点。它是一个Web服务器,将计算结果反馈给用户,并提供给制定端口网页服务。
(4)协调节点。负责所有节点的协调配置管理,也是维持Storm系统稳定、实用性的关键因素。
2 任务调度优化
2.1 Storm基本模型
2.1.1 Storm拓扑逻辑模型
拓扑结构一般都是应用二元组(C,S)来描述,其中C={c1,c2,…,c|c|}表示拓扑顶点集合,每个顶点表示1个组件,符号定义为Spout或Bolt;S={s1,2,s1,3,…,s|C|-i,|C|}表示拓扑中有向边集合,每个组件表示相邻组件间的数据流传递。当si,j∈S→ci,cj∈C,i≠j,即表示ci组件发送了数据,并由cj接收。因此就可以定义拓扑逻辑模型为具备上述特征的有向无环图[4-6]。
图1为一个拓扑逻辑模型,图中组件集为{ca,cb,…,cg},数据流集为{sa,c,sa,d,…,se,g}。数据初始顶点Spout为ca,cb,主要功能为数据的输入以及发送到流式计算群待处理;其余的节点表示为Bolt,主要功能为接收上一组件数据并将计算结果发送给下一组件;数据流的终端节点cf,cg直接将结果展示给用户或保存到数据库中。

图1 Storm拓扑逻辑模型
假设任意组件ci,cj,ck,cj是ci,ck的中间组件,组件ci发送的数据可以经过cj组件到达ck组件,则表示组件cj的关联组件为ci,ck。例如图1中cd组件的关联组件为ca,cb,cg;cc组件的关联组件为ca,cf。
2.1.2 流任务
在拓扑逻辑模型中,每个组件都可以并行处理多个任务,且每个任务由一个工作线程处理。而对于其中任意的组件ci∈C,存在任务Ei={et1,ei2,…,ei|Ti|},当中eij表示ci运行的第j个任务,尤其是任务数量为1的组件ci,则可以直接定义Ei={ei1}=ei。其中任务关联则表示存在上一任务流和下一任务流之间存在较大的数据流关联。图2为图1中的任务拓扑实例模型,其中组件ca有3个任务:ed1,ed2,ed3,任务关联以ed1为例,它的关联任务分别为ea,eb,ef1,ef2。子拓扑中各个组件必须存在数据流,即子拓扑中任务是可以数据流动。

图2 拓扑流结构
2.2 任务调度策略
在Storm集群中,资源都是由工作节点Supervisor构成的,slot表示任务工作节点内存资源,每个slot表示一个内存资源,且每个slot都只能被一个线程(Work)占用。在每个slot中每个Work则会包含多个Executor执行器,当中每个Executor执行器有很多个Task任务。Storm默认的调度器为EventScheduler,它是通过轮询策略来搜索集群中所有拓扑结构的工作节点,并将资源较为均匀地分配给任务进程[7]。
上述任务调度策略较为简单,任务分配较为均匀,已经应用到较多的场景中,但该上述资源分配调度只是平均分配集群资源,并没有充分考虑到具体任务对于磁盘、内存、CPU等需求都不一样,甚至子拓扑结构的关联任务需求资源都不一样,这就会给流式数据任务调度性能造成非常大的影响。例如当某些业务对于CPU的需求较高时,若采用上述任务调度策略就会致使子拓扑中任务都运行在同一个工作节点中,很容易发生集群工作节点负载不均衡的现象。
2.3 任务调度策略优化
为了更好地解决上述任务分配不均匀以及负载不均衡的问题,提出直接分配固定节点的分配调度策略,该任务分配调度策略将子拓扑中的计算组件强制运行在一个固定机器上,且分配计算任务较为简单的子拓扑,这就可以促进组件的维护管理;基于负载均衡策略,将子拓扑中多个线程都均衡分配给集群的各个工作节点,确保组件可以获取得到相似的线程数量,降低同性资源竞争,将一些对CPU需求较大的相似组件分配到不同任务处理,以此来获取得到更加均衡的资源调度[8]。
2.3.1 直接分配固定节点的任务分配调度策略
基于固定节点的直接分配调度策略,将子拓扑的组件线程都分配到一个固定的物理节点上,避免元组在不同节点间进行传输,提高任务调度的运维管理能力。子拓扑中组件固定分配给某一个物理节点,当数据临近该物理节点,就可以直接就近分配给该节点,以此来降低带宽开销;计算得到的数据结果Bolt直接分配给该节点,提升数据存储速度。具体任务调度优化步骤如下:
(1)目标定位。判断需求子拓扑是否已经上传到集群资源上,并从Storm拓扑模型中找到需求子拓扑进行下一步任务分配。
(2)确定目标是否需要分配。根据定位到的目标子拓扑,判断其是否已经被任务调用分配过:已经被调用过,则进入下一步;否则分配调度资源。
(3)定位目标线程。要对需求子拓扑中线程进行分配调度,已经被分配过线程不能被调度。
(4)目标组件分配确认。根据得到的需求子拓扑所有组件的线程,并确认目标组件是否要被分配资源。
(5)工作节点定位。在确认目标组件需要分配资源后,找到分配的相关执行器,接下来定位子拓扑进程节点。
(6)得到目标资源。根据上述定位到的目标进程得到相关资源slot,并判断slot资源是否可以满足子拓扑需求,当无法满足时要将已经被占用的slot释放,供需求子拓扑调用。
(7)分配调度。循环上述过程,并将所有非目标子拓扑的任务调度都分配给Storm的调度管理器EventSchedule实现。
2.3.2 基于负载均衡的任务调度策略
负载均衡的任务调度策略应用贪心算法思想,在每次对任务进行调度时尽可能分配slot数量最多的节点。定义符号Li(i=1,2,…,t)表示第i个子拓扑需求进程数量,Ki(i=1,2,…,t)表示第i个子拓扑需求线程数量。任务调度策略步骤如表1。

表1 基于负载均衡的任务调度策略
3 实验和评价
3.1 实验环境
实验所用的Storm环境搭建在Linux虚拟机中,Linux虚拟机数量为6;Storm集群由1个Nimbus节点、5个Supervisor节点构成;内存为8G;CPU为4核;每台服务器硬盘大小为80G。
3.2 数据时间性能测试
将本文任务调度算法应用在实时性要求较高的交通领域中,并从中获取得到上百亿海量的车牌识别数据,并将其输入到集群系统中。将集群计算组件Bolt并行度设置为5,以此来测试集群计算时间,即一条实时数据从传输到计算识别完成所需的时间。从图3可以看出,数据处理时间基本为0.6 ms,波动范围很小,表明本系统可以实时计算处理高并发数据流,具备非常好的时间效率。

图3 不同数据并发量下的计算时间
3.3 直接分配固定节点的任务分配调度策略评价
将某一个子拓扑作业“List”中的所有进程分配到工作节点“storm-node”上,且该作业任务提交给Nimbus节点上,将并行度设置为5。表2表示各个工作节点的使用情况:在storm-node工作节点上只有一个进程,即list;其他工作都没有工作,即集群中其他的slot都是闲置的。
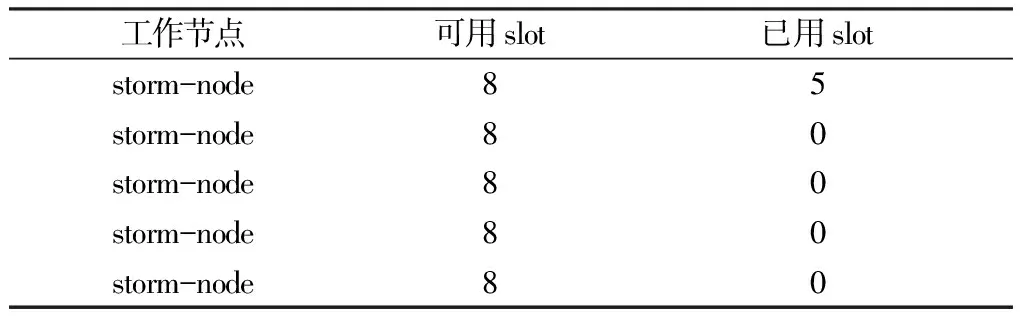
表2 直接分配固定节点的任务分配调度策略调度结果
通过将子拓扑list的并发度定义为2,4,6,8,并将该list提交到集群中,并分别将引用storm默认的调度器以及直接分配固定节点的任务分配调度策略进行识别时延对比,实验结果如图4所示。根据图4可知,直接分配固定节点的任务分配调度策略因降低了各个数据在网络关联度,明显降低了数据处理时延。

图4 不同并发下的两种调度器的处理时延
3.4 基于负载均衡的任务调度策略评价
为了更好地测试集群负载均衡任务调度策略的正确性,在当前集群环境中配置以下任务负载,并实时记录各个集群的使用情况。
(1)创建一个子拓扑T1,包含了一个spout(1个任务),两个bolt(均为8个task),定义并发度为4;
(2)创建一个子拓扑T2,包含了spout(1个任务),3个bolt(前两个bolt为8个task,第三个bolt为1个task),定义并发度为3;
(3)创建一个子拓扑T3,包含了spout(1个任务),2个bolt(均为8个task),定义并发度为3。
在提交每个子拓扑作业后,集群中节点slot数量的使用情况如表3。分析表3可知,在完成T3子拓扑提交后,集群中每个节点都应用了2个slot。由此可得基于负载均衡的任务调度可以将子拓扑中作业进程平均分配给各个工作节点,且在任务调度时,选择可用资源数量最大的节点进行分配。
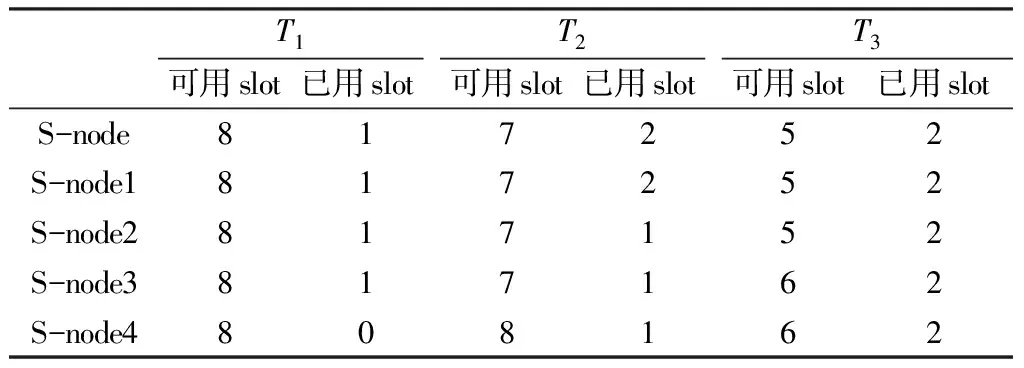
表3 基于负载均衡的任务调度策略
4 结论
Storm是当前处理流式大数据的主要框架,已经被广泛应用在实时性要求较高的领域行业中。Storm自带任务分配调度器没有考虑现实环境中任务需求以及负载均衡,会对任务调度性能产生比较大的影响。提出两种优化调度策略来解决上述问题,实验结果表明具备较好的实时处理效率。
猜你喜欢
吉林大学学报(信息科学版)(2022年2期)2022-08-15
现代电子技术(2022年8期)2022-04-13
计算机测量与控制(2022年2期)2022-03-30
网络安全技术与应用(2020年1期)2020-01-07
军事运筹与系统工程(2019年4期)2019-09-11
信息化建设(2019年2期)2019-03-27
电子制作(2018年11期)2018-08-04
知识就是力量(2017年2期)2017-01-21
科技与管理(2014年5期)2015-01-06
计算技术与自动化(2014年1期)2014-12-12
