
基于社交网络隐私信息挖掘的情绪智力画像方法研究
2019-07-08 07:09刘禹辰王伟
网络空间安全 2019年2期
刘禹辰 王伟


摘 要:在当今的大数据时代, 隐私挖掘和用户画像已经成为分析目标特征的一项重要技术。文章通过对传统情绪智力模型进行改进,提出了一种情绪智力水平的量化方法。该方法对目标用户在不同社交网络下产生的自然数据进行提取、分词和情感分析后,使用模型内各指数的生成规则量化目标用户的情绪智力,构建情绪智力模型并生成情绪智力值。最后分析了模型量化结果的具体案例和群体得分分布,并证明了通过隐私信息挖掘量化目标用户情绪智力方法的可行性、可量化、可解释等特点。
关键词:情绪智力;隐私挖掘;用户画像;情感分析
中图分类号:TP391.1 文献标识码:A
Privacy mining and emotional intelligence portrait in social networks
Liu Yuchen, Wang Wei
(Beijing Key Laboratory of Security and Privacy in Intelligent Transportation, Beijing Jiaotong University, Beijing, 100044)
Abstract: Privacy mining and user portraits have already become an important technology for target feature analysis in the big data era. This paper improves the traditional emotional intelligence model and proposes a quantitative method for the level of emotional intelligence. This method extracts, segments and emotional analyzes the natural data generated by the target users in different social networks, and then quantitates the target users' emotional intelligence ability by generating rules of indices in the model, constructs emotional intelligence model and generates the emotional intelligence number. Finally, this paper analyses the specific cases of quantitative results and the distribution of group scores, and proves that the method of quantifying the emotional intelligence of target users through privacy information mining is measurable and feasible.
Key words: emotional intelligence; privacy mining; user portrait; emotional analysis
1 引言
随着互联网的飞速发展,人们越来越依靠网络进行日常活动,这些行为在网络上留下的痕迹经过数据挖掘就可以生成用户画像。虽然该技术已经有了较为成熟的理论和商业应用,但大多局限于生成目标在某个特征上的画像,很少有涉及其本身性质的。为了能够通过目标用户在社交网络中产生的自然数据获取其人性方面的画像,本文以传统的情绪智力模型为基础,提出了一个构建用户情绪智力画像的方法,以反映目标的情绪控制能力、压力应对能力、人际关系能力等多种内在特质。
2 隐私数据挖掘
數据挖掘[1]作为一种通过相关算法在大量的数据中搜索并找出隐藏信息的技术,已被广泛应用到科学、医学和商业领域[2]。随着信息安全与数据挖掘的融合,对含有用户隐私信息的数据进行隐私挖掘变得备受青睐。该技术将目标用户的隐私数据进行适当的自然语言处理后,通过某些特定的算法和规则生成其在某些特质方面的画像,从而分析并获得目标用户的个人隐私。
社交网络上的数据可以按照数据的公开性分为媒体数据和聊天数据。本文使用网络爬虫采集了微博、豆瓣和美团点评三个分别在各自领域具有代表性的网络社交媒体数据。这类数据获取方便、数据量足够大,但由于社交平台是公开的,目标在发表言论时势必有所保留,这会导致在后续分析过程中存在一定偏差。
网络社交聊天数据能够更准确地分析目标的内在特质,本文通过手机聊天软件获取用户的聊天数据。微信是人们当前使用最广的一款即时通讯软件,含有足够的隐私数据。由于微信的聊天记录都是储存在本地的,因此只要掌握数据库密码的生成算法,就可以很方便地采集到用户的聊天数据。
3 中文分词与情感分析
3.1 中文文本分词
在获取到足够的数据后,就需要进行自然语言处理,本文采用基于统计的分词方法进行中文文本分词[3]。该方法与传统的基于词典的分词方法相比,能够很好地处理歧义问题和未登录词识别问题[4]。
首先使用全切分法[5]对文本进行所有形式的切分,然后从右向左依次计算各分词的出现频率,最终得到该情况下整句的出现频率,而所有情况中句频最大的情况即为近似最优解。对于未登录词的处理则使用隐马尔科夫模型[6],将一个句子以“BEMS”组成的序列串作为输出,通过调用维特比算法计算出这个句子关于“BEMS”状态的最大可能输出序列,从而完成整个句子的分词。
3.2 中文情感分析
情感分析是对带有情感色彩的主观性文本进行分析处理的过程[7]。本文采用一种基于词典和统计相结合的方法进行情感分析,对于词典中收录的词使用查询的方法计算情感值,对于未登录词通过相似度匹配算法判断其是否为情感词,并计算近似情感值。
3.2.1 情感词的情感值
情感词典是对情感词进行极性分类、情感分类和强度分析的词典,本文选取大连理工大学信息检索研究室的情感词汇本体库[8]作为情感词典。该库将情感分为乐、怒、哀、惧等七个大类,每个情感词具有强度和极性两个属性。
对于一个存在于情感词典中的词语,设为该词的情感值得分,为情感词强度,为修正后的情感词极性,则其情感值为。当该词的情感属性与极性相同时,;相反时,;当该词的情感极性为中性或褒贬兼有时,。
3.2.2 未登录词的情感值
对于情感词典中未收录的词语,首先要进行情感词的判断。判断方法为选取一些情感词作为词原,然后计算该词与词原的相似度,若相似度足够大则判断其为情感词并计算情感值。
知网提供的语义层次树是当前覆盖范围最广的中文语义关系网络[9],可以用于相似度的计算。由于该网络以词义为单元,故需将词原分解为更小的义原。对于词语和词原,其词语相似度即为各义原相似度的最大值,义原间的相似度为:
其中,为两个义原在语义层次树中的距离,为可调节参数,取[10]。
将情感词典中所有词语作为词原,计算未登录词与所有词原的相似度,相似度最大的即为未登录词的近似词原。设近似度阈值,为近似词原的情感值,则该词的最终情感值为:
3.2.3 副词的情感值修正
除情感词外,副词也会很大程度上影响句子的情感值。本文综合了知网的程度和否定副词表,使用影响因子来量化影响程度,如表1所示。
对于被副词修饰的情感词,其情感值修正为原情感值依次乘以所有修饰副词的影响因子。此外,当否定词在程度副词之前时会降低修饰程度,此时修正其影响因子为原来的一半。
3.2.4 句子的情感值
将全句中所有情感词依次相加,即可得到该句的情感值 ,然后通过引入反正切函数保证其在低分数段区分度放大且整体收敛。此外,若句中存在递进或转折关联词,则做出如下修正。
(1)递进,即后句拥有比前句更强的情感。设前句情感值为e1,后句为e2,则e=e1+1.5e2。
(2)转折,即后句拥有与前句完全相反的情感,此时e=-e1+e2。
4 构建情绪智力画像
4.1 情绪智力
情商[11]这一概念由以色列心理学家巴昂首创,美国心理学家萨罗维首次提出情绪智力这一概念,定义为“监控自己和他人的情感和情绪,对其加以识别并用这些信息指导自己的思维和行为的能力”[12]。此后,巴昂联合多名学者出版了《情绪智力手册》,提出了标准的情绪智力测量方法,即巴昂情绪智力模型。该模型是当今最受认可的情绪智力模型,包括个体内部、人际、适应性、压力管理和一般心境五个指数[13]。
然而随着这一模型的普及,其在量化过程中存在的问题也暴露出来[14]。一是情绪智力的善变性,即与接受测试时相比,目标的情绪智力水平会发生改变。二是测试结果的真实性,即目标在受测时的积极程度和主动性。若目标的心情是快乐,就会下意识地作出乐观的判断,导致整体结果偏向于高分,反之亦然。此外,目标是否主动配合测试也影响结果的真实性,目标或许会对于某些方面的问题避而不谈,甚至弄虚作假,导致最终结果不准确。
4.2 模型改进
随着隐私挖掘技术的介入,上述两个问题都得到了很好的解决。传统的巴昂情绪智力模型试图用一般心境指数来修正目标受测时的积极程度,但由于人为干预的可能性无法排除,因此仍存在很大的偏差。隐私挖掘方法能够在目标不知情的情况下获取数据,具有很高的真实性。对于量化過程中的另一个缺陷,由于获取的是用户在所有时间段的社交数据,便可以从整体上计算用户的情绪智力能力,无需拘泥于某一时刻的改变。
为使传统的情绪智力模型能更好地反映目标的情绪智力水平,本文在不影响原模型结构的前提下做出了一些改进。首先,取消了一般心境指数,因为在当前技术背景下已无需对数据的真实性进行修正。其次,将个体内部指数分为认知和管理两个指数,以便从宏观和微观分别量化目标的情绪控制能力。改进后模型的结构如下。
(1)认知指数,衡量目标是否能在大多数情况下,拥有对情绪的自我意识。
(2)管理指数,衡量目标是否能在各种情况下,维持情绪状态稳定不变。
(3)压力指数,衡量目标是否能在情绪因突发事件而受到巨大影响时,迅速调整其回到常态。
(4)感染指数,衡量目标能否快速理解他人情绪,并使得自我情绪被带入。
(5)人际指数,衡量目标在日常人际交往过程中受到的认可程度和接纳程度。
4.3 模型量化
将情感值与情绪智力模型联系起来,就可以通过句子情感值来量化各指数的大小,从而计算总情绪智力值。首先,使用窗口将文本数据进行分块,规定若窗口值为,则每个窗口内含有个被测目标的句子。此时在各窗口内被测目标的情感值为该窗口下各句的平均情感值,方差为各句情感值得分的方差,情绪变化值为前后两窗口平均情感值的差。此外,由于部分文本中含有对话,故数据中还存在与被测目标交流的陪测目标,陪测目标拥有与被测目标类似的平均情感值、方差和情绪变化值。
在选择了合适的窗口大小后,通过每次后移一个句子的方式可计算每个窗口内的数据值,然后根据模型要求进行判断和计算。下面分别给出情绪智力模型中五个指数的量化方法。
4.3.1 认知指数
认知指数评价目标对自我情绪的认知能力,主要体现在各窗口情感值的方差上,即认为拥有低方差值的目标能够维持一个较为稳定的平均情感值,拥有较强的情感认知能力。此外,该指数也受文本的总情感值影响。若目标数据文本的总句数为,总窗口数,则其认知指数为。
4.3.2 管理指数
管理指数评价目标的情绪管理能力,判断规则:当某窗口内目标的情感值方差超过0.1时,说明此时其情感值发生了较大波动,标记该窗口为波动窗口。然后评估目标到情绪稳定且情感值为正值所需的时间,即出现一个方差值不超过0.1且平均情感值为正值的窗口所需的时间。
设波动窗口出现后,下一个满足条件的窗口首句与波动窗口首句间相差个句子,则该窗口的管理指数为。目标的管理指数为所有波动窗口管理指数的平均值。
4.3.3 压力指数
压力指数评价目标在压力下调整自我情绪的能力。首先规定当某窗口内目标的平均情感值小于0时,为目标受压情况,标记该窗口为受压窗口,然后评估目标在受压后将情感值首次调整为正值所需的时间。
设受压窗口出现后,下一个平均情感值为正值的窗口首句与受压窗口首句间相差个句子,则该窗口的压力指数为。目标的压力指数为所有受压窗口压力指数的平均值。
4.3.4 感染指数
感染指数评价目标情绪受他人影响的程度,判断规则:当某窗口内陪测目标的情感值方差超过0.1时,说明陪测目标的情感值发生了较大波动,标记该窗口为被感染窗口。在该类窗口内,被测目标的情感值方差和情绪变化值为计算感染指数的重要指标。同时,用相似参数表示该窗口内被测目标与陪测目标平均情感值的相似程度,取。则该窗口的感染指数为,目标的感染指数为所有被感染窗口感染指数的平均值。
4.3.5 人际指数
人际指数评价目标影响他人情绪的能力,与感染指数的量化方式大致相同。当某窗口内被测目标的情感值方差超过0.1时,说明被测目标的情感值发生了较大波动,标记该窗口为影响性窗口。则该窗口的人际指数为,目标的人际指数为所有影响性窗口人际指数的平均值。
5 情绪智力量化结果与分析
5.1 结果分析
5.1.1 目标量化结果分析
根据上述量化方法,将获取到的用户数据先后通过文本分词、情感分析和模型构建处理,就可以量化出目标用户的各项指数及最终情绪智力值。
现任选几组目标数据进行实验,首先进行数据清理和文本分词,分词结果如图1所示。
分词结果中,词语使用单斜线分隔,句子使用双斜线分隔。在分词完成之后,就通过情感分析,计算每个句子的情感值,计算结果如图2所示。
根据上文中的情绪智力量化方法,通过句子情感值计算出五个指数的具体数值。由于各指数间的量化方法是相互独立的,故在生成目标用户的总情绪智力值时需要对各指数分别进行加权,保证各级指数的评分模式处于同一水平下,然后将各加权后的指数得分取平均值,即为用户的总情绪智力值,结果如表2所示。
其中,第1、3、5组为点评数据,第2、4、6组为影评数据,第7、8组为聊天數据,表中选取的均为在相应方面内比较有代表性的数据结果。由各组的数据得分可以看出, 社交网络数据的分数与用户的手动评分级别基本成正相关趋势,隐私聊天数据由于其对话信息较为密集,故其人际指数得分普遍较高。
表中的各项指数代表着目标用户在该项上的具体能力水平,分值越高表明其在该项上的能力越强。例如,第2组数据的各项指数均较高,说明该目标的各项情绪智力能力都很优秀,而观察上图中的用户文本也可以发现,该目标的确做出了积极的评价,情感分析结果中的句子情感值也基本保持正值,且部分句子情感值得分较高;而第3组数据中的管理指数得分较低,说明该目标在情绪控制方面的能力较差,而观察其用户文本发现,该目标的确在评价中对于其不喜爱的方面给予了较低的评价,且在后文中持续对这些方面进行评论和抱怨;第7组数据中的压力指数较低,说明该目标的压力应对能力较差,这也在其用户文本中得到了体现。
5.1.2 群体分布情况分析
将所有数据集的量化结果按一定的各分数段进行数量统计,通过各分数段的用户频数值,就可以生成目标群体在各指数下的得分分布情况及其回归曲线,具体分布结果如图3和图4所示。
图3和图4分别为对80万条社交网络数据和100组微信聊天记录数据进行量化,得到的认知和管理指数得分分布图和回归曲线。由图中数据可以看出,大多数用户的得分都处在一个中等的分数段内,只有少数用户的得分极高或极低。将五个指数以相应的权重加和,得到目标用户的总情绪智力值分布图,如图5所示。
由上述结果可以看出,在本情绪智力模型中,大多数目标的情绪智力值集中在80~130分范围内,占总数的65.28%,属于正常情绪智力水平;低于80分的占21.96%,为较低情绪智力水平;高于130分的占12.76%,为较高情绪智力水平。各指数结果和总体结果趋于正态分布,符合基本的统计规律,也符合人们日常对于情绪智力值的理解和认知。
此外,在社交网络数据中存在着一些具有评分属性的点评类数据,这些数据本身就包含目标的情感信息,能够对情绪智力值的准确性起到验证作用。图6为所有点评数据中,各级评分的人数和该评分群体所有目标用户的平均情绪智力值。
由图6的结果可以看出,评分低的用户群体其平均情绪智力值也较低,反之亦然。而各评分用户的分布走势也与情绪智力值分布结果大致相同。
5.2 窗口值选取
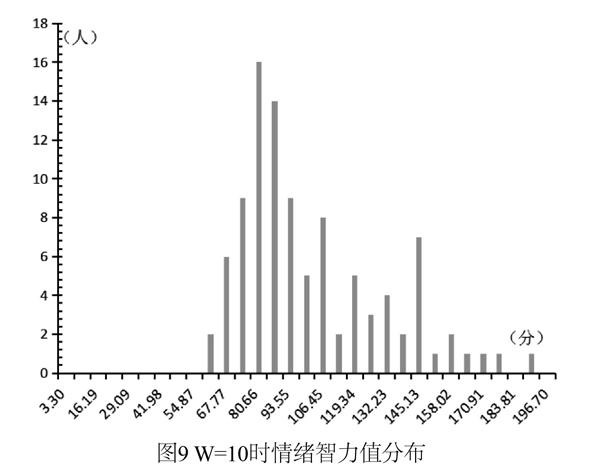
窗口宽度值会很大程度上影响情绪智力模型的量化结果。当窗口值较小时,会导致用方差进行窗口判断的管理、感染和人际指数出现漏报情况,使量化结果整体偏小;当窗口值较大时,由于目标用户很少会长时间保持较低情感,故会导致受压窗口的漏报,使结果整体偏大。窗口值为三种不同情况时,目标群体的情绪智力得分分布如图7、图8和图9所示。
由上述结果可以看出,过小的窗口值会严重影响最终结果,而过大则会使得情绪智力值结果的区分度不够明显。因此,选取最合适的窗口值就需要在保证窗口能够完整反映大多数负向情感的前提下,使窗口值尽量大。建议在选取窗口值时优先选取一个中等大小的数值范围,然后分别以该范围内所有整数为窗口值对数据进行模型构建,最终选取能够使量化结果区分度较大的数值作为窗口值。按照这一规则选取的窗口值既能确保受压窗口的判断不受影响,又能够使其他指数的结果更加准确可靠。
5.3 结论
通过以上隐私数据分析和情绪智力画像方法,可得到四个结论。
(1)本文的方法能够通过目标用户在社交网络上留下的行为数据,分析得到属于个人隐私的情绪智力能力,包括目标的自我认知、情绪管理、压力应对、社交感染和人际交往能力,以及总的情绪智力值。这些结果反映出目标所具有的各项能力水平,并且能够在其社交文本内容上得到很好的解释和印证。
(2)由目标用户群体量化结果可以看出,各项指数的得分分布基本都呈现“中间多,两端少”的状态,与正态回归曲线有着较高的契合度;同时,各级评分的用户平均情绪智力值折线走势也与总情绪智力值得分分布大体相同。这些现象证明了本文提出的情绪智力模型量化方法的确能够在一定程度上区分不同目标用户的情绪智力水平,在情绪智力能力方面也能够给出较为准确的评价。
(3)本文所有实验数据全部来自社交网络,实验结果也均为目标用户在社交网络下的情绪智力画像结果。由于本文是通过用户的文本数据进行分析的,因此对于任何能够提供用户文本信息的数据源,均可使用本文的方法进行情绪智力量化,即该方法在一定程度上具有普适性。
(4)本文的情绪智力模型的五项指数经巴昂传统情绪智力定义,受窗口值等参数影响,由文本分词、情感分析情况和模型量化方式共同决定最终结果。因此,只要准确应用本文的情绪智力模型量化方法,任何能够完成文本分词且能够分析并计算出句子情感值的方法都可被用于情绪智力模型的量化与构建。
6 结束语
本文从数据挖掘和用户画像的角度出发,通过用户在社交网络下的行为数据,分析其情绪智力能力。在通过网络爬虫、密码破译、文本分词等手段采集并处理数据后,使用基于词典和统计的中文情感分析方法计算情感值。该方法通过情感词典查询和相似度比对分别对不同的词语进行情感值计算,并从词语极性、强度、修饰、关联词等方面进行修正,降低了语法规则造成的误差,提高了最终结果的精确性。
为使情感值能够反映目标的情绪智力水平,本文分析了巴昂情绪智力模型的各项重要指标,提出了一个包含认知、管理、压力、感染、人际五项指数的改进型模型,并给出了量化规则。该规则以窗口为基本单位,通过特定数值情况判断特殊窗口,计算目标在各情况下的情感变化程度与情绪智力能力,并生成情绪智力值。随着人工智能的不断普及,情绪智力分析在对人性探索方面有着越来越重要的意义,在对目标进行分析和预测上也发挥着越来越重要的作用。
基金项目
1.国家重点研发计划重点专项(项目编号:2017YFB0802805);
2.国家自然科学基金(项目编号:U1736114)。
参考文献
[1] 吴超超,李伟春.基于隐私保護的数据挖掘技术与研究[J].科技资讯, 2015(15): 20.
[2] 张海涛,黄慧慧,徐亮,高莎莎.隐私保护数据挖掘研究进展[J].计算机应用研究, 2013,12(15):3529-3535.
[3] 吴熠潇.中文分词相关算法研究[J].科技经济导刊, 2017(27):122-123.
[4] 陈开昌.自然语言处理技术中的中文分词研究[J].信息与电脑(理论版), 2016(19):61-63.
[5] 常朝稳,魏进.基于全切分算法的歧义识别与处理[J].计算机工程与应用, 2008,44(15): 145-147.
[6] 岑咏华,韩哲,季培培.基于隐马尔科夫模型的中文术语识别研究[J].现代图书情报技术, 2008(12):54-58.
[7] Liu B. Sentiment analysis and subjectivity[A]. N. Indurkhya, F. J. Damerau. Handbook of Natural Language Processing[M]. Second Edition, Florida:CRC Press, 2010,627-661.
[8] 徐琳宏,林鸿飞,潘宇.情感词汇本体的构造[J].情报学报,2008,27(2):180-185.
[9] 闫红,李付学,周云.基于HowNet句子相似度的计算[J].计算机技术与发展, 2015(11):53-57.
[10] 刘群,李素建.基于《知网》的词汇语义相似度计算[J].中文计算语言学, 2002,7(2): 59-76.
[11] Bar-On R. BarOn Emotional Quotient Inventory:Technical Manaual[M]. Toronto: Multi-Health Systems Ins, 1997,1-8.
[12] Mayer JD, Salovey P. The Intelligence of Emotional Intelligence[J]. Intelligence, 1993,17(4):433-442.
[13] Bar-On R. The Handbook of Emotional Intelligence[M]. San Francisco: Jossey-Bass, 2000,1-10.
[14] Bar-On R. BarOn Emotional Quotient Inventory: Youth Version Technical Manaual[M]. Toronto:Multi-Health Systems Ins, 2000,6-7.
猜你喜欢
中国广播(2017年1期)2017-02-21
艺术研究(2016年4期)2017-01-16
物联网技术(2016年11期)2017-01-12
电子技术与软件工程(2016年22期)2016-12-26
预测(2016年5期)2016-12-26
亚太教育(2016年34期)2016-12-26
现代情报(2016年10期)2016-12-15
科技资讯(2016年18期)2016-11-15
现代经济信息(2016年24期)2016-11-09
电脑知识与技术(2016年7期)2016-05-19
