
蒙特卡罗临界计算全局计数问题新策略研究*
2019-06-29 08:23上官丹骅姬志成邓力李瑞李刚付元光
物理学报 2019年12期
上官丹骅 姬志成 邓力 李瑞 李刚 付元光
1)(北京应用物理与计算数学研究所,北京 100094)
2)(中国工程物理研究院高性能数值模拟软件中心,北京 100088)
1 引 言
计算核相关系统的临界性在核科学与工程领域是常见而重要的问题.作为一种成熟的计算方法,蒙特卡罗算法由于其几何、物理建模的精确性以及高度的可并行性等特点在临界计算中得到广泛的运用.
在最近的研究[1-4]中,由于计算机硬件与模拟计算方法、软件的巨大进步,使得过去由于能力不足而采取的近似手段有了可以进一步精确化处理的能力,例如反应堆设备的pin-by-pin计算等.这些趋势反过来对于计算方法和软件提出了更大的挑战.对于临界问题的蒙特卡罗模拟而言,由于核设备的精细化建模及多物理耦合计算需求,在计算临界特性(即特征值)的同时进行大规模的全局计数成为一个难以高效解决的问题[5-7].困难一方面来自于计数规模的庞大;另一方面来自于计算目标不能仅仅瞄准于最大程度地减少最小误差,而是必须提高全局计数的整体效率,这就使得单纯增加样本数是一种低效甚至无效的策略,因为在功率较高、误差较小的区域更容易得到新增样本,而功率较低、误差较大的区域反而得不到新增样本,从而使得整体效率难以提高.
为提高临界计算全局计数问题的整体效率,出现了一些算法上的研究.这些研究以95/95准则[5](即要求在一定时间内,至少95%的栅元内计数的相对误差要以至少95%的置信度位于1%以下)为指导,力图在总样本数一定的前提下获得更高的整体效率,其中均匀裂变点(UFS)算法[5-7]是最早提出的一种.该算法在假设裂变源本征分布已经达到的前提下,通过统计已完成迭代步的裂变点数密度,以此来偏倚当前迭代步的裂变次级平均粒子数,然后通过纠偏的手段保持结果的无偏性,最终的效果是在统计意义上使得计算误差较大的区域产生更多的低权重粒子而在计算误差较小的区域产生更少的高权重粒子,从而使得整体效率得到较大的提高.但是如果在裂变源分布还未收敛的情况下启动UFS算法,由于统计得到的裂变点密度具有系统误差,将会导致算法应用失败,解决这一问题的方法一般是凭经验选择一个足够大的非激活迭代步数来保证裂变源分布的收敛.同时,由于只在完成所有的设定迭代步计算后才统计整体效率,即使计算早已达到事先设定的整体效率标准,也不得不进行多余的计算.在后续的研究中还出现了效率更高的均匀计数密度算法[8,9].
本文提出了一种进一步提高临界计算全局计数问题整体效率的新策略.这一策略在自主研发的定态蒙特卡罗粒子输运模拟软件JMCT上进行了验证.本文第2节将介绍包含两个部分的新策略;第3节给出了相应的数值结果;第4节给出了结论.
2 提高临界计算全局计数问题效率的新策略描述
这一新策略包含两个部分.首先,基于一个裂变源分布对应香农熵的实时收敛性诊断方法,为提高全局计数整体效率而设计的UFS算法将在首次激活迭代步和首次判断收敛迭代步的最大值之后被激活,这就为保证裂变源分布已经收敛提供了双重保障,从而保证了UFS算法所使用的偏倚数据更加合理;其次,在UFS算法被启动后,将定期监测全局计数的一个整体精度指标,一旦这个指标小于事先约定的数值,则认为全局计数已经很好地收敛,整个计算将被终止,而不必等到事先设定的最大迭代步数全部完成.下面将详细介绍这两部分.
2.1 基于香农熵的裂变源分布实时收敛性诊断方法
香农熵最先引入蒙特卡罗临界计算是作为判断裂变源分布是否收敛的后验指标,同时,也存在另一些基于其他熵的实时收敛性诊断方法研究[10-12].基于香农熵的实时收敛性诊断方法在减少非定常输运问题的计算时间方面获得了成功的应用[13].将这一实时收敛性诊断方法应用在定态蒙特卡罗临界计算方面还属首次.
裂变源分布对应香农熵H的基本定义如下[10]:
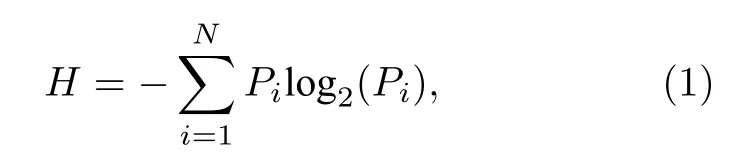
基于香农熵的实时收敛性判断准则依赖于多个香农熵值组合出的随机振子指标Kn,定义为[11]

其中,Hn是当前第n个迭代步的香农熵值,和分别是当前第n迭代步之前所有p个香农熵中的最大值和最小值.在香农熵值序列已经收敛的前提下,Kn将在0.5附近做无规随机涨落.实时判断香农熵是否收敛的准则在于判断当前第n迭代步及之前所有m个随机振子指标是否满足不等式[13]
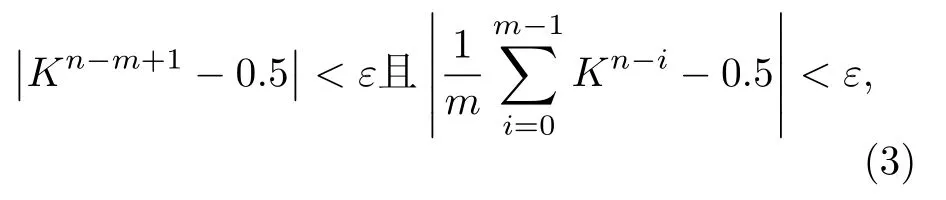
一旦满足,则认为裂变源分布已经收敛,可以在n和事先约定的非激活迭代步的最大值之后启动计数过程及UFS算法;p,m,ε按参考文献[11]的推荐取为20,50,0.1.
2.2 基于全局计数整体精度指标定期监测的提前结束计算方法
衡量全局计数整体效率的95/95准则的本质在于以尽可能少的计算时间获得尽可能高的整体精度.整体精度指标其实有很多种,都从一个方面反映了全局计数的整体收敛状况.95/95准则使用的整体精度指标是Pre_95,即所有计数的相对误差中至少95%的相对误差都不大于该值.要在并行计算环境下定期监测这一整体精度指标,就必须在激活UFS算法后每隔固定迭代步数计算一次所有计数的相对误差,而通常来说,并行蒙特卡罗程序需要进行规约之后才能得到计数的相对误差,一般仅在所有迭代步完成之后进行规约并输出计数.为解决这一问题,JMCT采用了对象序列化与在线反序列化技术(由于JMCT采用面向对象的编程方式实现,程序运行时将产生多个对象实例,其内存排布是无序的.但重启动及续算功能需要将对象保存在文件中,需要内存对象是有序且连续的.在数据备份时对无序对象进行的操作就是序列化,在恢复运行时对数据的操作就是反序列化),以最小的I/O开销实现了并行环境的备份与恢复,从而支持在任意迭代步中进行计数规约操作.
3 数值结果
以C5G7模型(图1)作为验证上述策略的基准模型.该模型是NEA发布的程序检验基准例题.其中包含两种组件,分别是铀氧化物UOX组件和铀钚混合氧化物MOX组件,交叉2×2布置.每个组件内有17×17个pin-cell,其中又分为264个燃料pin、24个导向管pin和一个仪表管pin.UOX组件中,包含一种富集度;MOX组件中包含三种富集度.该模型大约包含2万个栅元,其详细介绍可以参考文献[14].
以全局体平均通量计数作为计算目标.由于没有标准答案,所以,通过大规模1000迭代步的计算(每代5百万样本,跳过前500代)获得基准解,这一计算规模对于该问题是足够的.图2所示裂变源分布对应香农熵的变化反映了这一点.分四种情况进行了计算:1)不启动策略和UFS算法(简称为no_stra_no_UFS);2)不启动策略、启动UFS算法(简称为no_stra_with_UFS);3)启动策略、不启动UFS算法(简称为with_stra_no_UFS);4)启动策略和UFS算法(简称为with_stra_with_UFS).最初的设置是1500迭代步,跳过200代,每代20万样本数.图3显示了不启动策略时有无UFS算法裂变源分布所对应香农熵的变化,可以看出,200代的非激活迭代数目是不够的,也就是UFS算法利用了不够精确的数据进行偏倚.为考察全局计数的整体精度,设计了整体精度指标E_global,定义如下:
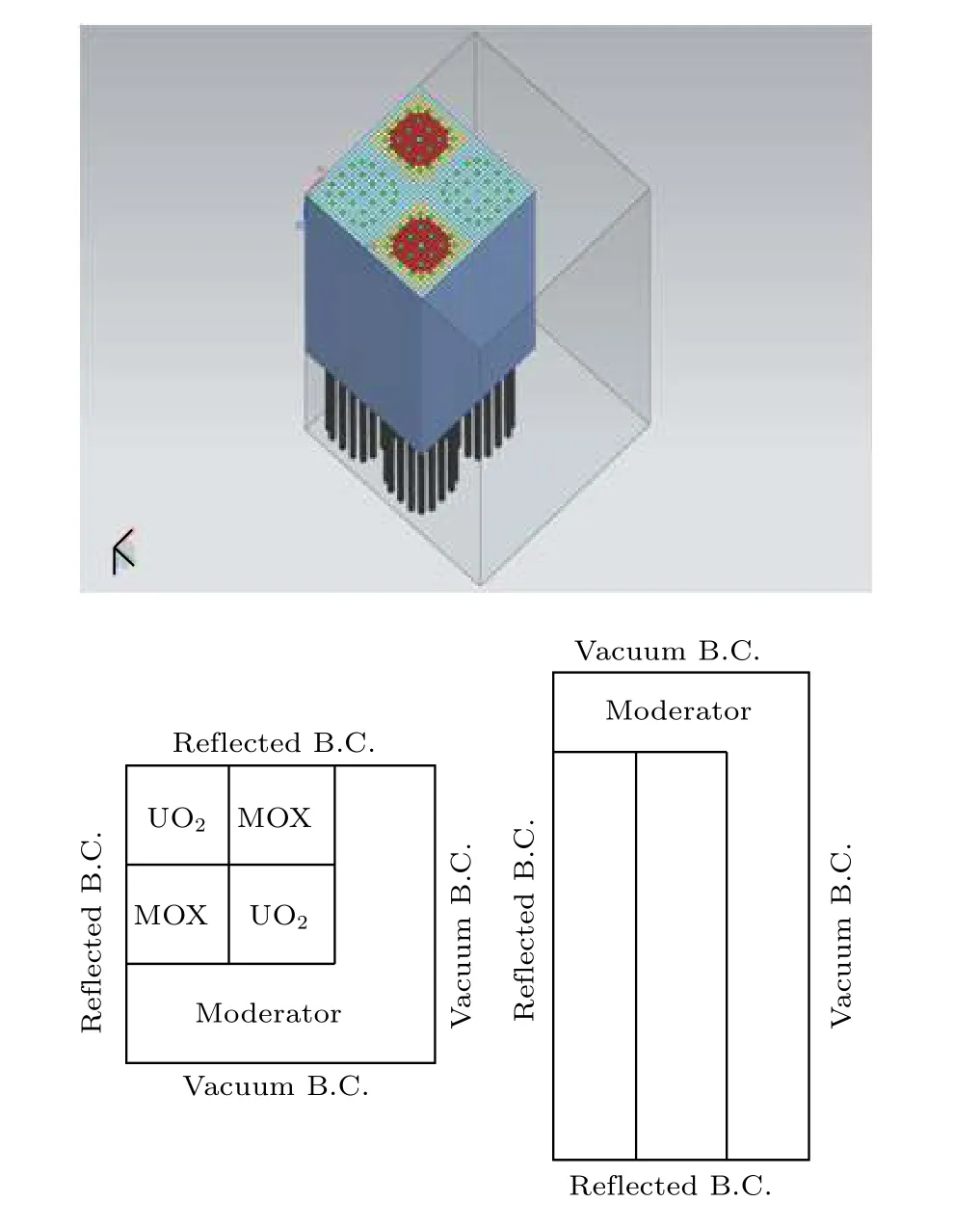
图1 C5G7模型图Fig.1.C5G7 model.


图2 基准解裂变源分布对应香农熵的变化Fig.2.Shannon entropy of fission source distribution for benchmark result.
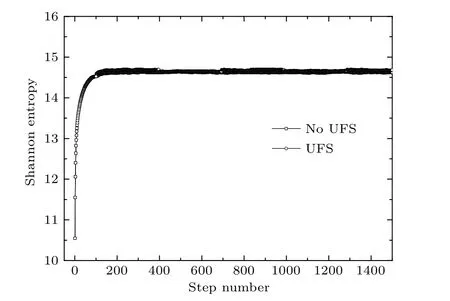
图3 不启动策略时有无UFS算法的裂变源分布对应香农熵的变化Fig.3.Shannon entropy of fission source distribution for two cases (without strategy and with or without UFS algorithm).
当启动策略时,原先约定的在第201步启动计数或UFS算法被推迟到第224步,显示香农熵的实时诊断方法判断直到第224步裂变源分布才收敛得比较充分.如果要求只要整体精度指标Pre_95不大于0.004就结束整个计算,且每隔40步判断一次,则不启动UFS算法时在第944步达到要求,而启动UFS算法时在第824步就达到了要求.从表1可以看出,各种情况下计算得到的特征值keff基本没有什么变化,说明各种方法得到的结果都是无偏的.由于不启动策略时UFS算法启动得过早(在第201步启动),no_stra_with_UFS这种情况下的整体计算精度E_global是较差的,即使其已经完成了全部1500个迭代步的计算.对于with_stra_no_UFS情形,虽然启动计数过程较晚,裂变源分布收敛得已经比较充分,但由于总共只有944个迭代步,有效样本较no_stra_no_UFS情形少很多,又没有UFS算法使全局计数的相对误差平均化,所以整体精度指标E_global是最差的,即使此时指标Pre_95已经小于0.004.而对于with_stra_with_UFS情形,虽然结束计算的时刻更早(在第824步),从而有效样本数更少,但由于启动UFS算法对全局计数误差的平均化效应,其整体精度指标E_global是最好的.

表1 结果比较Table 1.Comparison of results.
4 结 论
对于蒙特卡罗临界计算全局计数问题,基于已有的UFS算法,提出了一种进一步提高效率的新策略.该策略通过基于裂变源分布对应香农熵的实时判断收敛准则和对全局计数整体精度指标的定期监控,可进一步确保UFS算法获得质量更高的数据并且在保证精度的前提下减少冗余计算,从而提高了整体效率.对C5G7基准模型的计算表明本文提出的策略在参数合适时是高效的.当然,由于新策略中还有经验参数,利用更智能化的方法消除这些参数是下一步工作的目标.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
现代仪器与医疗(2022年3期)2022-08-12
雪豆月读·低年级(2021年7期)2021-08-27
现代计算机(2019年19期)2019-08-12
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
金桥(2018年4期)2018-09-26
科学之谜(2018年10期)2018-01-02
新东方英语·中学版(2017年4期)2017-05-04
