
基于卷积神经网络的手势识别网络
2019-06-27 04:21马俊峰
西安邮电大学学报 2019年6期
官 巍, 马俊峰, 马 力
(西安邮电大学 计算机学院, 陕西 西安 710121)
手势识别[1]是通过数学算法识别人类手势,使得机器设备按照人的意愿解决实际问题,是人机交互重要应用之一,现已广泛应用在教育和医疗、机器人控制、未来智能家居和交通等领域。
手势识别分为传统手势识别和卷积神经网络手势识别[2]。传统手势识别主要是手势分割、特征提取和手势识别。典型的手势识别算法包括哈尔(Haar-like,Haar)特征[3]、自适应提升(adaptive boosting,Adaboost)算法[4]、方向梯度直方图(histograms of oriented gradient,HOG)特征[5]、支持向量机(support vector machines,SVM)算法[6]和变形部件模型(deformable parts model,DPM)算法[7]等。基于骨骼信息的手势识别算法[8]通过提取骨架特征信息,对于单一背景识别效果较好,但这种方法前期提取特征难度较大,有干扰的特征信息存在。人机交互动态手势轮廓提取算法[9]通过提取手势的轮廓进行手势识别,也是对于单一背景识别效果较好,但复杂背景识别效率极低。基于无监督特征学习的手势识别方法[10]通过无监督的特征学习手势识别提高了手势识别的效率,但是识别率还是达不到理想要求。基于视觉的静态手势识别系统[11]虽然是成型的系统,但识别效果简单单一,识别准确率不高。基于改进凸分解的手势识别[12]利用肤色信息的手势区域检测与分割方法,可轻易得到表征手势特征的骨架信息,识别率较好,但容易受到光照影响和背景干扰。
卷积神经网络手势识别主要利用深度学习方法的图形分类与检测,提高手势识别精度,增强抗干扰能力。然而,基于深度学习的静态手势实时识别方法[13]通过录制的视频,将网络中的较深网络修改为浅层网络,虽然识别速度上升了,但识别率并不高;基于深度学习的手势识别算法[14]属于轻量级网络,识别速度较快,但识别率仍不高;基于深度信息的手势识别算法[15]能够使用图像的深度信息进行识别,但仅对简单容易区分的剪刀石头布训练识别,具有一定的局限性;参数自适应变化的强机动目标跟踪算法[16]对于复杂背景的目标有较好的识别效果,但识别率还有待于提高。
为了更好的提高手势识别率,本文建立一种基于卷积神经网络的手势识别网络。将Faster R-CNN修改为ResNet50,提取手势分割框;将VGG16的全连接层修改为1×1的卷积核,并修改激活函数Relu为LeakyRelu,通过调节参数及训练,进行手势图像的特征提取和识别。
1 手势识别基本原理
1.1 Faster R-CNN 网络
Faster R-CNN[17]是一个快速目标检测网络,通过引入区域建议网络(region proposal networks,RPN),使用端到端的方式训练得到高质量的区域建议框,提取对应区域的特征,并利用这些特征进行目标类别和边界框的预测,具体工作流程如下。
步骤1将输入的数据图像以多维数组的形式经过预训练卷积神经网络(convolutional neural networks, CNN)模型,获取卷积特征图。
步骤2将卷积特征图进行处理,经过区域生成网络,寻找可能包含目标的预定义数量的边界框。
步骤3利用预测的候选区域边框对特征图进行兴趣区域(regions of interest,ROI)操作并达到目标的识别和边界框的回归。
在RPN中,采用锚盒解决边界框列表长度不定的问题。对于每个滑动窗口,可以同时预测k个目标的候选框为锚点,每个锚点对应不同的尺度和比例。卷积特征图的每个点都是锚点的中心,即有k个相对应的锚点。窗口被映射到一个低维的向量,然后此向量被传到边界回归网络和边界分类网络。区域建议网络如图1所示。

图1 区域建议网络
1.2 VGG16网络
VGG网络结构较深,网络层数通常为16到24层,VGG16代表有16个权重层,网络输入为224×224大小的RGB图像,总共包含13个卷积层,5个最大池化层,3个全连接层[18]。所有滤波器大小为3×3,步长固定为1,最大的池化为2×2,步长为2,隐藏层的激活函数均采用非线性激活函数Relu。
VGG16卷积层中第l层中第j个特征图的数学表达式为[19]

对应的池化层的计算表达式为[20]

2 手势识别网络结构
手势识别网络结构分为两个阶段。第一阶段主要是将原始Faster R-CNN中的基础网络修改成ResNet50网络,增加网络深层学习能力,通过改进的Faster R-CNN提取分割后的手势分割框;第二阶段是将VGG16的全连接层修改为1×1的卷积核,并修改激活函数Relu为激活函数LeakyRelu,通过改进的VGG16网络进行特征提取与识别。手势识别流程如图2所示。

图2 手势识别流程
2.1 改进的Faster R-CNN
为了增强网络学习特征能力,将Faster R-CNN修改为网络更大、更强学习能力的ResNet50[20],通过检测手势目标,提取手势分割框。改进的Faster R-CNN结构如图3所示。

图3 改进后的Faster R-CNN结构
原始Faster R-CNN的特征提取使用VGG基础网络,有13个卷积层、13个激活函数和4个池化层。改进Faster R-CNN是将特征提取网络VGG替换为ResNet50网络,其中包含49个卷积层、49个激活函数和1个平均池化。采用更多的卷积层使得网络的学习能力更强,提升网络性能。
将RPN生成的候选框和特征提取网络进行ROI操作,共享卷积特征, 进行手势目标检测,从而提高了手势检测的速度。
美国手势手语(American sign language,ASL)公共数据集[21]在改进的Faster R-CNN网络中分割效果如图4所示。

图4 手势分割
2.2改进的VGG16网络
考虑到手势图像背景复杂而且种类更多,为了充分提取手势特征,使得识别效果更好,对卷积神经网络VGG16进行以下改进。
1)把全连接层修改成1×1的卷积核,代替全连接层,降低原始网络模型的参数,增加非线性能力。
2)将激活函数Relu修改成LeakyRelu ,在学习率设置较大的情况下,缓解神经元死亡问题,减少了稀疏性。
改进的VGG16网络模型如图5所示。输入手势框,经过每层卷积和池化,然后直接使用1×1的卷积核代替原始的全连接层,利用LeakyRelu激活函数改善稀疏问题。最后将提取后的手势框特征图经过分类器进行分类,从而进行手势图像的识别。
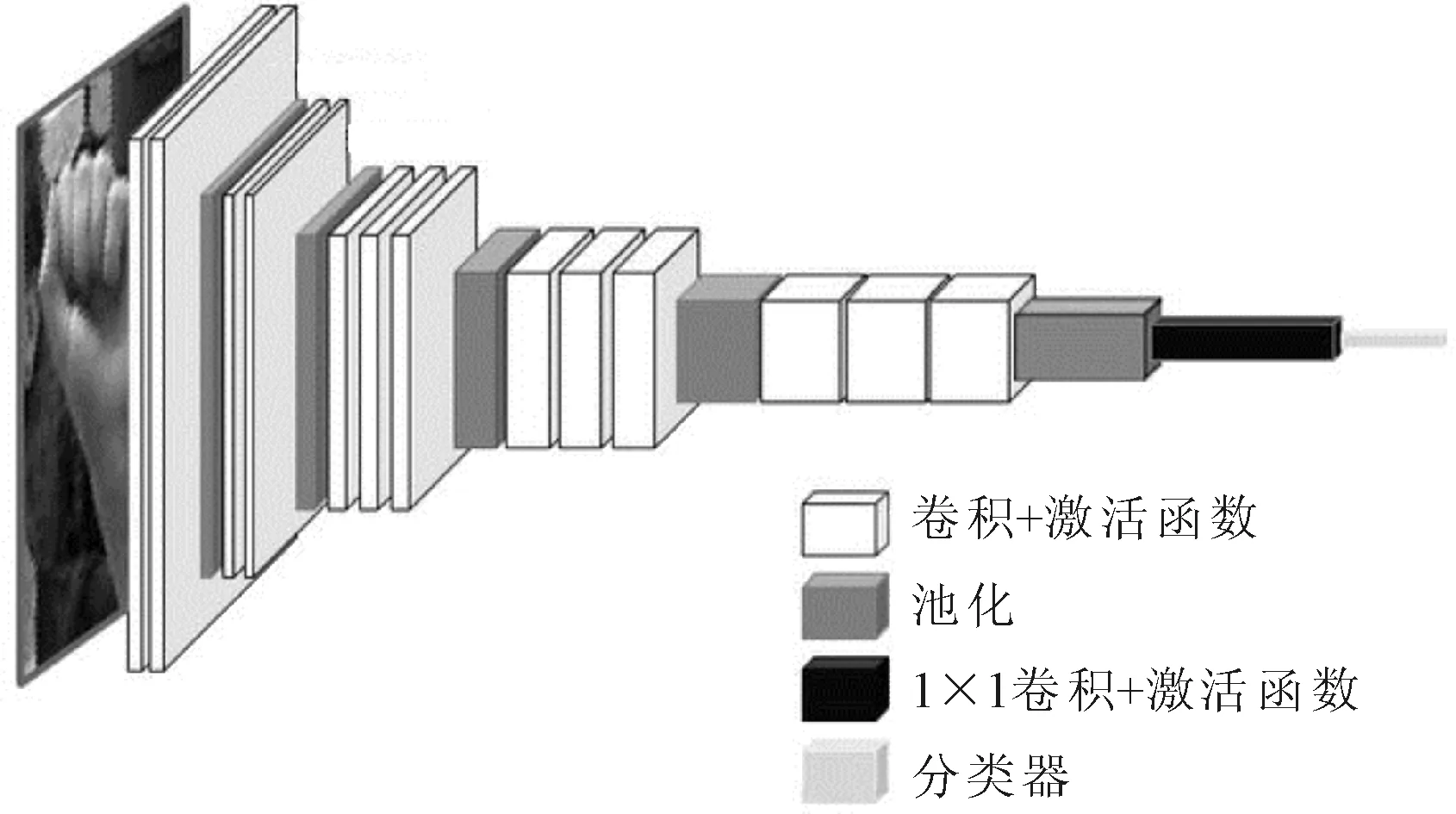
图5 改进的VGG16网络模型
3 实验结果和分析
3.1 数据集
选取ASL图像数据集对基于卷积神经网络的手势识别网络进行验证。该数据集每个手势分别由5个人在不同背景下完成,手势图像中一共有24个分类用于手语字母识别,分别由英文字母A到字母Z表示(字母J和Z的手势是动态的,这里不考虑)。每个手势样本有1 000张图片,RGB和深度图像各500张,总共有24×5×1 000=120 000张图像,训练集和验证集的比例是8∶2。
3.2 实验结果
将手势图像先通过原始Faster R-CNN进行分割,经过VGG16网络进行识别;再通过改进的Faster R-CNN进行分割,经过改进的VGG16网络进行识别,分别对比损失与手势识别率,结果分别如图6和图7所示。
由图6可以看出,改进网络在迭代4 K次时收敛,而原始网络在迭代5 K次时趋于0,说明改进网络损失收敛更快。由图7可以看出,随着迭代次数的增加,改进网络和原始网络的手势识别率有所提升,在迭代8 K次时,改进网络的手势识别率已经平稳,而原始网络在迭代16 K次才收敛,说明改进网络的手势识别率收敛更快。
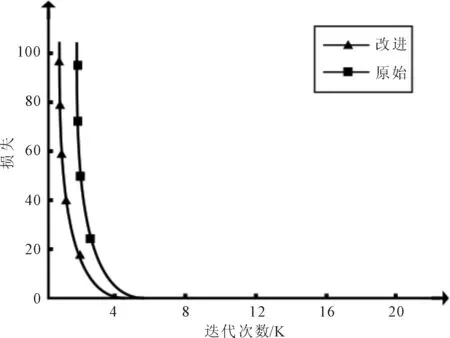
图6 原始网络和改进网络的损失对比

图7 原始网络和改进网络的手势识别率对比
3.3 不同方法对比分析
为了验证改进网络的高效性,分别对比改进网络与文献[8]、文献[10]、文献[11]和文献[13]方法在ASL图像数据集的手势识别率,结果如表1所示。
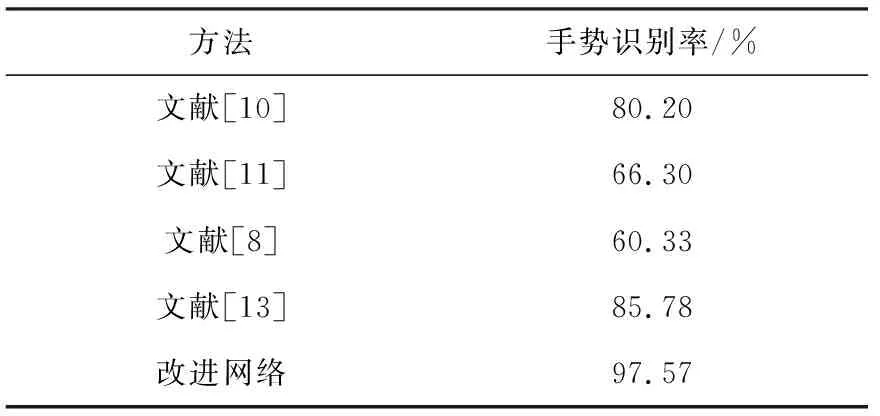
表1 不同方法手势识别率对比
由表1可以看出,文献[10]方法是半监督学习,在ASL图像数据集上识别率偏低,识别率为80.20%;文献[11]方法在ASL图像数据集上识别率仅仅为66.3%,这是因为ASL数据集背景复杂;文献[8]和文献[13]方法在ASL图像数据集上识别率分别为60.33%和85.78%;而本文通过改进的Faster R-CNN和改进的VGG网络,在ASL图像数据集中的识别率高达97.57%。
4 结语
基于卷积神经网络的手势识别网络将卷积神经网络Faster R-CNN的特征提取部分改进为ResNet50,在预处理阶段进行手势分割,减少无用的特征;将分割后的手势作为输入,在改进的VGG中进行手势特征提取及识别。实验结果表明,该网络手势识别率高达97.57%。
猜你喜欢
红领巾·萌芽(2019年9期)2019-10-09
电子制作(2019年15期)2019-08-27
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
小学科学(学生版)(2018年12期)2018-12-19
电子制作(2018年19期)2018-11-14
中国交通信息化(2018年3期)2018-06-13
小学阅读指南·低年级版(2017年6期)2017-06-12
自动化学报(2017年11期)2017-04-04
中国交通信息化(2016年2期)2016-06-06
