
基于多样性感知图的测试用例优先排序
2019-06-27 06:02王曙燕张振豪孙家泽
西安邮电大学学报 2019年6期
王曙燕, 张振豪, 孙家泽
(西安邮电大学 计算机学院, 陕西 西安 710121)
回归测试属于软件测试的一种,用于确认程序或代码的更改并未对现有功能产生不利的影响。在软件维护过程中,回归测试需要重新执行访问程序的所有测试用例,将产生时间和资源等额外的花费。现有的解决方法主要包括测试用例约简技术、测试用例选择技术和测试用例优先排序(test case prioritization, TCP)技术[1]。测试用例约简和测试用例选择虽然可以加快回归测试过程,但是可能导致程序的某些语句无法正常执行,测试用例检测能力受到影响。而测试用例优先排序按照最大化某种既定的测试目标对现有的测试用例重新排序,确定其执行顺序,不会舍弃任何测试用例,对改进回归测试的效率和有效性具有重要意义[2]。
目前,测试用例优先排序算法主要包括贪婪算法和启发式算法[3]。贪婪算法是最常用的一种TCP技术[4-5],在求解优化问题时,总是选择满足当前覆盖能力最高的测试用例,从而希望结果最优。通过查找被修改函数与其他函数的关联关系,从初始数据中选择出回归测试数据集,并对测试用例先排序再选择,可有效地减少测试用例的数量,减低测试成本。但是,该算法是对因为系统修改受到影响的代码部分进行测试,仅考虑了函数调用之间的关联性,在执行大量与输出相关的语句时,也可能受到修改的影响[6]。使用测试用例输出的相关切片信息可识别影响输出结果的语句和分支覆盖信息,并依据切片中的覆盖需求确定测试用例优先序列,但是,该方法也仅考虑了对输出有影响的语句和分支[7]。
基于佳点集的新遗传算法[8]在测试用例优先排序过程中,考虑了遗传算法的收敛速度和稳定性的问题,利用数论中佳点集的特性,对遗传算法中的交叉操作进行改进,提高了收敛速度,避免了早熟,并使用了语句、方法和分支等3种覆盖速率的评价指标,更具代表性。但是,该算法稳定性差,依赖初始种群的选择。基于值的粒子群优先排序方法[9]考虑了6种优先级因子,并分配相应的优先级,通过实施复杂性、需求波动性和需求可塑性等影响因子的组合,进行优先级排序。但是,该方法对于影响因子需求有等级设置,具有不可复制性。
测试用例优先排序的标准包括代码覆盖率、代码复杂性和路径复杂性等[5,10]。以奖励多样性为目标,类似聚类分析从不同的簇中选择,使得测试用例更具多样化[11],意味着必须从那些与已经确定优先序列的测试用例集中,选择差异性最大的测试用例,并分配更高的优先序列。而且,测试用例本身具有很重要的信息,与覆盖信息之间也具有相关性,相似的测试用例具有相似的错误检测能力[12],因此,有必要关注测试用例之间的关联。本文通过考虑测试用例之间的关联性,将多样性感知图算法(diversity-aware graph algorithm,DAGA)应用于测试用例优先排序。基于语句覆盖标准,使用测试用例的多样性化对测试用例序列优化,以期提高测试用例排序的效率。
1 问题描述和技术标准
1.1 问题描述
测试用例优先排序问题[13]可描述为给定测试用例T,T的全排列集为P,排序目标函数f的定义域为P,值域为实数,需要解决的问题是寻找T′∈P,使得(∀T″∈P)(T″≠T′),满足f(T″)≥f(T′)。
1.2 语句覆盖矩阵
代码覆盖测试属于白盒测试的一种,在进行代码覆盖测试时,要求可以直接访问待测程序代码并查看测试用例运行时的代码覆盖信息。按照被测程序所作测试的粒子程度,可划分为语句覆盖、基本块覆盖、分支覆盖、路径覆盖和方法覆盖等5种覆盖标准[14]。程序代码的覆盖信息体现了测试用例的测试能力,收集测试用例的覆盖信息,在测试用例优先排序中借鉴聚类的一些策略,考虑不同测试用例间的关联性,可提高代码覆盖速率。
设待测程序P,测试用例集Ω={T1,T2,…,Tn},其中Ti(1≤i≤n)为测试用例集中第i个测试用例,使用eclemma工具[15]收集语句覆盖信息Aij,生成语句覆盖矩阵A。当Aij=1时,表示第i个测试用例执行中覆盖了第j条语句;当Aij=0时,表示第i个测试用例执行中未覆盖第j条语句。令P中有9条语句,测试用例集用Ω={T1,T2,T3,T4,T5},测试用例语句覆盖信息如表1所示。
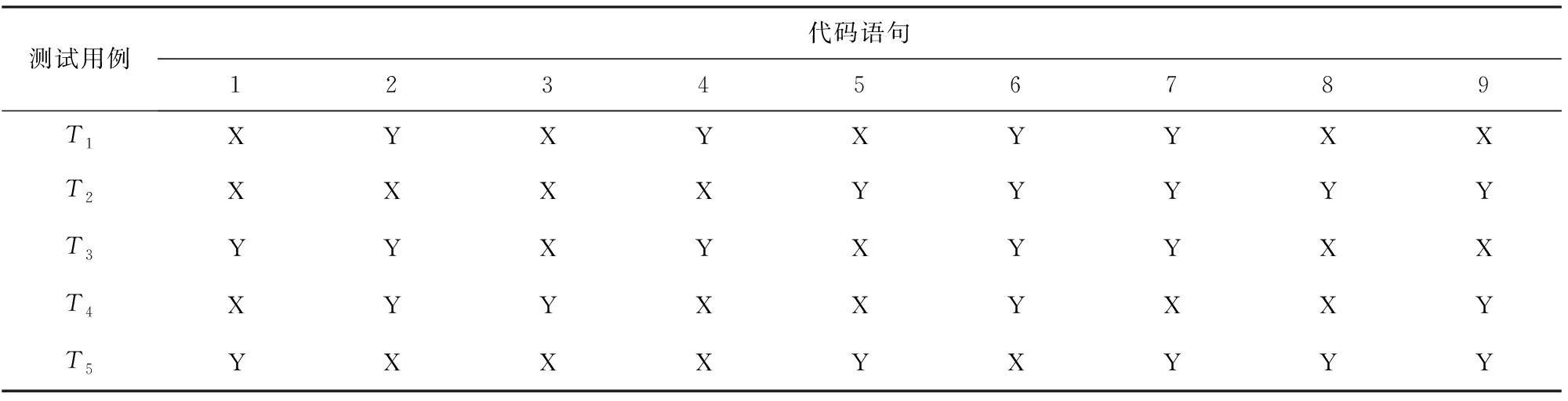
表1 测试用例覆盖信息
表1中X表示测试用例覆盖语句,Y表示测试用例未覆盖语句,则生成的语句覆盖矩阵可表示为

1.3 距离函数和测试用例相异矩阵
测试用例间具有关联性,使用杰卡德函数[15]计算不同测试用例间的多样性,可以扩大错误的检测率。给定测试用例Ti和Tj,每个测试用例有n个二进制属性,利用杰卡德函数度量测试用例Ti和Tj的重叠有用相似性[16],计算表达式为
(1)
其中:P11表示Ti和Tj的属性值都为1的总数;Q01表示Ti的属性值为0且Tj的属性值为1的总数;R10表示Ti的属性值为1和Tj的属性值为0的总数。
利用杰卡德距离度量测试用例Ti和Tj的相异性,计算表达式为
Jdist(Ti,Tj)=1-Jindex(Ti,Tj)。
(2)
令Sij=Jdist(Ti,Tj),1≤i≤n,1≤j≤n,则测试用例集Ω间的相异矩阵可表示为
(3)
2 多样性感知图的优先排序
基于多样性感知图算法进行测试用例排序时,先将测试用例优先排序问题转换成图的问题,通过转换测试用例为图的节点,转换测试用例相异信息为图的边,构建多样性感知图;然后遍历多样性感知图,实现对测试用例的排序。
2.1 多样性感知图的生成
为了映射测试用例优先排序到图,提取测试用例的某些特征并将其映射到图中,对节点和边增加额外功能,使用语句覆盖率和测试用例相异信息作为测试的指标,构建多样性感知图G。G属性信息包括节点和边,节点的标签为测试用例的编号,节点的值为语句覆盖率;由式(2)计算得出任意两个测试用例间的边的权值,利用式(3)生成相异矩阵M,即得到图G所有边的权值。
生成多样性感知图的具体步骤如下。
输入测试用例集Ω
输出多样性感知图G
步骤1将Ω中测试用例的编号作为图的标签值。
步骤2计算测试用例的语句覆盖率,并将其作为图的节点值。
步骤3通过式(2)计算任意两个测试用例之间的杰卡德距离,将其作为节点间的边权值,利用式(3)生成相异矩阵M。
步骤4以节点的标签和节点值作为节点信息,相异矩阵M为节点间边的信息生成多样性感知图G。
2.2 遍历多样性感知图
构建多样性感知图G后,遍历多样性感知图G找到更有价值的测试用例优先级。首先选择覆盖率最高的节点,移入已遍历的集合;然后选择具有最高增益值的节点S;最后使用递归算法计算剩余节点,直到遍历完所有节点。遍历多样性感知图算法具体步骤如下。
输入多样性感知图G
输出测试用例优先排序序列L
步骤1遍历多样性感知图G的所有节点选择节点值最大的值作为初始节点,并将其移入L中。
步骤2遍历G中剩余节点,计算剩余节点的节点值与剩余节点到L中节点边的权值之和并将最大值赋值给S。
步骤3将S中最大的节点移入L中。
步骤4若G不为空,返回步骤2重新执行;否则输出L。
2.3 多样性感知图的生成及遍历实例
图1为多样性感知图遍历算法示例。多样性感知由T1、T2、T3、T4、T5和T6等6个节点组成,每个节点值是由语句覆盖率计算得出,若总的可执行语句量是15,T3覆盖12条语句,该节点的值等于0.66(12/15)。边的权值由式(2)计算得出,式(1)可计算得出T1和T6之间相似性为0.5,T1和T2的边的权值为0.5(1-0.5)。使用多样性感知图算法,节点T6增益为最高值0.8,因此,遍历过程从这个节点开始。将T6移入已遍历集合L中,计算当前节点的增益值,与Ω中其他节点相比,节点T3增益为最高值1.66(0.66 + 1 = 1.66),因此,第二待选节点是T3。将T3及移入L中,删除边(T3,T5),重复此过程,直到算法遍历所有剩余的节点。最后L中存储路径为{T6,T3,T5,T4,T1,T2}。
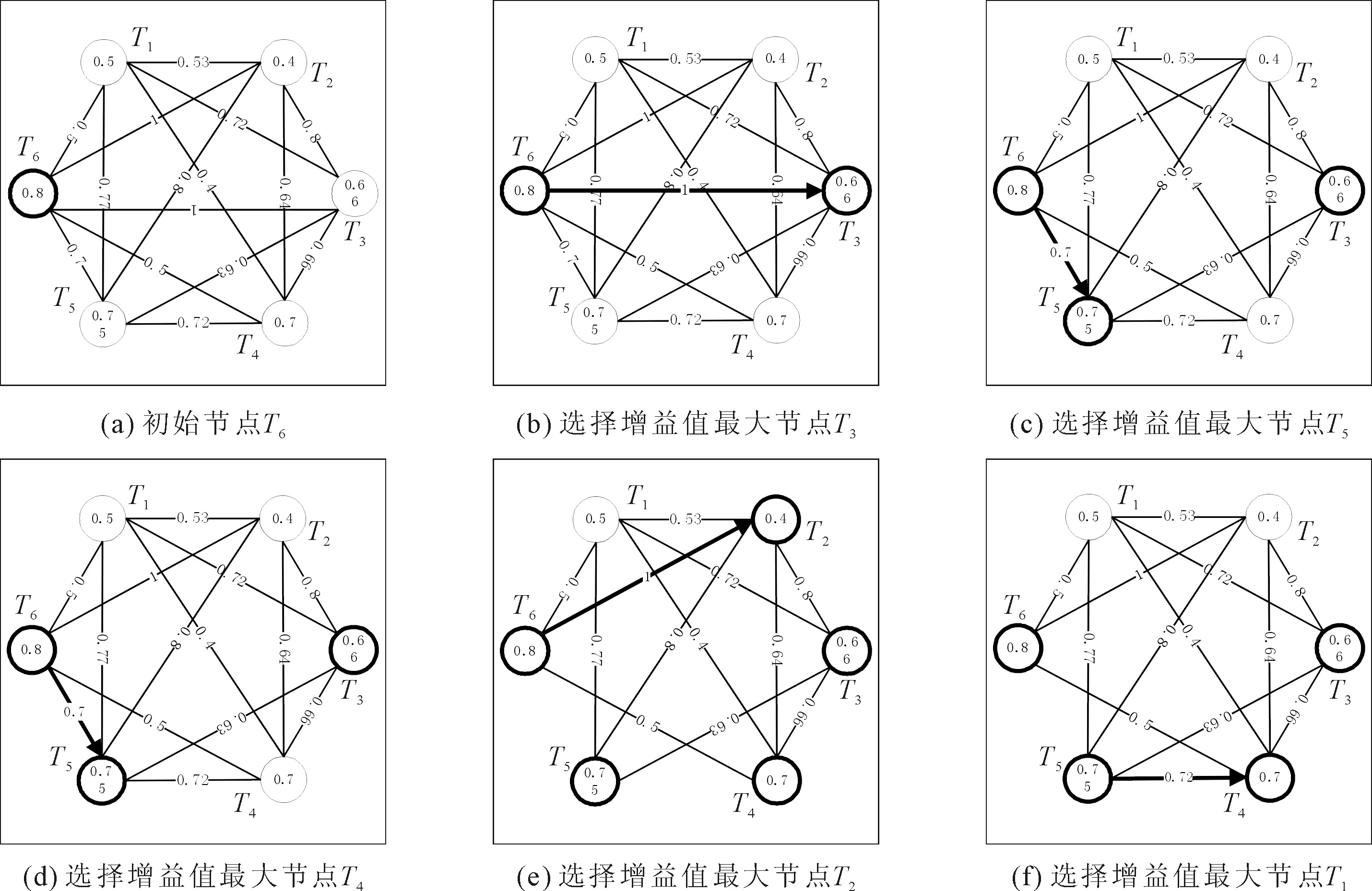
图1 多样性感知图遍历算法示例
3 实验结果及分析
实验环境为Intel Core 1.5 GHZ,4 GB内存Windows 764位,在集成开发环境Eclipse 4.5中运行,Java虚拟机版本号为jdk 1.8。
为了验证基于多样性感知图的测试用例优先排序的效率,选取jasmine 、apns 、jopt 和Scrib 等4个GitHub[17]上的程序作为回归测试数据集,分别对比多样性感知算法、贪婪算法、随机算法、顺序算法及逆序算法的平均语句覆盖(average percentage of statement coverage,APSC)[18]。数据集信息如表2所示。对每个待测试程序使用上述5种算法分别进行30次实验,平均结果如表3所示。

表2 数据集说明

表3 APSC实验结果
由表3中的APSC值可以看出,在4个数据集中,多样性感知算法都优于贪婪算法、随机等其他算法,在jasmine数据集中多样性感知算法效果明显;在apns数据集中,由于测试用例间的多样性区分度不高,多样性感知算法优于贪婪算法;jopt与Scribe数据集中由随机和顺序可知测试用例集较为稳定。因此,多样性感知算法在覆盖速率优于其他算法。
4 结语
考虑了测试用例的多样性及测试用例的覆盖能力,利用多样性感知图的算法求解测试用例优先排序,减少了盲目性的排序,提高了测试用例覆盖速率。实验结果表明,本文算法具有较快的覆盖速度,有效地提高了测试用例排序的效率。
猜你喜欢
科教导刊·电子版(2021年1期)2021-03-26
铁道通信信号(2020年6期)2020-09-21
新世纪智能(语文备考)(2020年4期)2020-07-25
商周刊(2018年25期)2019-01-08
传媒评论(2018年5期)2018-07-09
中国卫生(2016年12期)2016-11-23
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01
小学生·多元智能大王(2014年6期)2014-07-09
小说月刊(2014年12期)2014-04-19
空间控制技术与应用(2010年3期)2010-12-23
