
基于差异度量和互信息的文本特征选择算法
2019-06-27 04:21潘晓英赵逸喆
西安邮电大学学报 2019年6期
潘晓英, 陈 柳, 王 昊, 赵逸喆, 孙 俊
(1. 西安邮电大学 计算机学院, 陕西 西安710121;2. 西安邮电大学 陕西省网络数据分析与智能处理重点实验室, 陕西 西安 710121;3. 厦门优莱柏网络科技有限公司, 福建 厦门 361008)
文本分类技术[1]是处理文本信息的关键技术,已被广泛应用在垃圾邮件检测和电子邮件分类等日常生活中。在文本分类过程中,文档通常被建模为向量空间,每个词被视为特征。过多的特征不但会增加计算时间,而且会降低分类准确性。通过特征选择去除冗余特征,选择具有代表性的特征,可降低文本特征空间的高维度。
文本分类中主要的特征选择方法有过滤式、封装式和嵌入式。其中过滤式特征选择计算时间复杂度低、操作简便,应用较为广泛。利用改进的卡方检验(chi-square statistics,CHI)[2]和互信息结合的方法对特征集进行初步筛选,并载入MapReduce模型,可增加文本分类的准确度且缩短数据处理时间[3];CHI通过添加类内和类间分布因子,可降低低频词以及特征词对类间均匀分布的干扰[4];段落类别特征选择(feature selection paragraph category,FSPC)[5-6]将特征词的段落频率与特征词类别的分布程度进行融合,该度量标准能够描述特征词在文档中的均匀分布程度;CHI优化算法针对分布不均匀的特征数据集,适当改善了集中在少量文档中的单词的权重[7-8];基于文档频率的归一化差异度量 (normalized difference measure,NDM)通过对真正类率和假正类率之间的绝对差异与两者之间最小值的比值进行研究,优化了类别之间不平衡问题[9]。但是,上述方法均未考虑词频以及如何定义准确的特征。
针对忽略词频以及类别与特征词关系等问题,本文提出一种基于差异度量和互信息的文本特征选择算法。充分考虑文档频率、特征词频率、文档类别与特征词之间的关联度等方面,引入词频信息和特征分布系数,以期提高文本分类的准确率。
1 基本原理
1.1 归一化差异度量
NDM算法[9]通过使用真正类率rt和假正类率rf之间的绝对差异与两者之间最小值的比值表示特征词t排序的优先级。将rt和rf最小值引入算法中,不仅克服了数据集类别之间数据不平衡的问题且有效提高了分类的准确性。NDM算法表达式为
(1)
其中:A表示包含特征词t且属于正类的文档数;B表示不包含特征词t且属于正类的文档数;C表示包含特征词t且不属于正类的文档数;D表示不包含征词t且不属于正类的文档数。
NDM算法进行特征选择时,在考虑文档数量的同时引入类别信息,计算时间复杂度较低且操作简单,对理解数据方面也占有优势,但忽略了特征与类别之间的关联度。
1.2 互信息
互信息[10](mutual information,MI)在信息论中用于判断两个信号之间的相关性,在文本分类中作为特征选择算法,主要表示特征词和类别之间的相关程度。特征词t与文本类别c之间的关联度公式为
(2)
其中:P(c)表示属于类别c的文档占所有文档的概率;P(t)表示包含特征词t的文档占所有文档的频率;P(t,c)表示文档包含特征词t并且属于类别c的概率;P(t|c)表示文档在属于类别c的条件下包含特征词t的概率。
MI特征选择算法考虑了类内不同特征出现的频度,充分体现了特征对类别的表现能力,及文本类别与特征词的关联度。由式(2)可以看出,若特征词频率较低,则互信息明显偏高,倾向低频特征词,特征分类不准确。
2 文本特征提取算法的改进
NDM特征选择算法考虑了文档频率,但忽略了词频以及特征词和类别之间的关联度;MI特征选择算法考虑了文本类别与特征词的关联度,但倾向低频特征词,即特征词频率较低,则互信息偏高。因此,本文充分考虑文档频率、特征词频率、文档类别与特征词之间的关联以及准确的特征词只出现在固定类别等4个方面,提出一种基于差异度量和互信息文本特征选择算法 (normalized difference measure plus,NDMP)。融合归一化差异度量和互信息概念,引入词频信息和特征分布系数,对特征选择过程进一步优化。
设特征词为t,文档为d,文本类别为c,N为总类别数。词频信息和特征分布系数的计算表达式分别为
(3)
(4)
其中:ft(t,c)表示t在类别c出现的次数;fd(t,c)表示文档d包含t且属于类别c的文档数;fd(t)表示所有文档d包含t的文档数。若fd(t,c)接近fd(t),C趋近于1时,则说明特征词t对类别c表征效果较好,反之亦然。Ft适当地增加了高频特征所占的比重,C衡量了特征词在一个类别的权重。
在归一化度量NDM的基础上融合MI并增添词频信息和特征分布系数,得到改进的文本特征选择算法表达式为
DMNP=DMN×I(t,c)×Ft×C。
(5)
根据式(5)对特征词进行优先级排序,完成文本特征选择。通过引入Ft和C,特征词t对类别c表征效果越好,区分类别能力就越强。
NDMP算法具体步骤如下。
输入数据集Q,其中文档类别为c且c∈Q,文档中特征词为t且t∈c。
输出特征词优先级排序
步骤1判断数据集Q中是否包含特征词t及是否属于正类的文档数。
步骤2根据式(1)计算数据集Q的rt和rf,得出DMN,式(2)计算得出I(t,c)。
步骤3根据式(3)和式(4)分别计算词频信息Ft和特征分布系数C。
步骤4根据式(5)对特征词进行优先级排序,得到新的特征排名。
3 实验结果与分析
3.1 实验环境与语料库
实验环境为i5处理器、4G内存和Windows 10 64位操作系统,基于Python 3版本的Pycharm编译器。选用20 News-groups 语料库[11]作为实验数据集,并将数据集随机分为70%的训练集和30%的测试集,使用K折交叉[12]验证方法。
3.2 实验结果与分析
对数据集进行去除停用词、标点和词干化等操作。采用支持向量机和朴素贝叶斯对数据集进行分类,分别对比ACC2[13]、MI、NDM和NDMP等4种算法在不同特征维数下的分类效果,及精确度、召回率、准确率和F1分数等4种评价指标。分类效果分别如图1和图2所示;评价指标对比结果分别如表1和表2所示。
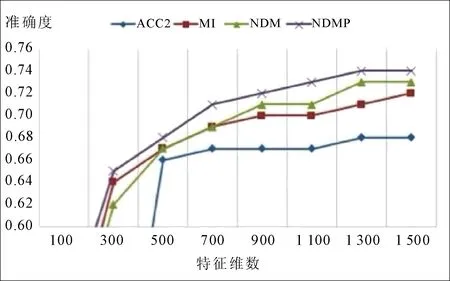
图1 不同特征维数下的支持向量机分类效果
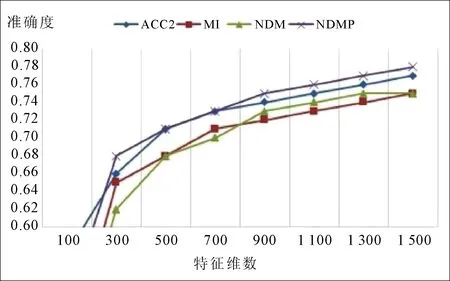
图2 不同特征维数下的朴素贝叶斯分类效果
由图1可以看出,使用支持向量机进行特征分类时,随着特征维数的增加,准确度也随之增加,且NDMP明显优于其他3种特征选择算法。由图2可以看出,使用朴素贝叶斯进行特征分类时,随着特征维数的增加,NDMP的准确率明显增加。当特征维数达到900时,NDMP准确度随之增加,但此时ACC2在降低;当特征维数达到1 500之后,分类准确率接近78%,说明NDMP方法更加稳定,综合性能更好。
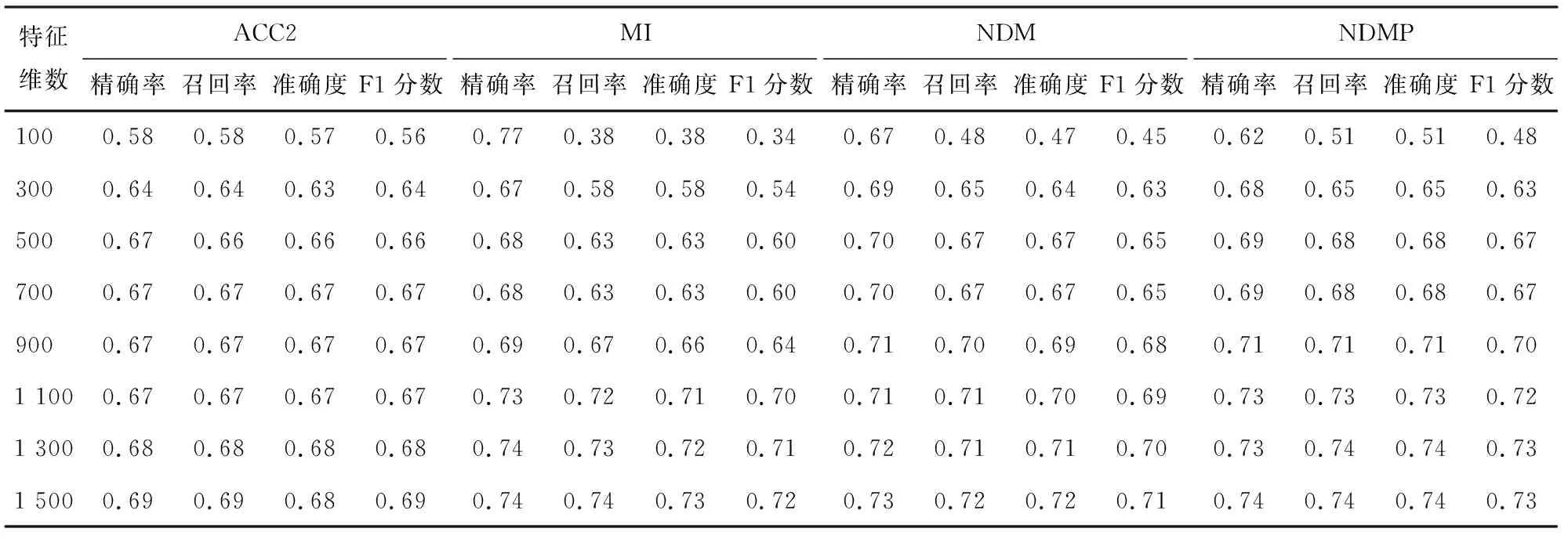
表1 4种算法评价指标对比(支持向量机)

表2 4种算法评价指标对比(朴素贝叶斯)
从表1和表2的结果可以看出,随着特征维数的变化,在不同分类器下NDMP在特征选择过程中精确度、召回率、准确率和F1分数,相比其他特征选择算法均有一定的提升。
4 结语
NDMP算法融合归一化差异度量和互信息,引入词频信息和特征分布系数,弥补了归一化差异度量在特征选择过程中忽略词频以及特征词和类别之间关系的不足,选择出了更多信息的特征,从而提高了分类器的性能。实验结果表明, 该算法提高了文本分类的准确率,且在特征选择相同的情况下,朴素贝叶斯训练出的分类准确率效果最显著。
猜你喜欢
计算机系统应用(2021年9期)2021-10-11
计算机技术与发展(2018年8期)2018-08-21
中国机械工程(2017年22期)2017-12-02
计算机应用(2016年10期)2017-05-12
中国修辞(2017年0期)2017-01-31
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
遥感信息(2015年3期)2015-12-13
读者·校园版(2015年7期)2015-05-14
中文信息学报(2015年4期)2015-04-21
弹箭与制导学报(2015年1期)2015-03-11
