
基于CNN和RNN的像素级视频目标跟踪算法
2019-06-26 10:14崔家梁冯朝晖李芹赵红颖
全球定位系统 2019年3期
崔家梁, 冯朝晖, 李芹, 赵红颖
(北京大学 地球与空间科学学院, 北京 100871)
0 引 言
目标跟踪是一项重要的视频处理功能.视频目标跟踪主要指计算机利用视频目标跟踪模型对视频中的目标进行持续定位的过程.视频目标跟踪算法主要包含初始化跟踪场景和后续跟踪两个过程.初始化即跟踪模型是根据一些初始信息启动整个跟踪的步骤.后续的跟踪是跟踪模型持续维持跟踪信息,并用跟踪信息和新的视频内容产生新的目标位置与新的跟踪信息的过程.
得益于基于光学的分辨率较高的视频传感器,理想的像素级目标跟踪算法从视频中提取到的结果的定位精度将远大于全球卫星导航系统(GNSS)获取的结果.结合视频目标跟踪与GNSS的定位方法将是解决定位精确度问题的重要途径.但由于视频处理硬件能力与算法的落后,现有的视觉目标跟踪算法很难直接工业化应用,算法优化研究迫在眉睫.
相比于图像目标检测识别、图像分类等图像处理应用,视频目标跟踪由于同时面临时间和空间纬度的大量数据,单位时间接受到的信息量极大,冗余度极高,处理起来显然更困难.目前的各种跟踪方式的研究一直在追求从大量、高维的信息中提取出最有效的少量信息.深度学习技术是目前最有希望解决这一点的途径.
视频跟踪算法可以根据获取跟踪目标的方式分为产生式模型和判别式模型.产生式模型基于前一段时间的目标状态,结合新加入的帧的视频内容,直接用预测模型产生一个新的跟踪目标.判别式模型先利用提取特征的方法,将新帧做图像特征提取运算,再结合提取出的特征和之前的跟踪结果,在提取出的特征中选择出要跟踪的目标.早期的跟踪模型[1-2]大多是产生式模型.当前阶段由于深度学习提取特征方面的优势,判别式模型较为占优.
目前主流的视频目标跟踪方法都是在解决矩形框跟踪问题,即最终的输出结果是目标的外包矩形,并不是目标本身的形状.像素级(Pixel-wise)的目标跟踪算法需要得到一副和原图同样大小的图片,并在像素级别区分目标与背景.图形处理领域已经完成过应用于图像分割的像素级算法研究[3-4].近年来像素级目标跟踪算法也有过研究,HUA等[5]在2006年的研究使用非深度学习的传统方法建模,尝试了像素级目标跟踪,由于传统方法的模型拟合度限制,使用了很复杂的模型也无法达到更好的普适性. SONG等[6]在2017年的研究使用深度学习的图像分割Conv-LSTM方法建立本地模型、实现了像素级的跟踪并得出了实验结果,但跟踪模型较简单,仅在单尺度下进行了卷积.且该模型需要借助预先训练好的图像分类模型才能实现,这种迁移学习会带来信息冗余与不稳定,不利于工业化.
本文将提出一种像素级目标跟踪算法.结合图像分割算法最新的研究成果与跟踪算法,本文提出的算法将把多尺度思想引入跟踪模型,获得理论创新,同时实现端到端的训练尝试,试图得到更接近工业化的结果.
1 基于CNN和RNN的像素级视频目标跟踪算法
1.1 模型概况与输入输出
本文提出的视频目标跟踪模型是一个结合卷积神经网络(CNN)和循环神经网络(RNN)的多尺度模型.其中CNN处理空间维度,RNN处理时间维度.CNN与RNN结合成CRNN单元进行时空处理,处理空间维度的CNN结构大致如图1所示.

图1 基于CNN和RNN的像素级跟踪模型的空间尺度处理
本模型的输入是视频,实际上是一帧帧图像组成的图像序列.本模型的输出是像素级的跟踪结果,即一帧帧黑白图像序列,高亮部分代表跟踪目标.由于使用了滤波方法处理图像,本模型会丢失一少部分图像边缘信息,得到结果的图幅会比输入小一些.
本模型在跟踪过程中需要用RNN结构保存并维护一定的跟踪信息,这些信息蕴含着跟踪目标一直以来的状态.后续的跟踪过程需要根据这些信息进行.
判别式模型由于需要依赖一个并非以最终的跟踪为目的目标生成阶段,其最终效果不得不依赖特征提取或目标检测等一些技术手段,实现方法将很复杂,效果也将打折扣.本模型试图尝试一种产生式跟踪方法,直接根据输入视频得到跟踪目标,避免过多中间步骤.
1.2 时间与空间维度的处理
单帧图片即空间维度的处理,本模型使用深度学习中处理图像的手段CNN.在CNN结构中,本文模型参考了图像分割的U-Net的做法[3],运用加密-解码思想.该思想为了得到最终与原图大小相同的图片设计了加密、解码阶段:在加密阶段,将‘CNN处理>降采样’的模块重复多次,每次处理后得到的信息更加宏观,细节更少.在解码阶段,将‘升采样,拼接>CNN处理’的模块重复和解码阶段相同的次数.其中升采样部分携带宏观信息,拼接部分携带微观信息,结合后得到综合宏观信息和微观信息的结果.另外,为了更好地获取与利用全局信息,本模型除了加密-解码结构还有一个CNN+LSTM&FC结构,直接用多级CNN提取特征以描述全局信息,具体结构如图2所示.

图2 CNN+LSTM&FC结构
本模型使用RNN处理时间维度,并存储跟踪信息.本模型使用的RNN结构是长短时记忆(LSTM)结构[7],该结构是使用基于遗忘设计的用于语义处理的结构,同样适用于视频目标跟踪.实际应用时根据效果也可尝试替换成GRU或普通RNN.不同于以往的先用CNN处理空间维度,再用RNN处理得到信息的跟踪模型,本文的RNN被插入了CNN的每个阶段.在加密-解码过程的每一个重复单元,CNN得到的结果都将进行RNN处理.即存在多个RNN,每个RNN处理加密-解码的某一个阶段,如小尺度加密的信息.浅层的RNN处理细节,并记录视频细节随时间的变化.深层的RNN与CNN+LSTM&FC处理宏观信息,记录整个视野的情况与变化.每个插入RNN的处理单元称为CRNN,用相同参数的RNN对图像每个像元进行处理.该插入结构是本模型实现多尺度理论突破的关键.
1.3 跟踪信息及其初始化
跟踪信息指在跟踪系统处理了一些帧后,其保留在系统内部的,将在处理接下来的帧的过程中用到的信息.跟踪信息的物理含义是跟踪目标与环境在这一时刻的状态.
主流的非深度学习的跟踪算法一般会规定一些跟踪信息的形式,如平移、仿射等.本模型的跟踪信息将完全存储在RNN的状态向量中.与传统研究不同的是,这样直接存储在RNN的状态向量中的存储方式不需要人为定义跟踪目标与环境所处状态,避免了人为考虑导致的稀疏表达问题.由于存在多级加密-解码结构,加密与解码中的每一级都将记录一个跟踪信息.这个跟踪信息的存在形式是一个多波段的图像,图像的大小跟级别深度成正比.在较深的层级,一个像素可能代表着之前很大的一片区域的信息.CONV-FC&LSTM结构的跟踪信息则代表最为全局的信息.
初始化是目标跟踪中的一个重要步骤,是跟踪模型根据一个初始的内容开启整个跟踪的过程.初始化将根据一些初始条件获取最初的跟踪信息.本模型跟踪信息的初始化使用第一帧图像和第一帧的标记作为输入,用一个静态的多层CNN进行算法处理.处理结构大致如图3所示.该网络的参数将在训练跟踪模型时通过联合训练得到.由于结构接近,这种初始化方法将适配后续的跟踪算法.
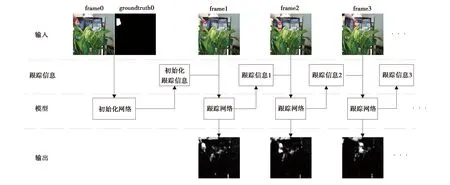
图3 时间维度的处理
1.4 跟踪结果的获取
1.1节中已介绍过,本模型的输出将是一系列黑白图像组成的视频,高亮区域代表目标.该结果实际是Sigmoid层[8]得到的(图1中有标识),该层将像素级的多波段卷积结果先线性组合成单波段结果,再用Sigmoid函数转化成(0,1)之间的结果.每个像素的结果代表该像素是目标的概率,实际跟踪应用中可以选择一个阈值,认为大于该阈值的区域是目标.后续的结果展示中,跟踪结果将以概率图的形式展示.
2 实验与结果
2.1 实验概况
本研究在设计出模型后,对所提出模型进行了实现与实验.整个实验过程包括数据准备、模型程序编写、模型训练、测试、结果评估.
2.2 数据及其预处理
本文使用VOT2016公开的像素级别跟踪数据集[9]作为训练、测试数据.VOT2016的像素级别数据包括60个视频序列,包括20 000多张图片组成的几个序列.实际使用过程中,由于本模型每次训练的序列较短,60个视频序列会被切成更多的序列使用.
本实验需要先对彩色图片进行归一化,将彩色图片三个波段的(0,255)范围内的输入值分别归一化到(0,1)的区间.本文使用的是直接线性拉伸归一化方法.本实验使用的训练与测试数据均需要进行目标标记.这里使用1和0分别标记目标区域和非目标区域.目标标记得到的二值标签视频将用于训练和测试.
为了保证实验效率,防止内存溢出,本实验实际执行时还将较大的图片进行降采样压缩.实际执行中将所有的图片分辨率压缩至128×128.
2.3 实验平台与程序
本实验在Tensorflow平台[10]上进行,使用Python语言作为主要编程语言.本实验的模型训练与评估主要在一台配置着24 GB内存,GTX1070图形处理器,英特尔i7中央处理器的普通笔记本电脑上进行.
2.4 模型初始化与训练
本实验使用随机正交初始化模型的参数.需要注意的是,将神经网络参数初始化为0会导致后续无法训练,而普通的随机初始化会导致训练效果不稳定.本文实验将神经网络参数中的w初始化到中心为0的正态分布后,将输入进行类似尺度的归一化以利于得到全局统一的梯度.本文提出的深度神经网络将使用Adam训练方法训练.实际上各种训练方法在表现上区别不大.本文使用GPU进行深度神经网络的训练.但由于本文使用的方法需要大量地将不同尺度图像进行拼接操作,GPU的提升并不明显.
本模型的训练目标是最小化得到的概率图与标记的对数损失.由于数据集中跟踪目标较小而背景较大,为防止数据严重偏斜导致的拟合失败,本实验取对数损失时在背景像素上乘了较小的权重,使所有背景和目标的权重基本相当.
本实验训练与评估过程中对数据的使用如图4所示,将数据切分为训练集与测试集,用相同的结构先训练,再测试.

图4 跟踪模型训练与评估
2.5 结果与评估
由于像素级的目标跟踪研究较少,对于跟踪结果的评估暂未形成统一、权威的指标.本实验采用了二分类问题的评价指标-AUC作为评价跟踪结果的指标.AUC的物理含义即模型认为一个正例(目标)比一个负例(背景)更像目标的概率.AUC是结合了精确率和准确率的一种评价指标,适合本实验这样的样本偏斜的二分类题.
经过实验测试,本算法在VOT2016数据集的各个数据序列上都实现了基本的跟踪.在某些数据序列,如bag数据序列,如图5所示,算法近乎完美地实现了像素级跟踪.但由于部分数据序列场景较复杂,如图6所示的tiger序列的预测AUC在80%左右,这意味着大约只有80%概率认为目标像素相比于背景更像目标.更多的序列预测统计结构如图7所示,总体上本模型还是实现了跟踪基本的形态.

图5 跟踪结果1: VOT2016的bag序列
3 结束语
本文提出了一种基于CNN和RNN 的像素级目标跟踪模型.为避免判别式模型的繁琐过程,我们直接采用了产生式模型思想.为了描述复杂的蕴含几何变化的跟踪信息,采用了深度学习向量表示法.为了获取多尺度跟踪结果,采用了加密、解码结构实现宏观、细节的处理.由于像素级别目标跟踪问题本身的难度,本实验得到的结果不是完美.相比于SONF等在2017年的研究,本研究提出的模型进一步探究了多尺度下Conv-LSTM的表现,并能进行端到端的训练,直接得到跟踪目标的概率图,为后续的像素级研究与应用提供了基础.
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
小学生学习指导(低年级)(2021年12期)2021-12-31
成都信息工程大学学报(2021年3期)2021-11-22
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
红领巾·萌芽(2019年8期)2019-08-27
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
小学生学习指导(低年级)(2018年11期)2018-12-03
CHIP新电脑(2016年3期)2016-03-10
