
数据驱动的人文社科研究困境与对策:基于微观数据层面的考量
2019-06-25 01:57是沁李阳
图书与情报 2019年1期
是沁 李阳

摘 要:文章从人文社科研究过程入手,分析了数据驱动的人文社科研究在数据获取、数据处理、数据共享各阶段存在的数据需求、数据隐私、数据质量、数据权益等问题。最后,从微观的数据层面,对数据驱动的人文社科研究提出了促进人文社科数据资源开放共享、构建多维度的人文社科研究数据管理与监督机制、加强人文社科研究人员的数据素养教育等3个方面的对策建议。
关键词:大数据;数据驱动;人文社科研究;应对策略
中图分类号:G250.2;C3 文献标识码:A DOI:10.11968/tsyqb.1003-6938.2019003
Abstract Clarifying the data problems faced by humanities and social sciences research under the big data environment is conducive to promoting the deep integration of big data and humanities and social sciences research. Starting from the research process of humanities and social sciences, this paper analyzes the problems such as data requirements, data privacy, data quality and data rights in data acquisition, data processing and data sharing of humanities and social sciences research. Then,targeted suggestions are put forward in three aspects: promoting the sharing of humanities and social sciences data resources, informing multiple-dimension data management and supervision mechanism of humanities and social sciences research, and strengthening data literacy education for humanities and social sciences researchers.
Key words big data; data driven; humanities and social sciences; coping strategy
大数据作为一种新的理念和技术,对现代生活产生了巨大影响,同时它作为一种新的科学图景,为不同学科发展带来了新的机遇[1]。在大数据时代,社会信息化和智能化程度有了前所未有的提升,技术环境也发生了巨大的变化,这些变化渗透到了人文社科研究的各个领域,推动了人文社科研究向数据驱动的“第四范式”转变。一方面,大数据使人文社科数据收集更加全面高效,社交媒体数据、传感器数据、社会管理数据等扩大了人文社科研究的数据规模,使研究成果更加科学化、精确化;另一方面,大数据为人文社科带来了新的研究方法,社会网络分析、数据挖掘、机器学习等使研究人员在开展研究时更加得心应手,为跨领域、跨学科研究提供了可能。
毫无疑问,大数据能够提升人文社科研究的质量,为人文社科研究带来新的活力,但近些年的研究表明,大数据带来的风险与挑战也是不容忽视的。如倪万和唐锡光[2]就大数据应用于社会科学研究的基础性问题展开研究,指出大数据环境下的社会科学研究存在“总体”与“样本”、“混杂”与“精确”、“相关”与“因果”四个方面的悖论;陈泓茹等[3]指出要警惕大数据融入人文社科研究的基本限度:其一,大数据改变了人文社科研究的存在形态,但从本质来说,精神世界是无法数据化的;其二,充分认识数据固然重要,但是要警惕数据崇拜;其三,大数据能提高人文社科研究的精确化程度,但是精确化并不等于科学化;米加宁等[4]指出第四范式驱动的社会科学研究需要关注大数据的技术伦理问题与以往社会科学传统价值的挖掘问题。
目前这些已有的研究在一定程度上揭示了大数据应用于社会科学研究的共性问题,但更倾向于宏观问题的描述,缺乏对大数据环境下人文社科研究中数据问题的细粒度分析。虽然有些学者已经提及了数据伦理、数据崇拜等问题,但并未对问题及其产生原因进行深入系统的分析。基于此,本研究对大数据环境下人文社科研究的数据问题进行多方面的综合考量,并有针对性地提出应对策略。
1 数据驱动的人文社科研究困境
大数据环境下人文社科研究的数据问题作为“元问题”,由一系列子问题共同构成人文社科研究数据问题的框架,这些子问题主要包括数据需求问题、数据隐私问题、数据质量问题、数据权益问题等。
1.1 数据需求问题
随着数据驱动的第四研究范式的兴起,数据的价值日益凸显,人文社科研究人员数据需求也发生了一系列的变化,主要表现为多元化的数据来源需求、多样化的数据类型需求、全方位的数据主题需求。首先,在数据密集型的科研环境下,人文社科研究人员不仅可以通过搜索引擎获取互联网大数据,还可以通过数据中心或者数据平台等专业数据库获取用于科学研究的大数据;其次,人文社科数据类型复杂多樣,数值型数据、文本、图片、视频等结构化、半结构化、非结构化数据都可以被嵌入到人文社科研究中,尤其像历史学、心理学、社会学等学科对非结构化数据的需求更为强烈;最后,人文社科各学科之间的融合与交汇不断加深,科学研究活动往往需要跨领域数据的支持,科研人员需要获取跨学科的数据以链接不同领域的知识点。
人文社科研究人员数据需求日益迫切,人文社科数据资源建设与管理的现状却不乐观。近年来,中国人民大学、复旦大学、武汉大学、《图书馆杂志》出版社等先后搭建了数据中心以支撑人文社科研究的发展。但是数据资源建设蓬勃兴起的同时,仍然存在资源分散、管理混乱、内容单一等问题:(1)国内人文社科数据平台功能相对单一,仅提供浏览、查询等服务,不支持机器的读取和原始下载。如中山大学社会科学调查中心规定数据知识产权划归数据原始持有机构所有,规定数据获取需要审核;(2)人文社科数据资源建设标准不统一,不利于数据互联互通。由于人文社科数据资源建设标准不完善,普遍缺乏数据读取和交互操作的数据接口,科研人员无法查看详细数据结构,更无法通过关联数据的方式相互共享链接[5]。目前,中国人民大学社会调查与数据中心、复旦大学社会科学中心等明确使用DDI元数据标准,而其他很多机构在人文社科数据标引规则、数据互操作、数据存储等方面尚需要进一步统一;(3)数据内容揭示不足,数据资源整合层次较浅。目前,一些人文社科数据资源平台能做到对数据或者数据集进行标引,但是缺乏对数据内容的深入标引,大多数平台不具备全面的高级检索功能,无法满足人文社科研究人员的数据多元化跨领域的数据需求。
1.2 数据隐私问题
大数据环境下人文社科研究可以通过社交软件、智能设备、网络日志、开放API等方式获取实时数据,对数据进行清洗、脱敏、匿名后通过社会网络分析、聚类分析、关联分析等方法揭示多源异构数据之间的相关关系、时间关系与空间关系,形成相关研究,但在这个过程中随时有可能造成个人隐私数据的侵犯。
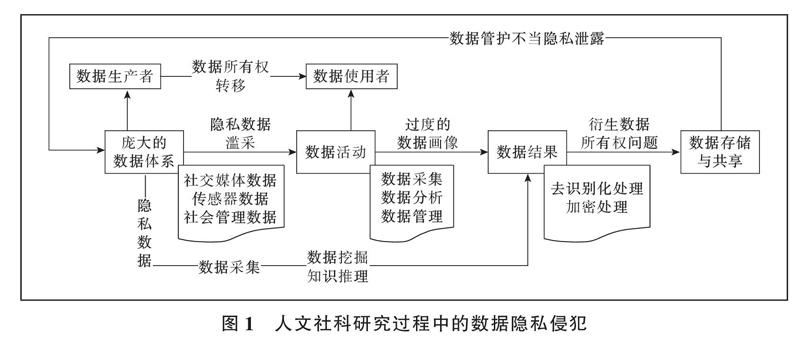
人文社科研究的数据类型包括用户生成内容(UGC)、空间位置数据与电子踪迹等,这些规模庞大且杂乱的数据中包含着个人识别信息、个人身份信息、个人偏好信息等隐私数据(见图1)。在数据采集阶段,这些隐私数据在用户毫不知情的情况下被获取,自此潜在威胁开始显露。政府网站、数据中心等开放平台的数据一般都通过去识别化处理将数据与其来源相剥离,通过爬虫获取的数据也会进行匿名处理,但是这些方法不是绝对安全的,多个数据集跨域互联之后,即使是已经匿名化的数据也会慢慢清晰。研究者通过数据挖掘和知识推理技术将毫无关联的数据进行加工与整合,将碎片化的静态单元信息通过时空组合形成网状化模块数据,不直接触及到隐私的信息经过科研人员叠加处理,可以轻易用数据画像还原个人生活全貌。Latanya Sweeney通过对去识别化的出生日期、性别、邮政编码信息、投票登记记录进行数据配比,从而重新确认州保险委员会发布的匿名化的健康记录信息[6]。在数据管护阶段,如果不能有效存储数据和合理开放数据,也会对个人隐私与数据安全造成巨大威胁。大数据时代科学数据不断增长,存储与传输系统处理这些科学数据需要坚实的组织与技术保障,并且需要通过相互协作来汇集不同来源的数据。然而,目前我国缺乏统一的数据管护平台,人文社科各数据管理中心的数据安全评估标准与数据安全防护机制也不完善,这些因素都可能成为隐私泄露的原因。
数据管理中心数据政策缺失是隐私侵犯的原因之一,其根本原因在于我国缺乏个人隐私保护相关法律对研究人员行为进行规范。从全球来看,联合国有113个成员国建立了数据保护法或其他等同法案。反观我国截至目前没有独立完整的数据保护法,相关规定分散在各种法律法规中。最新的《中华人民共和国网络安全法》新增了最少够用原则、个人信息共享条件等新规定[7],《最高人民法院、最高人民检察院关于办理侵犯公民个人信息刑事案件适用法律若干问题的解释》补充了《刑法》,明确了侵犯公民个人信息罪的定罪量刑标准、相关法律适用等内容[8]。但上述个人隐私保护的法律条款侧重对一般社会行为下的隐私侵犯行为的处罚,不足之处主要表现在:没有对科学研究中的隐私侵害行为进行界定,就目前国内的隐私保护条例而言,公民的隐私信息受法律保护,那么公民就有权利要求科研部门在避开个人隐私数据基础上开展研究,这是法律较难平衡和界定的部分。我国缺少对数据驱动的人文社科研究存在的问题进行底线约束,也未形成完善的道德規范体系进行预防。我国早在2009年就颁布《高校人文社会科学学术规范指南》,该指南涉及到了学术伦理、引用规范、学术评价规范等方面,然而随着时间的推移,该指南已经无法适应大数据环境下人文社科研究的新场景、新范式、新问题。
1.3 数据质量问题
大数据时代,数据生成与科学研究分离,加上数据的极度丰富与多维属性,研究人员因个人原因造成的“观念先行”“材料拼凑”“以偏概全”等问题被认为可以有效避免[9]。因此,有研究认为“大数据时代,人文社科研究从海量数据中获得的结论,相比通过传统抽样统计分析的结果更为准确”[10]。事实上,数据的生产与科学研究相互独立,不但未能有效排除影响因素,反而可能在一定程度上招致更多的干扰因素。各种外部环境干扰与人为干扰隐藏在数据生产到数据分析再到结果展示的各个阶段,持续影响着人文社科研究的数据质量。
首先,数据本身的真实性存在很大的疑问。如以互联网大数据为例,Twitter、新浪微博、知乎等互联网平台带有浓厚的商业色彩,这些平台不是以服务科学研究为目的而建立的,而是追求利润的商业平台,因此生成的数据在一定意义上可以被理解为是销售与消费行为交互作用的结果。在市场逻辑下,围绕信息生产、分配与交换形成一种“数据商业”,大量的人为操纵因素被注入到互联网大数据中[9]。如微博热搜、知乎问答、微博公众号等的阅读数都存在着大量水军操纵的痕迹。对于人文社科相关研究而言,这些“重新制作”的数据从商业用途转用于科学研究,如果研究人员不能对其进行有效甄别与剔除,数据有可能会存在偏差,最终导致研究结果出现错误。然而,对于虚假数据的识别与筛选仍然是目前研究人员有待解决的技术难题。
其次,即使生成的数据足够科学客观,但对数据的采集与处理同样是一个主观的操作过程。舍恩伯格认为大数据时代的数据一定是基于总体的,数据驱动的人文社科研究追求获得总体数据,但是在具体的研究往往与舍恩伯格的愿望相差甚远。人文社科研究对象的性质决定难以获得全体数据,在实际研究中能够通过数据量化的总体几乎不会出现,并且一旦追求大而全的数据样本,不可避免的会以牺牲数据源的甄选作为代价。另外,数据量的庞大和数据的多样性给科研人员数据处理带来了一定的挑战,但同时也赋予其更多的对数据进行选择的权利,这就意味着在数据处理的环节,很有可能出现随意取舍、组合数据,删除与期望不符的数据以获得研究结果的现象。如2014年12月,《科学》杂志刊登的题为“When contact changes minds: An experiment on transmission of support for gay equality”[11]的论文由于数据获取方式及验证性存疑,在政治社会科学领域引起关注并引发争论。最终,论文作者承认数据造假并于2015年5月正式向《科学》提出撤稿申请。
最后,即使经过处理的数据真实可靠,对数据进行分析时也难免掺杂研究人员的个人意志。一方面,从社会学角度看,所有的数据说到底都是关于“人”的符号,是一种具有社会文化意义的建构行动[12]。大数据环境下的人文社科研究执着于“客观数据”的解读,缺少对“主观数据”的反映,忽视了数据符号所蕴含的社会文化意义的挖掘;另一方面,人不是法律规范的机械执行者,社会行为必须结合其所发生的具体情境才能被更好地理解。然而,现实情况下人文学科的许多情境因素都未能被记录到大数据之中,而即使是那些被记录、被解读出来情境,也应当不断反思是数据本身的意义还是研究人员对数据意义的过度解读。
1.4 数据权益问题
当前数据驱动的研究范式下,科学数据已经成为一种必不可少的资源,只有实现更大范围的数据共享,才能推动人文社科研究的创新。保障科学数据权益是提高数据生产者共享积极性的关键,其既包括各利益主体的权益与义务的协调问题,也涉及到科学数据相关法律与政策文本是否完善的问题。
(1)数据获取阶段权益问题。随着大数据、物联网、数字中国建设推进,人文社科领域的研究资源逐渐从调查获取向感知获取转变,研究人员通过网络媒体系统、电子政务系统、电子商务系统等获取社交媒体数据、金融系统数据、用户隐私数据等[5],在这一过程中,数据生产者的数据所有权被研究人员获取。从数据收集的对象来看,其本身是数据的生产者,但是被直接剥夺了数据的所有权,进而也就失去了数据产生价值的收益权。“数据知情权”是数据搜集中被普遍认可的权利,但是在大数据环境下,知情同意的难度较以往大幅增加了。个体签署同意书通常在数据收集之前,而对信息的实际利用发生在其后。与小数据时代数据利用的目的相对确定不同,大数据时代数据处理具有频繁性,数据获取主体与使用目的常常难以预知。因此,即使数据是合法收集的,个体再也不知道他们的数据会被用来做什么。此外,考虑到时间与成本等因素,研究人员在数据获取之前也不可能一一履行告知义务。
(2)数据共享阶段权益问题。科学数据开放共享最核心的问题是“最大程度的利用数据”与“最大程度保护相关者的权益”之间的平衡问题。数据权利化是数据开放共享的现实需求,但是现行的法律与政策对知识产权、数据产权的规定甚少。科学数据的所有权尚未在制度层面予以明确,使得数据存储权、使用权、重用权等无法进一步厘清,给科学数据开放获取的实施增加了难度。另外,我国的人文社科数据管理平台没有对科学数据生产者作出明确的界定,对于数据使用者的权限规定也仅停留在网站的“政策说明”或者“网站申请”的层次。与自然科学领域的学术期刊相比,人文社科类学术期刊的数据政策尚不完善。如在图书情报领域,很多期刊并没有明确的数据管理政策,一些期刊如《数据分析与知识发现》和《图书馆杂志》要求作者在提交论文时上传支撑论文的研究数据,并且有相应的数据提交要求,然而这些要求仅涉及到数据格式、存储形式、提交方式等内容,并未对数据权属、数据引用等问题制定相关细则。科学数据汇交政策、保存与权限控制政策、科学数据重用等规定的模糊,会造成人文社会科学数据生产者、数据管理者与数据使用者权益分配的混乱。
2 推动大数据与人文社科研究深度融合的对策
2.1 促进人文社科数据资源开放共享
(1)构建一套完整的人文社科数据资源标准体系。首先,人文社科数据资源建设需要一套统一且规范的数据标准,包括数据资源建设机构的资质要求、数据库选型要求、数据资源筛选分类标准、数据清洗标准、数据资源组织标准、数据资源开放标准等;其次,需要加强薄弱环节建设,管理和评估标准是人文社科數据资源标准规范体系中的薄弱环节,重点建设评估规范、整合服务规范。人文社科数据类型复杂,不仅包括数值数据,还包括文本数据、档案数据、汇编数据和PDF格式等,根据不同形式的数据制定相应数据评估标准。
(2)搭建一站式人文社科数据开放平台。当前,国内许多人文社科特色数据库及人文社科数据中心普遍存在规模小、数据质量差、聚合程度低等问题,数据难以得到有效的应用。搭建功能齐全、资源丰富、质量保障的人文社科研究数据聚合与一站式服务平台势在必行。①实现数据的有效组织,建立数据共建、共用、共享的开放系统,明确统一的数据开放端口,并根据数据主题、机构、学科等对数据进行分类,实现人文社科资源平台互联互通的同时保障数据的一致性;②完善数据开放服务功能,以大数据环境下研究人员数据需求为中心,增设交互功能,实现一站式服务。人文社科数据资源开放平台应具备数据存储、管理、浏览、检索、关联查找、互动与反馈评价功能。
2.2 构建多维度的人文社科研究数据管理与监督机制
数据驱动的人文社科研究数据管理与监督机制构建的关键在于两个方面:其一针对人文社科研究中存在的数据问题制定相应的法律、政策和规范性文件;其二构建大数据环境下人文社科研究管理与监督共同体,明确多个参与主体职责(见图2)。
(1)由政府机关完善数据所有权相关法律。大数据环境下的人文社科研究在数据收集、数据处理、数据开放共享过程中都不可避免的涉及到数据隐私问题、数据权益与责任的界定问题、法律执行等操作性问题。因此,国家应该在法律层面就大数据技术的伦理问题,尽快完善全方位保护数据所有权的立法。一方面将数据所有权纳入到知识产权体系中,规定具体的权利内容与对应的义务;另一方面借鉴《数据时代知识发现海牙宣言》[13]原则中与数据挖掘相关的三大原则(知识产权与促进研究相一致原则、合同许可条款不得限制个人使用原则、知识产权法不限制基于数据和思想的创新与研究原则),对知识产权侵权行为归责原则进行补充,保护数据主体的权益、规范数据使用行为、规避知识产权风险。
(2)教育部社会科学委员会学风建设委员会在考虑新技术产生的社会性与伦理性影响基础之上,重新修订《高校人文社会科学学术规范指南》。高校、科研机构等可以考虑增设专门的“研究规范指导委员会”和“学术道德问题咨询委员会”,将大数据环境下的数据伦理要求与项目申请、项目审批挂钩,严格规范人文社科研究人员的学术行为。另外,积极为人文社科研究人员提供系统的科研规范教育和学术道德问题咨询服务,通过正向引导与教育,强化科研人员的道德意识,促进道德内化。
猜你喜欢
科技创新与应用(2016年34期)2016-12-23
青春岁月(2016年20期)2016-12-21
科技视界(2016年26期)2016-12-17
新闻前哨(2016年10期)2016-10-31
中国市场(2016年33期)2016-10-18
中国市场(2016年33期)2016-10-18
科技视界(2016年20期)2016-09-29
科技视界(2016年1期)2016-03-30
