
基于深层卷积神经网络的智能导盲终端设计与应用
2019-06-25 09:44彭琳钰刘宇红马治楠戴晨亮
贵州大学学报(自然科学版) 2019年3期
彭琳钰,刘宇红,马治楠,戴晨亮
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
据英国《The Lancet Global Health》刊载的一篇研究报告显示:到2050年,全球失明病例将从3600万增加到1.15亿。中国是世界上视力障碍人数最多的国家之一,2016年底视力障碍人数统计约1731万人,其中盲人占500多万,每年约新增盲人45万,低视力者135万。盲人作为视听障碍群体,信息接收上的障碍严重影响了其生活、社交。
目前,盲人普遍采用手杖或导盲犬的传统导盲方式,而普通手杖探测范围较窄,导盲犬训练不易,成本较高。近年也出现了许多对于新型导盲设备的研究。曾婧婧等[1]将能力风暴机器人设计为机器导盲犬,机器人装置有碰撞、红外等传感器,通过控制机器导盲犬的行动来实现导盲,但该机器人控制不便,且不利于在复杂环境中使用(例如台阶、水坑等)。方仁杰等[2]设计了一种基于GPS与超声波的导盲手杖,用超声波技术探测障碍,但该手杖仅能探测正前方的路况,检测盲区较大。朱爱斌等[3]研究了一种可穿戴式的导盲机器人,由上下身皆装置超声波模块的两部分组成,其中还结合了双目、红外测距功能,但该设计仅能探测障碍物的距离,且穿戴繁琐、功耗较大,不便携带。
上述导盲方式均不能使盲人拥有直观的“视觉”体验,针对已有导盲技术存在的问题,本文设计了一种基于深层卷积神经网络[4]的智能导盲终端,旨在帮助盲人群体在外出过程中准确、安全地对障碍物进行“认知”避让,该系统功能使用稳定,设计人性化,具有开阔的市场前景。
1 导盲终端的总体系统设计
导盲终端的控制系统主要由两个主从控制的中央处理器构成。系统以Cortex-A9架构的I.MX6Q处理器为主控制模块,负责控制各硬件模块,并与从处理器进行交互。以Cortex-A53架构的Raspberry PI 3 Model B为从处理器,作为深层神经网络专用处理器,利用其GPU加速以提高计算效率。两个处理器皆搭载Linux系统,通过数据总线,以一个三态缓冲器控制存储单元的读写,当读写控制线处于低电位时,主控制器向从控制器的存储器里写入;处于高电位时,则由主控制器读出;无需传输时,端口处于高阻态。
主控制器搭建双目图像采集、4G通信、GPS定位系统、语音播报、报警等核心功能模块,以保证导盲终端功能的完整性及实用性。为了协调各功能,系统主控制器采用多线程处理,终端由五个触发按键切换控制,按键功能分别为:识别障碍物、标志并测距;识别场景;GPS定位并播报;传送求助报警信息和时间播报。这种主从结构的中央处理器并行计算方式,可直接在前端搭建深度学习[5]框架及双目测距算法,并协同其他功能模块完成导盲任务,大大减少了系统反应时间,提高了实时性。此外,针对盲人的监护者,本系统设计了对应的APP,通过APP,监护人不仅能够实时查看盲人的位置,还能够接收到盲人的求助信息。系统的总体设计框图如图1所示。

图1 系统的总体设计框图Fig.1 Overall design block diagram of the system
2 导盲终端硬件模块设计概况
2.1 图像采集模块
图像采集模块采用两个300万像素的Logitech C270高清摄像头,固定摄像头使其视轴平行且角度一致以便于定标。该模块主要用于采集当前环境信息及目标的深度信息。
2.2 4G通信模块
本文采用4G通信技术,主要供搭载的Linux系统联网校时,以及前端与移动客户端之间的通信。一方面通过4G网络将GPS模块获取的经纬度信息发送至移动客户端,再调用百度API接口进行经纬度解析和定位显示。另一方面,当盲人遇到困难需要紧急联系家人时,由4G网络向移动客户端发送警报信息。系统选用SIM7100C作为通信模块。
2.3 GPS模块
GPS系统能在全球范围内进行全天候、高效率、高精度的实时定位[6]。本系统采用的GPS型号为U-blox公司的NEO-7N,定位精度最高能达2.5 m。
2.4 智能语音模块
智能语音模块的合成芯片采用SYN6658,该模块的系统结构如图2所示。主控制器与SYN6658通过UART或SPI接口连接,向语音芯片发送控制命令和识别文本,经过切分词汇等处理,SYN6658将文本合成为语音输出,通过功放和喇叭播报结果。该模块主要用于播报障碍物和标志的距离、种类及方位,并根据需求播报所处场景、定位和时间,以引导盲人安全出行。
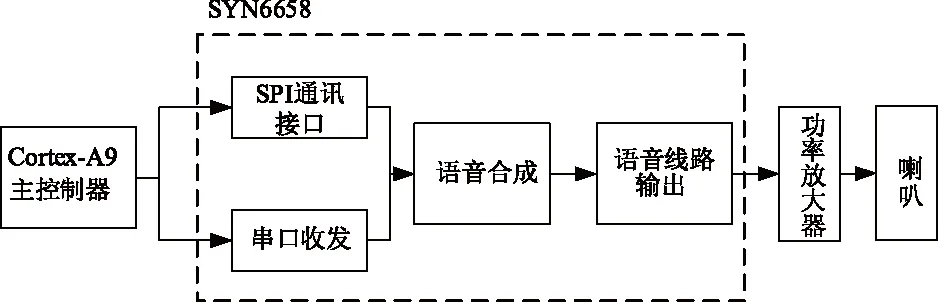
图2 语音合成模块的系统结构图Fig.2 System structure diagram of speech synthesis module
3 导盲终端的系统软件设计
智能导盲终端的系统软件设计主要包括:主控制模块,负责调度和控制整个系统的数据传输、运行流程;图像采集模块,负责采集当前环境的图像信息,图片采集频率为2帧/s;计算模块,采用C++/Python等编程语言实现双目测距算法及深度学习算法;语音播报模块,负责把识别的结果、实时定位信息、当前时间等播报出来;定位模块,负责获取使用者所在经纬度信息,对于终端,通过IPC传输给解析程序,解析程序使用Qt的WebBrowser加载解析程序,再调用百度地图API接口完成位置纠偏和解析;对于监护者,在手机端直接解析后显示定位。图3是导盲终端的软件设计图。
4 深层卷积神经网络
4.1 卷积神经网络的基本框架
人类大脑的活动是神经元之间的彼此联系,深度学习模仿人脑的神经元之间传递和处理信息的方式,不断增加网络隐藏层层数和神经元数目,以一种类似人脑分层模型的结构,从输入的数据中学习隐含的高层表示[7]。图4为一个典型的多隐藏层卷积神经网络模型。
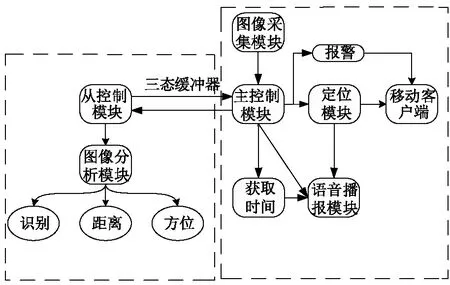
图3 导盲终端的软件设计图Fig.3 Software design diagram of the guide terminal

图4 卷积神经网络典型网络结构Fig.4 Convolutional neural network typical network structure
深度学习中的卷积神经网络(CNN)是计算机视觉领域最流行、广泛的一种算法,其基本架构为:局部互联,共享权重,池化,多层卷积[8]。网络初始主要由卷积层和下采样层组成,卷积层检测前一层的局部连接特征后,下采样层进行局部平均,降低表示维度,这种结构在整个网络中多次交替分布,再接入更多的卷积层或全连接层。卷积神经网络具有内存占用小,参数量小,泛化能力强,计算速度快及训练简单等优点[9]。
4.2 基于深层卷积神经网络的设计与实验
4.2.1数据集介绍
本文的智能导盲系统有常见障碍物、交通/警示标志、场景共三大类图像识别对象。其中常见障碍物采用改进的Pascal VOC数据集,在原始的Pascal VOC数据集中共有自行车、小汽车等20类。场景集采用改进的NUS-WIDE-SCENE数据集,原始的NUS数据集数据质量高,但每类数据数目不均且杂乱。为了增加系统的实用性,结合日常实际情况,本文对Pascal VOC数据集进行改进,新增减速带、斑马线、台阶、树、路灯、门、电梯等共40类常见障碍物数据,对NUS-WIDE-SCENE也进行了整理和扩充,分为办公室、超市、建筑群、草地/草坪、海/湖/河流、马路、人群共七大场景。另外,为了使盲人在出行中更安全便捷,本文对国内常见的交通/警告标志、男/女洗手间等共30类标志进行了训练。上述数据集中训练集为6000张/类,测试集为4000张/类。
训练样本数据前,图像统一缩减为224*224的彩色图像,由于数据量规模较小,故采用仿射变换法、平移变换法及模糊处理进行数据增强,以防训练陷入过拟合。
4.2.2网络结构设计
对比测试了AlexNet[10]、VGG[11]等常见深度学习模型后,选用ILSVRC2015比赛中获得冠军的ResNet[12]为基础网络结构,该模型一共有152层之深,主要结构为多层堆叠的残差学习单元,通过学习输入、输出的差别来简化学习目标和难度,这种结构能优化训练速度和识别效果,解决退化问题。
本文所用模型设计为46层,主要结构如下:输入层,主要加载数据集,载入的数据向量为 [32,3,224,224],此处32为批处理量(batch size),即一次读取32张3维的图片。卷积层,主要从图片中学习隐含的特征,第一个卷积层的卷积核大小为7*7,stride设为2,pad设为3。之后的残差层采用3层的残差网络结构,为了缓解由网络较深引起的梯度消失现象,以1*1-3*3-1*1大小的卷积核交替搭建,如图5所示,stride依据具体情况设为:1~2,pad设为:0~1,使用ReLU激活函数提高网络收敛速度。池化层,用于扩大感受野,对卷积层输出的特征图做聚合统计,本模型中一共2层,第一层紧跟在首层卷积层后面,采用最大值下采样法,下采样窗口尺寸设为3*3,stride为2,对每个不重叠的3*3的区域进行降采样,减少参数量。第二层后接全连接层,采用平均池化法,下采样窗口尺寸为7*7,stride设为1。整个网络随着层数加深,抽取的特征也由边缘信息提升为高层表示。最后输入一个神经元数量为40(以障碍物数据集为例)的全连接层,通过SoftmaxWithLoss层计算测试样本分别在40个类别上的概率,SoftmaxWithLoss层实际上包含交叉熵代价函数及Softmax分类器,Softmax分类器常用于解决多分类问题,对于给定的输入M,可以得到n分类的概率,公式如下,此处n=40:
(1)

图5 三层残差网络结构图Fig.5 Three-layer residual network structure
4.2.3实验工具及训练机制
本文模型训练所使用的实验工具参数如表1所示,训练耗时总计约7小时40分钟。

表1 实验工具参数Tab.1 Experimental tool parameters
采用监督训练的方式,将初始阶段学习率设置为0.01,学习策略采用multistep模式,从底层逐层地向顶层训练,分别获取各层参数,再由此进一步调整整个模型的参数,通过带标签的数据去训练。在训练迭代300000次后,用序列化存储学习到的权值对网络进行微调,以增强模型的泛化性和鲁棒性。
5 实验测试及结果分析
5.1 模型及系统性能测试
本文训练的模型准确率如图6所示,训练及测试时的loss变化如图7所示。为检验模型性能,在Pascal VOC数据集上对各类主流方法进行了横向比较,训练迭代50000次,对比结果如图8所示。由于人在行进状态中,摄像头采集的图像存在模糊、变形的情况,为验证模型的鲁棒性及实时性,随机加入了经压缩、旋转、加噪等方式处理的图像数据进行系统实测,FPS测试为12帧/s。本文采用SGBM算法进行测距,使用OpenCV对两个参数一致的摄像头进行标定和立体校正,然后从不同视点图中进行特征匹配,生成包含距离信息的深度图,在树莓派上的系统运行可视化如图9所示。
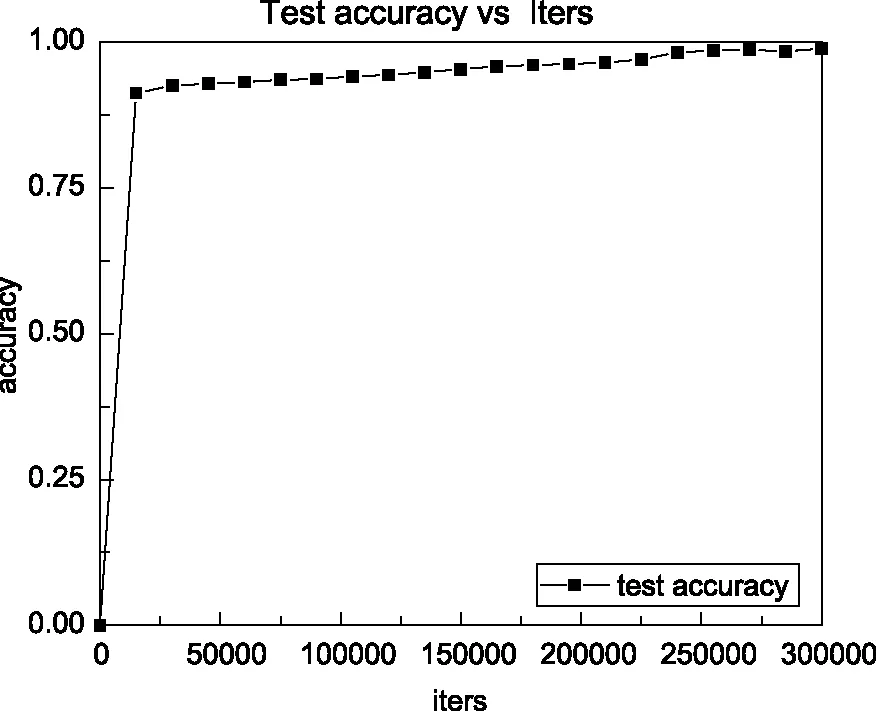
图6 本文模型的准确率Fig.6 Accuracy of the model
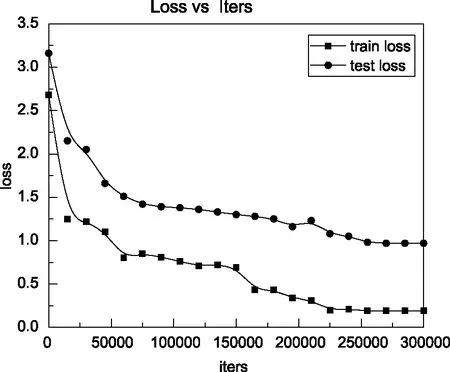
图7 训练和测试时的loss变化Fig.7 Loss changes during training and testing

图8 在Pascal VOC数据集上与其他算法的准确率比较Fig.8 Comparison of accuracy with other algorithms on Pascal VOC datasets

图9 系统识别与测距结果Fig.9 System identification and ranging results
本文针对7个类测试模型的准确率,准确率详细情况如表2所示。

表2 系统实测的准确率Tab.2 The measured accuracy of the system
上述实验证明,采用主从并行计算的处理方式,不仅能实现将深度学习框架移植在硬件上,还有效提高了系统运行效率。采用预训练与迁移学习结合的深层卷积神经网络训练策略,模型的平均准确率为98.77%,与传统的机器学习算法相比,提高了近30%,而且训练速度更快,避免了训练出现过拟合的现象。
5.2 导盲终端APP功能测试
针对盲人监护者需求,结合导盲终端GPS及报警功能进行系统调试。为安全起见,每个终端对应一个账户,以防信息泄露。用户登录移动客户端后可跟踪使用者的位置。当在终端按下报警求助按键时,手机在数秒内即通过振动/响铃的方式提示并输出信息。实验证明,监护者能通过登录APP,随时定位盲人的位置,为盲人的安全出行提供了多重保护。
6 结语
本文所设计的基于深层卷积神经网络的导盲终端,以主从并行计算的结构,将系统主控制模块与计算模块配置在两个独立的处理器上,并协同图像采集、GPS定位、报警报时、语音播报、无线通讯模块,完成了导盲终端的软、硬件设计。经系统实测,训练的模型能顺利移植到前端硬件上,实现了深度学习框架在硬件上的移植,控制器并行处理的结构提高了实时运行效率。该智能导盲终端不仅能对室外常见障碍物、标志、场景做出较为准确的识别,且各功能切换流畅。供监护者使用的移动客户端定位实时精确,人性化的设计使盲人的出行更加便捷。该设计能给盲人朋友带来直观的“视觉”福音,使其生活更加便捷,在科技高速发展的今天,对于较大基数的盲人群体来说显得尤为迫切,也具有一定的社会意义。
贵州大学学报(自然科学版)2019年3期