
带重现概念漂移的不平衡数据流分类研究
2019-06-25 09:49:10季梦遥
贵州大学学报(自然科学版) 2019年3期
季梦遥,袁 磊
(1.武汉大学人民医院 消化内科, 湖北 武汉 430000;2.武汉大学人民医院 信息中心,湖北 武汉 4300002)
数据随着时间延续而无限地、快速地、有序地动态增长称之为数据流。目前数据流广泛存在于现实世界的多个应用场景,如气象测控[1]、网络监控[2]、故障检测[3]等。数据流分为稳定数据流和动态数据流,稳定数据流是指数据分布或数据概念不随时间的推移而变化,动态数据流是指数据分布或数据概念随时间的推移而变化,此类数据分布或概念变化即为概念漂移。例如,在网络购物记录数据流分析中,顾客的购物行为会因为隐含的或不可预知的因素(如,爱国情愫、身份变更等)而发生根本性的概念变化。重现概念漂移(recurring concepts)是概念漂移的一种重要表现形式,它区别于突变式概念漂移和渐变式概念漂移的重点在数据概念之前出现在数据流中,但随着时间推移该数据概念又重新再现。例如,天气变化会随时间的推移出现相同的气候现象、顾客的购买行为会随着季节的变化出现类似的购买行为等。然而,目前处理概念漂移的多数研究工作,大部分将重现概念漂移视为新概念,很少考虑重现概念漂移,因此在处理带重现概念漂移的数据流时会导致分类器对概念漂移反应迟钝、学习时间过长等问题。
隐含重现概念漂移的不平衡数据流是带重现概念漂移数据流的复杂情况,是指数据流中数据分布存在不平衡性或失衡性,即数据流中某一类或多类数据的样本数目明显大于其他类的现象。样本数目明显偏多的类称之为多数类,样本数目明显偏少的类称之为少数类,少数类往往具有更高的价值。例如,在网络监测数据中,正常的网络数据样本数目(多数类)要远远大于异常的网络数据(少数类),而异常数据往往具有更高的价值。目前,关于数据流的分类研究有很多,但大多数数据流分类器多基于数据分布是平衡分布的。数据分布的不平衡性会使分类器的训练结果向多数类倾斜,严重影响分类器的分类性能。例如,在网络监测数据中,多数类数据占整个样本的99.5%,少数类样本占整个样本的0.5%,训练所得的分类器对整体分类准确率达99.5%,但是对少数类的分类准确率却十分低。带重现概念漂移的不平衡数据流同时具有重现概念漂移和数据分布不平衡的双重特征,如何有效地处理数据流的这两种特征使训练所得的分类器同时具备快速检测重现概念漂移和克服数据分布不平衡是本文的研究重点。
概念漂移在被提出之后,得到了学术界的重视并涌现出大量的研究成果。目前,隐含概念漂移数据流的分类研究工作可分为单分类器模式和集成分类器模式。例如,KATAKIS等[4]提出采用增长式特征分类器来评估特征的价值用于检测概念漂移。SOARES等[5]提出了一种全新的在线集成学习拟合模型,该模型利用OA技术检测概念漂移。带概念漂移的不平衡数据流是指带概念漂移数据流中隐含着数据分布不平衡的特性,如某一类样本数目远远大于其他类的样本数目。概念漂移或数据分布不平衡都会影响分类器的性能,当概念漂移和数据分布共存时会对数据流分类研究带来具大挑战。例如,传统的用于处理概念漂移的分类器可能会对数据分布不平衡度不敏感,从而导致性能下降,这种性能下降在有价值的少数类分类上更加凸显。用于处理不平衡数据流的分类模型,可能会因为对概念漂移敏感度差而导致分类器过时或失效。目前,一些学者逐渐开始关注带概念漂移不平衡数据流的分类研究。例如,DITZLER and ELWELL等[6-7]提出了Learn++.NIE(learning in nonstationary and imbalanced environments)和Learn++.CDS(combination of Learn++.NSE and SMOTE)算法用于处理带概念漂移不平衡数据流的分类问题,该算法是Learn++.NSE(learn in nonstationary environments)算法[8]的扩展。其中Learn++.CDS算法本质上是Learn++.NSE与SMOTE采样算法的结合。类似的研究还有诸如SEA算法[9]、SEAR算法[10]、REA算法[11]、UCB算法[12]等。然而,多数研究在处理带概念漂移不平衡数据流时,未考虑重现概念漂移,而将重现概念漂移视为新的概念,因此不具备探测重现概念漂移的能力,从而导致错误报警率提升、计算资源和人力资源浪费。基于上述原因,本文提出了用于处理带重现概念漂移的不平衡数据流分类算法(Random Balanced Sampling Recurring-concepts Imbalanced Streaming Ensemble Algorithm, RBSRISEA)。
1 算法描述
1.1 随机平衡采样算法
不平衡数据的存在会使传统的分类器性能偏离价值更高的少数类,而偏向价值较低的多数类,从而导致分类器失效。针对上述问题,本文提出了一种数据再平衡算法,随机平衡采样算法(Random Balance Sampling,RBS算法)。RBS算法本质是一种数据预处理再平衡算法,它通过随机的改变数据集中的少数类或多数类的比例,而不改变原来数据集的数据分布。这种随机再平衡技术不再是单纯的加入少数类或者减少多数类样本数,而是根据原数据分布改变少数类或多数类的比例生成新数据集用于训练分类器,从理论上保证了集成子分类器的多样性,理论分析详见后续,RBS算法如下所示。
输入:原数据集S={(x1,y1),(x2,y2),…,
(xm,ym)}/,yi∈Y={-1,+1},xi∈X∈Rn
输出:新的数据集S′
1.totalSize←|S|SN←{(xi,yi)∈S|yi=-1}
SP←{(xi,yi)∈S|yi=+1}
2.majoritySize←|SN|minoritySize←|SP|
3.newMajoritySize←[2,totalSize-2]之间的随意整数
//随机产生多数类;
4.newMinoritySize←totalSize-newMajoritySize
//随机产生少数类;
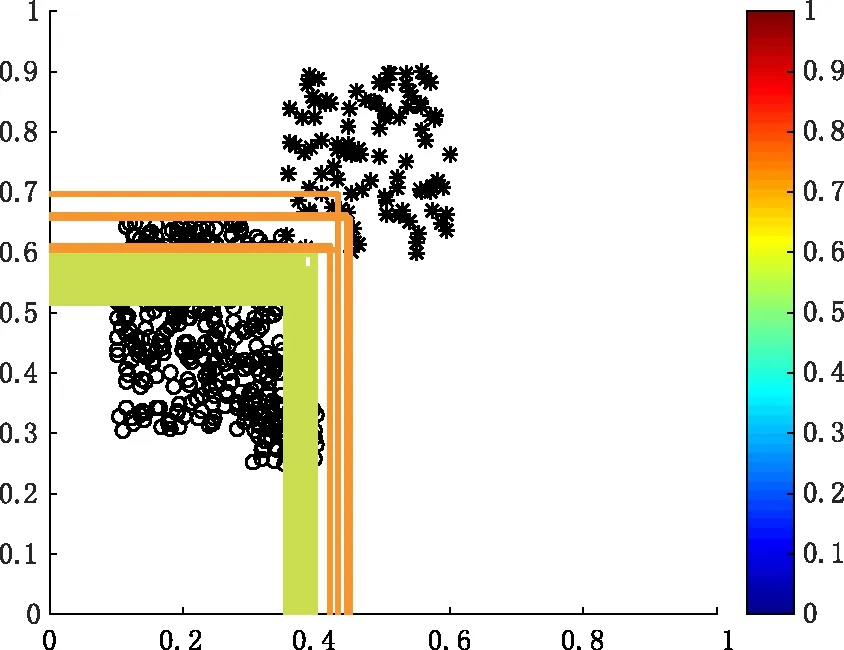
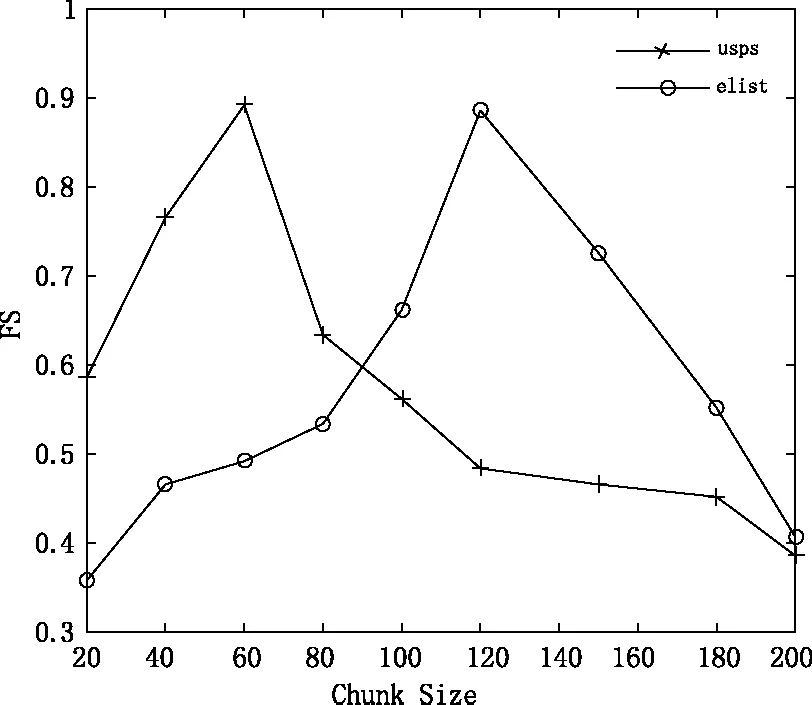
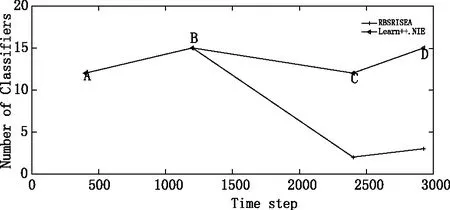
5. if newMajoritySize 7.S′←S′+newMajoritySize 8.S′←S′+SMOTE(newMinoritySize-MinoritySize) 9. else 11.S′←S′+newMinoritySize 12.S′←S′+SMOTE(newMajoritySize-MajoritySize) 13. end if 14.输出S′ 带重现概念漂移的不平衡数据流是数据流的复杂表现形式之一,具有概念漂移和数据分布不平衡的特征。针对带重现概念漂移的复杂特征,带重现概念漂移的不平衡数据流分类器必须同时满足以下几个条件:(1)历史数据不可重现。(2)分类器对概念漂移有较强的敏感性。(3)分类器具有抵抗数据分布不平衡的能力。(4)分类器可区别重现概念与新概念。基于上述目标,本文提出了一种处理带重现概念漂移不平衡数据流的分类算法,该算法是一种带权重的集成分类器模型。RBSRISEA如下。 输入:训练数据流D(t)={xi∈X,yi∈Y={1,-1}},最新历史全分类器G(t),最新集成分类器E(t), 基分类器BC,集成分类器大小K, 时间戳t, 随机采样算法RBS,单个分类器预测误差阈值β fort=1… 1.Dt′=RBS(Dt),Mt=BC(Dt′)=hk∶X→Y, Et=M∪Mt,G=Gt-1∪Mt //当集成分类器池未达到K时,先对每个数据块Dt进行随机平衡采样产生新的数据块Dt′,之后用弱分类器对Dt′进行学习,分别插入集成分类器池E和总分类器池G中,最终E满,则输出集成权重分类器Et 3. 用新来的数据流对Et进行性能评估,评估的标准为1-FS。注FS为基于混淆矩阵的F-Score值 5. forMi∈E //如果存在任意一个分类器预测值小于β,则存在重现概念,则保存目前集成分类器,go to 第3行 mi+1=BC(RBS(Dt+1)), //如果所有的子分类器预测值都大于β,则为新概念,需重新训练分类器,并插入总分类器池G,半赋予权重,子分类器性能越佳,权重越高 //从总分类器池中选出子分类器预测值大于β的分类器重新生成新的集成分类器 end for end for end for 输出:H(t)(x) 假设数据流以固定数据块大小S={D1,D2,…,Dn}的形式连续到达,用基分类器对每个数据块进行学习得到一个独立的弱分类器M={M1,M2,…,Mn},当弱分类器个数达到集成分类器池E上限K时,建立集成分类器E={M1∪M2,…∪Mk}。当数据流中产生新概念时,建立新的分类器Mi。但是不删除历史分类器,而将历史分类器存放于全分类器池G中。本文采用不删除历史分类器的方法可以成功地区分新概念与历史概念,从而避免了重现概念被当作新概念重新学习的瓶颈。 RBS算法是一个随机数据再平衡技术,这种数据再平衡技术不同于传统的过采样或欠采样技术,不再是简单地加入少数类或减少多数类的平衡技术。它是一种能改变多数类与少数类比例的循环算法达到数据再平衡的技术,这种改变多数类与少数类比例包括多数类与少数类样本数目相当、多数类样本数目占绝对优势和少数类样本数目占绝对优势的可能情形。数据集yeast1的分类器边界示意图如图1所示。图中共有500个数据样本,不平衡率为46,“o”表示多数类, “*”表示少数类,每个分类器边界颜色代表少数类用于训练基分类器的概率,红色、蓝绿色和蓝色分别表示用少数类训练基分类器的概率从高到低。实际上,当少数类训练基分类器的概率较高时,子分类器对少数类的关注度较高,分类性能较高。反之,当少数类训练基分类器的概率较低时,子分类器对少类器的关注度较低,分类性能较低。从图1可以看出,采用RBS算法训练基本分器时,子分类器的边界相对较宽,边界向少数类偏移,子分类器呈现较强的多样性和泛化能力。 理论上,在RBS算法中多数类和少数类入选生成新数据集用于训练基分类器的概率是不同的。当多数类样本数目占主动地位时,少数类入选的概率偏高。反之,当少数类样本数目占绝对优势时,多数类入选的概率偏高。 (a)RBS算法 (b)Bagging算法 图1 集成分类器边界示意图Fig.1 the ensemble classifiers′ boundaries (1) (2) 该部分主要内容为验证RBSRISEA算法处理带重现概念漂移不平衡数据流的能力,包括:(1)RBSRISEA算法是否可以检测突发性概念漂移。(2)RBSRISEA算法是否可以检测重现概念漂移。(3)RBSRISEA算法是否可以处理不平衡数据流的概念漂移。(4)RBSRISEA算法对不平衡数据是否对少数类具有较高的关注度。 本文采用的数据集如表1所示,其中yeast1为不含概念漂移的不平衡数据集,用于验证本文提出的RBS算法处理不平衡数据流的性能。SEA数据集[13]为带突变概念漂移不平衡数据流合成数据集,elist和usps为不同不平衡率的含重现概念不平衡数据流数据集, 不平衡率范围为6~18。 表1 实验数据Tab.1 Experimental data set 由于带重现概念不平衡数据流具有数据分布不平衡的特点,从而使分类器缺少对少数类的分类关注度,而同时分类器的整体性能却很高。因此,用于度量传统分类器性能的评价体系不适用于带重现概念不平衡数据流分类器的性能评估。本文采用分类评价指标为基于混淆矩阵的评价体系,具体评价指标包括接收者操作特征曲线下面积(Area Under Curve,AUC)、F-Score(FS)和召回率(Recall,R)三种。 分类器性能分析。为了验证RBSRISEA对处理带重现概念不平衡数据流分类的有效性,本文分别在SEA和usps两个数据集上对其进行实验。同时将RBSRISEA与Learn++.NIE和UCB算法在AUC和R两个方面进行比较,实验结果如图2所示。 (a)不同算法在数据集SEA上的性能比较 (b) 不同算法在数据集usps上的性能比较 图2 分类器性能分析结果对比图Fig.2 Comparison results between different classifiers 从图2可见,当三种算法处理突发概念漂移时,性能相当。但应对带重现概念漂移时,RBSRISEA具有明显的优势,召回率较高且概念识别度较高,延迟明显小于其它两种算法,这主要由于本算法不需要对重现概念进行重新学习。 数据块大小对分类器性能影响分析。RBSRISEA将数据流划分为若干个大小相同的数据块,数据块用于建立子分类器和集成分类器的验证,数据块的大小直接影响分类器的性能。如果数据块太大,则集成分类器不能检测到数据块内的小的概念漂移。如果数据块太小,则集成分类器的泛化能力较差。图3为数据块大小对集成分类器性能FS的影响分析图,横坐标表示数据块大小,范围为20~120,纵坐标为集成分类器整体性能指标FS。从图3可以看出,当数据块较小或较大时,分类器的整体性能有较大的波动。 图3 数据块大小对分类器性能的影响Fig.3 Classifier performances on different chunk size 应对概念漂移时需建立子分类器个数分析。由于RBSRISEA采用不删除历史子分类器的方法,因此该算法对不平衡数据流中新概念与重现概念有较强的敏感度和区分能力。在不平衡数据流中,存在着重现概念、新概念、相近概念,RBSRISEA对识别不同种类的概念所需建立的子分类器个数也不相同。理论上,识别重现概念时,建立子分类器个数较少。相反地,识别新概念时,需建立子分类器个数较多。图4显示了RBSRISEA在数据集usps上应对不同类型概念漂移时需建立子分类器的个数,其中横坐标表示时间戳,纵坐标表示子分类器的个数。从图4可以看出,当发生概念漂移时,需建立的子分类器个数不同。其中,时间戳A、C表示新概念发生时,需建立子分类器的个数分别为12、15,需建立的分类器个数相对较多。而时间戳B、D表示重现概念漂移发生,需建立的子分类器个数最少为2个。可见,RBSRISEA对重现概念漂移有较强的敏感度。相反地,Learn++.NIE算法无法识别重现概念,因此当发生重现概念时需要建立更多的子分类器。 图4 应对重现概念漂移时建立集成分类器个数对比图Fig.4 Different ensemble sizes with recurring concepts 带重现概念漂移的不平衡数据流广泛存在于现实世界中,本文分别分析了处理重现概念漂移数据流和不平衡数据流的方法,提出了处理带重现概念漂移不平衡数据流分类算法RBSRISEA。该算法是基于RBS算法的集成分类算法,实验证明该算法具有区分新概念和重现概念的能力,克服了重现概念被识为新概念而重新学习的困境,提高了分类器识别概念漂移的敏感度。同时,RBSRISEA是基于RBS算法的集成分类算法,RBS算法的数据再平衡能力使RBSRISEA具备抵抗数据流的数据分布不平衡特性,提高了分类器的整体性能和健壮性,尤其提高了对少数类的关注度。下一步,我们将采用不同的评价标准来量化子分类器的权重,同时也将尝试采用不同的基分类器和更广泛的数据集深度评估该算法的泛化能力。1.2 RBSRISEA
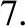


1.3 理论分析


2 实验分析
2.1 实验数据

2.2 评价指标
2.3 结果与分析

3 结语
