
一种基于动态优先级的无线传感器网络能量多路径路由算法
2019-06-22 05:35刘俞
江汉大学学报(自然科学版) 2019年3期
刘 俞
(马鞍山职业技术学院 电子信息系,安徽 马鞍山 243031)
无线传感器网络路由算法[1-2]的任务是在源节点和汇聚节点间寻找优化路径完成数据传输。在无线传感器网络中,节点的能量是有限的且难以补充,因此路由算法要高效地利用能量[3-4]。
无线传感器网络的路由算法分为平面路由算法和分簇路由算法两种类型[5]。文献[6]提出的能量多路径路由算法是最早提出的无线传感器网络平面路由算法之一,该路由算法重点考虑能量高效,在数据传输过程中,选择能量消耗小且能量相对充足的路径完成数据由源节点到汇聚节点的传输。但是,在算法中没有动态考虑各节点能量损耗情况,一旦概率确定,在整个生存期内不再变化。这样会导致在数据传输时,选择概率高的路径会被频繁选中,造成各节点的能量消耗不均衡[7-8]。
本文提出基于动态优先级的能量多路径路由算法。在算法中通过为节点设置优先级来衡量其与汇聚节点的通信能量代价及其节点剩余能量,在数据传输过程中依照优先级的大小进行路径选择。同时,节点的优先级随着其能量损耗动态变化。初始时所有节点有着相同的能量,赋予它们相同的初始优先级。在路径建立过程中,根据节点与汇聚节点间距离的跳数值[9]更新它们的优先级。在数据传播过程中,根据节点采集的数据量和转发的数据包数量实时地更新其优先级。该算法能有效降低和平衡各节点的能耗,延长了整个网络的生存期。
1 能量多路径路由算法
1.1 能量多路径路由算法中路径建立算法的步骤
能量多路径路由算法中路径建立算法具体执行步骤如下:
步骤1启动路径建立,汇聚节点广播路径建立数据包。
步骤2相邻节点接收到路径建立数据包后,根据数据包中的坐标信息计算本节点与汇聚节点的距离,然后和上一节点与汇聚节点的距离值进行比较,若本节点较上一节点距离汇聚节点更远时,则本节点转发此数据包,否则将此数据包丢弃,以避免产生回路。
步骤3如图1 所示,如果节点Dj接收到节点Di发来的路径建立数据包,经过步骤2 的判断,在转发该数据包之前,迭代计算节点Dj经过节点Di与汇聚节点Ds相连通的路径通信能耗代价C(Dj,Di),计算如下式:


图1 路径建立示意图Fig.1 Diagram of path establishment
Exp(Dj,Di)为节点Dj到节点Di通信所产生的能耗,此能耗值是由节点Dj到节点Di通信产生的直接能耗值与节点Di的剩余能量值计算得出的,综合考虑了两个节点通信的直接能耗和上一节点的剩余能量值。
步骤4节点对路径进行筛选,放弃能耗过大的路径。如节点Dj要根据以下条件判断是否将节点Di存入自身的路由表中:

其中γ的值是根据节点的路由表存储空间和系统对路由路径数量的需求预设的。当γ较小时,该节点路由表中保存的路径数少;反之,则保存的路径数多。
步骤5节点计算自身路由表中所有下一节点的选择概率,如:节点Di在节点Dj的路由表中,是节点Dj下一节点,因此节点Dj要计算节点Di的选择概率,计算如下式:

其中PDj(Di)表示在节点Dj的路由表中,节点Di被选中作为数据传输的下一节点的概率值。可以看出,通过某节点的路径通信能耗越高,此节点的选中概率越低。
步骤6节点以路由表中每项下一跳节点选择概率为权值,如节点Dj计算出所有项的能量代价加权平均值Cost(Dj)作为新的能量代价值。其含义为经由路由表中节点到达汇聚节点代价的平均值,计算如下式:

接下来,节点Dj将新的代价值Cost(Dj)置入路径建立消息中,向邻居节点广播该消息。然后转至步骤2,不断重复,直至所有节点的路由信息建立完成。
1.2 数据传输路径选择过程
路径建立完成后,当源节点要将获取的信息传输给汇聚节点时,从源节点开始,选择其路由表中选择概率最大的节点作为下一节点,依次将信息转发,直至发送到汇聚节点。
1.3 能量多路径路由算法的缺陷分析
能量多路径路由算法通过综合考虑各路径上的能量消耗及路径上各节点的剩余能量来选择最优路径,使各路径实现了能量负载均衡。但经过分析,可以发现能量多路径路由算法还存在下述一些缺陷。
1)在路径建立过程中,需要计算节点之间数据传输所需的能耗以及节点的剩余能量,在现实系统中很难实现,因为这些能耗和剩余能量很难计量。
2)在路径建立过程中,每个节点都要进行大量的复杂运算,这对节点的性能和能耗本身就是一个挑战。
3)算法中没有动态考虑各节点能量损耗情况,一旦概率确定,在整个生存期内不再变化。这样会导致在数据传输时,选择概率高的路径会被频繁选中,造成这些路径上的节点能量过度损耗而过早失效。
4)若采用周期性地由汇聚节点到其他节点实施泛洪来重新计算各参数,每次都会产生大量的运算及数据传输,累加起来所带来的能量损耗十分可观,从而导致整个网络生存期的缩短。
2 基于动态优先级的能量多路径路由算法
针对已有的能量多路径路由算法的缺陷,本研究提出一种基于动态优先级的能量多路径路由(dynamic priority energy multipath routing,DPEMR)算法。
2.1 DPEMR算法的基本思想
在DPEMR 算法中,设置优先级的作用是在数据传输过程中,当一个节点要将数据转发给下一个节点,在其路由表中选中优先级最高的节点作为下一跳节点,将数据转发给它,以此方式依次转发,直到通过此路径将数据传送至汇聚节点。在路径建立阶段,记录路径上各节点到汇聚节点的跳数值来替代它们之间的能量代价,根据跳数值对节点的初始优先级进行计算设置。在网络工作阶段,根据节点工作的频度和负荷[10](节点接收及转发数据包的数量)不断更新其优先级。
2.2 DPEMR算法路径建立算法的步骤
DPEMR 算法路径建立算法具体执行步骤如下:
步骤1汇聚节点向邻居节点广播路径建立数据包SetPath(idi,x0,y0,si,hopsi)。其中,idi是消息发送节点i的ID 号(网络中每个节点都有唯一的ID 标识号);(x0,y0)是汇聚节点的位置坐标值(在网络部署后,通过定位算法,每个节点都计算出自身的位置坐标值并存储);si是节点i与汇聚节点之间的距离(汇聚节点发出的数据包中,其值为0);hopsi是节点i距汇聚节点的跳数(汇聚节点发出的数据包中,其值为0)。
步骤2当相邻的节点j接收到节点i发来的SetPath 数据包后,根据汇聚节点及自身的位置坐标值计算出其与汇聚节点的距离值sj,比较sj与si的大小关系,若sj >si,说明节点j比节点i距汇聚节点更远,接下来对数据包中的相关数据进行计算、记录,更新该数据包(执行第3 步至第5 步)后继续向相邻节点转发,否则将数据包丢弃。节点j与汇聚节点的距离值计算公式如下:

步骤3如果节点j接收到节点i发来的路径建立数据包SetPath,经过步骤2 的判断,在转发该数据包之前,计算经由节点i的路径代价(hopsi=hopsi+1,因为汇聚节点经过节点i到节点j,跳数增加1),根据是否满足条件,决定是否将节点i加入自身存储的路由表中,判定选择条件如下:

经过(6)式的判断,若节点i满足条件,则被存储到节点j的路由表中。
在这里,统计节点距离汇聚节点的跳数值是用来替代路径能耗代价的,因为一条路径上的跳数值越大,数据被转发的次数也越多,能耗代价也就越大。
节点路由表的数据结构定义如下:
struct RouteTable{
char ID;//节点的 ID 标识号
int P; //节点的优先级
int hops;//节点距离汇聚节点的跳数
}RTdata;
步骤4节点的路由表建立完成后,节点根据路径跳数值计算其路由表中每个下一跳节点的初始优先级,假设节点i在节点j的路由表中,以计算节点i的优先级为例,计算公式如下:

其中n为节点j的路由表中节点的个数,(∑k∈RTj hopsk)/n为节点j路由表中所有下一跳节点距离汇聚节点跳数值的平均值,hopsi为节点i距离汇聚节点的跳数值,Emax为节点i的初始能量值。
步骤5节点j更新 SetPath(idj,x0,y0,sj,hopsj)数据包,其中,sj是步骤 2 所计算出的节点j与汇聚节点的距离值,hopsj是节点j通过自身路由表中各节点到达汇聚节点跳数值的加权平均值,其计算公式如下:

由(8)式可知,节点j到汇聚节点的跳数hopsj是节点j通过自身路由表中各节点到达汇聚节点的跳数与以优先级为权值得到的加权平均数,其值反映了由节点j传输数据至汇聚节点的平均能耗。
新的SetPath 数据包更新完成后,节点j将其向邻居节点转发。
步骤6跳转至步骤2,循环迭代,直至全部节点的路由表建立完成,路径建立过程结束。
2.3 数据传输路径选择及节点优先级更新过程
整个网络的路由路径建立完成后,网络进入工作状态。源节点采集后的数据要传输至汇聚节点,此时,需要通过各节点的路由表选择优先级高的路径,将数据从源节点传输至汇聚节点。源节点采集数据及数据传输路径上的节点转发数据时都产生能量损耗,因此,同时要对源节点及选中的传输路径上各个节点的优先级进行更新。以下按图2 所示的情况对具体步骤进行分析。
步骤1假设某一时刻,节点i采集外界的信息,形成数据包Message(idi,idnext,data)将发送至汇聚节点s,其中idi是节点i的ID 标识号,idnext是节点i路由表中优先级最高的下一跳节点(例如图2 中的节点j)的ID 标识号,data是其所采集到的数据。
此时,节点i要将自身存储的路由表中相关节点的优先级进行更新,例如,在图2 中节点i选中的下一跳节点是节点j,节点j将接收及转发该数据包,因此根据将产生的能耗更新节点j的优先级,计算公式如下:

其中Etx(n,d)为节点转发一个nbit 数据包所产生的能耗,Etx(n)为节点接收一个nbit 数据包所产生的能耗,Pmin是整个网络统一的优先级下限,主要考虑节点数据传输之外的能耗,若节点的优先级降为此值视为死亡。
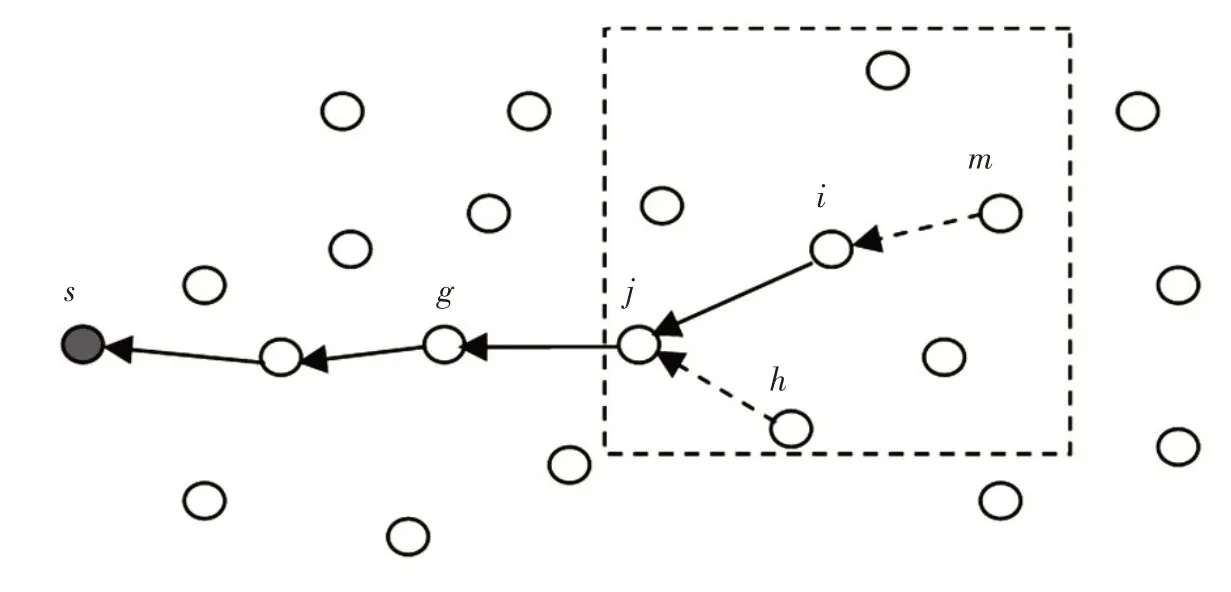
图2 数据传输路径选择及节点优先级更新过程示意图Fig.2 Diagram of data transmission path selection and nodes priority renewing process
步骤2节点i向邻居节点广播Message 数据包,处于节点i在1 跳范围内的节点都将收到此数据包,如图2 中虚线方框内包括节点j和节点m在内共6 个节点都是节点i的邻居节点,它们都在节点i的直接通信范围内。
节点i的邻居节点分为4 种情况,不同情况的节点收到Message 数据包后进行不同的处理,如下所述:
1)当相邻节点收到Message 数据包后,发现自己的ID 标识号与数据包中idnext相等(例如图2 中节点j),则该节点就是上一节点选中的转发数据的下一节点,然后在自身路由表中查询优先级最高的下一跳节点(例如图2 中节点g),用这个节点的ID 标识号更新Message 数据包中的idnext。同时,在自身的路由表中将idnext节点的优先级降低,按公式(9)将其优先级计算更新。接下来向邻居节点转发Message数据包。
2)当相邻节点收到Message 数据包后,发现自己的ID 标识号与数据包中idnext不相等,但数据包中的idnext节点在自身的路由表中(例如图2 中节点h、节点j在其路由表中),那么该节点将其路由表中的节点idnext的优先级降低,例如,节点h将其路由表中节点j的优先级按公式(9)进行计算更新,然后将Message 数据包丢弃。
3)当相邻节点收到Message 数据包后,发现自己的ID 标识号与数据包中idnext不相等,数据包中idnext节点也不在自身的路由表中,但数据包中的idi在其路由表中(例如图2 中节点m、节点i在其路由表中),那么该节点将其路由表中的idi节点的优先级降低,例如,节点m将其路由表中节点i的优先级进行更新,然后将Message 数据包丢弃。优先级更新公式如下:

4)当相邻节点收到Message 数据包后,经判断不满足以上任何一种情况,直接将Message 数据包丢弃。
步骤3下一个节点继续转发Message 数据包,转至步骤2,不断重复,直至数据包到达汇聚节点。
3 实验仿真
为了验证DPEMR 算法的性能,在NS-2 仿真环境中对能量多路径路由算法和DPEMR 算法进行仿真,对比分别使用两种路由算法下的网络负载均衡性(load balance factor,LBF)和网络生存周期。仿真环境的参数设置如表1 所示。
公式(11)与公式(12)分别为节点发送与接收数据能耗的计算公式。

LBF 是某时刻网络中节点剩余能量最大值与最小值的比值,反映网络中节点的负载均衡程度。两种算法的LBF 与运行轮数的关系情况如图3 所示。

表1 实验仿真参数表Tab.1 Parameters of simulation experiment

图3 负载均衡指数对比Fig.3 Comparison of load balance index
从图3 可以看出,随着运行轮数的推进,DPEMR 算法的LBF 明显小于原算法且增幅较小。说明DPEMR 算法的网络负载均衡性优于原路由算法,其原因是由于算法利用动态优先级使得网络在数据传输时的路径选择更为合理。
两种算法的存活节点数量与运行轮数的关系如图4 所示。

图4 网络生存期对比Fig.4 Comparison of network life cycle
从图4 可以看出,使用DPEMR 算法的网络中,第一个节点能量耗尽到最后一个节点能量耗尽的时间均迟于使用原有路由算法的网络。这是因为在DPEMR 算法中,网络的负载均衡性得到了明显提高,避免了采用原算法所出现的部分节点能量过度消耗的现象,使网络寿命得以延长。
4 结语
本文在现有的能量多路径路由算法的基础上提出了DPEMR 算法。该算法为节点设置优先级来衡量其与汇聚节点的通信能量代价及其节点剩余能量,在路径建立过程中,根据节点与汇聚节点间距离的跳数值计算出它们的初始优先级。在数据传输过程中依照优先级的大小进行路径选择。同时,根据节点接收和转发的数据包数量实时地更新其优先级。经分析可以得出,DPEMR 算法实现简单、复杂度低、计算量小,优先级的更新在数据传输过程中同时完成,避免了周期性路由维护所带来的时间与能量损失。仿真实验的结果表明,DPEMR 算法有效降低和平衡了各节点的能耗,延长了整个网络的生存期。
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
北京航空航天大学学报(2021年9期)2021-11-02
今日农业(2021年15期)2021-10-14
民用飞机设计与研究(2020年4期)2021-01-21
湖北第二师范学院学报(2020年2期)2020-06-05
魅力中国(2019年37期)2019-10-21
中国交通信息化(2019年2期)2019-03-25
网络安全和信息化(2018年4期)2018-11-09
中国交通信息化(2015年10期)2015-06-06
中国教育网络(2011年1期)2011-09-25
