
细长弹性飞行器飞行动力学并行计算及优化研究
2019-06-21 07:46:34胡斌星李新国常武权
振动与冲击 2019年11期
胡斌星, 李新国, 常武权
(1.西北工业大学 航天学院,西安 710072; 2.中国运载火箭技术研究院,北京 100076)
随着对飞行器性能要求的不断提高,飞行器自重比例逐步减小,弹性结构与其气动、控制系统的耦合问题愈发严重,箭体在飞行过程中振动特性对其动态性能影响较大,对其准确表征逐步成为新一代飞行器设计的核心技术内容之一。由于火箭和导弹的长细比较大,以往常用方法是将箭体简化为柔性梁分析;即使在有助推器的情况下,仍将助推器也视为一维梁与芯级组成空间梁系,基于特定的小偏差增量模型分析弹性振动对控制系统的影响[1];在新一代高超声速飞行器的分析中也常以自由梁或悬臂梁建模分析与气动、推进系统的耦合关系[2]。在设计验证阶段,通常将弹体离散成若干个梁单元或弹簧-质点(站点)模型,以此为基础建立飞行器模态信息并提前装订至仿真计算机;但在实际工程应用中,由于材料、飞行器几何外形的不规则以及简化过程模型精度损失等问题的影响,过少的站点数已无法准确表达飞行器自身的弹性特性,而过多的单元数已无法满足仿真过程的实时性要求。为快速的在仿真过程中获取较精确的振动特性以便为姿态控制设计、响应分析提供参考,势必采用并行计算的方法解决[3]。一些文献提出利用OpenMP(Open Multiple Processing)或MPI(Multi Point Interface)技术提高计算速度,但OpenMP技术从理论上仅能提供当前计算机CPU核心数的最大加速性能,其受线程创建及任务分发的影响较大;而MPI在仿真中由于通信的延迟其实时性并不良好,且两者维护上存在着较大的不便[4-5]。较之单纯的CPU集群运算,GPU(Graphics Processing Unit)的带宽更高、延迟更低、单位浮点运算的功耗更低,故现有的超级计算机将GPU作为协处理器以提升浮点运算能力。而自2007年NVIDIA公司正式发布统一计算设备架构(CUDA, Compute Unifed Device Architecture)并行计算技术以来,由于其采用标准C语言扩展的API形式大大降低可开发门槛,通过PCIE总线与CPU连接可以保证一定的实时性,故近年来在有限元的显式动力学[6]、隐式动力学[7]、结构力学[8]、分子动力学、方面有着广泛应用,并已成为高性能计算领域的重要分支。Fleischmann等[9]就MPI和OpenMP 及CUDA结合,在矩阵不完全LU分解和子空间迭代法求解特征值问题的加速效果做了非常详细的对比,验证了GPU在数值计算方面能取得明显的性能提升;Cheng等[10]对克里金插值的GPU加速算法做了详尽阐述,说明了插值计算GPU加速的可能性;李涛等[11]实现了基于线程池的GPU任务并行计算模式,就矩阵运算等一般性的运算做了验证分析,但并未针对GPU特性实现细粒度的性能优化。在多GPU运算方面,赖剑奇等实现了多GPU的并行可压缩流求解器,验证了多GPU良好的可扩展性;Gao等[12-13]也发表了大型稀疏线性系统求解的多GPU解算方案,可上述文献皆未关注除解算器以外的粗粒度并行问题,仅在有限元法解算中实现了加速,设计适宜实时仿真的多GPU架构并未阐述。因此本文根据以上研究内容,从GPU硬件特点着手,在单台多GPU的工作站上设计了细长体弹性飞行器弹性模块异步并发并行计算的架构设计,实现了基于算法的GPU的动态性能优化,首次提出了动态分配线程块的八叉树构建及索引方法用以实现多线程快速索引气动数据,对不同计算规模的性能进行系统分析。对并行程序设计及优化,三维数据快速索引插值方面具有重要指导意义。
1 细长体飞行器振动响应算法分析
为便于说明细长体弹性飞行器振动响应算法的并行实现,在此结合算法分析计算流程,并分析各步骤的计算量及比例,以便决定并行算法设计的重点。如前所述,将全弹体简化为非均质梁模型,以EJ(x)表示弯曲刚度,m(x)表示线质量,l表示参考长度,q(x,t)表示作用在梁元上的横向分布外力,忽略梁元的转动惯性,且在无阻尼的情况下,依据梁的弯曲理论和力矩平衡方程,得到梁的弯曲振动微分方程
(1)
当q(x,t)=0时得到该振动微分方程的通解部分;通过自由梁两端的边界条件可得特解;把梁的受迫振动展开成固有振型的级数形式如下
y(x,t)=yc(t)+θ(t)(x-xc)+
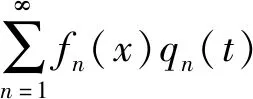
(2)
鉴于单位长度分布外力可表示为乘积q(x,t)=q(t)P(x),把式(2)代入式(1)对x积分变换后得
(3)
式(3)中等式右端广义力为
式(3)中第一项表示质心运动方程,第二项表示绕横轴的旋转运动方程。当给定外力q(t)P(x)时,可以由最后一组方程求得梁弯曲振动的广义坐标。经推导,可将细长体飞行器的法向和横向弹性振动方程数值解算步骤归纳为
(4)
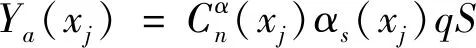
(5)
Qfayi=Ya(xj)×fiy(xj)
(6)
Qfayi+Py+Feiy+Fpy+Fdy
(7)
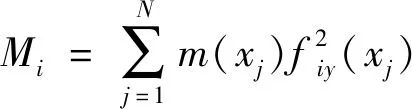
(8)
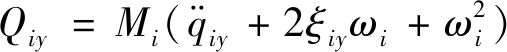
(9)
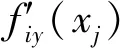

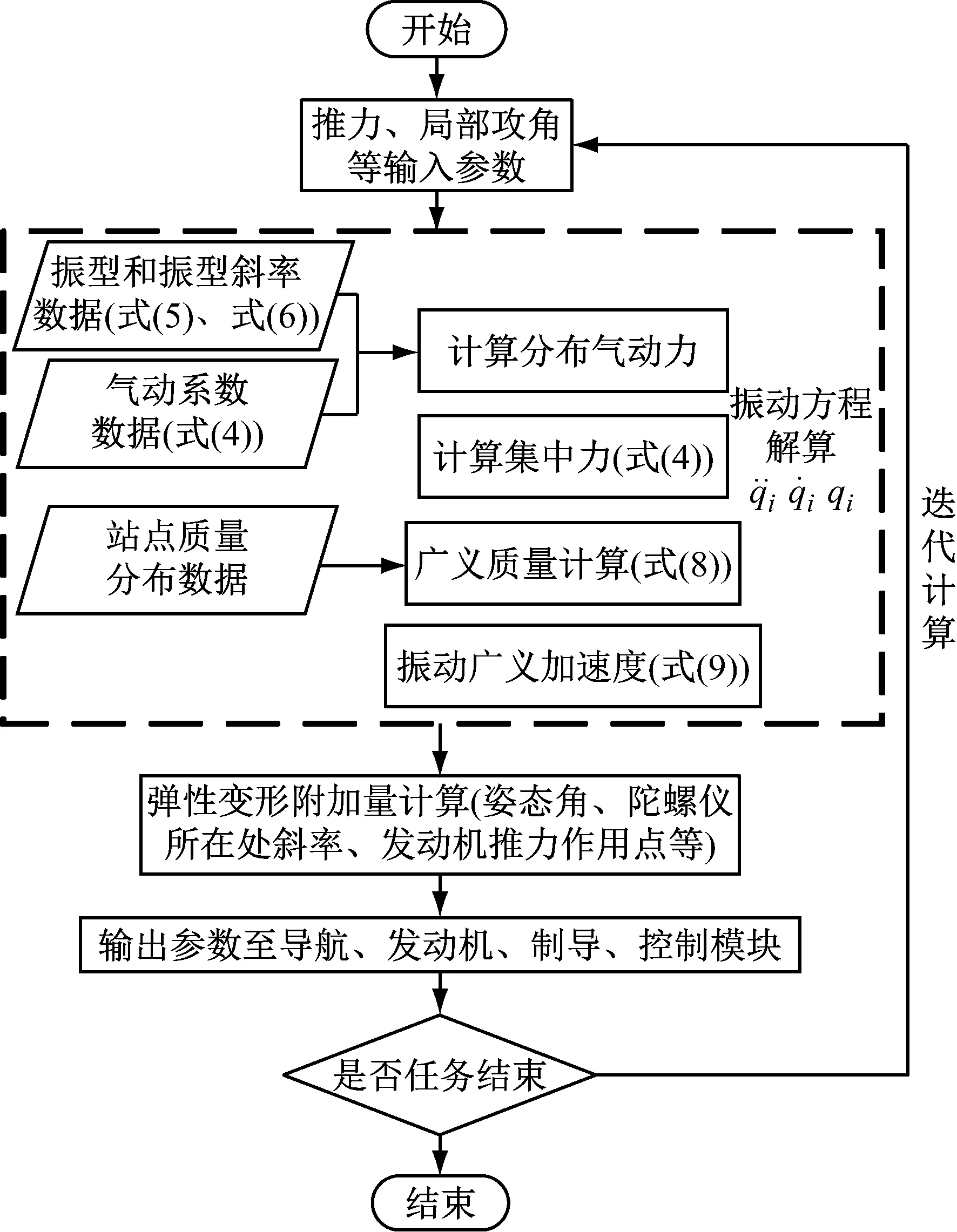
图1 飞行动力学仿真中弹性模块计算流程
表1 不同站点数CPU版插值计算耗时及占计算总时长百分比
Tab.1 Interpolation calculation accounts for the total length of calculation using different sites

站点数20080032001280051200CPU耗时/ms1.382.4718.676.9269.4占计算总时长百分比/%6177879195
2 基于CUDA的算法设计及架构优化
2.1 广义质量的并行算法设计
如上节所述,广义质量的计算包含两次长度为N的向量元素相乘和长度为N的向量归约问题[14]。在本文中每个线程完成元素相乘的工作后,选用交错配对的归约算法[15]。交错配对归约算法与邻近配对归约算法相比,其计算的跨越步长不再是相邻线程的数据,而是为线程块大小的一半起始,每次迭代减少一半,因此与邻近配对归约算法相比,交错配对算法每次迭代减少的工作线程不发生变化,使得尽可能的减少了线程束的失速。经测试表明,交错配对归约算法较邻近配对归约算法,在不同计算规模下有1.34倍~1.69倍的加速比。
2.2 气动系数插值计算的并行算法设计
针对此类问题,通常用八叉树描述三维空间的树状数据结构:树中任意节点的子节点数要么为零要么为八,通过增加每个节点指针的数量(由两个变为八或九个)和每次索引后的计算量(由左右边界的判断变为三方向上边界与中点的判断)减少索引深度,以达到提高速度的目的。而NVIDIA公司提供了动态并行API(CDP,CUDA Dynamic Parallelism API)并演示了通过递归的方式构建四叉树的示例,故本文以此为模板构建气动数据表的八叉树。其GPU内动态创建线程块的流程图如图2所示:在获取数据表数据大小后确认八叉树的深度;待满足建表要求后,将父线程块一分为八并以线程束为基本单位统计每个子块内的点数;待线程束完成其计算后将相关数据传与八个子线程块,以此递归直至不满足条件为止。
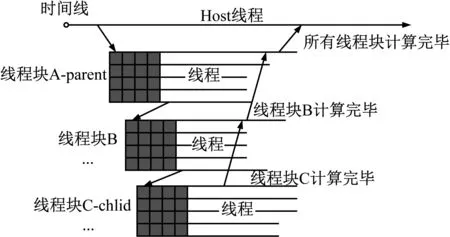
图2 动态构建线程块示意图
2.3 基于异步消息的并行架构优化
国内外针对多机并行计算时多选用MPI实现数据的交互及同步[18],但在单机多GPU算例中未详细阐述针对所研究对象的程序架构优化问题。在以上文献中均使用的同步函数,使得设备在完成任务前不会将控制权交还主机线程,导致主机线程的阻塞。故在此可通过粗粒度的CPU和细粒度的GPU两方面着手实现并行程序的性能优化:前者实则为程序主架构的优化,通过开启一个有着若干线程的线程池,初始化阶段构建一个任务结构体,内含CUDA计算的识别号、所使用的设备号、流指针、主机端数据指针及设备端数据指针,在程序初始化时根据当前所拥有的设备数将计算任务分发给不同的线程,运用异步方式始终保证CPU的控制权,直至GPU运算完成触发回调函数即可按逻辑进行下一步的计算;而后者则可通过某个计算能力2.x以上的GPU在执行计算时同时进行数据的传输,使GPU得执行引擎与存储引擎可同时工作[19]。
鉴于在本文数值解算过程中弹性振动方程解算模块解耦为轴法横三个方向的独立计算,且没有相互耦合的中间变量,程序主架构的设计如图3所示。主线程维护一个先进先出的队列完成任务分配并追踪线程池内从线程的任务进度和状态,而线程池内从线程负责完成实际的GPU函数调用并产生局部解算结果。
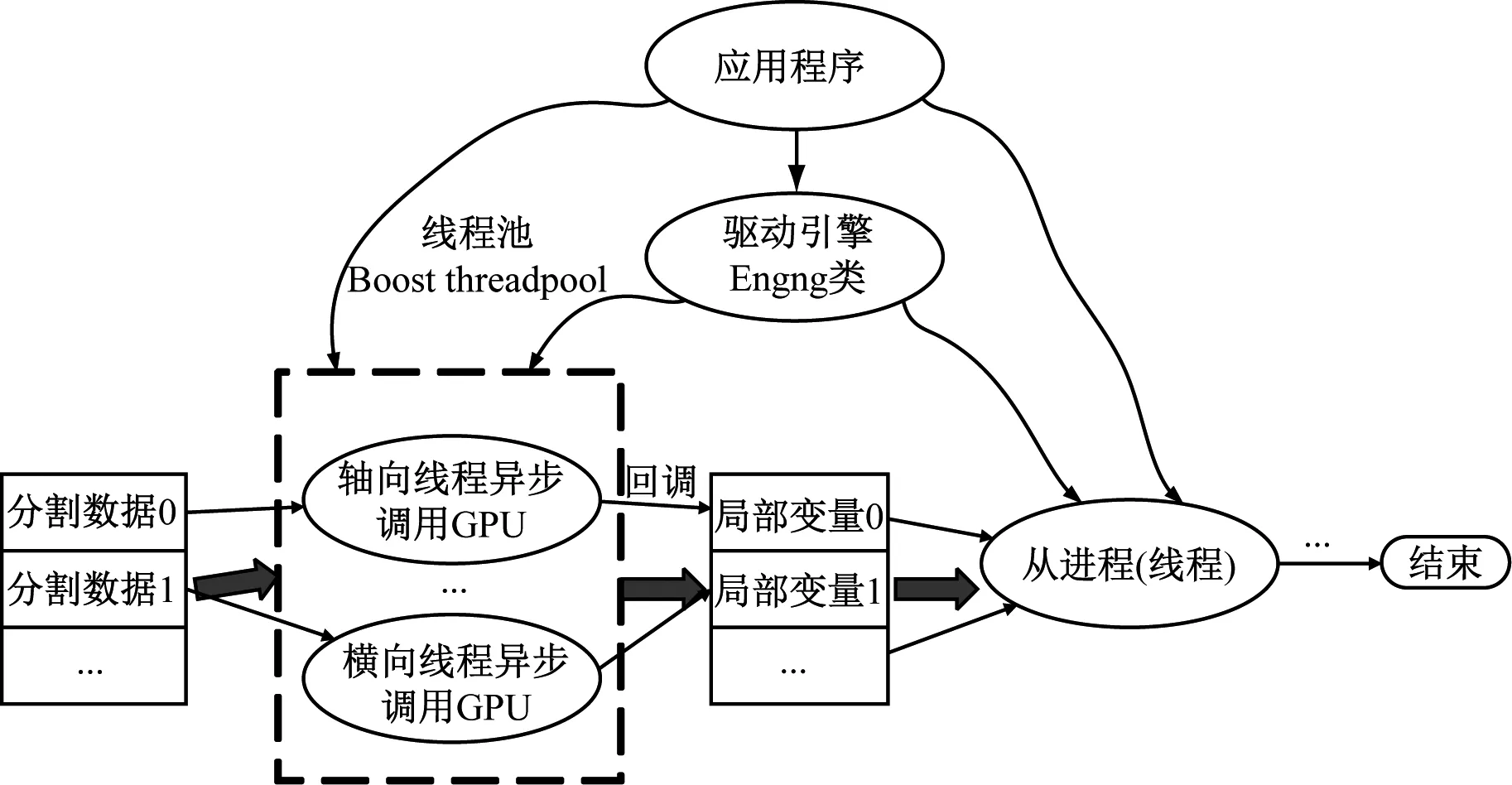
图3 程序多线程异步架构示意图
而图4演示了某个线程内GPU运算的时序对比。GPU采用同步运行时,一旦传输数据量较大可能导致GPU设备的空置。若像图中在初始化阶段进行数据分割,即将某一方向中的原始数据划分为若干个小块,以流的形式可以实现数据传输的隐藏以提高计算效率。同时自Kepler架构后HyperQ技术使得运行多个CPU核或线程在某一GPU上启动任务,以多个工作队列的形式提高了GPU的利用率,避免了伪依赖。其伪代码如下
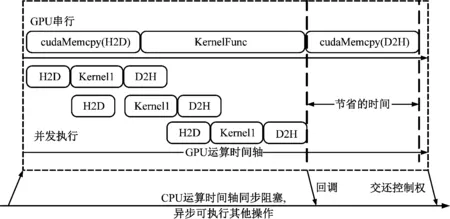
图4 串行与异步流形式运算时序对比图
1) CreateStream
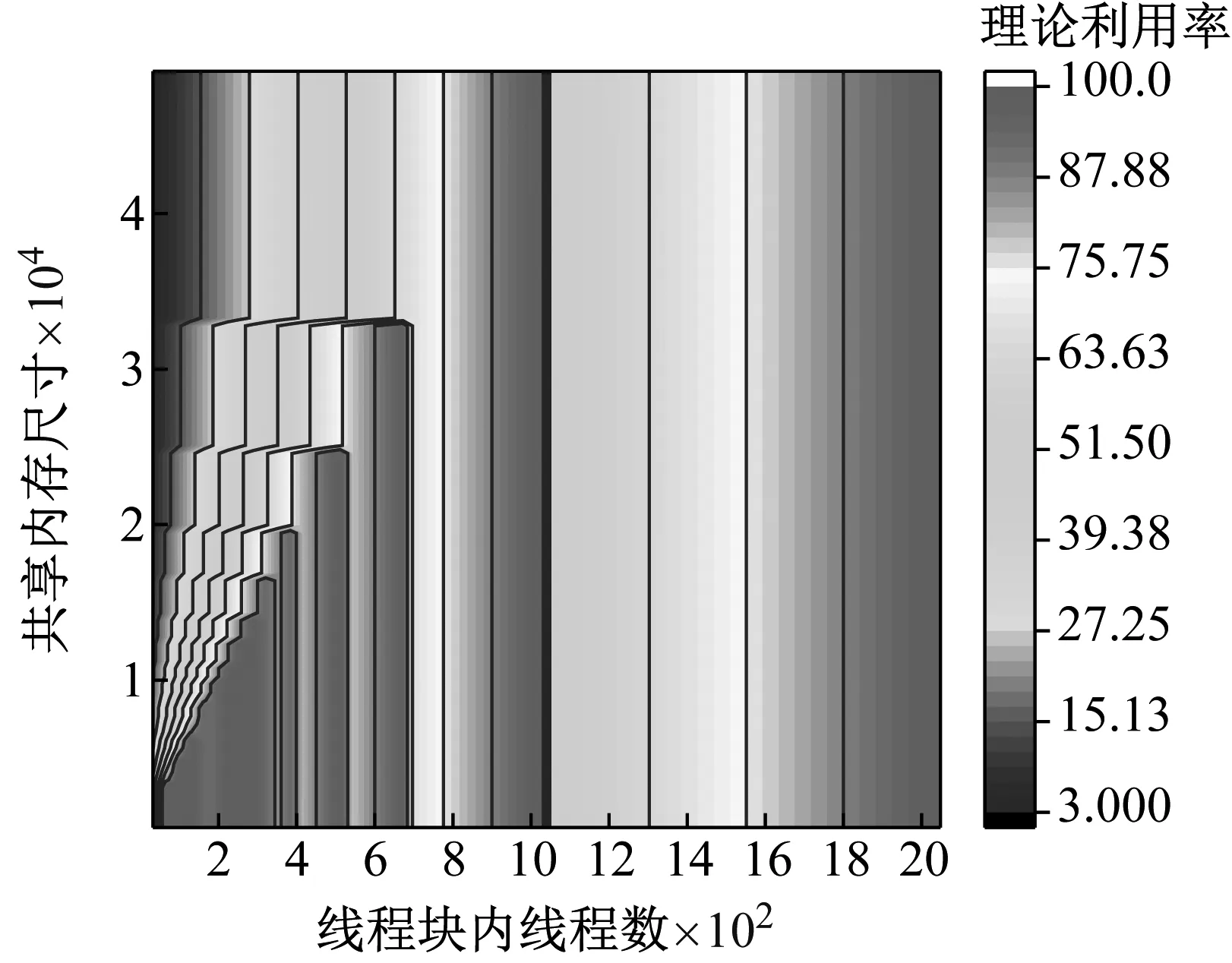
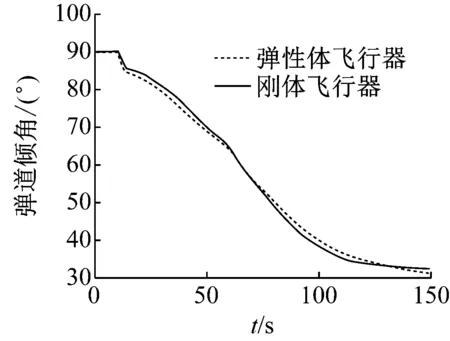
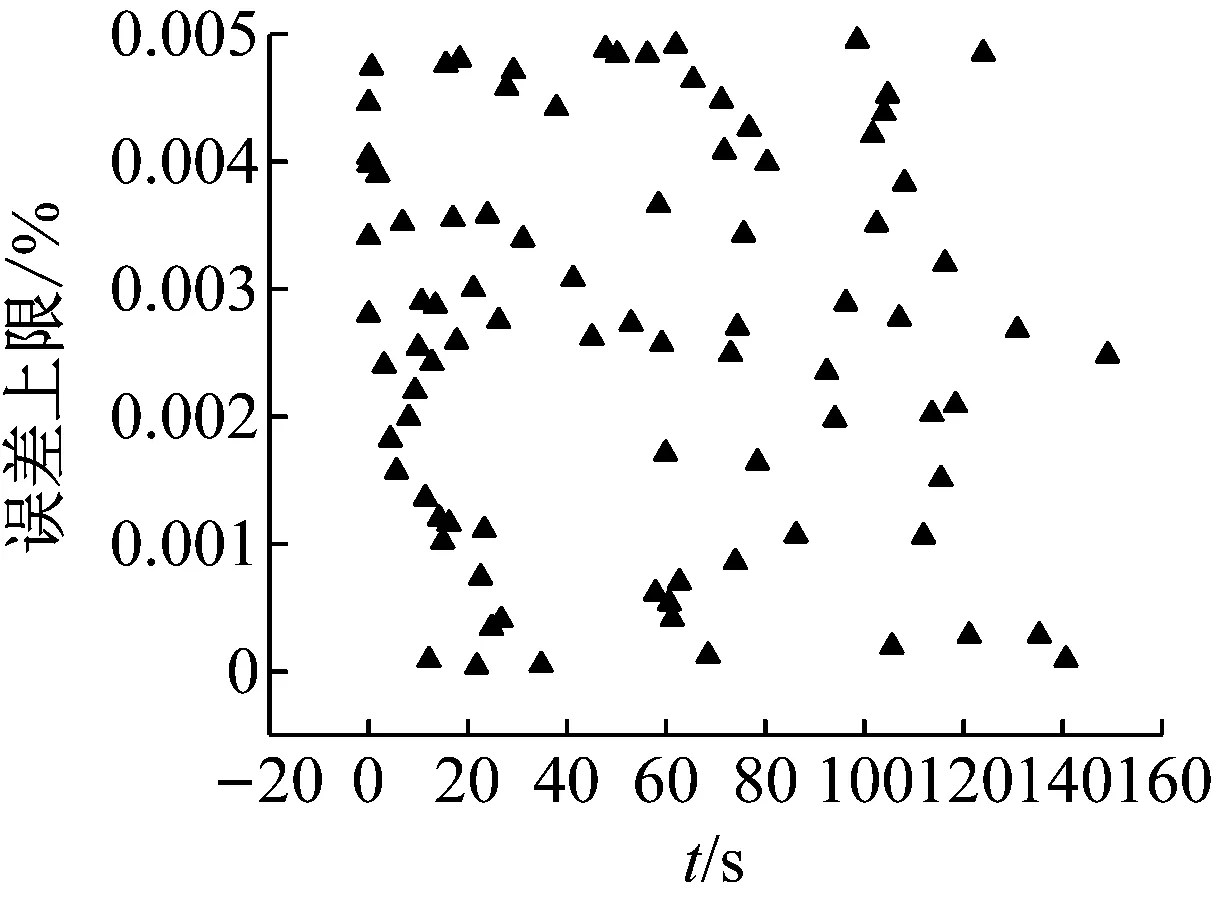
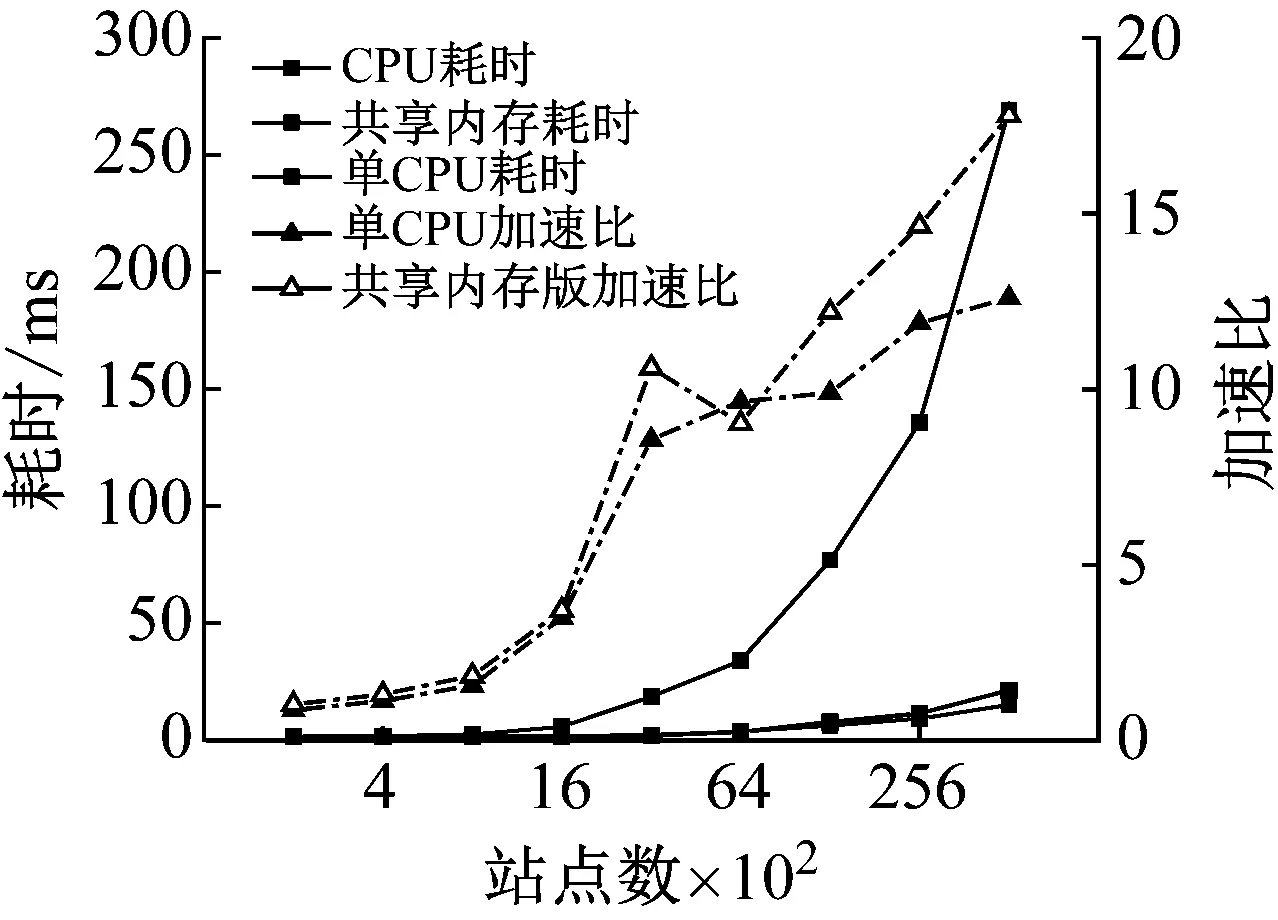
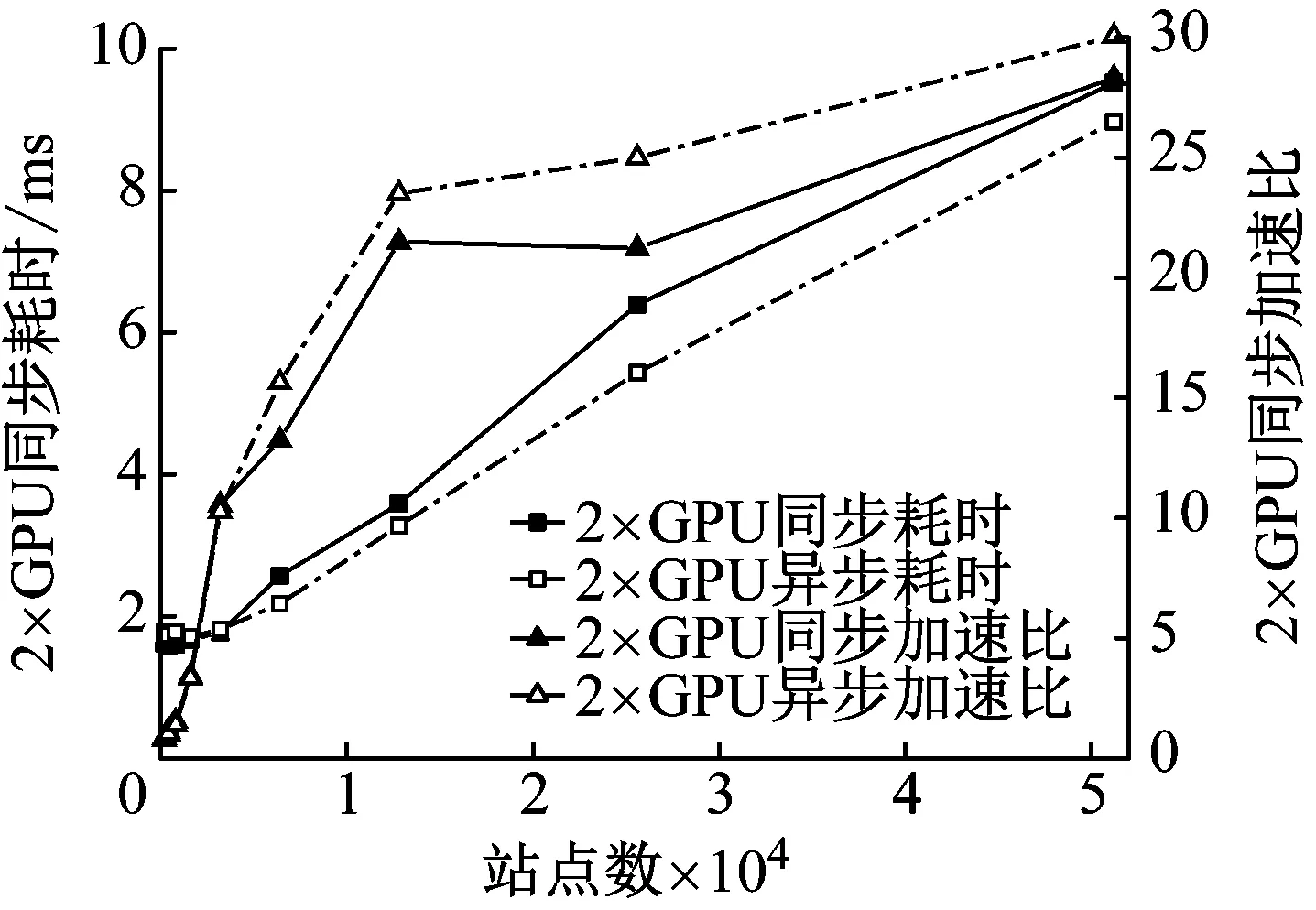
2) While i 3) cudaHostAlloc && cudamalloc 4) cudaMemcpyAsync(H2D) 5) interpolate<< 6) cudaMemcpyAsync(D2H) 7) cudaStreamAddCallback(stream,callbackfunc, data,flag) 8)i++, return 3) 上述第1)步首先依照任务结构体内的流指针创建流对象,并得到计算设备其内部的各种硬件参数;第2)步~第8)步依照给定的流对象完成内存拷贝、核函数计算、函数回调等待数据回传的过程。其中第5)步的第三个模板参数即低访问延迟的共享内存的大小,在核函数内通过extern __shared__关键词动态分配共享内存空间,以起到节省每个流多处理器(SM,Streaming Multiprocessors)上宝贵的一级缓存空间,防止核函数调用失败。鉴于本文所用最大的三维气动插值表不超过1 200个数据点,因此可通过将线性化的气动数据表放入共享内存中以实现读取气动数据的加速。 为使程序在任意复杂度的数值算法中保证高性能的通适性,需考虑第5)步内前两个参数对硬件的利用率有影响:一个流多处理器在线程数、线程块数及寄存器数方面皆有硬件限制,具体参数因GPU计算能力不同而异。在计算模式和算法已定的情况下,每个线程内的寄存器使用数量即已确定,而所需分配共享内存的大小直接取决于气动数据表的大小,故最为影响流多处理器理论效率的即为核函数的第二个参数,即每个线程块内的线程数。依照参考文献[20]建立流多处理器利用率和共享内存大小、线程块内线程束的函数,在程序初始化阶段依照该函数关系建立效率索引表,如图5所示为单线程使用25个寄存器的情况下每个流多处理器的理论效率索引图。故在程序中可依照算法和气动数据表的大小决定参数2,以期实现利用率的最大化及核函数的动态参数优化。 本文建立单台计算机、多GPU并行求解器,模拟细长体弹性飞行器飞行过程进行仿真,并对单GPU及多GPU并行的性能及拓展性进行对比。因本文重点为加速计算的方法研究,暂选用某型飞行器的气动数据,但鉴于数据敏感且不失一般性,计算时每个时步较上一个时步在气动系数的各个维度上均添加一个随机量。受计算资源限制,算例平台硬件采用主频3.4的Intel E3 1230V5,两片英伟达GTX1060 3G显卡;编程环境为VS2017下的MSVC14.0编译器及CUDA 9.0的NVCC编译器。时间统计时采用CUDA自带的cudaEvenet_t计时,其精度为0.5 μs;考虑弹性模块与其他模块的数据耦合关系,以计算最频繁的控制周期为实时性判定准则,在此选用10 ms为限。 图5 流多处理器利用率索引示意图 程序的正确性及快速性是衡量程序性能的重要指标。选用某型细长体飞行器的攻角作为标准,模拟起飞时刻至第一级分离过程弹性模块的计算流程,如图6所示,刚体飞行器与弹性体飞行器的弹道倾角变化总体一致且相差不大。其原因是在传统刚体飞行器的弹道仿真中,由于控制系统的鲁棒性,在有一定偏差条件下仍能够满足飞行姿态的稳定并保证对标准弹道的跟踪,故弹性变形引起的各附加量输出至指导控制计算机后对整体弹道的影响不大。而如图7所示,通过传统CPU与GPU运算结果对比,可认为CPU与GPU的运算结果并无二致。 由图8可知,单GPU情况下在站点数较少时加速效果并不明显,因为计算均需通过低速的PCI-E总线传输计算数据,且启动的线程数不足以隐藏数据传输和核函数启动的时间开销,即异构架构带来额外的通信及函数启动时间无法抵消多核运算带来的性能提升。但尽管选用常规的Geforce卡,其没有ECC显存且每个流多处理器内的双精度计算单元比例更少,采用CUDA技术的双精度计算的求解时间在单元个数较多时仍能保证较好的加速比,经优化后在站点数25 000个左右时能保证仿真计算的实时性;随站点数的增加,加速比达到13左右且斜率下降趋于稳定。而当气动数据表较小足以放入共享内存中时,同理在站点数较少加速效果不明显,随着站点数的增加,计算由I/O密集型转向计算密集型,加速效果逐渐明显;与常规从全局显存读取数据的加速比不同,在站点数3 000左右有一个下跌的趋势,其原因可能是多线程访问共享内存导致的访存冲突进而影响了运算效率。 图6 弹性体与刚形体弹道倾角对比 Fig.6 Comparison of trajectory inclination angle between rigid and elastic vehicle 图7 CPU与GPU运算误差结果对比 Fig.7 Comparison of error results between CPU and GPU 图8 不同站点数CPU与GPU计算结果对比 Fig.8 Comparison of the calculate results between CPU and GPU with different scales 图9 不同站点数多GPU同/异步架构耗时对比 Fig.9 Time consuming comparison of multi GPU synchronous/asynchronous architecture with different scales 而异步较之于同步设计、多GPU较之于单GPU在数据规模较小时差异不大,甚至效率更低,如图9所示。其原因是多GPU情况需要进行数据分割和开启额外的显卡资源。此时异步操作更需要线程同步等待,加速比更为不理想;随站点数的增加,多GPU加速比提升更快,加速效果更明显,直至50 000个站点时也未出现加速比趋于平缓的趋势,其原因是数据分割时间所占总时长百分比愈来愈小,并行部分的传输较计算操作在程序中所占比例逐步减少得到充分的延迟隐藏,使得流多处理器效率更高,也从侧面映证该方案适宜求解大规模的数值运算。 (1) 基于CUDA技术实现了细长体飞行器弹性模块的快速求解方法设计,在多GPU环境下取截断模态40阶,可保证至少1 200个站点的弹性飞行器的实时仿真计算。 (2) 针对GPU架构提出了动态并行分配线程块的八叉树的气动系数索引方法,优化了双线性插值的索引步骤,效果较好。 (3) 设计了单机多GPU的异步并行架构,并仿真说明多GPU并行能够进一步显著提高计算效率,证明了所建并行架构的扩展性与快速性。在此研究基础之上,开展针对超过三维的插值表优化索引模式研究,对多机协同计算做进一步的可拓展性分析。3 数值算例分析
3.1 测试平台
3.2 计算精度及效率分析
4 结 论
猜你喜欢
天然气与石油(2022年4期)2022-09-21 07:05:54
凤凰动漫(军事大王)(2022年1期)2022-04-19 11:35:10
北京航空航天大学学报(2021年6期)2021-07-20 07:23:52
测控技术(2018年9期)2018-11-25 07:44:24
电子制作(2018年2期)2018-04-18 07:13:25
环球市场(2017年36期)2017-03-09 15:48:21
小朋友·快乐手工(2015年5期)2015-06-06 00:46:12
凿岩机械气动工具(2014年3期)2014-03-01 04:00:07
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
杭州电子科技大学学报(自然科学版)(2010年5期)2010-01-08 07:28:38
