
基于数据挖掘分类的创新创业团队管理考核机制研究
2019-06-19 02:33马莉周小虎
现代电子技术 2019年11期
马莉 周小虎


摘 要: 为了对现有创新创业人才管理体系中的量化绩效考核机制进行改进,提出一种基于数据挖掘技术的研究方案。将决策树算法与聚类分析相结合运用到量化绩效考核体系中,从而发掘考核结果与各种因素之间的关系。采用K?means聚类算法对团队成员进行测评分析,以分类规则的形式粗略划分为4个等级。采用ID3决策树算法根据测评等级和创业团队核心属性,生成细化的最终个人量化考核得分表。以某个创业团队的实际数据为样本进行测试、分析和验证,测试结果表明提出方案具有较好的准确率,为人才队伍管理提供了有力的决策支持。
关键词: 数据挖掘; 考核指标; 绩效考核; 量化绩效; K?means聚类; 决策树算法
中图分类号: TN711?34; TP393 文献标识码: A 文章编号: 1004?373X(2019)11?0178?03
Abstract: In order to improve the quantitative performance appraisal mechanism in the existing innovation and entrepreneur talents management system, a research plan based on data mining technology is proposed. The decision tree algorithm and cluster analysis are combined to apply to the quantitative performance appraisal system, so as to explore the relationship between the assessment results and various factors. The K?means clustering algorithm is used to evaluate and analyze the team members, and the members are roughly divided into four levels in the form of classification rules. The ID3 decision tree algorithm is used to generate a refined final score table of personal quantitative assessment, which is based on the evaluation level and the core attributes of the entrepreneur team. The actual data of a entrepreneur team was taken as a sample for testing, analysis and verification. The test results show that the proposed scheme has high accuracy rate, and provides powerful decision support for the talent team management.
Keywords: data mining; appraisal index; performance appraisal; quantitative performance; K?means clustering; decision tree algorithm
0 引 言
随着计算机技术的快速发展和大规模普及,信息采集与分析成为各大企事业单位发展过程中必须面对的重点问题。21世纪进入了大数据时代,办公自动化、信息化设备、数据库软件等各种计算机辅助技术的运用,产生了海量的数据信息[1]。但是,如何高效地分析和处理这些急剧膨胀的数据,并为部门业务发展提供决策服务和技术支持,成为过程监管控制系统需要解决的难题,特别是创新创业团队管理。
数据挖掘是20世纪90年代出现的一门交叉学科,涉及来自数据库技术、知识工程、概率与统计、模式识别、神经元网络、可视化技术等各领域的研究成果[2]。数据挖掘的本质目标是从大量、有噪声的、不完全的、模糊的、随机的数据中抽取出隐藏的并具有一定可利用价值的信息和关系。目前,数据挖掘在量化绩效考核管理系统中的应用已经成为热门研究方向[3?4]。文献[5]提出一种基于数据挖掘的人力资源考核系统。文献[6]利用数据挖掘关联规则的Apriori算法对学生成绩进行综合分析,不仅能够获悉学生对知识的掌握程度,还能够发掘课程之间的彼此内在联系。文献[7]应用数据挖掘技术将与企业有潜在价值的信息挖掘并与相关的信息比对整合,得到评价企业更有价值的信息,使用项目考核提升效率。通过上述研究分析发现,现有的基于数据挖掘的绩效考核方法均采用单一的决策树或者关联规则分析,且对绩效考核评估涉及的成员属性选择并不准确。
因此,本文提出将决策树算法与聚类分析相结合运用到量化绩效考核体系中,以便揭示出隐含在绩效考核评估背后的有价值信息。首先采用K?means聚类算法对团队成员进行测评分析,以分类规则的形式粗略划分为4个等级。然后,采用ID3决策树算法根据测评等级和创业团队核心属性,生成细化的最终个人量化考核得分表。以某个创业团队的实际数据为样本进行测试、分析和验证,测试结果表明提出方案具有较好的聚类精度和评估准确率,为决策管理提供了有力的技术支持,提高了创新创业团队管理的工作效率。
1 数据挖掘定义
数据挖掘汇集了来自机器学习、模式识别、数据库、统计学、人工智能等各领域的研究成果[2?4]。计算机的大规模普及产生了海量的数据,数据挖掘通过综合以上学科领域的技术成果,对海量数据进行处理和分析。数据挖掘是知识发现流程的关键步骤,如图1所示。
图1 数据挖掘知识发现图
将大量的业务信息数据化并进行关键信息采集、预处理和变换,以及合理的模型选择,从中抽取出能够辅助管理决策的有价值的隐藏关联信息。通过数据挖掘可以有效提升业务竞争力,提升团队运作效率。通过数据挖掘技术可以发现两个不相关的数据,但同时又与其他第三方数据有关系,从而间接地通过网络建立一个隐藏的连接,以便于信息的传输和分析。本文的研究目标就是构建基于数据挖掘技术的创新创业团队量化绩效考核机制,从而发掘考核结果与各成员工作相关因素之间的关系。
2 基于数据挖掘的量化绩效考核方法研究
2.1 考核指标分析
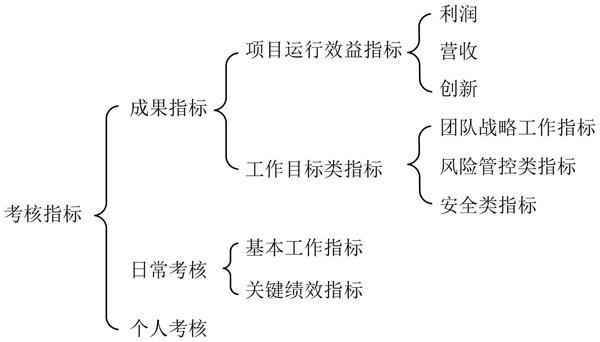
针对创新创业人才管理体系,采用的绩效考核指标如图2所示,包括成果指标、日常考核指标和个人考核指标。基于数据挖掘的量化绩效考核方法原理如图3所示。
图2 绩效考核指标体系
图3 基于数据挖掘的量化绩效考核方法原理图
2.2 基于K?means聚类的绩效考核等级测评
作为一种基于距离的划分聚类算法,K?means聚类算法具有算法结构简单、运行效率高且适用范围广等优点[8]。K?means聚类算法一般通过式(1)所示的目标函数来实现优化:
式中:[E]为聚类准则函数;[K]为聚类的总数;[Cj(j=1,2,…,K)]为聚类中的簇;[x]为簇[Cj]中绩效考核指标体系的内容;[mj]为每项指标的平均值。
本文K?means聚类算法的输入参数[K]为4个测评等级(优秀/良好/合格/不合格),如表1所示。数据集[X]中聚类目标的数量[n]为绩效考核数据库中给的数据源,输出为使聚类准则函数[E]达到最小的[K]个聚类。K?means聚类算法的基本流程为:
1) 输入参数并初始化[K]个聚类中心;
2) 计算[E]的数值;
3) 更新每个群集的中心并计算新[E];
4) 是否满足收敛条件,是则输出参数并结束;反之跳转到步骤2)。
表1 绩效考核等级参照表

2.3 基于ID3决策树算法的量化绩效评估
ID3决策树算法的关键是按照递归思想进行信息增益和熵的计算。计算初始熵的方法如下[9]:
为了得到更加准确的评估结果,本文在绩效考核数据库中设置了7项核心属性来构建ID3决策树,如表2所示,并选择具有最大信息增益率的“专业能力”作为ID3决策树的根节点。
表2 核心属性

3 测试结果与分析
3.1 测试配置
实验硬件环境参数为:Windows 7操作系统,CPU为I7处理器,4 GB内存。测试数据来自某创业团队近两年的实际历史数据,该团队分为4个项目组,共计38人。
3.2 结果分析
K?means聚类算法和ID3决策树算法计算出的某小组中所有成员的绩效考核得分如表3所示。
表3 个人绩效考核得分数据

表3得出的个人绩效考核得分与实际个人绩效考核结果一致,数据准确性达到92%,在精度上能够满足实际应用需求。此外,通过本文数据挖掘方法,量化绩效考核工作效率得到了大幅提升,驗证了该方法的先进性和有效性。
4 结 论
本文将决策树算法与聚类分析相结合应用到量化绩效考核体系。首先采用K?means聚类算法对团队成员进行测评分析,以分类规则的形式粗略划分为4个等级。然后,采用ID3决策树算法根据测评等级和创业团队核心属性,生成细化的最终个人量化考核得分表。实际测试结果表明本文提出方案具有较好的聚类精度和评估准确率,对量化绩效考核系统具有一定的参考意义。
参考文献
[1] XU L, JIANG C, WANG J, et al. Information security in big data: privacy and data mining [J]. IEEE access, 2017, 2(2): 1149?1176.
[2] EASLEY D, PRADO M L D, O′HARA M. Discerning information from trade data [J]. Journal of financial economics, 2016, 120(2): 269?285.
[3] MERCHANT C J, PAUL F, POPP T, et al. Uncertainty information in climate data records from earth observation [J]. Earth system science data, 2017, 9(2): 1?28.
[4] SUN Y, BIE R, THOMAS P, et al. Advances on data, information, and knowledge in the Internet of Things [J]. Personal & ubiquitous computing, 2016, 20(5): 653?655.
[5] 裴新明.基于数据挖掘的人力资源考核系统分析[J].企业改革与管理,2016(18):57?58.
PEI Xinming. Analysis of human resource assessment system based on data mining [J]. Enterprise reform and management, 2016(18): 57?58.
[6] 孙永辉,周宏.数据挖掘技术在高校成绩分析中的应用研究[J].科技创新导报,2015(33):157?159.
SUN Yonghui, ZHOU Hong. Application research of data mi?ning technology in college performance analysis [J]. Science and technology innovation review, 2015(33): 157?159.
[7] 王孟钊,臧冲.工程建设领域信息系统的实现[J]. 信息技术,2014(5):206?209.
WANG Mengzhao, ZANG Chong. Implementation of information system in engineering construction field [J]. Information technology, 2014(5): 206?209.
[8] LIU H, WU J, LIU T, et al. Spectral ensemble clustering via weighted K?means: theoretical and practical evidence [J]. IEEE transactions on knowledge & data engineering, 2017, 29(5): 1129?1143.
[9] ZHANG X, AI F, LI X, et al. Inflammation?induced S100A8 activates Id3 and promotes colorectal tumorigenesis [J]. International journal of cancer, 2015, 137(12): 2803?2814.
猜你喜欢
大众投资指南(2021年35期)2021-02-16
经济技术协作信息(2018年30期)2018-11-22
经济技术协作信息(2018年30期)2018-11-22
消费导刊(2017年24期)2018-01-31
电力与能源(2017年6期)2017-05-14
时代金融(2016年27期)2016-11-25
科技视界(2016年14期)2016-06-08
科技视界(2016年7期)2016-04-01
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
