
基于大数据技术的数据仓库体系结构设计
2019-06-15 01:01姚鹏飞
数字技术与应用 2019年3期
姚鹏飞

摘要:大数据时代,数据结构的复杂性和数据体量的剧增使得传统数据仓库体系结构已经不能满足数据处理的需要。本文在对传统数据仓库体系结构相关理论研究的基础上,重点分析了传统数据仓库体系结构存在的不足以及大数据的特征和对数据处理的新需求,构建了基于大数据技术的数据仓库体系结构,采用目前流行的Hadoop/Spark大数据处理技术架构,实现半结构化数据和非结构化数据的收集、处理、存储和分析挖掘,弥补了传统数据仓库在海量数据处理、存储方面的不足,有效解决数据利用率低、价值发挥不明显的问题。
关键词:大数据;数据仓库;体系结构
中图分类号:TP311.13 文献标识码:A 文章编号:1007-9416(2019)03-0141-03
0 引言
随着数据量的急剧增长,传统的数据仓库应用已经难以满足联机分析处理对数据仓库提出的新需求[1],数据处理的实时性要求和数据结构的多元化、非结构化使得传统数据仓库的性能瓶颈逐渐显现。大数据、云计算等新技术以其强大和高效的存储和计算能力正在成为海量数据管理的经济有效方式[11]。在数据应用领域,随着各类系统复杂性的不断增强,数据总量正逐年以指数形式上涨,且数据类型超越了传统数据库所能处理的范畴。如何将这些数据进行收集、整理并加以分析、应用成为研究热点。传统的数据仓库由于处理数据格式有限、计算能力扩展困难,已经不能满足数据处理需要,寻求新的数据仓库解决方案成为当务之急。大数据技术能够极大拓展数据的收集能力,提升数据的综合分析处理能力。本文基于大数据技术构建数据仓库体系结构,将大数据和数据仓库技术进行结合,采用目前流行的大数据架构Hadoop/Spark,充分借鉴其低成本、高性能、高可靠性和可扩展的特点,以期实现对数据的采集、处理、存储和深度挖掘分析,有效发挥数据价值。
1 传统数据仓库技术架构面临的挑战
1.1 传统数据仓库技术架构
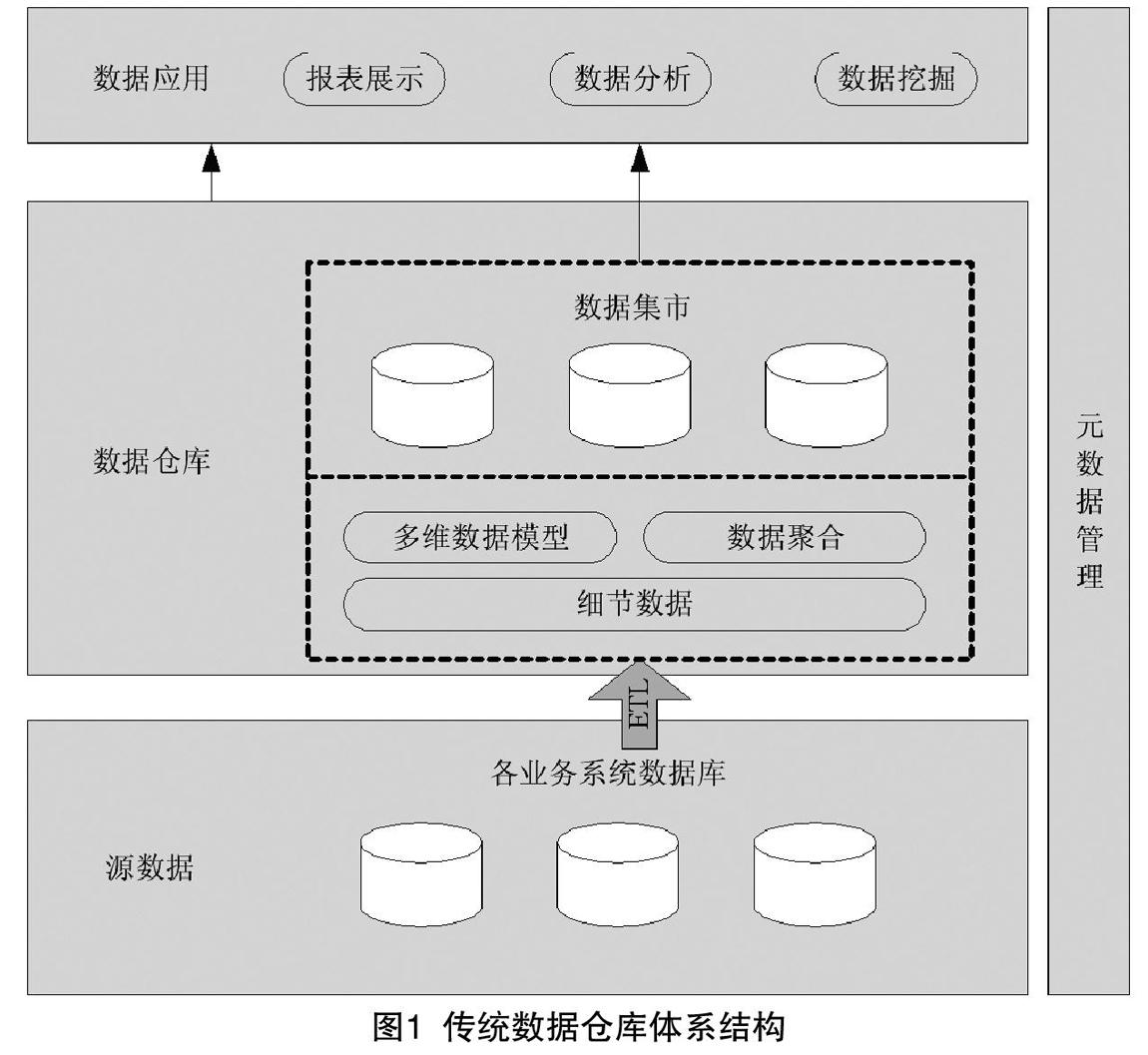
数据仓库是以数据库技术为核心,涉及元数据、数据挖掘、数据展现等多技术领域的综合应用[10]。传统数据仓库按层次划分,主要包含源数据层、数据仓库层、数据应用层三部分。传统数据仓库体系结构如图1所示。
(1)源数据层。传统数据仓库的数据来源主要是从各个业务系统抽取的数据。按照数据仓库数据结构和编码格式对源数据进行抽取、清洗、转换和加载。
(2)数据仓库层。传统数据仓库主要存储的是经过ETL(Extract /Transformation /Load)处理后的结构化数据,且是按照数据的主题进行分类存储。主要的存储方式包括:多维数据库、关系型数据库及两者相结合的方式[2]。传统数据仓库基于维护细节数据基础,使其能够真正应用于分析。聚合数据指的是基于特定需求的简单聚合,多维数据模型提供了多角度多层次的分析应用,可以实现在各时间维度和地域维度的交叉查询[3]。除此之外,数据仓库中还存储元数据,描述数据仓库的数据信息及辅助用户使用和了解数据仓库的数据信息。
(3)数据应用层。数据应用层的核心是联机分析处理OLAP(On-Line Analysis Processing),主要包含报表展示、数据分析和数据挖掘,为决策者提供多维度数据[9]。联机分析处理从多维度、多角度对数据进行分析,系统深入挖掘数据背后的关联,从而辅助用户决策。
(4)元数据管理。元数据能支持系统对数据的管理和维护,是进行数据集成的基础,主要存储了原始数据和数据仓库中数据的对应关系以及校验、转换、过滤的规则等信息[4]。元数据是建设数据仓库必需的最主要、最根本和最基础的描述元素[12]。通过对元数据的统一维护,可以实现各业务信息系统之间信息交互,避免出现“数据孤岛”现象。另外,元数据提供了数据访问的接口,帮助进行数据检索和数据挖掘。
1.2 存在的主要问题
(1)传统数据仓库架构基本以三层架构为主,采用单点服务器结构,一方面,对分布式并行计算模式的支持力度不够,难以实现处理能力水平拓展,往往需要通过对服务器等硬件的升级改造来实现处理性能提升,升级改造成本相对较高,且服务器等硬件性能升级周期较长[5]。另一方面,采用单点服务器结构经常会遇到单点故障和I/O處理性能瓶颈等问题,计算能力和存储能力相对较弱。
(2)由于地域、型号等因素影响,数据应用系统种类繁多、形式多样,在单个数据仓库系统处理性能有限的状况下,普遍存在独自建设,导致“烟囱”式建设现象严重,缺乏统一的顶层设计和筹划规划,各个数据仓库系统间界限划分不合理,口径不一致,存在数据的重复加工问题。
(3)传统数据仓库主要面向数据分析型应用设计,在数据的实时处理方面不足,无法适应高并发、低延迟等应用场景需要,难以满足实时分析处理需求。
(4)传统数据仓库主要处理的是结构化数据,通过从各类关系型数据库系统抽取数据实现数据集成。在大数据背景下,非结构化数据、半结构化数据大量出现,占到数据总量的90%以上,传统数据仓库架构不支持HBase、NoSQL等数据库,在处理各类非结构化数据和半结构化数据方面能力不足,不能实现对各类数据的完全覆盖。
2 数据特征及新处理需求
随着数据采集方式的多样化,数据积累体量将呈指数级增长,传统的存储手段、计算能力已经不能满足海量数据的存储和分析。此外,云计算、大数据等相关技术快速发展,数据的存储和分析能力得到了前所未有的提升,通过海量数据处理、多样本分析、超实时计算和复杂模型解算实现数据价值深度挖掘、开发各类数据产品已经成为对数据处理的新需求。
大数据时代,数据处理的模式主要包括:“离线批处理式数据处理”,“查询式数据处理”以及“实时式数据处理”三种模式[7]。按照以上数据处理模式,基于大数据的数据仓库采用Hadoop/Spark架构,可以有效弥补传统数据仓库在海量数据处理、数据存储等方面的不足,有效解决传统数据仓库平台处理能力不足的问题。基于大数据技术构建的数据仓库可以实现弹性扩容和资源隔离,缩短统计分析响应时间,通过统一资源调度管理平台,减少数据复制导致的时间开销和多个应用数据库独立部署带来冗余的数据存储成本。另外,可以实现对数据的有效管控和数据标准的实施,实现数据质量管理。Hadoop是一个开源的、可运行于大规模集群之上的分布式计算平台,通过实现MapReduce计算模型和分布式文件系统HDFS(Hadoop Distributed File System),并且可以通过横向扩展实现计算能力和存储能力的大幅提升,可以实现对离线的、处理实时性要求不高的海量数据的存储与处理分析工作[8]。Spark是基于内存计算的大数据并行计算框架,可以有效减少迭代计算时的I/O开销,实现对数据的实时分析和处理。
3 基于大数据的数据仓库体系架构设计
基于大数据的数据仓库体系架构采用柔性架构设计理念和分层设计思想,综合运用Hadoop/Spark为代表的大规模数据处理技术和传统数据仓库的特点,采用组件化、模块化、服务化的方式进行设计,体系结构的主要内容以及相互之间的逻辑关系如图2所示。
(1)数据源部分。目前,试验数据应用领域,已建成的信息系统主要采用Oracle、SqlServer、基础数据库,除此之外,与相关的文档、模型数据、音视频数据、图片数据等,大多数以非结构化或半结构化数据形式存在。相比传统数据仓库体系结构而言,基于大数据的数据仓库不仅能实现对结构化数据的处理,还能实现对半结构化及非结构化数据的处理。
(2)数据融合部分。分为两部分,对于关系型数据,按照主题数据库的分类进行抽取、转换,加载到主题数据库中。对于非关系型数据,按照指定的元数据、数据结构、数据编码、数据定义、键结构和数据物理特征等进行数据抽取和转换,加载到主题数据库,为后续的统计、分析、挖掘业务提供标准化、规范化的数据资源。
(3)数据存储部分。主题数据库中按照不同的主题对数据进行分类存放,主题数据库为数据仓库提供数据来源。数据仓库采用Hadoop和Spark统一部署模式架构,具有高模块化、松耦合特点,利用其先进的并行计算框架和资源调度框架,弥补传统数据库的局限,支持SQL标准数据库语言及Oracle、DB2、MySQL、SQLServer等多种传统应用数据库。MapReduce、Spark在资源管理框架YARN之上部署和运行,可以有效实现计算资源按需伸缩、共享底层存储,避免数据跨集群迁移。根据不同应用场景,实现资源调度和数据处理工作。对于据数据处理速度及分析响应要求高的数据处理场景,采用Spark处理架构实现实时处理,对于数据处理速度及分析响应要求不高的数据处理场景,采用MapReduce架构实现批处理。Sqoop组件主要用来实现Hadoop和主题数据庫之间的数据交换,完成关系型数据库到Hadoop平台的数据迁移工作。
(4)服务管理部分。实现对各种服务的管理,主要包括数据分析服务、数据查询服务、数据交换服务和数据服务接口,以组件化、模块化的方式,为实现数据挖掘分析及综合展现提供服务支持。
(5)数据应用部分。主要包含数据查询、数据分析、数据挖掘、OLAP等数据应用,并将查询及挖掘结果以图表、仪表盘等可视化方式进行展现。
(6)元数据管理部分。元数据(Meta Date),即数据的数据。主要描述数据仓库中各种模型的定义、各层级间的映射关系、数据仓库的数据状态信息,通过元数据库实现统一存储和管理。
4 结语
长期以来,由于在数据融合、数据挖掘等方面缺乏必要的技术手段支持,数据的效益没有得到有效发挥。本文通过分析传统数据仓库在处理大数据方面的不足,结合大数据时代数据处理的新需求,研究构建基于大数据技术的数据仓库体系结构,以期实现数据的高效管理和快速处理分析。
参考文献
[1] 吴黎兵,邱 鑫,叶璐瑶,等.基于Hadoop的SQL查询引擎性能研究[J].华中师范大学学报(自然科学版),2016,50(2):174-182.
[2] 瞿志凯,张婷.基于大数据的反恐情报数据仓库体系结构设计[J].情报杂志,2016,35(2):30-36.
[3] 费仕忆.Hadoop大数据平台与传统数据仓库的协作研究[D].上海:东华大学,2014.
[4] 张鹤.元数据在图书馆信息管理中的应用研究[J].北京印刷学院学报,2017,25(4):60-62.
[5] 赵毅.基于大数据平台构建数据仓库的研究与实践[J].中国金融电脑,2017(05):37-42.
[6] 龚昕,周大庆,鞠亮,等.武器数据工程理论与实践[M].北京:国防工业出版社,2017:20-30.
[7] 李贞强,陈康,武永卫,等.大数据处理模式—系统结构,方法以及发展趋势[J].小型微型计算机系统,2015,4(4):641-646.
[8] 林子雨.大数据技术原理与应用[M].北京:人民邮电出版社,2017:184-187.
[9] 宁兆龙,孔祥杰.大数据导论[M].北京:科学出版社,2017:34-40.
[10] 于鹃.数据仓库与大数据融合的探讨[J].电信科学,2015,66(1):66-71.
[11] 王缓缓,郭敬义,张警灿,等.基于Hadoop的数据仓库构建模式研究[J].重庆理工大学学报(自然科学版),2015,29(7):69-73.
[12] 党怀义.典型大数据仓库-飞行试验数据仓库设计[J].计算机测量与控制,2015,23(4):1407-1413.
Research on Data Warehouse Architecture Based on Big Data Technology
YAO Peng-fei
(Army of 92493,Huludao Liaoning 125000)
Abstract:In the age of big data,the complexity of data structure and the sharp increase of data volume make the traditional data warehouse architecture connot meet the needs of data processing.This paper is based on the theoretical research of traditional data warehouse architecture, shortcomings of traditional data warehouse architecture and characteristics of data and new requirements for data process are emphatically analyzed,the system architecture of data warehouse based on big data technology is constructed,adopt the currently popular hadoop/spark big data process technology architecture,realizes the collection,processing,storage ,analysis and mining of semi-structured and unstructured data , makes up for the deficiency of traditional data warehouse in mass data processing and storage,this way can solve the problem of low utilization of data and unobvious value.
Key words:big data;data warehouse;architecture
猜你喜欢
自然资源信息化(2019年4期)2019-03-29
电子制作(2016年15期)2017-01-15
山东工业技术(2016年15期)2016-12-01
系统工程与电子技术(2016年4期)2016-08-24
现代防御技术(2016年1期)2016-06-01
海军航空大学学报(2015年1期)2015-11-11
中国教育信息化(2015年10期)2015-08-23
空间控制技术与应用(2015年4期)2015-06-05
