
混合分层抽样与协同过滤的旅游景点推荐模型研究
2019-06-15 02:13:56李广丽张红斌
数据采集与处理 2019年3期
李广丽 朱 涛 袁 天 滑 瑾 张红斌
(1.华东交通大学信息工程学院,南昌,330013;2.华东交通大学软件学院,南昌,330013;3.武汉大学计算机学院,武汉,430072)
引 言
随着互联网的不断发展,网络上的数据快速增长,人们正逐渐从信息匮乏的时代步入“信息过载”时代,此时,无论是信息消费者(网站用户)还是信息生产者(网站管理者)都面临很大的挑战。基于互联网搜索旅游信息已成为人们在出游前获取信息的最主要渠道之一。然而,伴随大量旅游网站的出现,人们常常被淹没于海量信息的搜索之中,却无法获取有价值的信息。推荐模型(系统)是解决“信息过载”问题,进而提升信息价值的有效方法。据统计,约有四分之三的旅游者在出游前都会搜索并查看旅游评论信息,以更好地规划他们的行程。
推荐模型可追溯到认知科学[1]、近似理论[2]以及信息检索[3]等领域的扩展研究。在20世纪90年代中期,推荐模型作为一门独立的学科被广泛关注,研究者主要从事具有显式评分的推荐问题研究,而推荐问题则转化为用户对未知物品的评分预测问题:基于用户历史评分,获取对物品的预测评分,进而向用户推荐评分最高的物品。目前,常用的推荐模型分三类:基于内容的推荐、协同过滤推荐和融合过滤。其中,协同过滤推荐的优势主要在于其能处理复杂的非结构化对象,且不需要领域知识就可以发现用户的新兴趣,同时推荐的个性化程度也较高。
“协同过滤”的概念由Goldberg等[4]提出,并应用于Tapestry系统,该系统仅适用于较小用户群,且对用户有较高要求(如用户要显式地给出评价)。作为协同过滤推荐模型的雏形,Tapestry展示了一种新的推荐思想,但它并不适合Internet环境。此后,出现了基于评分的协同过滤推荐模型。Resnick等[5]提出基于评分的协同过滤推荐模型GroupLens,向用户推荐新闻和电影。GroupLens的基本思想:分析用户偏好以形成推荐。它采集用户评分,评分值为1~5的整数,分值越大表明用户的偏好度越高。它通过计算用户间的评分相似性,选出相似性较高的一组用户来预测新用户对新物品的偏好。Konstan[6],Miller等[7]扩展GroupLens,使其成为一个基于开放式架构的分布式系统。自GroupLens之后,协同过滤理论取得较快发展,国际顶级会议、期刊发表的相关论文也逐年增加:Kim等[8]将社会网络分析(Social network analysis,SNA)与聚类技术相结合,通过反射隐藏的、用户社会群体的信息来提高推荐模型的预测精度;Nilashi等[9]利用分类与回归树(Classfication and regression tree,CART)和期望最大化(Expectation maximum,EM)等算法提出一种新的推荐方法。目前,大量Web网站也开始应用协同过滤算法向用户推荐个性化信息,如Amazon,Netflix和Last.Fm等,其中,Amazon对协同过滤推荐模型的研究已有十余年,借助推荐模型,Amazon收获了巨大的经济效益。此外,Video Recommender[10]和Ringo[11]也被认为是第一批能够进行自动预测的协同过滤推荐模型。
本文围绕旅游景点推荐这一热点问题展开研究,采用问卷调查与自动抓取相结合的方式,采集并制作涵盖若干属性维度的、全新的“智慧旅游”数据集。继而对其作分层抽样统计,获取用户的旅游喜好信息。最后,根据用户评分,设计基于用户聚类的协同过滤推荐算法,并融合旅游喜好信息,生成高质量的混合推荐结果。本文模型简单、有效,具备较高实用价值,它对于旅游景点推荐模型的开发与应用具有重要的借鉴意义。
1 旅游景点推荐模型设计
1.1 基本原理
协同过滤推荐模型指:分析其他用户已评分的物品(本文指旅游景点)来预测目标用户对某类物品的偏好程度(兴趣)。因此,景点z对用户u的效用ef(u,z)取决于景点z对与u评分行为相似的其他用户ui∈U(用户集合)的相关效用ef(ui,z)。在旅游景点推荐过程中,协同过滤算法先要找出那些与用户u在旅游景点上兴趣相同的用户(即对同一旅游景点评分相似的用户)。然后,将这些用户喜好的景点推荐给用户u。故用户相似性度量是协同过滤算法的关键所在。综上分析,混合分层抽样与协同过滤的旅游景点推荐模型包括用户数据采集、分层抽样、用户聚类以及协同过滤并产生推荐等几大核心部件,系统框架如图1所示。

图1 混合分层抽样与协同过滤的旅游景点推荐模型Fig.1 Recommendation model of tourist attractions based on hierarchical sampling and collaborative filtering
首先,设计调查问卷以收集人们的旅游喜好信息,并对其做分层抽样统计;其次,设计抓取规则,在“携程网”自动采集用户对不同旅游景点的评分,并对数据做预处理:用0~5表示用户对旅游景点的满意度(0分最低,5分最高);再次,采用K-means聚类算法处理用户数据,产生k个聚类中心,以刻画用户兴趣所属类别;基于协同过滤算法计算目标用户与各聚类中心的语义相似性,预测用户评分,形成预推荐列表LA。最后,混合分层抽样结果输出的预推荐列表LB,生成旅游景点的混合推荐列表“LA+LB”。
1.2 “智慧旅游”数据集建立
“智慧旅游”数据集的建立分3步:问卷调查、自动抓取和数据汇总。问卷采用“问卷星网”[12]制作,主要用于收集用户的旅游喜好信息,问卷中包括:用户性别、地区、年龄、学历、工作性质和月收入等基本信息及“出游季节”“兴趣类别”“出游方式”等旅游喜好信息;自动抓取通过规则抓取“携程网”上的景点图像、用户评分等信息:进入旅游景点用户点评页面,抓取用户对旅游景点的评分及景点图像,制作出涵盖“用户评分”“用户统计信息”“景点图像”等在内的数据集。最后,汇总调查问卷结果与自动抓取的数据,生成“智慧旅游”数据集。
1.3 基于分层抽样模型的用户喜好信息分析
分层抽样模型按规定比例从不同层中随机抽取样品。它按照一定规则将目标分成num个互不相交的子集。然后,在每个子集中独立抽样。每个子集称为层(E1,E2,…,Enum),num个层合起来就是总体分布

第1步:引入目标随机变量,以反映不同人群旅游兴趣的差异,目标随机变量有多个,如“出游季节”、“出游目的地”和“出游方式”等;
第2步:目标总体分层,把影响因素λ(如性别、地区等)作为分层原则,将旅游人群E根据其属性分为num层,第i(i=1,2,…,num)层中有Ei个人;
第3步:确定各层人数,若总体抽样人数为M,分num层抽样,第i层的人数为Ei,对于第i层的抽样人数:Xi=M*Ei/E,其中i=0,1,2,…,num。
分层抽样模型根据目标总体的特征分布对其作层次化分类,以降低层内差异并增大层间差异,从而提高分类精度,更准确、客观地捕获用户的喜好信息。
1.4 基于K-means算法的用户聚类
聚类分析是把数据对象划分成若干子集的过程。每个子集是一个簇,簇中对象彼此相似,而与其他簇中对象不相似。簇的集合称作一个聚类。常用聚类算法可分为层次聚类和非层次聚类。K-means算法属于非层次聚类,它给定一组观测值(a1,a2,…,an),每个观测值是一个d维向量,聚类算法将n个观测值划分成t(≤n)个集合S=(S1,S2,…,St),以减少集合内的平方和(方差),即
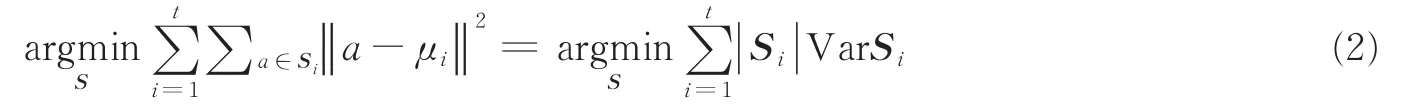
式中:μi是Si中点的平均值,VarSi表示Si的方差。
令用户集合是U=(u1,u2,…,um)的矩阵,评分景点集合是Z=(z1,z2,…,zn)的矩阵,用户-景点评分矩阵是G,G中dij表示用户集合U中第i个用户对景点集合Z中第j个景点的评分,故用户基本信息矩阵为S=(U,Z,G)。执行K-means聚类的前提:确定聚类数k和选定初始聚类中心。在收集用户数据时,根据景点性质将60个评分景点划分为k(5≤k≤10)个类别,每种类别各选1个典型用户(共k个)作为初始聚类中心,以完成K-means聚类。
算法1基于K-means算法的用户聚类
输入:用户聚类数目k、用户基本信息数据源S=(U,Z,G)、迭代次数iter_num
输出:用户聚类中心矩阵D

用户聚类中心D是k行n列的矩阵,k代表k个用户聚类中心,n表示景点数。故D中第i行、第j列元素Dij表示第i个聚类中心中所有用户对景点j的评分均值。
采用式(3)计算用户之间的相似性。即基于皮尔逊相关系数度量用户之间的语义相关性

式中:r表示用户评分;分别表示用户x和用户y对景点的平均评分;Sxy表示用户x和y共同评分的景点集合,即
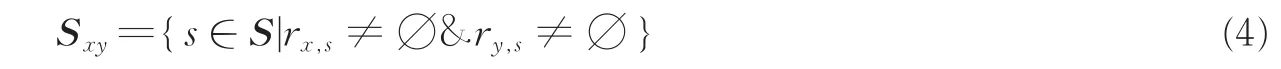
1.5 基于用户聚类的协同过滤推荐算法
聚类算法输出用户聚类中心,即可计算目标用户与各聚类中心的相似性,从而得出目标用户的最近邻居,并对景点进行评分预测,最终输出预推荐列表。令给定目标用户c及最近邻居集合KSc时,对新旅游景点的评分预测[13]计算公式为
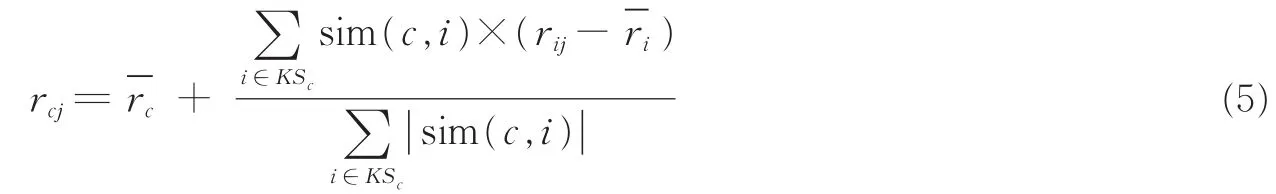
算法2基于用户聚类的协同过滤推荐算法
输入:目标用户的景点评分矩阵R,用户聚类中心矩阵D
输出:用户预测评分矩阵D′、预推荐列表LA
1.根据目标用户的景点评分R和用户聚类中心矩阵D,采用式(3)计算目标用户与各聚类中心的相似性
2.假设当前用户为u,初始化使其最近邻集合为空,即KS(u)=∅
3.选择聚类中心内与用户u相似性最高的用户,并放入最近邻集合KS(u)中,此时KS(u)≠∅
4.重复第3步,直到所有的相关用户都被加入到KS(u)中
5.根据KS(u)中用户相似性大小,对集合中所有用户作降序排序,并将排序中的前l项作为用户u的最近邻KS(u)
6.根据式(5)计算评分预测矩阵D′,并按照降序排列,取前v项生成预推荐列表LA
7.计算模型的RMSE值和MAE值,以评估推荐性能
2 实验结果及分析
2.1 数据集
“智慧旅游”数据集中的评论信息采集自“携程网”,共抓取了60个景点、5 000个用户的评分数据,可将60个景点分为8个类别(实验中也进行了验证),分别是:海滨海岛、世界遗产、祈福拜佛、邮轮之旅、古镇游玩、亲子游、养生休闲和民俗体验。随机选取4 000个用户(80%)数据作为训练集,剩余1 000个用户(20%)数据作为测试集。数据集详见网址:https://drive.google.com/drive/mydrive?tdsourcetag=s_pctim_aiomsg。此外,编写调查问卷,基于Web吸引2 170位游客随机完成调查,收集用户基本信息,以完善“智慧旅游”数据集。最后,对评分数据进行预处理:将用户评分中的“很满意”“满意”“一般”“不满意”“很不满意”分别用“5”“4”“3”“2”“1”5 个离散值表示。此外,用户的性别、地区、年龄、学历、工作性质和月收入等基本属性(详见表1)也进行相似的数字化处理,以便于后续实验。
2.2 分层抽样结果分析
采用1.3节的分层抽样模型对2 170位游客的调查答卷进行统计分析:从游客的性别、地区、年龄、学历、工作性质和月收入等方面对游客旅游兴趣进行分层抽样,各用户属性中随机抽出1 000名游客作为抽样代表,得到游客旅游兴趣的分层抽样统计表,如表1所示(用户偏好最大值用黑体加下划线给出),同时根据表中结果生成预推荐列表LB。
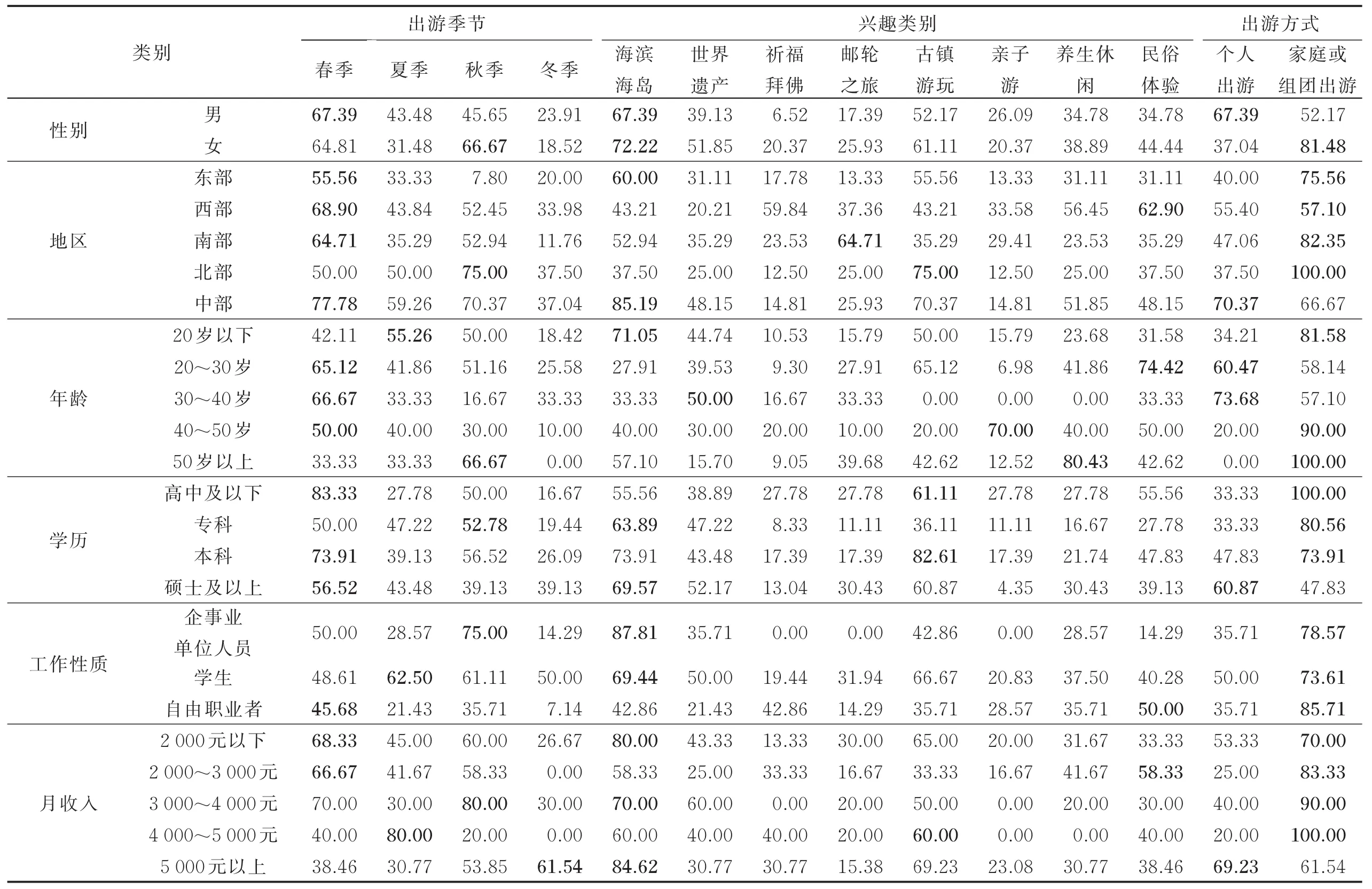
表1 游客的旅游兴趣分层抽样统计表Tab.1Hierarchical sampling statistics of tourist interest%
由表1可以发现很多有趣的结论,这些结论与人们的客观认知较吻合:
(1)大部分受访人群更偏爱于春、秋季出行,这应该缘于中国大部分地区在春、秋两季的风景非常吸引人;
(2)大部分人群更注重于“家庭或组团出游”,这源于中国人强烈的家庭观念,即以家庭为单位出行,其乐融融;
(3)中老年人更偏爱于“养生休闲”类景点,这类景点对个人体力没有过高要求,即休闲、旅游两不误,非常适合中老年人;
(4)学生团体更愿意夏季出游,因为,中国的7,8月份是暑假,故各类围绕大、中、小学生的旅游活动、暑期项目非常普遍;
(5)中、东部地区游客更喜欢“海滨海岛”,南方地区游客更青睐“邮轮之旅”,西部地区游客乐于“民俗体验”,而北方游客则倾向于“古镇游玩”,这与各地区游客的生活习惯、地理环境等都密不可分;
(6)男性受访者倾向于“个人出游”,而女性受访者则更喜欢“家庭或组团出游”。
2.3 聚类实验结果分析
用户聚类是本文模型的核心,故需先评判聚类算法对推荐性能的影响。人们常通过预测用户对被推荐物品的评分来评判推荐性能。均方根误差(Root mean square error,RMSE)、平均绝对误差(Mean absolute error,MAE)是目前应用最广泛的评判评分精度的指标。本文利用RMSE,MAE对推荐模型作评测。若给定测试数据集T、用户-景点组合(u,z)、用户真实评分ruz及推荐模型的预测评分。预测评分和真实评分之间的RMSE和MAE分别为
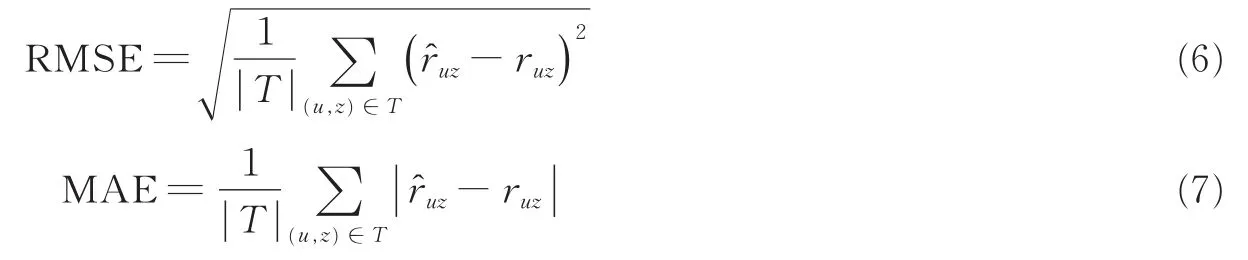
由式(6,7)可知:RMSE,MAE分别计算预测评分和真实评分之间的均方根误差、平均绝对误差。RMSE、MAE值越小,推荐性能越好。实验时把60个旅游景点划分成k(5≤k≤10)类,然后分别执行K-means聚类、层次聚类和模糊聚类等多种算法。接着,结合协同过滤算法完成旅游景点推荐,计算各算法在选取不同k值时所获取的RMSE和MAE值,实验结果如图2所示。
由图2可知:RMSE和MAE的变化趋势非常相似,这表明RMSE,MAE的评判本质很接近,它们可以同时使用,以综合评判推荐性能。然而,由于惩罚力度更大,RMSE结果的震荡幅度相对也更大;显然,K-means算法的性能优于其他两类算法。综合RMSE和MAE值,当聚类数目k=8时,K-means算法的推荐效果最好(这与人工设置吻合)。故选取K-means算法并设置聚类数k=8完成后续实验。
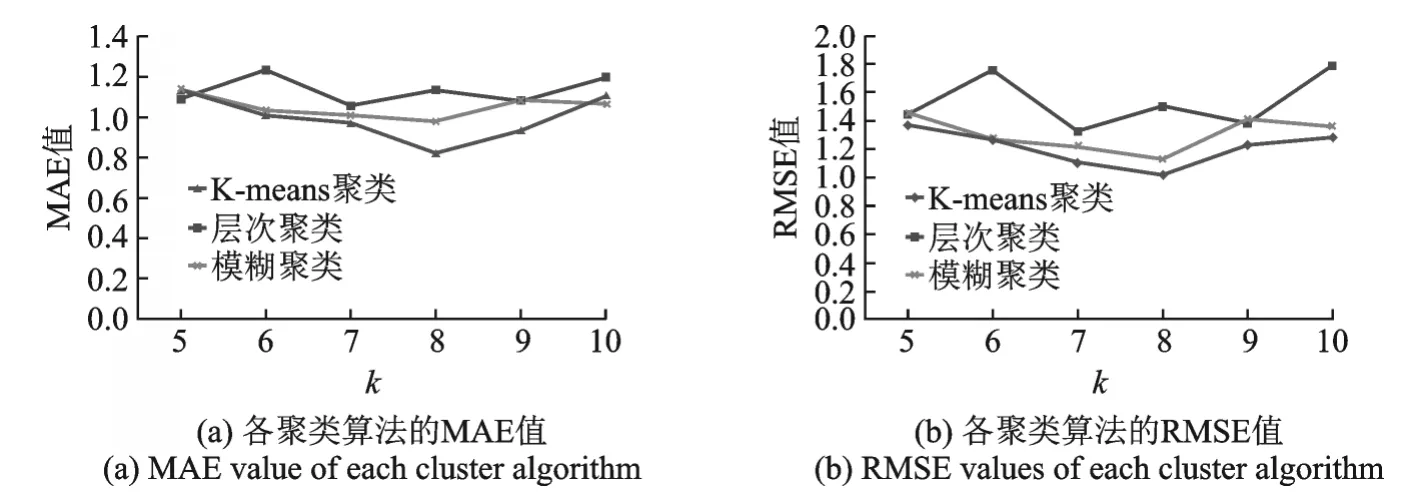
图2 各聚类算法在选取不同聚类数时的RMSE和MAE值比较Fig.2 RMSE and MAE values of each cluster algorithm by setting different clustering numbers
2.4 预测评分实验结果分析
本文选取基于模糊聚类的协同过滤算法、基于层次聚类的协同过滤算法实验,同时与基于用户的协同过滤(User-based collaborative filtering,UBCF)算法[14]、基于项目的协同过滤(Item-based collaborative filtering,IBCF)算法[15]以及基于杰卡德相似系数的推荐算法(LBCF)[16]等基线进行RMSE,MAE值比较,其中最近邻居值l=10。实验结果如图3所示。
由图3可知:本文算法的RMSE值与UBCF,IBCF和LBCF相比分别降低了61.0%,64.9%和59.4%,而与模糊聚类和层次聚类两算法相比分别降低11.5%和47.3%;其次,本文算法的MAE值与UBCF,IBCF和LBCF相比分别降低47.7%,34.1%和28.3%,与模糊聚类和层次聚类两算法相比也分别降低18.8%和37.9%。这表明:本文提出的协同过滤推荐算法能在一定程度上提高评分预测的精度,这有利于更好地生成旅游景点推荐列表,进而准确拟合用户的旅游偏好(兴趣)。主要原因分析:(1)“智慧旅游”数据集中良好的景点分类机制:8个类别、60个景点,聚类算法实验中也较好地验证了这一机制;(2)合理地选择聚类数(8个)及初始聚类中心(典型用户),并完成基于K-means的用户聚类。在聚类结果中,类内相似度较高,而类之间相似度较低;(3)皮尔逊相关系数(式(3))能较好地刻划用户之间的语义相关性。

图3 不同算法的RMSE和MAE值Fig.3 RMSE and MAE values of different algorithms
2.5 混合推荐结果分析
1.3节提出应用分层抽样模型获取用户的旅游喜好信息,将该算法命名为Our_HS。根据专家经验及交叉验证,设置各用户属性指标的相对重要性,即利用主观赋权评价法[17]对分层抽样结果设定权重。其中性别:5.1%;地区:13.75%;年龄:19.44%;学历:13.75%;工作性质:10.91%;月收入:37.06%,各项之和为100%,以建立Our_HS。此外,1.4节、1.5节提出基于用户聚类的协同过滤算法,该算法命名为Our_CF。由分层抽样结果可知(表1),用户属性不同,其旅游兴趣会有较大差异,而这些兴趣是提升推荐性能的重要依据。因此,本节混合协同过滤算法(Our_CF)输出的预推荐列表LA与分层抽样模型(Our_HS)输出的预推荐列表LB,生成混合推荐列表,该算法命名为Our_Mixed。
准确率(Precision)和召回率(Recall)这两个指标常被用来全面地评测推荐性能。而要计算这两个指标,先要确定被推荐的景点属于表2中的哪种情况。在表2中,“True-positive(tp)”表示被推荐且用户喜好的景点;“False-positive(fp)”表示被推荐用户却不喜好的景点;“False-negative(fn)”表示未被推荐且用户喜好的景点;“True-negative(tn)”表示未被推荐且用户不喜好的景点。

表2 被推荐景点的分类情况Tab.2 Classification resultsofeach recommended item
基于表2的定义,可得到准确率和召回率的计算公式为


式中:#tp表示被推荐且用户喜好的景点总数;#fp表示被推荐且用户不喜好的景点总数;#fn表示未被推荐且用户喜好的景点总数。假设给用户推荐N′个旅游景点,本节比较IBCF,UBCF,LBCF和Our_CF(协同过滤算法)、Our_HS(分层抽样模型)、模糊聚类、层次聚类以及Our_Mixed(混合推荐)等算法的准确率与召回率,并引入AP指标综合度量各算法优劣,即有

式中:index表示准确率/召回率值,N′=10。具体实验结果如表3和表4所示,每行最优值用黑体标出。
由表3可知:N′=1时,UBCF的准确率最高,即推荐少量旅游景点时,UBCF的效果较好。但推荐更多旅游景点时,由于用户评分的稀疏性越来越高,UBCF的效果逐渐降低。相反,Our_Mixed充分利用用户的旅游喜好信息,当N′≥2时,其推荐性能较优,且准确率稳步提高。Our_Mixed的AP值较同行的次优指标提升(9.678-8.461)/8.461≈14.38%,即在混合推荐时,LA与LB这两个推荐列表有良好的互补性。基于AP值,所有模型的推荐性能(准确率)降序排列:Our_Mixed> Our_CF>Our_HS>模糊聚类>层次聚类>UBCF> LBCF>IBCF,Our_CF优于Our_HS,这说明:Our_HS、Our_CF算法的性能优于传统方法,而分层抽样模型输出的用户喜好信息在旅游景点推荐中发挥了重要作用。
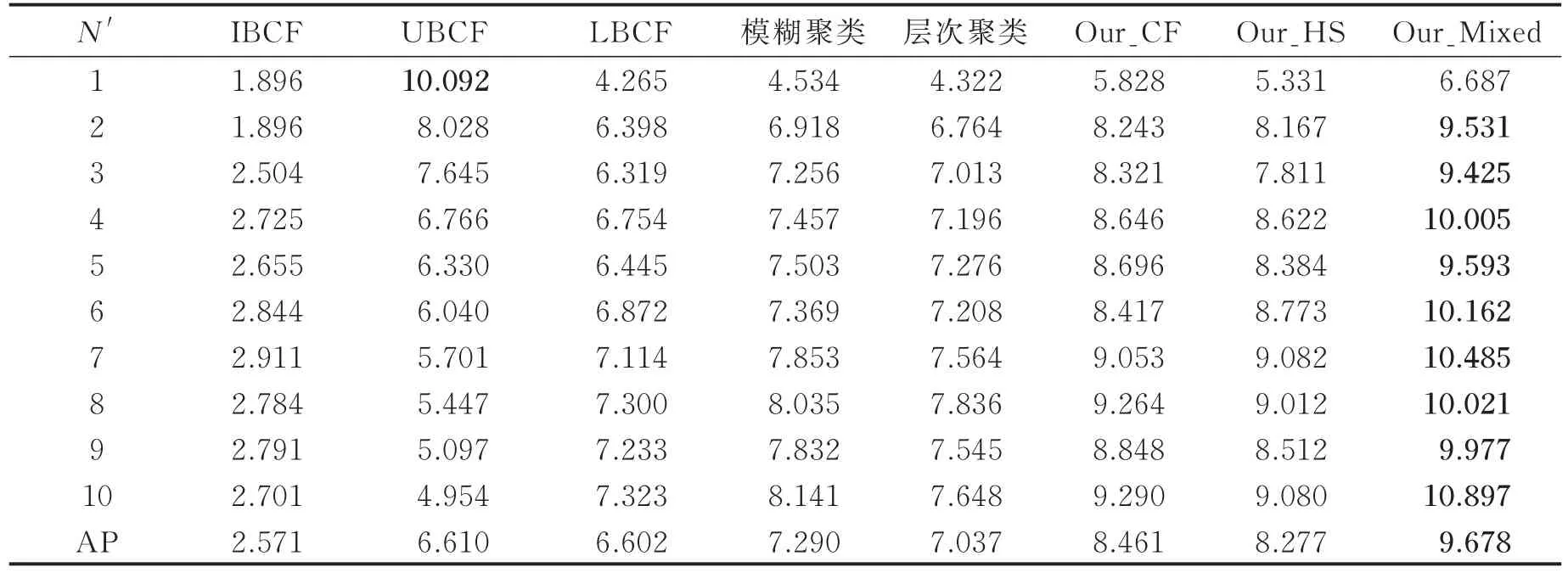
表3 各算法在不同N′下的Precision值Tab.3 Precision values of different algorithms under different N′ %

表4 各算法在不同N′下的Recall值Tab.4 Recall values of different algorithms under different N′%
由表4可知:当推荐更多旅游景点时,用户之间单一的相似性度量不能完全代表用户喜好,这迫切需要融入用户的旅游喜好信息。混合推荐的效果表现更佳,且召回率稳步提高。Our_Mixed的AP值较同行的次优指标提升(3.958-2.989)/2.544≈32.4%,这进一步说明LA与LB之间具有良好的互补性。基于AP值,所有模型的推荐性能(召回率)降序排列:Our_Mixed>Our_CF>Our_HS>模糊聚类>层次聚类>LBCF>UBCF>IBCF,Our_HS优于传统算法,这也表明分层抽样模型输出的用户喜好信息在推荐中的重要性。混合分层抽样与协同过滤的旅游景点推荐模型能获取更优的推荐性能,这有助于提升旅游网站的影响力与竞争力。
2.6 算法的时间复杂度
除上述评测方式外,时间复杂度也是评价推荐模型优劣的一个重要指标。本节分析基于用户聚类的协同过滤算法的时间复杂度,并与传统算法进行比较。
传统的UBCF算法需要查找用户共同评分的景点,假设用户u1偏好景点z1和景点z2,用户u2偏好景点z1,则算法可能会将景点z2推荐给用户u2。若用户数量多,需逐个查找用户共同评分的景点。若有m个用户、y个景点,该算法时间复杂度为O(m×y),m和y属于同一数量级且m>y,则该算法的时间复杂度近似是O(m2)。
传统的 IBCF 算法中,令用户集合是U=(u1,u2,…,um)的矩阵,评分景点集合是Z=(z1,z2,…,zn)的矩阵,计算景点相似矩阵时,任意两个景点都要计算其相似性,其时间复杂度为O(mn2)。向目标用户推荐时,先根据景点相似矩阵对景点的n个相似度排序,找出最近邻,故其时间复杂度为O(nlogn),然后通过景点的l个最近邻产生推荐,其时间复杂度是O(mn2)+O(nlogn)+O(l)。
而基于用户聚类的协同过滤算法仅需计算用户与各聚类中心的语义相似性。若有k个聚类中心,m个用户,该算法的时间复杂度是O(k×m)。由于k≪m,它们不属于同一数量级,则该算法的时间复杂度近似是O(m)。从时间复杂度衡量,本文算法优于UBCF及IBCF。
3 结束语
在旅游网站上,人们常常无法快速地找到感兴趣的旅游信息。因此,本文围绕推荐模型在旅游网站中的应用这一热点问题建立全新的“智慧旅游”数据集。提出混合分层抽样与协同过滤的推荐模型,其中,设计基于用户聚类的协同过滤算法,以计算目标用户与聚类中心的相似性,完成高质量的旅游景点推荐。实验表明:混合分层抽样与协同过滤的旅游景点推荐模型能够有效地提升推荐精度,并降低算法时间复杂度。这对于面向旅游景点的推荐模型的设计及应用都具有重要的借鉴意义。
未来主要工作:(1)结合景点的图像内容对用户建模,以弥补仅依赖用户评分的聚类方法;(2)运用Relative Attribute模型[18]进一步分析用户旅游兴趣的程度变化,更有针对性地推送景点信息;(3)运用深度学习模型[19]抽取图像、文本特征,并刻划用户特性,以改善推荐性能。
猜你喜欢
阅读与作文(小学高年级版)(2021年9期)2021-09-09 20:25:40
少年博览·小学低年级(2020年10期)2020-11-06 07:32:53
意林·全彩Color(2018年7期)2018-08-13 09:35:24
电子测试(2017年15期)2017-12-18 07:19:27
小学生时代·大嘴英语(2017年8期)2017-08-09 21:48:14
海外星云(2016年7期)2016-12-01 04:18:07
智能系统学报(2015年4期)2015-12-27 09:38:39
Coco薇(2015年11期)2015-11-09 13:19:52
股市动态分析(2015年12期)2015-09-10 13:50:31
电子设计工程(2015年6期)2015-02-27 12:04:53
