
基于加权信息量的地质灾害易发性评价
——以四川省泸定县为例
2019-06-14 09:18梁丽萍刘延国唐自豪李景吉
水土保持通报 2019年6期
梁丽萍, 刘延国, 唐自豪, 邹 强, 李景吉
(1.成都理工大学 地球科学学院, 四川 成都 610059; 2.成都理工大学 生态环境学院, 四川 成都 610059;3.西南科技大学 环境与资源学院, 四川 绵阳 621010; 4.中科院 山地灾害与环境研究所, 四川 成都 610041)
地质灾害易发性评价是以基础地质条件为出发点,考虑致灾体内在控制因素从而评估地质灾害在区域内某个空间发生的可能性大小[1]。美国数学家Shannon[2]最早提出了“信息量法”的概念,并在概率论知识和逻辑推理方法的基础上,推导出了信息量的计算公式。随着信息量法不断完善,其运用到地质灾害易发性评价中被众多学者接受。随着3S技术的快速发展,研究者更多的在基于GIS的基础上对地质灾害进行易发性评价,现在已经成为重要的有效工具。众多研究者在易发性评价中根据研究区的特殊条件,构建了不同的评价体系并且进行了很多模型上的尝试。目前,主要的方法模型有逻辑回归法,信息量法,确定性系数法、贡献权重叠加模型、支持向量机法、BP神经网络模型、随机森林模型等[3-11]。近年来,研究者不仅仅注重单一模型的选取,更多的研究者对不同的模型进行对比以及重新组合。其中由于信息量是一种比较可以客观的统计分析方法,在地质灾害易发性的评价中常常和确定系数法、层次分析法以及逻辑回归方法等方法结合,赋予客观评价因子不同的权重,从而结合成加权信息量模型[12-13]。本文采用确定性系数法和信息量法结合对研究区进行了地质灾害易发性分析。
1 研究区域及数据源
1.1 研究区概况
四川省泸定县隶属甘孜藏族自治州,介于101°46′—102°25′E,北纬29°54′-30°10′N之间,平均海拔在2 000 m左右,最高海拔7 556 m,位于大雪山贡嘎山主峰。研究区地处川西高原与四川盆地的过渡带,大渡河由北向南将全县分割为东西两部分,为典型的高山峡谷地貌。地形上严格受构造控制,总体地势西北高,东南低。构造上泸定县地跨扬子陆块区与羌塘—三江造山系两大一级构造单元,主要由川滇南北向构造带、北东向龙门山构造带、北西向构造带构成[14]。泸定县属青藏高原亚湿润气候,受东南、西南季风和青藏高原冷空气的双重影响,气候垂直差异明显,大渡河河谷及其支流河谷海拔1 800 m以下地区属于热带季风气候,年降水量664.4 mm,多集中在6—8月,为典型的干热河谷区[10]。河流两岸坡度陡峭,同时受岩性和温度等因素的影响,多破碎岩体出露地表且广泛分布。
1.2 数据来源
本文使用的数据主要包括数字高程模型(DEM)、土壤、土地利用、工程岩组、断裂带、水系、多年平均温度、地质灾害点等多个数据集。其中,DEM数据来自地理空间数据(http:∥www.gscloud.cn/),研究区坡度、坡向、起伏度均由DEM数据在ArcGIS 10.1中生成;土壤类型来自南京土壤所1∶100万中国土壤数据库;土地利用类型基于2018年土地变更调查数据库并结合《土地利用现状分类(GB/T21010-2017)》生成;工程岩组、断裂带均采用中国地质调查局1∶20万地质图;多年平均温度由四川省气象数据库(1986—2016年)数据插值生成。地质灾害点类型主要包括滑坡、泥石流和崩塌,基于谷歌卫星影像(2018年)通过目视解译获取(图1),并由实地调查验证,研究区地质灾害点共279处。

图1 研究区谷歌影像解译示例图
2 研究方法
2.1 评价单元
地质灾害的易发性评价首先要选择一个合适的评价单元,即制图单元。“单元”即地质灾害评价中最小的地表研究对象,其形状可以是规则图形,也可以是不规则多边形。常用的有以下4种方法:规则格网法即栅格单元、地域条件、独特条件和斜坡单元。本文采用栅格单元评价法,基于前人[12]的研究经验以及研究区的实际情况,本文以30 m×30 m栅格单元为最小评价单元。研究区共2 404 481栅格个单元,在此基础上展开易发性评价。
2.2 加权信息量模型
2.2.1 信息量模型 信息量模型属于统计分析模型的一种,于其物理意义明确、操作简单,在地质灾害易发性评价的研究和实践中得到了广泛的应用[15]。该模型可以比较客观的反映单个评价因素中在不同分级标准下,对地质灾害易发性贡献的大小。根据研究区地貌、地质、气象等特征,在复杂的环境中,选取一种“最佳因素组合”,对地质灾害发生影响最大。
信息量的表达式为:
(1) 单个因素信息量计算公式:
(1)
式中:Ni——在因素Xi特定类别xi内的地质灾害点个数;N——研究区域地质灾害发生的灾害点总数;Si——研究区域内含有评价因素xi的单元面积;S——研究区域评价单元面积总数。
(2) 单个评价单元内总的信息量,计算公式
(2)
式中:Ij——评价单元总的信息量,也表示该评价单元地质灾害的易发性大小。其中Ij的值越大表明越有利于滑坡灾害的发生。
2.2.2 确定性系数法 确定性系数模型(CF)是一个概率函数,最早由Shortlifffe和Buchanan(1975年)提出[16],由Heckerman[17]进行了改进。该模型通常用于事物发生不同因素的敏感性分析,也有学者[18-19]着重用于确定因子的权重。刘艳辉等[18]基于CF值代表着各因子对地质灾害的贡献,提出了基于CF的多因子叠加确定权重法。马玉宽等[19]根据各因子的CF值,通过计算得出各因子权重。确定性系数确定权重的方法为:
(1) CF计算:
(3)
式中:PPa——地质灾害在数据a类中发生的条件概率,应用时为因素a类中存在的地质灾害个数与因素a类的面积的比值;PPs——地质灾害在整个研究区A中发生的先验概率,可以表示为整个研究区域的地质灾害的个数与研究区面积的比值。CF的变化区间为[-1,1],正值代表地质灾害发生的确定性高,较易发生地质灾害;负值代表地质灾害发生的确定性降低,不易发生地质灾害;当计算结果接近0表示该因子在分类中不能确定是否容易发生地质灾害。
(2) 权重Wi:
Wi=CF(i,max)-CF(i,min)
(4)
式中:CF(i,max)——因子i各分类对地质灾害发生的确定系数的最大值; CF(i,min)——因子i各分类对地质灾害发生的确定系数的最小值;通过对易发性指数的计算,可以分析各个评价因子对地质灾害的影响程度。
2.2.3 加权信息量 由于地质灾害发生原因复杂,各因素在整个过程中所起到的作用大小不一,信息量模型未考虑各评价因子在地质灾害发生过程中所起作用的大小,不能反映不同因子影响程度的差异。因此为了更加科学合理的进行易发性分析,应考虑对各个影响因子赋予权重与信息量相乘得到加权信息量[12]。本文结合确定系数法和信息量法的优点,最终模型为:
(5)
3 易发性评价因子
3.1 评价指标
地质灾害的发生具有快速性、突发性和不确定性的特征,影响因素也很多样。本文将影响因子分为地形地貌、土壤与土地利用/覆被(LULC)、岩性构造、气象水文4大类来进行分析。具体有坡度、坡向、起伏度、土壤、土地利用、工程岩组、与断层距离、年均温度和与河流距离9个指标为本研究区地质灾害易发性评价因子(附图1)。
3.1.1 地形地貌
(1) 坡度。坡度是基本的自然地理要素,坡度的大小决定了地表松散堆积物发生位移并形成地质灾害的可能性,是影响地质灾害发育的重要因素,对地质灾害的发生起着控制性作用。研究区坡度范围为0°~88.57°,将坡度分为9个等级(图2)。根据灾害统计看出(附图1),地质灾害多发生在30°以上的斜坡上,共发生201处,占总灾害点的72.04%。但从信息量而言,除了30°以上研究区较高外,坡度在8~15°的也较高,信息量为0.07。
(2) 坡向。不同的坡向使得其受太阳照射的时间有很大差别,从而影响了地表松散程度。承载体的松散程度是地质灾害是否发生的关键性因素,阳坡和阴坡由于阳光照射不同,地表破碎程度不一。由泸定县地质灾害与8个坡向的统计数据来看(附图1),阳坡发生的灾害点明显多于阴坡,位于东南、南、西南方向共发生179个地质灾害,占研究区总灾害点个数的70.61%。各个坡向的信息量和发生的地质灾害点数量呈现明显的正相关性,其中东南,南的信息量分别为0.68,0.67。
(3) 起伏度。起伏度在一定程度上也影响着地质灾害的发育,其控制着地质灾害所聚集的势能[20]。在高山深切河谷地貌中,起伏度与地质灾害尤其是滑坡灾害具有良好的相关性。本文通过ArcGIS得到研究区起伏度分布图(附图1),将起伏度分为分0~20 m,20~40 m,40~60 m,60~80 m,80~100 m以及>100 m共6个等级。地质灾害多集中于起伏度40~60 m之间,共发生99处地质灾害,占总灾害的35.48%。虽然起伏度在80~100 m区间内地质灾害仅发生29处,但由于单位研究区面积小,仅占总研究区的0.08%,故该区段信息量较高,具体值为0.22(图2)。
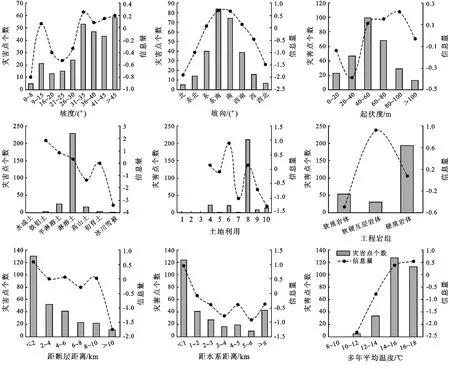
注:1为工矿仓储; 2为特殊用地; 3为交通运输; 4为水域及水利; 5为住宅用地; 6为耕地; 7为园地; 8为林地; 9为草地; 10为其他用地。
图2 研究区影响因子灾害数量、加权信息量相关性统计
3.1.2 土壤与土地利用/覆被(LULC)
(1) 土壤类型。土壤的质地影响着土壤的渗透性能,土壤的渗透性越好,越有利于泄洪,一般沙性土壤颗粒较粗,不容易产生径流,或流量较小。相反,黏质土壤透水性差,容易产生径流。根据1∶100万中国土壤数据库,研究区拥有7种土类,15种土壤亚类,土壤类型丰富(附图1)。据统计(附图1),泸定县地质灾害82.08%集中在淋溶土区,该区域面积占总研究区面积的61.02%。淋溶土及指湿润土壤水分状况下,石灰充分淋溶,具有明显黏粒淋溶和淀积的土壤,透水性相对较差,故地质灾害发生相对集中。
(2) 土地利用/覆被(LULC)。地质灾害的发生与土地利用联系非常密切[21],不同的土地利用类型发生的地质灾害数量差别较大。根据2017年土地利用分类现状,研究区共有耕地、园地、林地、草地、工矿仓储用地、住宅用地、特殊用地、交通运输用地、水域及水利设施用地以及其他用地10种(附图1)。其中林地是研究区土地利用的主要类型,面积占总面积的65.53%。同时也是地质灾害集中的区域,共发生211处地质灾害,占总灾害的43.37%。
3.1.3 岩性构造
(1) 工程岩组。工程岩性的硬度不同,其抗拉、抗压等力学性能相差巨大,从而导致灾害的难易程度不同[22]。研究区的工程岩组包括硬质岩组(白云岩,灰岩、玄武岩、黑云二长花岗岩等)、软质岩组(斜长角闪岩、混合片麻岩、变粒岩等)和软硬互层岩组(泥灰岩、砂岩、粉砂岩等)(附图1)。可以直接看出硬质岩体是研究区的主要工程岩组类型,面积为1 385.99 km2,占总面积的64.03%。由于其在研究区分布面积大,在硬质岩组统计的地质灾害点相对较多,共194处是总灾害的69.53%,但硬质岩体并不是信息量最大的工程岩组类型。软硬互层岩组虽然在研究区所占面积小,仅为95.43 km2,但由于其稳定性差并且在内外力作用下容易发生滑坡等地质灾害。软硬互层岩组信息量高达0.92,可见软硬互层岩组在该区域内是最容易发生地质灾害的区域。
(2) 与断层距离。研究区内主要断裂构造有鲜水河断裂、磨西断裂、大渡河断裂、龙门山断裂、金坪断裂等。由于断裂的走向控制着河流、河谷的发育方向,而其两侧又是人类活动的主要区域,地质灾害发生率高且危险性大,所以将距断层距离考虑到易发性评价中。本文将研究区距断层的距离分为:<2 km,2~4 km,4~6 km,6~8 km,8~10 km以及>10 km共6个等级(附图1),由统计(附图1)看出距断层距离越近地质灾害发生率越高的总体趋势,距断层2 km以内是地质灾害发生的主要区域,共发生130处,占总灾害的46.6%,信息量为0.58。
3.1.4 气象水文
(1) 与水系距离。河流是控制坡面侵蚀的重要原因,泸定县境内有大渡河及其支流木角沟、磨河沟、冷碛潘沟、兴隆沟等20余条分布于大渡河两岸的溪沟,流域面积达2 144.1 km2,河流多深切峡谷,具有较好的地质灾害点发育临空面。本文用将研究区距水系的距离(km)分为:<1 km,1~2 km,2~3 km,3~4 km,4~5 km,5~6 km和>6 km共7个等级(附图1)。通过统计看出(附图1),总体上距水系距离越近,地质灾害发生的概率越高。距水系1 km以内是地质灾害发生的重点区域,共发生124处地质灾害,占总灾害的44.4%,信息量高达0.95。
(2) 年均温度。年均温度是区域地形、气候等多因素综合影响下的气象表征。泸定县年均气温15.5 ℃,但受地形影响泸定县温度差异明显:在高山地区常年积雪,属于高原气候;河谷地区四季分明属于典型的亚热带季风气候。温度较高的河谷地区,由于长时间受阳光照射以及河谷风力侵蚀,加速了两岸坡面的松散程度,为地质灾害的发生提供了有利条件。研究区大致分为:8~10 ℃,10~12 ℃,12~14 ℃,14~16 ℃,16~18 ℃共5大区域,年均温度由东向西递减(附图1)。由地质灾害点与多年平均温度的统计来看(附图1),年均温度越高,信息量越大,表示越容易发生地质灾害。其中年均温14~16 ℃以及16~18 ℃的区域地质灾害分别发生127处和113处,占发生总灾害的45.52%,40.5%。
3.2 权重以及信息量
运用公式(3)对各评价因子CF值量化,再运用公式(4)确定各评价因子权重(表1)。运用公式(1)—(2)计算单个评价因子各分类等级信息量值(表2)。通过ArcGIS,所有数据源均投影到2000国家大地坐标系(CGCS2000)坐标系下,并将每个评价因子图层转成30 m×30 m的栅格图层。

表1 地质灾害影响因子权重
3.3 易发性检验
通过栅格计算器将各个图层进行叠加,将叠加后图层用自然断点法分为5个易发区:极低易发区、低易发区、中易发区、高易发区、极高易发区,得到利用加权信息量模型做出的研究区易发性分区图。为了验证加权信息量模型在易发性评价分区中的精确度,通过信息量模型与之对比,运用信息量模型得到易发性分区图(附图2)。
工作特征曲线(ROC)是衡量评价模型预测精度的指标,本文以信息量值从高到低的区域累计栅格与总栅格的百分比作为横轴,以对应信息量区间内地质灾害累计点数与地质灾害总数百分比作为纵轴,分别将信息量模型和加权的信息量模型所得数值代入,得到两条过(0,0),(1,1)的曲线(图3)。ROC曲线越接近左上角模型越理想,曲线下方面积AUC被用来评价模型的精度,信息量模型与加权信息量模型的AUC值分别为0.773,0.793。可见在本研究区构建的加权信息量模型精度高于单一的信息量模型。

表2 地质灾害易发性评价各因素状态信息量
注:Ni表示在因素Xi特定类别xi内的地质灾害点个数;Si表示研究区域内含有评价因素xi的单元面积。Ii表示信息量值。
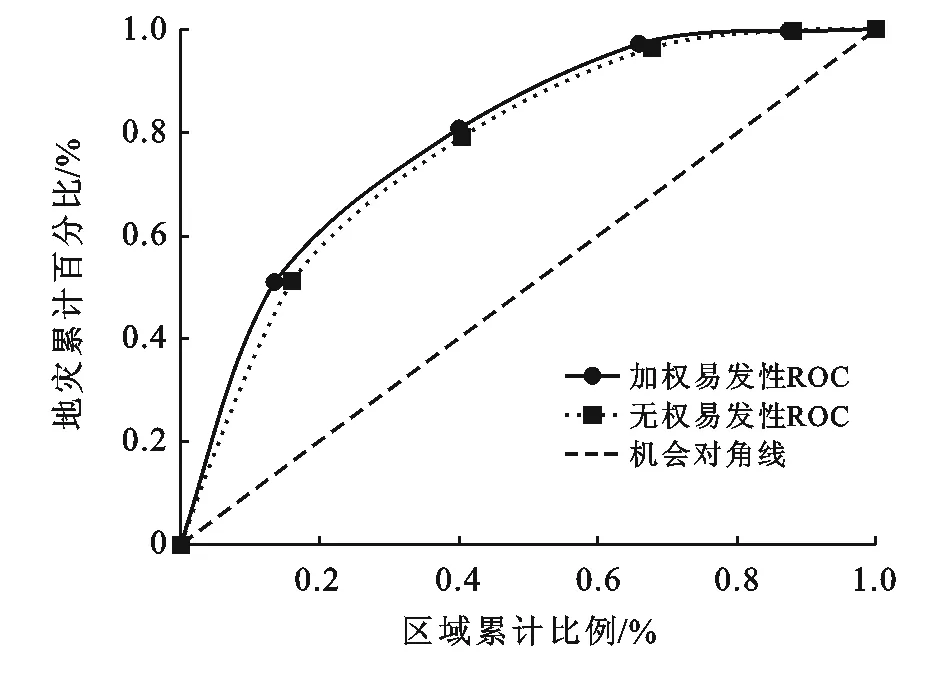
图3 地质灾害易发性评价结果ROC图
经加权信息量模型分区结果和统计情况(表3)表明,研究区共225处地质灾害位于高易发区以及极高易发区,占总地质灾害的80.65%。其中高易发区地质灾害与总灾害比29.75%,高易发区面积与总面积比26.49%;极高易发区地质灾害与总灾害比50.90%,极高易发区面积与总面积比13.54%。加权信息量模型预测结果较好。

表3 研究区易发性分区结果统计
4 结 论
(1) 根据CF计算各因子权重大小来看,研究区致灾评价因子中土壤类型和年均温度所占比重较大,分别高达1.96和1.93,是地质灾害的主控因子。其次为土地利用类型、坡向、与断层和水系的距离以及工程岩组,坡度和起伏度相对来说所占权重较小。
(2) 地质灾害易发性分区表明,研究区40.03%被划为高易发区以及极高易发区。从各评价要素提供的信息量来看,坡度为31~35°,坡向为东南,起伏度在60~80 m,年均温度在16~18 ℃且距离水系小于1 km,断层小于2 km,土壤类型为铁铝土,土地利用类型为耕地,软硬互层的工程地质岩组的范围和类型内极易发生地质灾害。
(3) 运用确定系数法确定评价因子权重大小,结合信息量法,构成加权信息量模型。通过ROC检验,加权信息量在研究区划定的易发性分区更精确,AUC值为0.793。研究区279处地质灾害点,225处落在高易发区和极高易发区中,占总灾害点的80.65%。与研究区实际情况比较一致,能够在地质灾害危险性评价中起相应作用。
猜你喜欢
水土保持研究(2022年1期)2022-12-27
水土保持研究(2022年2期)2022-03-15
房地产导刊(2022年1期)2022-02-28
水土保持研究(2021年4期)2021-06-23
水土保持研究(2021年2期)2021-02-06
中国金属通报(2020年21期)2021-01-04
资源环境与工程(2020年2期)2020-07-09
西南交通大学学报(2018年5期)2018-11-08
环球人文地理·评论版(2017年3期)2017-06-14
成才之路(2016年18期)2016-07-08
