
一种基于XGBoost 算法的月度负荷预测方法
2019-06-14 09:01:26钱仲文纪德良
浙江电力 2019年5期
钱仲文, 陈 浩, 纪德良
(1. 国网浙江省电力有限公司, 杭州 310007; 2. 浙江华云信息科技有限公司, 杭州 310008)
0 引言
负荷预测对电力系统的安全运行和电网企业的经济效益有着重要意义, 一直以来, 短、 中、长期的电力负荷预测作为供电企业的重要工作,各类负荷预测方法和研究层出不穷, 经典的预测方法包括时间序列、 神经网络、 SVM(支持向量机)、 灰色预测法等。 主流的电力负荷预测主要针对地区性、 行业性的宏观负荷数据, 单个企业的负荷数据由于受企业生产、 宏观政策等不确定因素影响, 缺乏周期性规律, 波动性大, 存在较大的模型预测误差。
用电客户, 尤其是大工业用户的月度电力负荷数据与用电成本密切相关, 在当前电力改革大背景下, 电网企业可以利用自身的技术和数据优势, 为大工业用户提供月度负荷预测结果, 帮助企业合理选择计费方式, 降低用电成本, 为客户提供增值服务。
本文提出了一种应用XGBoost(极端梯度上升)算法[1]进行大工业用户月度负荷预测的模型,通过综合考虑天气、 企业生产情况、 历史负荷变化等因素, 预测企业月度负荷变化趋势, 为企业业扩报装提供科学的判断依据。
1 基于XGBoost 模型的建立
1.1 XGBoost 原理
XGBoost 算法原理于2004 年由陈天奇提出[2],是在GBDT(梯度提升决策树)的基础上对Boosting 算法的改进, 解决GBDT 算法模型难以并行计算的问题, 实现对模型过拟合问题的有效控制。
GBDT 是一种迭代的决策树算法, 为便于求解目标函数, GBDT 常用回归树生长过程错误分类产生的残差平方作为损失函数, 即通过拟合残差平方构造损失函数。 随着树的生成, 损失函数不断下降; 回归树生长过程每个分裂节点划分时枚举所有特征值, 选择使得错误分类最少、 损失函数下降最快的特征值作为划分点; 每一棵回归树学习的是之前所有树的结论和残差, 拟合得到一个当前的残差回归树; 最后, 累加所有树的结果作为最终结果。 GBDT 回归树生长过程如图1所示。

图1 GBDT 回归树生长过程
GBDT 回归树求取目标函数最优解只对平方损失函数方便求得, 对于其他的损失函数变得很复杂。 以最小平方损失确定分裂节点的选取, 仅考虑了回归树各叶节点预测精度, 在追求高精度的同时易造成模型复杂度提升, 造成回归树的生长出现过拟合。
XGBoost 算法模型对GBDT 上述两个不足进行改进。 XGBoost 算法增加了对树模型复杂度的衡量, 在回归树生成过程分裂节点的选取考虑了损失和模型复杂度[3]两个因素, 在权衡模型低损失高复杂和模型低复杂高损失后[4], 求取最优解,防止一味追求降低损失函数产生过拟合现象, 且速度快, 准确性高[5], 是有效的集成学习算法[6]。XGBoost 回归树生长过程如图2 所示。

图2 XGBoost 回归树生长过程
通过推导, 最终的目标函数可简化为:

式中: T 为回归树叶子数; Gj为所有数据在损失函数上的一阶导数; Hj为所有数据在损失函数上的二阶导数; γ 为叶节点个数代表的复杂度的惩罚系数; λ 为叶节点权重代表的复杂度的惩罚系数。
可见, 目标函数只依赖于每个数据点在误差函数上的一阶导数和二阶导数, 通过二阶泰勒展开式[7]的变换, 这样求解其他损失函数变得可行。
XGBoost 目标函数根据研究的对象不同可进行自行定义, 具体可分为: 针对连续型研究变量,目标函数为线性回归; 针对分类型研究变量, 目标函数可为逻辑回归; 针对计数型研究变量, 目标函数为泊松回归。
1.2 基于XGBoost 负荷预测模型的建立
1.2.1 样本及数据预处理
本文采用XGBoost 模型对用户每月最大负荷进行预测, 选取浙江某地市大工业用户近5 年月度最大负荷数据及影响负荷因素指标数据作为样本进行训练建模。
由于负荷数据的获取受设备和人为因素影响可能存在坏数据[8], 会影响模型的准确性, 故在建模前需识别和替换负荷异常数据, 填补缺失数据; 影响负荷因素指标可能受偶然环境因素的影响, 需进行识别、 替换、 剔除、 填补操作; 对相关影响指标与负荷间的关联性进行分析, 与负荷间存在复杂的非线性关系指标, 需对指标进行转换; 对分类型影响因素指标进行独热编码处理。处理步骤如下:
(1)负荷数据异常识别、 替换: 按用户采用3σ 法则, 对于超出该用户历史5 年月度最大负荷±3σ取值的用±3σ 替代。
(2)负荷数据、 相关影响指标缺失填补: 按用户采用历史同期值进行填补。
(3)相关影响指标受偶然环境因素作用走势明显异常填补: 分别按用户采用历史同期值替换。
(4)指标转换: 结合指标散点图和关联分析显著性检验, 研究影响指标与负荷间关系, 并对指标进行相应转换。
(5)分类指标处理: 对月份、 行业类别等分类变量进行独热编码处理。
通过对模型指标数据的预处理, 填补缺失、替换异常、 寻找关联挖掘指标间隐藏规律, 确保数据的完整性、 可用性、 有效性, 有利于提高模型准确性。
1.2.2 输入输出量的选择
以浙江某地区大工业户近5 年每月最大负荷数据为研究变量, 作为模型的输出Y, 选择关键指标进行建模是模型准确的保证[9]。 本文结合预处理结果, 选择与月最大负荷关联性较强的影响因素作为输入变量X, 加入模型中。 具体的影响因素X, 分为以下几类[10]:
(2)相关天气指标: 预测月温度、 湿度、 风力、天气类型等的同期、 上期、 预报的n 个天气指标B={b1, b2, …, bn}。
(3)用户基本信息指标: 预测月用户当前的户龄、 行业、 合同容量、 用电类别等p 个基本信息指标C={c1, c2, …, cp}。
(4)企业生产情况指标: 预测月用户生产计划、 产值、 注册资本等q 个生产情况指标D={d1,d2, …, dq}。
(5)行业整体情况指标: 预测月反映行业景气度的r 个行业指标E={e1, e2, …, er}。
(6)节假日指标F={ f1, f2, …, fs}: 预测月所含节假日天数、 是否春节等s 个节假日指标。
(7)独热编码变量G={ g1, g2, …, gt}: 基于上述几类变量中的分类变量产生的独热编码变量, 如天气指标中的天气类型; 用户基本信息指标中的行业类别、 用电类别等分类指标产生的t个独热编码变量指标。
1.2.3 负荷预测的XGBoost 模型
在当前的高中语文课堂教学中还存在很多的问题,部分教师还是习惯于采用“灌输式”“照本宣科”的教学方法来对待学生,导致课堂氛围较为枯燥,学生只能够通过“死记硬背”的形式来学习高中语文知识,根本无法发挥出语文学科的育人功能,而在网络时代,高中语文教师可以利用多媒体技术,把课本知识用图片、声音、视频的形式展示出来,让学生能够全身心地投入到语文学习中去,加深对文章的理解与记忆,师生之间共同构建高效、和谐的语文课堂。
将选入模型的影响负荷预测因素变量转化为稀疏矩阵, 形成XGBoost 建模数据; 将月最大负荷定义为XGBoost 模型输出; 定义模型学习目标函数、 回归树生成参数等构造负荷预测的XGBoost 模型[11]。 XGBoost 可根据研究任务来确定目标函数。 本文研究任务为预测月度最大负荷, 负荷值属于连续属性变量, 学习任务是对负荷进行回归预测, 故可选择线性模型作为目标函数。
XGBoost 回归树的最大深度、 学习率、 迭代次数等参数均会影响预测精度。 通过对XGBoost 各参数进行交叉验证测试, 调整优化模型参数[12],得到模型精度最高的参数组合。
2 实例验证
获取实例数据, 分别采用传统神经网络、 支持向量机和XGBoost 3 类算法[13]进行模型效果测试, 通过对比分析, 对XGBoost 模型可行性进行验证。
结合交叉验证方法进行模型指标筛选和模型效果评估, 其中80%的样本数据为测试集, 20%的样本数据为验证集。 为保证3 类算法具有可比性, 每种机器学习算法都采用相同的训练集和测试集。 采用MAPE(平均绝对百分比误差)、 RMSE(均方根误差)和R2(R 平方值)3 种方法综合评估模型性能[14]。
其中, MAPE 反映模型预测准确性, 其值越小, 代表模型预测准确性越高; RMSE 反映模型的平均误差情况, 其值越小, 代表误差越小; R2反映模型拟合效果, 其值越大, 代表这个模型对数据拟合越好。


式中: yi为历史月最大负荷实际值;为模型预测值;为最大负荷平均值; n 为验证集合数据样本个数。
本文使用数据为浙江某地区部分大工业用户近5 年每月最大负荷及其相关影响因素指标数据, 表1 为2018 年7 月部分用户实际月最大负荷数据。
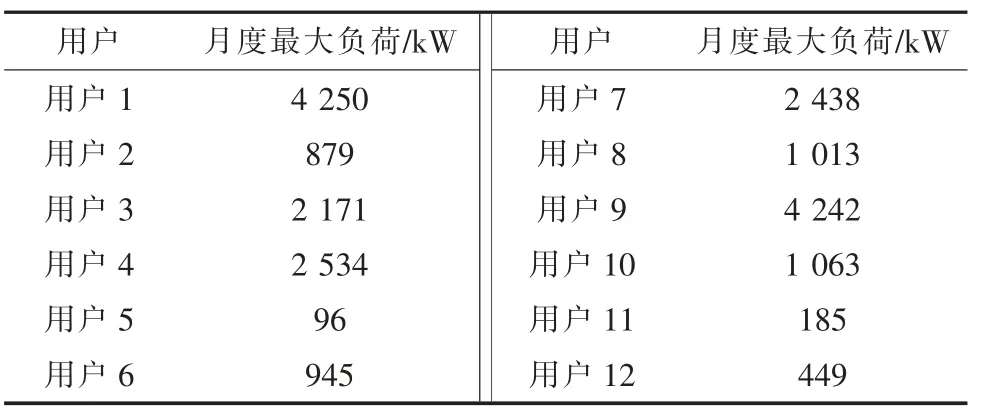
表1 部分用户2018 年7 月最大负荷数据
2.1 指标测试与选择
对用户近5 年月最大负荷数据开展建模测试, 抽取前4 年历史数据样本作为训练集, 最近1 年数据样本作为测试集, 结合上述数据预处理和变量选取规则, 采取指标关联分析、 指标变换、 因子降维等多种方法进行指标筛选[15](如图3 所示)。 经过模型多次迭代测试后, 保留预测误差最小的指标体系。

图3 指标筛选流程
针对本文使用的浙江某地区部分大工业用户近5 年每月最大负荷及其相关影响因素指标数据, 采用XGBoost 算法, 以Gain(信息增益)指标对变量重要性进行排序, 其中重要性前十的变量如图4 所示。
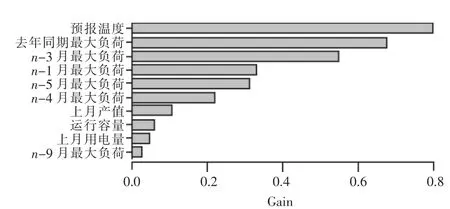
图4 按变量重要性排序
2.2 模型预测效果对比
2.2.1 支持向量机模型负荷预测
针对本实例数据, 使用径向机核函数将原始特征映射到高维线性空间, 寻找变量间线性关系(见图5)。
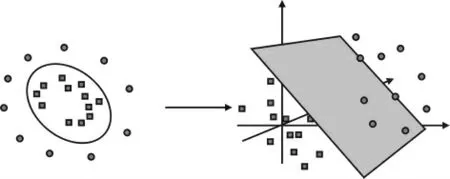
图5 函数寻找高维线性空间
经测试知设置惩罚因子Cost 为1 000, 决定数据映射到新特征空间分布的Gamma 为0.000 1时模型预测效果最佳,在测试集上MAPE=18.78%,RMSE=177.43, R2=0.988。
2.2.2 神经网络模型负荷预测
针对本实例数据, 设置神经网络隐藏层包含10 个神经元, 选取Sigmoid 为激活函数(见图6)。 函数表达式为:

式中: w 为每个输入的权重集合; b 为所有输入的偏置; x 为输入集合。
通过该激活函数转化, 将输入实数压缩到0~1 区间。 通过多次测试, 最终权值衰减为0.01, 最大迭代次数为1 000 时, 模型预测效果最佳, 在测试集上,MAPE=14.37%,RMSE=190.21,R2=0.986。

图6 Sigmoid 函数
2.2.3 XGBoost 模型负荷预测
针对本实例数据, 采用XGBoost 模型进行预测时, 根据研究对象, 定义目标函数为线性回归。
通过交叉验证, 最大深度为7, 学习率为0.3,迭代次数为60 时模型预测效果最佳。 在测试集上, MAPE=4.5%, RMSE=78.26, R2=0.998。 其交叉迭代误差如图7 所示。 3 种机器学习算法预测结果对比情况见表2。
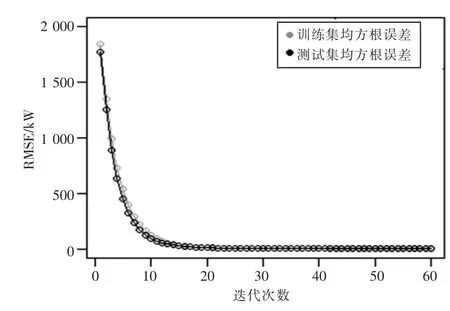
图7 交叉验证迭代的RMSE
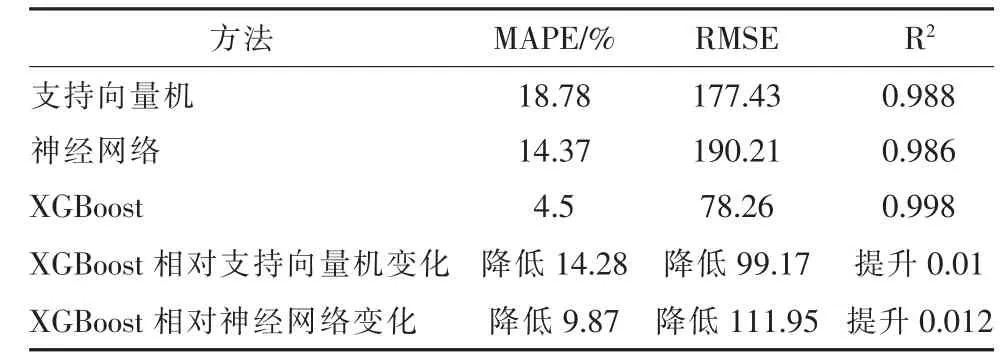
表2 3 类算法模型预测结果比较
由表2 的输出结果可知, XGBoost 输出的模型性能评估指标相比于支持向量机模型输出的变化分别是:MAPE 降低14.28%,RMSE 降低99.17,R2提升0.01; 相比于神经输出的变化分别是:MAPE 降低9.87%, RMSE 降低111.95, R2提 升0.012。
相比于支持向量机模型和神经网络模型,XGBoost 模型的预测准确性高、 模型平均误差小、模型数据拟合效果好。
综上所述, XGBoost 模型预测效果最佳, 故保留XGBoost 算法对该地市大工业用户用电负荷进行预测。
以某气体有限公司(用户1)为例, 该用户合同容量6 060 kVA, 行业类别为化工业, 2018 年1—7 月的月度最大负荷实际值与预测值偏差情况如图8 所示, 相对误差最大值为2.3%。

图8 2018 年用户1 最大负荷预测值与实际值偏差率
以某化工有限公司(用户9)为例, 该用户合同容量10 000 kVA, 行业类别为化工业, 2018年1—7 月的月度最大负荷实际值与预测值偏差情况如图9 所示, 相对误差最大值为1.8%。
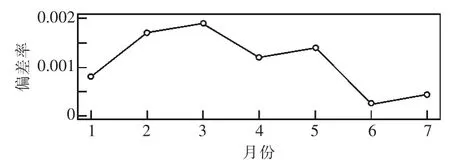
图9 2018 年用户9 最大负荷预测值与实际值偏差率
3 结语
随着电力市场化改革和发展, 大工业用户作为电力高价值客户, 其用电负荷变化越来越受到售电公司的重视, 企业级负荷预测的重要性日趋显著, 并且对预测的精准度要求也越来越高。 本文基于XGBoost 算法, 对比传统神经网络、 支持向量机算法模型, 对浙江某地市化工行业近5 年月度负荷数据进行建模和预测, 结果显示, 采用XGBoost 模型MAPE 控制在5%以内, 对预测单个企业未来一个月的最大负荷数据效果较好。 本方法对帮助企业优化用电方式, 降低用电成本有一定的指导和借鉴意义。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
小学生学习指导(高年级)(2021年4期)2021-04-29 02:17:10
河北理科教学研究(2020年2期)2020-09-11 06:15:48
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
东北电力技术(2016年2期)2016-05-17 04:32:46
中国化肥信息(2016年35期)2016-05-17 04:25:50
数学年刊A辑(中文版)(2015年2期)2015-10-30 01:56:14
核科学与工程(2015年2期)2015-09-26 11:56:59
