
利用一致性低秩表示模型进行多聚焦图像融合
2019-06-13 02:56周国众
指挥控制与仿真 2019年3期
刘 洋,周国众,王 凡
(1.陆军炮兵防空兵学院沈阳士官学校,辽宁 沈阳 110162;2.中国人民解放军63612部队,甘肃 敦煌 736200)
图像是对现实场景的一种模拟的、生动性的描述或写真,是人们在日常生活中最常用的信息载体之一,是人们感知和传播信息的重要工具。现实中,一幅清晰完整的、信息量丰富的图像能够更好地帮助人们概括和理解现实场景的相关信息。因此,获取一幅高质量的图像对于人类获取信息来说至关重要[1]。但因为成像器材景深有限,使得物体位于聚焦区域内或附近时,图像较为清晰,反之较为模糊,给后期处理和信息获取带来不便。多聚焦图像融合是解决这类问题的一种有效途径,它能够集成同一场景不同图像上所有聚焦信息为一体,生成一幅全聚焦的清晰图像,能够更好地帮助人类感知场景信息。
现有的多聚焦图像融合方法主要可以分为三个类型,即:基于空间域的融合方法、基于变换域的融合方法以和基于图像稀疏表示的融合方法。传统空域的图像融合方法直接作用于源图像,针对不同源图像上的像素或区域,采用一定的方法,选择出清晰度较高的区域,然后将这些清晰的区域融合起来生成最后的融合图像。基于传统空域的多聚焦融合方法整体来说,其思想简单,计算量较小,融合速度比较快,但其融合结果一般,对噪声和误配准比较敏感,分块融合时还会造成严重的“块效应”。
基于变换域的融合方法主要是对图像采用一种变换基,将其转换到另一种计算域中进行分解和融合,最典型的变换域的融合方法为基于多尺度变换的图像融合。一般处理过程是首先采用多尺度分解工具对输入图像进行多尺度分解,获得多个分解层的多尺度图像,然后在每一个分解层上设计相应的融合规则,将各层的融合结果进行多尺度重构得到最终的融合图像。这种方法因为可以针对变换域内的不同尺度层选择相应的较为高效的融合规则,因此,其具有较好的融合效果。常用的多尺度变换的方法主要有拉普拉斯金字塔[2]、离散小波变换(DWT)[3]、轮廓波变换[4]等。这些融合方法能够快速执行,对图像刻画更为具体,但其对噪声和误配准比较敏感,同时会出现边缘的模糊和变形以及丢失部分细节信息等。
近些年来稀疏表示在图像处理领域得到了大量的应用,其基本思想是源图像中的图像块可以使用少量的字典原子线性组合来进行表示。文献[5]首次将稀疏表示应用到了图像融合领域,在此之后,出现了大量的基于稀疏表示的融合方法,使得融合结果更加精确和稳定。但是,基于稀疏表示的图像融合算法一般采用滑动窗工具(如文献[6-7])对源图像进行采样,以减少“块效应”,这就造成了融合图像对比度的下降以及细节信息的丢失,同时使用滑动窗工具也增加了算法的计算复杂度。
针对以上问题,本文提出一种新的基于低秩表示和空间一致性约束相结合的多聚焦图像融合算法,该算法利用低秩表示模型对源图像进行低秩表示,将源图像分解为低秩的背景信息和稀疏的细节信息,再利用细节信息进行多聚焦区域的判断,较大程度上提高了融合结果的可靠性。这里,采用均值数据作为字典,节省了字典学习带来的计算量,并且能够对数据进行高效的表示。同时,在低秩模型中引用了拉普拉斯约束项,利用空间邻域对结果进行约束,减少“块效应”的同时,提高融合图像的质量。
1 基本理论
1.1 低秩表示
低秩表示是将观测的数据分解为低秩块和稀疏块之和的一种手段,由于该方法对噪声具有较好的鲁棒性而受广大学者关注。目前,低秩表示方法已经较多地用于人脸识别、目标检测等领域并取得了较好的效果。它的基本思想是假设对于某个字典,数据表示系数是低秩的,旨在寻求数据矩阵的最低秩表示。其模型如式(1)所示。
(1)
其中,DZ表示低秩部分,Z是X基于字典表示的系数矩阵,Z具有低秩特性,式中对Z进行了低秩约束。E是稀疏的噪声,‖·‖2,1是l2,1范数,表示对E进行列稀疏约束[8]。在使用低秩表示时,原始数据能够被分解为两部分,一部分为低秩的纯净数据,另一部分为稀疏的噪声数据,从而达到去噪的目的。而低秩表示在应用到多聚焦图像融合中时,可以将图像分解为低秩的背景信息和稀疏的细节信息,细节矩阵E包含较为丰富的结构和边缘信息(如图1所示),从而利用细节信息就能够判断出图像的清晰度。

图1 利用低秩表示将源图像分解为低秩的背景信息和稀疏的细节信息
1.2 基于图论的一致性约束
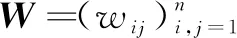
流形学习中,拉普拉斯特征映射算法[10]假设:若两个顶点xi与xj,其几何分布是“相临近”的,则这两个数据顶点在利用相关变换基在表示时,其系数向量zi和zj通常也应是“相邻近”的。利用此原理,通过最小化公式(2)的函数可实现从数据到系数之间的相似性映射:
(2)
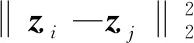
(3)
式中,σ为方差(高斯核),在本文中,其值设为1。
对式(2)进行矩阵变换,可将其转换为式(4)。
Tr(ZCZT)-Tr(ZWZT)=Tr(ZLZT)
(4)

最小化公式(4),可对特征相似的两个数据点或区域的表示系数进行相似性约束,使其具有一致性,因此,Tr(ZLZ)为对数据表示系数的一致性约束项。
2 融合算法
2.1 算法框架
本文提出的算法是利用低秩表示模型和空间一致性结合进行多聚焦图像融合,算法的整个过程包括:源图像的块划分及向量化,一致性低秩表示,定义融合规则并构建融合图像等过程,整个算法框架如图2所示。

图2 算法整体框架
2.2 构建源图像对应的向量化矩阵

2.3 模型的构建和编码
对于任意一个图像块,其聚焦特性与邻域内其他图像块具有较大可能的相似性,即当图像块位于同一个邻域内时,这些图像很可能同时聚焦或者同时离焦。因此,可采用图论的方式来约束这种相似性。以图像块为图的顶点,权重矩阵的构建为
(5)
式(1)中,利用低秩模型可以将源图像分解为低秩的背景图像和稀疏的细节信息。细节信息能够作为聚焦性因子,判断出图像区域的清晰度。为了提高E的准确性,本算法对E进一步进行了邻域内一致性约束,得到的模型为
s.t.X=DZ+E
(6)
其中,‖·‖*为核范数约束,‖·‖2,1是进行l2,1范数约束,L为拉普拉斯矩阵,由公式(4)进行构建。
式(6)可以采用线性迭代方向法[12](LADMAP)进行求解,引入变量J,并通过最小化(8)式的增广拉格朗日函数进行求解:
(7)
L(J,E,Z)=‖J‖*+λ‖E‖2,1+βtr(ELET)+
(8)
其中,H和P为拉格朗日乘子,μ>0是一个惩罚参数,〈A,B〉为矩阵A和B的欧氏内积。在更新时,每次更新一个变量,并固定其他所有变量,对该拉格朗日函数的求解问题可以转换为以下子优化问题。
1)更新J
(9)
该子优化问题存在如下的闭式解[12]:
(10)
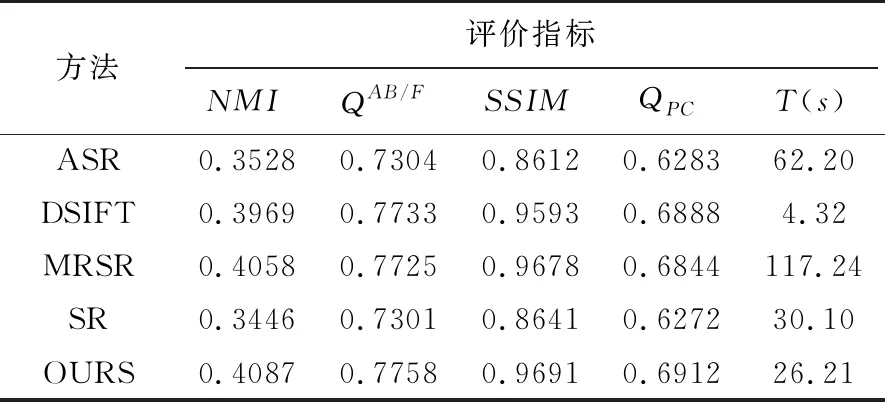
其中,SVTδ(A)=Udiag({(δi-δ)})VT,且A=Udiag({δi}1 2)更新Z (11) 求导,并优化得 (12) 式中,I代表单位矩阵。 3)更新E (13) 该子优化问题存在闭式解[13]: (14) 该模型的求解和编码过程见算法1。 算法1: 对一致性低秩表示模型的优化输入:(a) 数据矩阵X,表示字典D,惩罚参数λ和β,最大迭代次数itermax,容许误差ε。 (b) 算法初始化:Z0=J0=0,E0=0,H0=0,P0=0,μ=10-6,φ=1.1,μmax=106,ε=10-8,itermax=103。迭代步骤: 1)固定其他变量,更新J:Jj+1=SVT1μj(Zj+1μjPj)2)固定其他变量,更新Z:Zj+1=(DTD+I)-1(DT(X-Ej)+Jj+1+DTHj-Pjμj)3)固定其他变量,更新E:Ej+1(:,i)=(‖Q(:,i)‖2-ληj)‖Q(:,i)‖2Q(:,i), if‖Q(:,i)‖2>ληj0, otherwise4)更新拉格朗日乘子H和P:Hj+1=Hj+μj(X-DZj+1-Ej+1),Pj+1=Pj+μj(Zj+1-Jj+1)5)更新μ:μj+1=min(μjφ,μmax)6)检查是否满足收敛条件max‖X-DZj+1-Ej+1‖∞<εandmax‖Zj+1-Jj+1‖∞<ε‖·‖∞代表矩阵的无穷范数,如果满足收敛条件,结束;否则,继续步骤1-6。输出:一致性低秩表示系数矩阵Z和误差矩阵E。 1)融合规则的选取 对源图像进行低秩分解后,DZ描述的是图像的背景信息,E描述的是图像的细节信息。而细节信息中包含了图像的结构和边缘信息,能够描述出图像的清晰度,因此本算法中,采用E并利用l2范数取大作为活跃性测量因子对源图像进行融合。利用该融合测量因子,可得到多聚焦图像融合的初始决策标记图,如式(15)。 (15) 其中,F(x,y)表示标记矩阵F在(x,y)位置处的元素值,EA(:,i)表示源图像IA的低秩表示EA的第i列,EB(:,i)表示源图像IB的低秩表示EB的第i列,‖·‖2表示向量的l2范数。 2)初始决策图的优化 将F转换为与源图像相同大小的标记矩阵Do,F中每一列代表Do中对应的某一图像块。首先经过去洞处理,去除孤立区域,然后利用空间邻域一致性对初始决策标记矩阵Do进行优化,得到最终的决策标记图Df。主要实施过程:对于初始决策标记矩阵Do中每一个图像块,统计其8邻域内被标记为1和0的图像块个数,若被邻域内其他所有的图像块都被标记为1,则当前的图像块也被标记为1;若邻域内所有图像块被标记为0,则当前图像块也被标记为0。 3)构建最终的融合图像 利用Df构建最终的融合图像IF: IF=IA.×Df+IB.×(1-Df) (16) 其中,1表示元素值全为1的矩阵。 图4 五种算法对“Student”的融合结果比较 图3 待融合的六组多聚焦图像 图4为本文所选取的不同融合算法以及本文所提出的算法对“Student”源图像的融合结果和归一化差值图像。“Student”图像并未完全配准,存在一定的配准误差,通过利用该图像对算法进行融合比较,可反映出算法的稳定性和鲁棒性。图4为其融合结果,第一行为不同算法所对应的融合图像,第二行为融合图像与源图像的归一化差分图像。图中,(a-d)为所选取的四种算法所对应的融合结果,图4(e)为本文所提出的算法的融合结果。通过对比可以看出,在差分图像中,ASR和SR算法其融合结果包含较多的不一致区域(矩形框区域),DSIFT算法,相比前两种算法而言,其融合结果视觉效果较好,但仍然存在一定的形变,影响了融合算法的精度。这些算法得到的融合结果存在这些残差或不一致区域,表明在融合图像中引入了源图像中的非聚焦区域,使得融合图像出现大量的局部模糊和形变。在MRSR算法中,“钟表”的右边缘区域也存在一些残差区域,说明该算法在对边缘的提取和保留等方面存在不一致性,影响了融合质量。从图4(e)结果可以看出,本文算法存在较少的残差区域,尤其是在边缘区域以及白色框中的平滑区域,本文算法都能够保持较好的一致性,使得融合图像具有较好的清晰度,误差较少。因此从主观上,通过这些实验结果可得知,本文算法相比其他几种算法,其能得到较好的融合结果,并且对图像的误配准也具有较好的稳定性。 图5是其他五组图像,采取不同的方法所得到的聚焦决策图。对比该实验结果可以看出,现有的几种多聚焦图像融合算法所构建的融合标记图中基本上都包含有“孤立”的局部块状模糊区域,即“块效应”。这些块效应的存在表明算法在融合时,将图像的离焦区域错误地判定为聚焦区域并将其保留到最终的融合图像中,或是将聚焦区域错误判定为离焦区域而丢弃,降低了融合图像的清晰度,进而影响了融合图像的质量。如图5所示,ASR算法和SR算法,在其融合标记图中出现大量的“快效应”,可知这两种算法融合效果较差,存在较多的不一致性,而本文提出的方法构建的决策标记图中不存在“孤立”的块状区域,相比较其他四种方法具有较大的优势,基本上消除了“块状”效应,同时准确度较高。 上述实验从主观上充分验证了本文算法的有效性。为了从客观上对不同算法的性能进行比较,本文在上述实验的基础上,统计了不同融合算法对六组源图像进行融合得到的结果,所对应的五种客观指标的平均值见表1。表1中实验结果表明:本文算法相比其他几种算法,几种客观指标都具有明显的优势,虽然在时间复杂度上,DSIFT算法有一定的优势,但比较其他几种客观评价指标可发现,本文算法的在一致性、结构相似性等方面都优于DSIFT算法。从该客观评价结果可知,本文提出的利用一致性低秩表示模型进行多聚焦图像融合算法,其精度较高,融合效果较好。 图5 五种多聚焦图像融合算法对其他五组源图像的融合决策标记图 表1 六组多聚焦源图像采用不同融合算法的客观评价指标平均值对比 本文提出了一种新的多聚焦图像融合算法,该算法利用低秩表示模型将图像分解为背景信息和稀疏的细节信息,细节信息包含了图像的结构和边缘信息,能够描述出图像区域的清晰度。同时本文在进行低秩表示时,增加了空间一致性约束项,并利用拉普拉斯项构建了新的低秩表示模型。通过该模型对源图像进行低秩表示,利用表示结果的细节信息,采用l2范数取大作为融合规则进行融合,具有较好的融合效果。最后,用现有的几种多聚焦图像融合算法和本文算法对多组不同的多聚焦图像进行了融合比较,通过实验验证本文的算法无论从主观上还是客观上都明显优于其他算法。




2.4 融合规则的选取和优化
3 实验与分析




4 结束语
猜你喜欢
辽宁教育(2022年19期)2022-11-18
汽车实用技术(2022年9期)2022-05-20
控制与信息技术(2021年2期)2021-07-23
疯狂英语·新悦读(2021年1期)2021-01-27
家庭影院技术(2020年10期)2020-12-14
小学生优秀作文(低年级)(2018年10期)2018-10-13
读与写·教育教学版(2017年10期)2017-11-10
Coco薇(2016年10期)2016-11-29
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
