
基于DCNN特征的建筑物震害损毁区域检测
2019-06-10 07:01周阳张云生陈斯飏邹峥嵘朱耀晨赵芮雪
自然资源遥感 2019年2期
周阳, 张云生, 陈斯飏, 邹峥嵘, 朱耀晨, 赵芮雪
(中南大学地球科学与信息物理学院,长沙 410083)
0 引言
地震对于人类的生命和财产安全具有极大的威胁,震后的救援行动刻不容缓。快速地对震后建筑物损毁严重程度进行评估不仅能及时给救援部门和应急行动组提供可靠的救援参考,而且可以为震后灾区重建提供依据[1-2]。因此第一时间掌握建筑物震害损毁信息十分重要。
近年来无人机技术的快速发展使得迅速获取震后高空间分辨率遥感影像(以下简称高分遥感影像)成为可能[3]。因此,目前利用高分遥感影像进行建筑物震害损毁的检测逐渐受到越来越多的关注。传统的建筑物损毁检测方法一般基于手工设计的特征,分为基于单一特征和基于多特征结合的方法。其中单一特征包括颜色特征[4]、纹理特征[5-6]和地学纹理特征[7]等。单一特征局限性大,不能完整地描述地物的信息,精度也不够可靠,所以很多学者在单一特征的基础上研究了多特征结合的方法,如结合纹理特征和相互关系信息[8]、结合纹理特征和几何特征[9-10]等。虽然多特征结合的方法比单一特征的精度有所提高,但也只是基于各种单一特征的简单组合,精度提高的效果不是特别理想。因此如何得到更具表征能力的特征来进行建筑物震害损毁评估仍需进一步研究。
以上通过手工设计的特征表征能力依然较弱,近年发展起来的深度学习属于一种端到端的特征学习、表征学习,在语音识别、目标检测和图像分类上取得了很好的效果,在高分遥感影像的场景分类上也表现出了很强大的潜力[11-13]; 在震害损毁评估方面,Vetrivel等[14]提取无人机影像和航空影像的深度卷积神经网络(deep convolutional neural network,DCNN)特征,结合影像衍生的点云三维特征进行多核学习实现震害损毁评估,但仅考虑了较早的AlexNet模型。这些成功的应用表明DCNN强大的特征提取能力,但其网络结构复杂、训练时间长且需要大量的训练样本。相比于深度学习,支持向量机(support vector machine,SVM)具有保证全局唯一性、避免陷入局部最优的优点,且训练速度和分类精度都具有明显优势[15],同时,目前有很多基于SVM的遥感影像分类与对象提取的研究工作表明SVM在遥感数据分类中的效果较好[16-17],但是它属于浅层结构模型,对于原始输入信息只能有较少层次的处理,很难完整地描述原始的输入,故仅采用SVM分类具有很大的局限性。因此,如何将卷积神经网络的特征提取功能与常规的浅层分类结构SVM结合并应用到建筑物震害损毁检测上具有重大的研究意义和价值。综上,本文利用在ImageNet影像库上已经取得成功的DCNN模型来提取特征,结合SVM分类器来完成建筑物震害损毁区域的检测,以期获得更高的检测精度。
1 DCNN模型
在深度学习中,DCNN是一种最基本的模型,可作为一种特征提取器,其基本结构如图1所示,它包括输入层、若干个卷积层和池化层的组合以及全连接层。其中,卷积层输出特征图,其每个要素是通过计算由一些矩形排列的神经元组成的若干个特征平面和卷积核之间的点积来获得的,卷积核通常是以随机小数矩阵的形式初始化,然后在网络训练的过程中学习合理的权值; 池化层起到下采样的作用,即沿着特征图的空间维度,通过计算局部区域上的最大值来执行采样操作; 全连接层紧跟在若干个卷积层和池化层的组合之后,它连接所有卷积层和池化层中具有区分性的局部信息即局部特征,最后一层全连接层为输出层(softmax层)。DCNN的参数(即卷积层和全连接层中的权重)通过基于反向传播算法的经典随机梯度下降进行训练[18]。

图1 DCNN结构
本文使用AlexNet模型和VGGNet模型进行建筑物震害损毁检测。AlexNet模型由Krizhevsky等开发[14],与早期的DCNN模型相比,AlexNet模型由5个卷积层和3个全连接层组成,采用线性整流函数(rectified linear units,ReLu)作为激活函数代替Sigmoid非线性激活函数,来加快随机梯度下降的收敛速度,并且AlexNet模型在全连接层中引入Dropout方法来降低过拟合,提高模型的泛化能力。VGGNet模型由牛津大学视觉几何组的Simonyan等[19]提出,它由AlexNet模型发展而来,使用3个3像元×3像元(为表达简洁,以下省略“像元”)卷积,不仅使决策函数更有判别性,而且减少了参数; 同时增加网络深度,能够有效提升模型的效果,并且VGGNet模型对其他数据集也有很好的泛化能力。
2 损毁区域检测方法
本文方法流程如图2所示,主要包括2部分: ①模型训练,选取损毁和未损毁区域的样本,分为训练和测试样本2部分,利用预训练的DCNN模型提取特征,然后将训练样本的DCNN特征输入SVM分类器中,对SVM进行训练,并用测试样本进行测试和精度评定; ②区域检测,基于第①部分训练得到的SVM分类器对待分类影像进行建筑物损毁区域检测。2部分的特征提取采用同样流程。
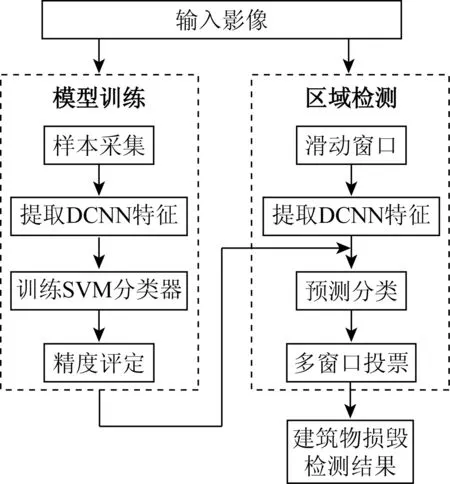
图2 方法流程
2.1 特征提取
利用ImageNet影像库预训练的DCNN学习的高层次激活值已被证明是具有优异性能的通用特征表达,可以迁移到遥感影像的特征提取中[20-21]。本文遵循已有工作的标准流程,移除预训练DCNN的最后一个全连接层,并将DCNN的其余部分视为固定特征提取器。将输入影像块输入到DCNN中,以前馈方式直接从除输出层以外的最后一个全连接层计算4 096维激活值(特征向量),然后将该特征向量视为输入影像的全局特征,用于表达输入影像块。因为所有预训练的DCNN结构需要一个固定尺寸的影像输入,如本文比较的2种模型AlexNet和VGGNet(ImageNet预训练模型下载自https: //github.com/BVLC/caffe/wiki/Model-Zoo),输入影像尺寸分别为227×227和224×224,当影像块尺寸不符时,需进行采样,生成符合尺寸大小的影像。因此本文在生成样本时,为了与滑动窗口步长协调,影像块大小设置为256×256,在训练过程中,先将256×256的影像降采样成与输入影像相同的大小。
2.2 模型训练
SVM是Cortes等[22]提出的一种线性分类器,它是根据带标签的训练样本,计算输出一个最优超平面对测试样本进行分类,在有限的样本信息和强学习能力之间寻求最佳结果。为了处理非线性分类问题,可以通过非线性函数,将输入映射至多维空间,在该空间中,可以产生一个泛化能力很强的线性分类器。本文采用LIBSVM工具来实现SVM运算,核函数选择径向基函数。
2.3 区域检测
在实际应用中,需要对整幅影像进行检测,常规方法是截取分类器所需尺寸的影像块进行分类预测,然后将预测结果作为中心像素的分类结果,但影像较大时,此过程耗时较长。根据DCNN特征的表征能力,本文采用类似的方式,但滑动窗口移动步长采用32,在分类器窗口滑动过程中,每一个32×32格网会被多个256×256的影像块覆盖,因此对于多个分类结果采用投票的形式确定最后的分类结果。整幅影像的检测过程如下:
1) 开辟2个与影像大小一样的类别累加器ACC[P(y=0)]和ACC[P(y=1)],分别赋为0,其中y=0和y=1分别表示影像中未损毁和损毁区域。
2) 以32个像素作为滑动步长,循环截取256×256大小的影像块,记录截取影像块的左上角坐标(x0,y0)。
3) 利用预训练的DCNN模型提取这些影像块的DCNN特征,然后利用训练好的SVM分类器进行分类预测,最后根据分类结果更新类别累加器,即
(1)
式中i,j∈(0,255)。
4) 比较每个32×32影像块2个累加器的结果,以类别占多数的结果作为当前影像块的结果。
3 数据处理与结果分析
3.1 实验数据
本文采用的数据是在www.haiti-patrimoine.org下载的2010年海地雅克梅勒地区震后的倾斜航空影像,其东、南、西、北4个摄影方向的影像空间分辨率均为1 m。研究区影像如图3所示,在这些影像中均匀选取1 500个样本,每个样本为256×256的影像块,共包含500个损毁区域,1 000个未损毁区域。图4(a)、(b)和(c)、(d)分别为损毁和未损毁区域样本的示例。

(a)东 (b) 南

(c) 西 (d) 北

(a) 损毁区域1(b) 损毁区域2 (c) 未损毁区域1 (d) 未损毁区域2
实验中按4∶ 1比例随机选择训练集和测试集。为了进一步验证方法的检测精度,选取了如图3(a)和(c)所示的红色方框区域验证本文方法,放大显示如图5所示,大小分别为1 888×1 376和1 280×1 280。

(a) 验证区域1 (b) 验证区域2
3.2 实验结果与分析
3.2.1 SVM分类器模型训练结果
分别利用训练样本通过AlexNet模型和VGGNet模型学习的DCNN特征训练SVM分类器并进行测试。为了进行对比,本文还实现了基于词袋模型(bag of words,BOW)的中层特征提取过程,即提取训练和测试样本尺度不变特征变换(scale-invariant feature transform,SIFT)描述符,利用K-means聚类方法,采用1 100个聚类中心构建BOW模型,训练SVM分类器并用测试样本进行测试[23]。3种特征训练结果如表1所示。从表1结果中可以看出,基于传统SIFT特征的BOW模型的测试精度低于基于DCNN提取的特征,其中,VGGNet模型相对于AlexNet模型具有更高的测试精度。
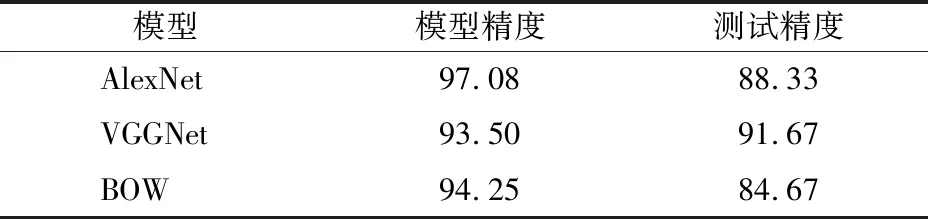
表1 SVM训练结果
3.2.2 验证区域结果
利用上述DCNN特征训练的SVM模型分别对验证集进行分类,结果如图6和表2所示。图6中红色区域为正确检测的损毁区域、黄色区域为漏检区域、蓝色区域为误检区域,未标记的区域为正确检测的未损毁区域。
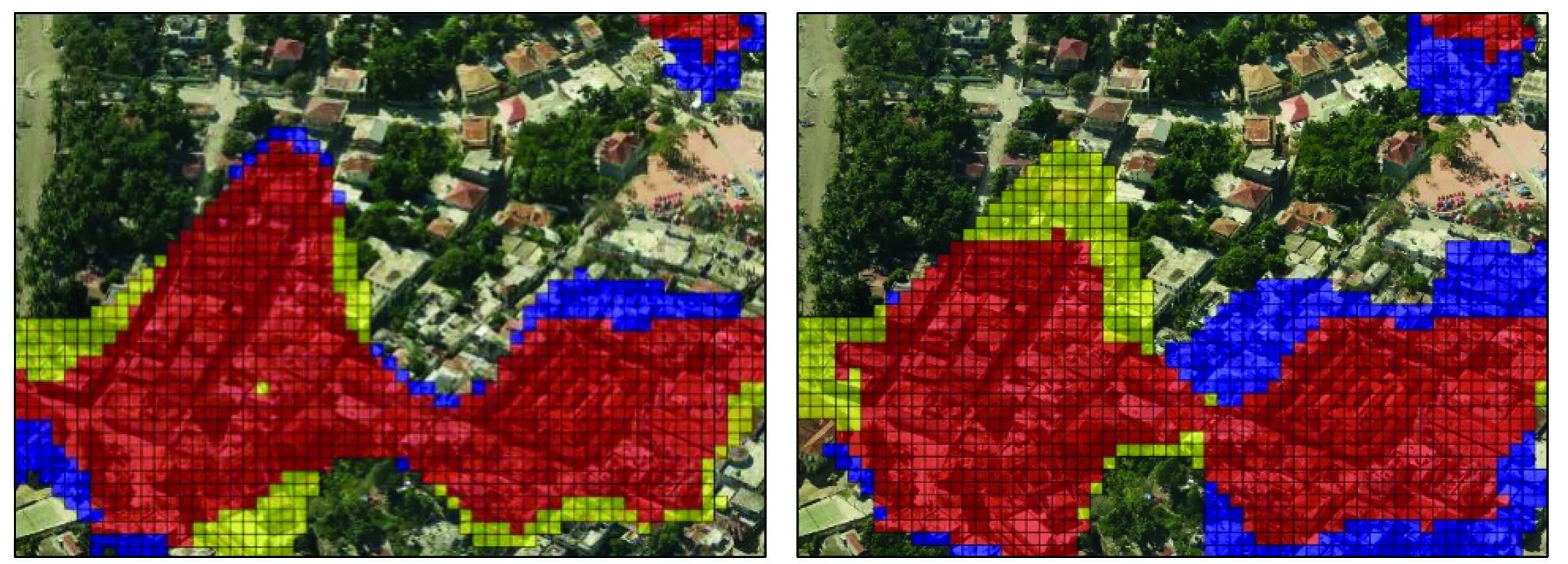
(a) 验证区域1基于VGGNet模型提取特征的结果 (b) 验证区域1基于AlexNet模型提取特征的结果

(c) 验证区域2基于VGGNet模型提取特征的结果 (d) 验证区域2基于AlexNet模型提取特征的结果

表2 验证集分类结果
从表2中可以看出,在验证区域1中,一共选取了2 537块,采用VGGNet模型提取的特征得到的结果中,漏检150块,误检129块,正确检测2 258块,达到89.0%正确率,9.8%的误检率和12.8%的漏检率; 而AlexNet模型提取的特征得到的结果中,漏检156块,误检291块,正确检测2 090块,达到82.4%正确率,19.1%的误检率和15.4%的漏检率。在验证区域2中,一共选取了1 600块,采用VGGNet模型提取的特征得到的结果中,漏检53块,误检166块,正确检测1 381块,达到86.3%正确率,20.0%的误检率和6.9%的漏检率; 而AlexNet模型提取的特征得到的结果中,漏检124块,误检158块,正确检测1 318块,达到82.4%正确率,19.1%的误检率和16.1%的漏检率。实验结果表明,本文提出的方法在建筑物损毁检测领域能达到80%以上的正确率,其中VGGNet模型提取的DCNN特征的实验结果正确率高达89%,表明本文所提出的方法在建筑物震害损毁检测领域是可行的,并且具有一定的潜力和研究价值。
由于本文实验所选影像的空间分辨率为1 m,所以分类精度不是很高,但是精度也能高达89%,这说明利用DCNN特征的方法是有优势的,可以应用于建筑物震害损毁区域的检测。实验结果中误检的区域成片地出现在损毁与未损毁区域的交界处,这与实验中采用重复区域有关,因为在损毁和未损毁过渡区域,损毁和未损毁的比例是逐渐变化的,边界区域容易出现误检和漏检。
4 结论与展望
本文提出了利用DCNN特征来进行建筑物震害损毁区域检测的方法,比较了常用的AlexNet和VGGNet这2种模型的能力,利用海地地震的高空间分辨率影像进行了实验,得出以下结论:
1) 利用DCNN特征结合SVM分类器来进行建筑物震害损毁区域检测的方法是有效的,该方法能够快速获取建筑物震害损毁信息。
2) 本文方法与基于SIFT特征的BOW方法进行了对比,结果表明: 在面向建筑物震害损毁区域的检测中,利用预训练DCNN提取的特征具有更好的表征能力。
3) 预训练的VGGNet模型比AlexNet模型在面向遥感影像的建筑物震害损毁评估应用中更具潜力。
本文方法虽然能达到较高的检测精度,但需要较多的训练样本,在实际应用时,常会遇到样本有限的困难,因此后续研究将在本文研究基础上,引入主动学习来选取尽可能少但具有代表性的样本以保证检测精度。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
铁道建筑技术(2021年4期)2021-07-21
计算机系统应用(2021年2期)2021-02-23
黑龙江水利科技(2020年8期)2021-01-21
电子制作(2019年13期)2020-01-14
电子技术与软件工程(2019年18期)2019-11-18
小学生学习指导(低年级)(2019年9期)2019-09-25
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
电子技术与软件工程(2017年14期)2017-09-08
