
命名数据网络多维命名机制研究
2019-06-10 07:52郭瑞彬
铁路计算机应用 2019年5期
郭瑞彬
( 北京交通大学 电子信息工程学院,北京 100044)
近年来,世界各国积极开展针对现有互联网体系结构缺陷的研究,取得许多具有影响力的研究成果,正式提出一些全新的、用于替代TCP/IP体系的未来互联网结构。命名数据网络(NDN,Named Data Networking)[1]就是其中的重要代表。有别于TCP/IP体系端到端的通信机制,NDN将内容与终端分离,实现了以内容为中心的网络体系与通信机制。也正是这一特点,使得NDN在支持物联网应用方面具有了先天优势。
目前,学术界已经就如何将NDN架构应用于物联网进行了广泛的研究,应用领域包括车联网、无线传感器网络、移动自组织网络等。然而,NDN在设计之初的一些特点对其在物联网方面的应用形成了阻碍。物联网数据经常以时间和空间作为数据的表征,因此,物联网数据天然具有时间空间等多维度特征。与之相应,用户(人或设备)在请求自己所感兴趣的内容时,通常也会以多个维度对其进行描述。但是,NDN架构在设计之初采用了类似统一资源定位符(URL)的分级可读一维命名规则,缺少应对物联网多维数据特征的能力,无法对来自上层应用的多维请求进行高效适配,也难以在网络层面进行高效的内容匹配。
鉴于以上情况,学术界提出了在NDN的网络层面和应用层面添加一个中间件层面,在不改变NDN一维命名规则的前提下为NDN增加多维数据支持能力。本文基于这一思想,采用已提出的中间件架构,以车联网应用场景为例,详细阐述中间件层面支持多维请求的工作原理,验证并进一步完善对原始数据名称的翻译和优化算法。另外,本文将提供数据仿真结果,对比经过优化算法处理前后,网络中获取相同数据量的内容时所需传递的兴趣包数量,验证算法的性能。
1 NDN与中间件简介
1.1 NDN
NDN关心内容本身而非内容的位置。作为对IP体系结构的重大革新,NDN仍保留了细腰角色。图1展示了两种架构的重要区别。在NDN架构中,细腰结构的核心不再是IP地址,而是内容模块。
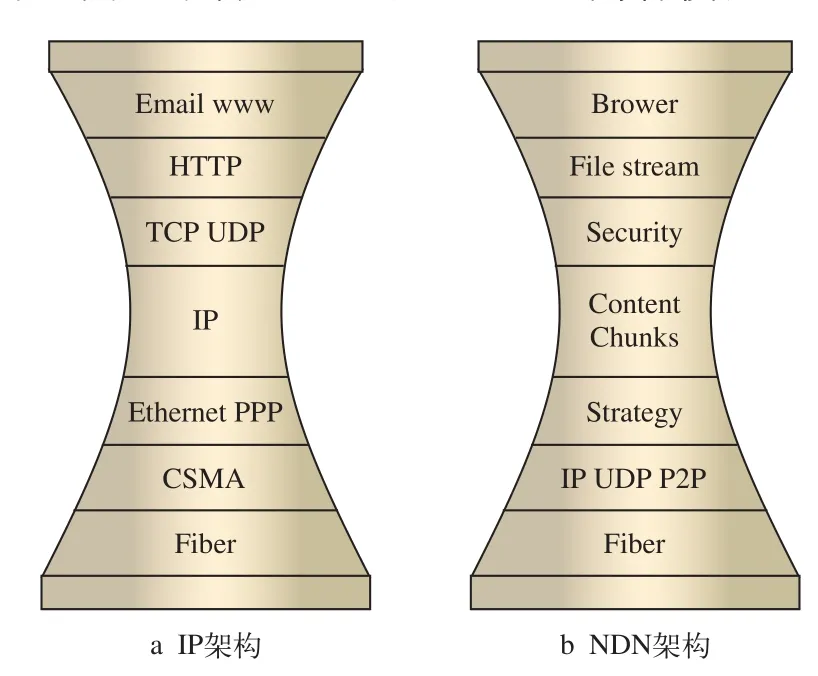
图1 IP架构与NDN架构对比
NDN通信过程由两种类型的数据包驱动:兴趣包(Interest Packet)和数据包(Data Packet),通信实体可以分为3种:消费者(Consumer)、生产者(Producer)和中继器(Router)。
通信时,消费者通过向网络发送兴趣包请求数据。当网络中的某个节点缓存了满足消费者兴趣的内容时,该节点通过数据包将数据通过中继器(通常是路由器)传递给消费者。此时,该节点被称为生产者。
为了实现数据包和兴趣包的转发功能,NDN路由器上维护着3种数据结构:待处理兴趣表(PIT,Pending Interest Table),转发信息表(FIB,Forwarding Information Base)和内容缓存(CS,Content Store)。PIT存储了路由器已经转发但还未被满足的兴趣包,以及该兴趣包的进接口和出接口。FIB用于记录路由信息,CS在一定时间内缓存经过该路由器的数据包,成为新的内容生产者。
1.2 中间件结构与功能
1.2.1 中间件结构
中间件层面位于网络层面和应用层面之间。设置中间件的目的是提高NDN对物联网应用多维数据名称请求的支持能力。如图2所示,中间件层面有两种外部接口:面向用户的北向接口和面向网络层的南向接口。为了与NDN的一维命名规则兼容,南向接口采用标准的NDN消息格式;北向接口则尽量支持多种维度、多种粒度的名称请求。在北向接口方向,采用多个独立组件对不同维度的物联网应用请求分别处理,每个组件均可独立进行该维度的数据名称翻译和优化聚合工作。
1.2.2 中间件结构功能
中间件结构的主要功能是提供由多维到一维的兴趣请求翻译和优化服务。
(1)基本翻译。当接收到来自应用层的内容请求后,北向接口按照标准的一维命名格式,根据语义对多维的请求进行语法转换,使之成为符合命名规范的原始数据请求。这一步被称为名称的基本翻译。考虑到用户一次对数据的请求量可能较大,如果直接使用原始数据请求作为兴趣包,网络的传输负担将过重,因此,还需要进行名称的优化聚合工作。
(2)聚合名字生成。原始数据请求具有离散化的特点,可根据原始名字的聚合特征生成可能的聚合名字。通过查询内容感知模块的数据库Metadatabase,名字优化组件将确认生成的聚合名字是否可以用来作为兴趣包请求数据。通常,聚合名字可以有效减少所需发送兴趣包的数量,显著缩短内容获取时延。
(3)异常处理。名字分解与数据融合模块具有异常处理的功能。当设计机制缺陷或其他原因导致不同节点的名称数据库不一致时,该模块将发挥重要作用。在本论文中,假设节点间通信机制有效可靠,不存在数据库不一致的问题,因此对该模块不作进一步讨论。
2 名称翻译与优化算法
本章以车联网为例,详细解释中间件结构支持多维名字请求的工作原理,并给出具体名字翻译和优化算法。
2.1 车联网场景概述
2.1.1 场景角色

图2 中间件层面体系架构
车联网场景沿用了命名数据网络体系结构初始设定的3种角色:生产者(Producer),消费者(Consumer)和中继器(Router)。
(1)生产者(Producer):生产者在本车联网场景中是固定部署在公路两侧的路边单元,按照指定的时间间隔搜集一定区域内的道路信息并存储在本地,等待用户获取。需要指出的是,不同的路边单元之间不会缓存对方的道路信息,避免存储器负担过重。
(2)中继器(Router):公路两侧的路边单元既可以作为生产者,也可以作为中继器。假设某一路边单元收到了兴趣包,如果它不缓存兴趣包所请求的数据,需要向其他单元转发兴趣包,则它被视作中继器。
(3)消费者(Consumer):车联网应用中,车辆节点作为消费者,定期向路边节点请求道路信息,为车辆的驾驶提供辅助。由于车辆所需要的信息种类是多样的,因此车辆产生的请求将包含多种维度。
2.1.2 名称格式
本场景考虑3种维度的数据请求:空间、时间和信息类型。在中间件结构中,3种维度的数据按照以下的格式组成兴趣包:
/middleware/space/…/time/…/type
对于每个维度,做出如下设计。
(1)空间维度
空间维度描述车辆节点希望获取的信息产生的位置,格式如下:
/space/road ID/kilometer section number
其中,road ID:车载导航系统中该路段的名字;
kilometer section number:考虑到任何一条公路均可视为一条有起点和终点的线段,以1 km为单位,将公路分割为1,2,3…,i,…;这里,i代表指定公路第i到(i+1) km的路段。
(2)时间维度
时间维度描述消费者希望获取的信息产生的时间,格式如下:
/time/date/five minutes index
其中,date:按照/year/month/day的格式指定日期;
five minutes index:一天中含有288个5 min长的时段,分割为0,1,2,…,n,…287;n代表 {n*5,(n+1)*5}时段。
(3)信息类型维度
路边单元收集的信息是多样的,例如,该路段的平均气温和车辆行驶速度。信息类型维度指定了某个兴趣包具体请求哪一类信息。格式如下:
/type/category
其中,category:在具体兴趣包中填写speed或temperature等。
2.2 基本名字翻译算法
假定车辆位于北京长安街。东起建国门,西至复兴门,全长约8 km。如果每公里部署一个路边单元,以5 min一次的频率生成该路段车辆的平均速度信息,车辆节点生成原始名字的流程和算法如下:
(1)车辆根据自身位置和车况确定需要的道路信息;
(2)车辆将对所需信息的描述通过北向接口传递给中间件;
(3)中间件根据基本语义翻译规则得到具有固定粒度的原始名字。
原始名字采用离散化的命名机制。图3展示了将连续的时间维度和空间维度请求分解并翻译成固定粒度的名字算法。
在图3中,深灰色区域表示车辆请求的内容,(x1,x2)表示请求覆盖的时间,(y1,y2)表示请求覆盖的公里数。需要指出,x1,x2;y1,y2可能不具备基本语义翻译要求的离散性,例如,x1可能表示3.5 km,而在2.1节中空间维度定义的格式要求起终点位置必须是整数公里,因此,有必要使用更大范围的空间间隔冗余覆盖用户请求。时间维度的翻译规则与空间维度相同。

图3 基本语义翻译算法
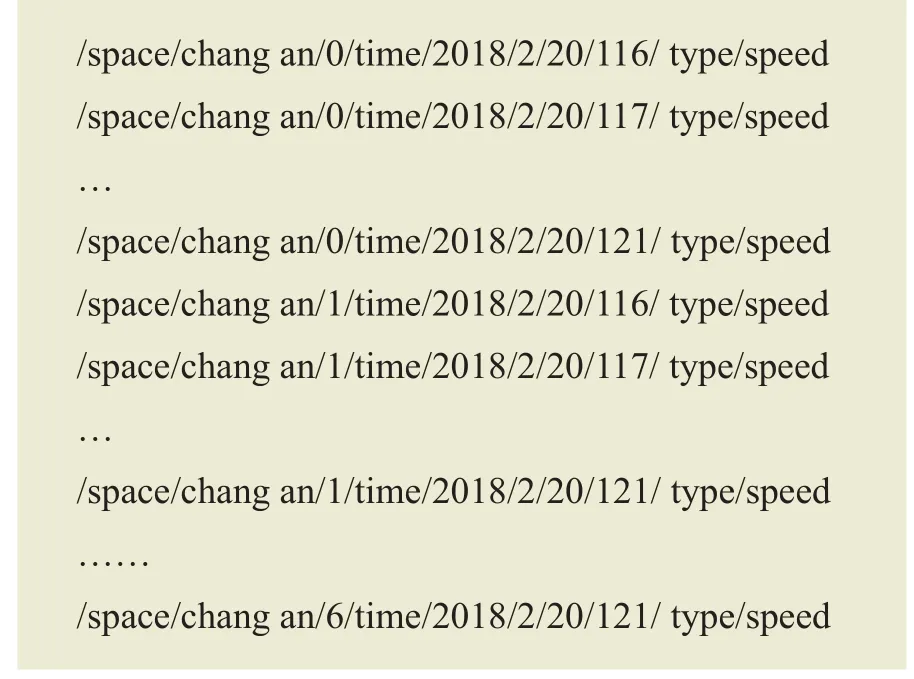
为方便起见,使用‘chang an’代表长安街。假设车辆需要2018年2月20日全天所有路边单元产生的信息,得到的原始名称如下:

在仅使用基本翻译算法的前提下,为了获取长安街20日全天的信息,共需发送8×288=2 304个兴趣包。
2.3 名称聚合优化算法
流量控制是互联网体系设计需要考虑的核心问题之一。大量的兴趣包在网络中传送会引起传输过载。中间件结构有必要采用相关算法,用更少的兴趣包获取相同的内容,提高请求效率。
名称聚合优化算法在每一维度独立工作。多个离散化的原始名字会聚合成一个聚合名字。通常,聚合名字比原始名字的长度显著缩短。
本节用一个实例帮助理解优化算法的工作原理。图4表示车辆希望获得的信息。

图4 车辆请求信息(a)
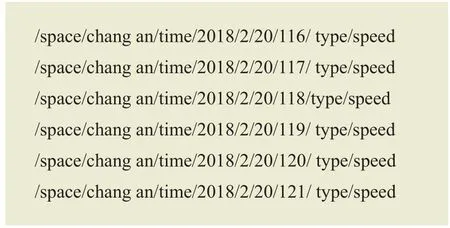
车辆请求信息的时间要求非常明确,但空间维度条件比较松散。根据2.2节的算法,为了冗余覆盖用户请求,生成如下的原始名字:

以上共产生8×6=48个原始名字。在空间维度,当所有路段的信息都被请求时,中间件可将8个离散的原始名称聚合成一个聚合度更高的名称,因此,原始名字经优化后得到如下6个兴趣包。

对比中间件执行优化处理算法前后,实现名称聚合使得获取资源效率极大提升,网络通信量显著减少。
2.4 优化算法的改进
2.3节的优化算法明显提升了内容获取效率,但仍存在设计机制缺陷。考虑车辆请求如图5所示的道路信息:
时间维度和空间维度的数据请求条件都十分明确。数据请求经北向接口进入中间件后,通过基本

图5 车辆请求信息(b)
翻译算法得到原始名字:

未经优化前,共有8×6=48个原始名字。按照2.3节给出的规则,只有离散化的名字足够多,在空间维度覆盖整条道路或时间维度覆盖全天时,才符合被聚合的条件,因此,48个原始名字按照2.3节算法优化后的聚合名字是:
优化算法处理前后,聚合名字的数量没有发生任何变化。2.4节原始名字仅比2.3节少了6个,聚合名字却多了36个,这样的机制明显存在缺陷。因此,对优化算法提出这样一个改进:
(1)按照2.3节提出的优化算法处理原始名字。如果符合聚合条件,产生的聚合名字数量明显少于原始名字,则将聚合名字交给南向接口生成兴趣包。
(2)如果优化后的名字相比原始名字没有发生变化,则依照聚合条件计算生成高度聚合的名字需要补充的请求数量。δ表示补充名字数量,λ表示原始名字数量。当式(1)成立,南向接口向网络层发送聚合名字,反之,向网络层直接发送原始名字。

由改进后的算法,本节示例补充以下6个名字后可生成高度聚合的名字:

带入具体数值,经计算,式(1)成立,因此,南向接口将向网络层发送与 2.3相同的聚合名字:
需要指出的是,本节算法补充的名字所表示的信息,车辆从未希望获得。网络按照兴趣包的请求将所有信息转发到中间件后,中间件应将用户不需要的数据自动丢弃。
观察上述过程,网络虽然传输了一些不需要的数据包,但兴趣包数量的减少对网络负载降低作用更加显著。本节算法的核心思想正是用内容数据传送量的少量增加换取兴趣数据传送量的显著减少。
3 实验仿真与结果分析
为验证本文给出的名字基本翻译与优化算法的性能,通过软件进行仿真。实验用软件包括常用数学分析软件Matlab和基于ns-3模拟器的ndnSIM(Named Data Networking Simulator)。仿真在Linux系统下进行。
3.1 仿真环境
ns-3是运行在Linux系统下的离散时间模拟器,ndnSIM则是专为NDN研究而开发的基于ns-3的模块化仿真工具。本实验由ndnSIM平台对车辆请求路况信息的全过程进行仿真,得到中间件生成的原始名字、聚合名字和部分情境下额外产生的补充名字。Matlab软件接受来自ndnSIM平台产生的数据,分析指定情境下网络的性能表现。
3.1.1 环境配置
本次的仿真实验基于第2章所描述的车联网情景。采用图6所示3×3的9节点方格网状路网结构。路网左上角的节点代表希望获取数据的车辆,其余8个节点表示部署在公路两侧的路边单元。

图6 车辆网络拓扑图
假设所有数据均储存在右下角的路边单元中,其他节点的路边单元仅承担路由转发的功能。仿真需要的网络性能相关参数如表1所示。

表1 网络性能仿真关键参数
3.1.2 评价指标
结合名字翻译与优化算法的特点,采用以下指标评价算法性能。
(1)请求压缩率。表示获取相同量的数据,发送兴趣包数量和原始名字的比率,衡量优化算法的有效性。压缩率越低,原始名字聚合程度越高,算法越有效。
(2)网络负载量。表示在一次数据请求过程中,生产者与消费者产生的数据量总和。本文提出的算法旨在从源头减少数据产生,因此,不考虑中间路由策略引起的流量差异。
(3)路由器平均时延。表示路由器转发一个包的平均时间。T代表路由器处理所有兴趣包和数据包的总时延,m代表数据包个数,n代表兴趣包个数,则路由器平均时延t可由式(2)计算得到:

路由器对兴趣包和数据包的处理能力存在明显差异。用路由器平均时延衡量改进优化算法对两类包占比配置的合理程度。该值越小,说明路由器平均处理速度越快,改进优化算法对包的配置越合理。
3.2 仿真结果
仿真过程基于第2章给出的场景,仅考虑空间维度的名字聚合。依据第2章给出的翻译规则,空间维度1~8 km间可生成8个不同的原始名字。时间维度认为产生了6个名字。根据仿真结果,分析名字优化算法和改进型算法的有效性。
3.2.1 请求压缩率
请求压缩率表示获取相同量的数据,发送兴趣包数量和原始名字的比率。比例越低,算法越有效。
如图7所示,对于名字优化算法和改进的优化算法,压缩效率存在明显差异。当数据请求不多时,两种算法均不符合名字聚合条件,得到的兴趣包数量与基本翻译得到的原始名字数量相同,压缩率也相同,均为1。当请求数量增加,由于改进型优化算法的聚合条件比基本型优化算法的更宽松,基于2.4节假定的场景,在42~47个原始名字范围内,使用改进型优化算法,压缩率仅0.13,基本优化算法接近1。结果验证了算法的有效性。

图7 请求压缩率对比
3.2.2 网络负载量
网络负载量表示在一次数据请求过程中,生产者与消费者产生的数据量总和。负载量越小,算法对网络负载的控制越有效。
实验结果如图8所示,基于2.4节场景,原始名字的数量接近聚合条件时,改进型优化算法产生的网络负载量显著低于未改进优化算法。使用基本优化算法网络负载量约为55 KB,改进后网络负载量迅速下降到50 KB。出现这一情况的主要原因是改进型优化算法大幅减少了在网络中传递的兴趣包数量,同时,额外传递的数据包数量却不多。结果符合预期。
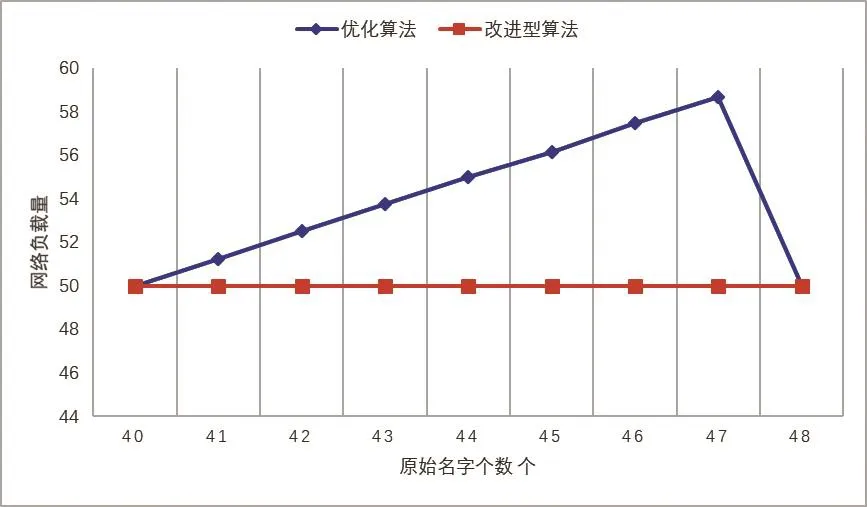
图8 网络负载量对比
3.2.3 路由器平均时延
路由器平均时延。表示路由器转发一个包的平均时间。该值越小,说明路由器平均处理速度越快,改进优化算法对包的配置越合理。
实验结果如图9所示,改进后的优化算法明显对路由器更加友好。在接近基本优化算法聚合条件的范围内,改进型优化算法使得路由器平均处理时间下降到0.77 ms左右,显著低于未改进时0.9 ms的平均时间。兴趣包报头信息量比数据包报头更大,路由器需要的处理时间更长,因此请求相同的内容,使用兴趣包的数量越少越好。实验结果证明,改进型算法实现了上述目标。

图9 路由器平均时延对比
4 结束语
为提高NDN对多维名称请求的支持能力,本文引入了中间件结构,并给出与之相匹配的名字翻译和优化算法。针对优化算法存在的缺陷,提出了改进措施。仿真结果表明,中间件和相关算法搭配使用,可以显著提高NDN对物联网多维数据请求的支持能力。除此之外,对于名字优化算法,还存在进一步改进的空间。改进式优化算法对网络性能的提升是明显的,但是使用改进优化算法的条件有待进一步研究,例如:式(1)范围确定在15%是否最优;是否有可能将聚合规则要求的粒度降低等。
猜你喜欢
科教新报(2022年24期)2022-07-08
当代陕西(2022年4期)2022-04-19
作文小学中年级(2021年10期)2021-12-26
科教新报(2021年23期)2021-07-21
恋爱婚姻家庭·养生版(2021年5期)2021-05-31
当代陕西(2020年22期)2021-01-18
中华诗词(2019年7期)2019-11-25
电子制作(2018年14期)2018-08-21
电子制作(2017年13期)2017-12-15
计算机工程与设计(2014年4期)2014-05-04
