
Spark Streaming中参数与资源协同调整策略
2019-06-07 15:08梁毅刘飞常仕禄
软件导刊 2019年1期
关键词:资源分配
梁毅 刘飞 常仕禄


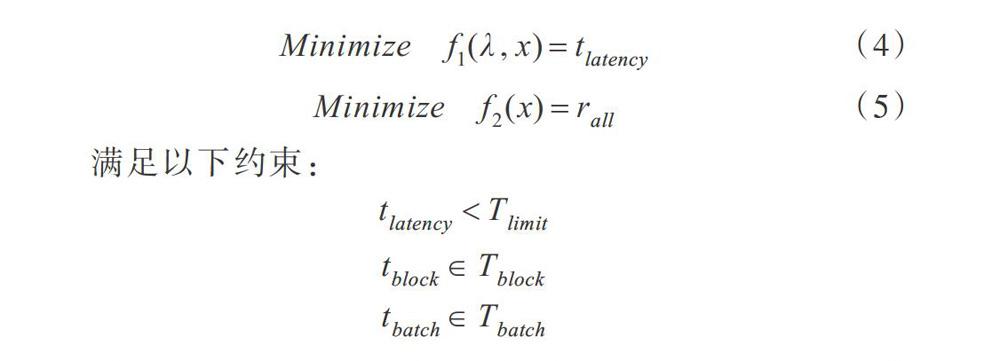
摘 要:Spark Streaming是一种典型的批量流式计算平台,可用于处理持续到达的数据流。流式数据最重要的两个特征是波动性和时效性。利用动态调整系统参数和动态调整资源满足不同数据到达速率的响应延迟,但调整参数的方式具有局限性,其用户成本较大。因此提出一种参数和资源协同调整策略,采用动态邻域粒子群算法找到一种满足SLO目标且使用资源最少的系统方案。实验表明,AdaStreaming与DyBBS相比,延迟性降低了70.1%,在资源使用量上比DRA降低了42.1%。
关键词:Spark Streaming; 动态邻域粒子群;参数配置;资源分配
DOI:10. 11907/rjdk. 181652
中图分类号:TP301文献标识码:A文章编号:1672-7800(2019)001-0045-03
Abstract:Spark Streaming is a typical batched streaming processing system that can be used to process continuously arriving data streams. The two most important characteristics of streaming data are its volatility and timeliness. The method of dynamical parameter configuration and dynamical resource allocation are proposed to guarantee the end to end latency with different data arrival rates. However, the method of dynamical parameter configuration has limitation on scope of application, and the method of dynamical resource allocation will bring greater cost to users. Therefore, this paper proposes a parameter and resource coordination adjustment strategy, using dynamic neighborhood particle swarm algorithm to find a solution that can achieve resource minimization on the premise of meeting the SLO goal. Experiments show that AdaStreaming reduced latency by 59% against DyBBS, and reduced the amount of resources by 34% against DRA.
0 引言
随着大数据应用场景的多样化,各种行业产生了海量流式数据[1-3]。流式数据最重要的两个特征是波动性和时效性,不同时刻流式数据到达的速率是波动的,且需在一定时间内完成处理[4]。Spark Streaming[5]是一种典型的批量流式计算平台,被工业界和学术界广泛采用。
随着云计算的发展,许多流式计算平台被部署到云上,为用户提供灵活的服务[6]。对于这类部署在云上的Spark Streaming平台,满足用户SLO和最小化资源使用以降低用户成本成为最重要的两个目标[7-8]。现有研究主要从3方面进行优化:①数据丢弃[9-11]。但该方法不适用具有“至少执行一次”语义保证的应用;②动态调整参数配置[12-13]。然而,当数据速率激增时,当前资源分配情况下可能出现调整参数无法使延迟满足需求的情况;③动态调整资源。当数据处理落后于数据流入时,会增加分配的资源数量以提升数据处理速率[14]。考虑到云环境按需付费的服务模式,该方法会给用户带来巨大的成本开销。
本文通过分析影响Spark Streaming平台性能的一些因素,提出一种参数和资源协同调整策略AdaStreaming。该策略采用一种动态邻域粒子群算法,在满足SLO的前提下,選择一种资源使用量最少的参数和资源调整方案,并以此为依据进行系统调整。实验表明,与动态调整参数的DyBBS方法相比,本文提出的AdaStreaming在延迟上降低了59%,与动态调整资源的DRA方法相比,AdaStreaming在资源使用量上降低了34%。
1 Spark Streaming
Spark Streaming构建于Spark[15]之上,其处理流程如图1所示。流入系统的数据以一定的划分间隔分割成分开的数据块,然后以一定批次的划分间隔划分为独立的批次任务,并按顺序提交到Spark引擎中执行。根据上述处理过程,可以看出数据块划分间隔和批次划分间隔是影响系统性能的两个重要参数。
2 SparkStreaming中参数与资源协同调整策略
2.1 动态邻域粒子群算法
粒子群优化算法(Particle Swarm Optimization,PSO)是一种基于迭代的优化算法,易于实现且无较多参数需要调整[16-18]。动态邻域粒子群(DNPSO)算法可在不同阶段考虑不同目标,用于多目标约束优化问题的求解[19-20]。对于两个目标的问题,第一个目标[f1]可确定粒子邻域,第二个目标[f2]作为度量粒子质量的适应度函数。因此邻域函数[f1]找到粒子i的邻域[Ni]后,粒子i在t+1时刻的个体最优位置可由式(1)计算。
猜你喜欢
计算机仿真(2023年9期)2023-10-29
英语文摘(2020年10期)2020-11-26
测控技术(2018年7期)2018-12-09
计算机系统应用(2018年7期)2018-07-18
计算机应用(2016年10期)2017-05-12
文艺生活·中旬刊(2016年12期)2017-01-18
计算机工程(2014年6期)2014-02-28
