
可预测的差分扰动用户轨迹隐私保护方法
2019-06-06 06:16:56胡德敏
小型微型计算机系统 2019年6期
胡德敏,詹 涵
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
近年来,有定位能力移动设备的日益普及和无线通信技术的不断提高,基于位置服务(loaction-based service,LBS)得到广泛应用,给人们生活带来极大便利,但用户获取服务的同时,也有可能泄露自己真实位置.如果用户连续查询,由于轨迹位置间的相关性更易泄露真实位置.
位置服务分两种类型:快照LBS和连续LBS.快照LBS指用户只发送一次当前位置信息给位置服务器获取服务,连续LBS指用户按照一定频率周期性地发送当前位置信息给位置服务器获取连续的服务.现实生活中,用户多执行连续查询,因此连续LBS轨迹隐私保护比快照LBS位置隐私保护更具有挑战性.
2 相关工作
越来越多的学者开始关注连续LBS轨迹隐私保护.由于轨迹位置间的相关性,现有的快照LBS位置隐私保护方法在连续查询时不能很好的起到轨迹隐私保护作用.因此,对用户轨迹隐私保护需要提出更有效的方法,目前,这方面的研究主要有泛化、混合区和扰乱等方法[1].
泛化指用一个泛化的空间区域代替用户真实位置,也称隐藏区.文献[2]提出一个支持连续空间查询的k匿名隐藏区生成算法KAA.为了保证n次连续查询后,该隐藏区仍然满足k匿名,需要包含最初生成的k个用户,因此隐藏区会随着这k个用户的运动而逐渐扩展,最终导致隐藏区因过大而失效.文献[3]使用假名代替用户真实身份的方法.但攻击者可以很容易地从用户日常活动中获得辅助信息,将用户的假名与他的真实身份相关联,因此,使用长期假名不足以保护用户轨迹位置隐私.为了解决这个问题,Xu等人[4]提出将用户的活动区域划分为混合区和应用区,用户在混合区交换假名,在应用区请求服务,混合区指的是一个小区域,例如一个道路交叉口.混合区打破了持续暴露的位置信息,从而保护了用户的下一个位置,但混合区部署将影响查询的服务质量.扰乱的方法在近年来有较多的研究,它的思想是将各个时刻的真实位置通过一定的变换,生成假位置,用假位置代替用户真实位置请求服务.文献[5]先使用DLG算法为每个快照位置生成一组虚假位置,再使用DPC算法将生成的虚假位置连接成几条虚拟路径,此方法无法判断生成的虚拟轨迹是否合理.
近年来,开始采用差分隐私[6]来控制连续查询中添加的噪声量,把噪声和隐私建立定量的关系.文献[7]用马尔科夫链表示两个连续位置的关系,提出基于差分隐私的“δ位置集”来保护每个时间戳的真实位置,进而提出位置扰动机制PIM,但只考虑了单个时刻上的位置发布,忽略了已发布的当前位置对之前真实位置的影响.文献[8]通过添加高斯噪声,产生与原始轨迹序列自相关函数一致的相关性噪声序列,但统计相关特性的方法只适用于相关性较强的平稳序列中,对于非平稳序列不再适用.文献[9]将原始轨迹数据集转换成用户位置二分图,并且注入仔细校准的噪声以满足所需的差分隐私保证,但关联矩阵的选择是一个问题.文献[10]向用户真实位置添加可控的平面拉普拉斯噪声生成干扰位置并将其作为锚点发送给位置服务商,解决了单次查询的位置隐私保护问题.若将该方法直接用于连续查询,由于轨迹位置间的相关性,随着查询次数的增加,用户轨迹位置隐私水平越来越低.
虽然差分隐私机制作为一种随机扰动方法被广泛研究,但现有的轨迹差分隐私保护方法大多将轨迹位置作为独立的序列来处理,添加独立的噪声,攻击者可以利用一些滤除噪声的方法过滤噪声,同时利用轨迹间位置的相关性提高推测成功的概率.
本文提出一种可预测的差分扰动轨迹隐私保护方法.由预测函数、测试函数和噪声机制三部分构成,如果预测函数生成的干扰位置通过测试函数,则直接使用该干扰位置去请求服务,否则使用噪声机制向当前真实位置添加噪声,重新生成一个干扰位置去请求服务.
本文的组织结构如下:第1节介绍轨迹隐私保护的背景;第2节介绍轨迹隐私保护的研究现状;第3节描述可预测的差分扰动用户轨迹隐私保护方法;第4节进行实验以及实验结果分析;第5节对全文进行总结.
3 可预测的差分扰动用户轨迹隐私保护方法
3.1 相关定义
定义1.用户轨迹T={(x1,y1,t1),(x2,y2,t2),…,(xn,yn,tn)}.其中(xn,yn,tn)表示用户在tn时刻的位置为(xn,yn),T[i]表示轨迹T的第i个元素,|T|=n表示轨迹T的长度.
定义2.用户轨迹隐私需求Tq={ε,r}.其中ε表示轨迹隐私水平即轨迹隐私预算,r表示隐私保护区域的半径.
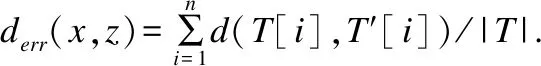
3.2 独立噪声机制
文献[10]通过向用户真实位置添加平面拉普拉斯噪声生成干扰位置,用该干扰位置代替用户真实位置请求位置服务器获取服务.在连续查询中,如果以同样的方法向用户轨迹中的每个真实位置都添加这样的噪声,为每个位置生成一个干扰位置,同时生成一条虚假轨迹称做独立噪声机制(Independent Noise Mechanism,INM),算法1中N(εN)表示噪声机制,εN表示噪声机制隐私水平,满足εN-地理不可区分性.
用户每次查询都会消耗一部分隐私预算,连续n次查询消耗n次隐私预算,当隐私预算全部消耗完时查询停止.由于轨迹位置间的相关性,随着查询次数的增加,位置点越来越多,隐私程度越来越低,隐私水平要求也越来越高,消耗的隐私预算总比前一次要多,导致隐私预算快速消耗.因此,该方法仅在查询次数很少时才适用.
算法1.独立噪声机制INM
输入:用户轨迹T,隐私水平εN;
输出:虚假轨迹T′.
1.T′←0;
2.for(i=1;i++;i≤|n|);
3.z←N(εN)(T[i]);//为每个真实位置生成干扰位置
4.add z toT′;
5.returnT′;
3.3 预测噪声机制
预测噪声机制(Predictive Noise Mechanism,PNM)由预测函数Ω、测试函数Θ和噪声机制N组成.预测函数Ω根据已有的干扰位置预测一个新的接近真实位置的点,如果该点通过测试函数,直接使用该点请求服务;若未通过,则用噪声机制N重新生成一个干扰位置,用新生成的这个干扰位置代替用户真实位置去请求服务.轨迹位置间的相关性是预测噪声机制较大的一个优点,相关性越高,生成的干扰位置通过测试概率越大,需要重新添加噪声的真实位置点越少,测试函数消耗的隐私预算远低于噪声机制消耗的隐私预算.
a)预测函数
序列r=[z1,b1,z2,b2,…,zn,bn]由每个真实位置对应的干扰位置和布尔值b组成.其中z表示干扰位置,布尔值b表示干扰位置是否通过了测试,b=0通过,称当前真实位置为容易点,b=1未通过,称当前真实位置为困难点.预测函数Ω:r→z以序列r为输入,当前真实位置的预测干扰位置z为输出.
b)测试函数
测试函数Θ(εθ,l,z):x→b,以当前真实位置x为输入,b为输出,测试z是否可用作当前真实位置的干扰位置.如果测试成功,z直接使用;否则,使用噪声机制N重新另生成一个干扰位置,测试函数定义如下:
(1)
其中,d(,)是两点之间的欧几里得距离,测试函数消耗的隐私预算εθ>0,测试阈值l∈[0,+∞),Lap(εθ)为测试函数添加的线性拉普拉斯噪声,干扰位置z∈Z,真实位置x∈R2.
c)噪声机制
噪声机制[10]N(εN):x→z,其中εN表示噪声机制消耗的隐私预算.即利用差分隐私按照期望的隐私预算,向用户真实位置添加可控的拉普拉斯噪声产生扰动,该扰动位置在一定范围内和用户真实位置不可区分,文献[10]详细讲解了以下算法.
算法2.干扰位置生成算法
输入:用户位置Ω,隐私需求Θ(εθ,l,z),用户所在区域N(εN),位置坐标精度T′,可接受区域半径ψ=neasy/|T|.
输出:干扰位置neasy.
1.ρ=εβ(r)/ε;
3.calculate angelεuniformly inρ;//计算derr
4.calculatez=(x+rcosθ,y+rsinθ);
5.divide area intoGaccording toδ;
6.getz′ by remappingzto the closest pointzonG;
7.ifra≤rand ifz′∉A
8.getz″ onA∩G
9.z←z″;
10.returnz;
噪声机制用来给未通过测试的干扰位置为相应的真实位置添加噪声,用算法1重新生成一个干扰位置请求服务.
d)预算管理器
测试函数的参数εθ,l和噪声机制的参数εN在每步都需要重新计算,这通过预算管理器β动态配置.β(r)=(εθ,εN,l)以当前时刻的序列r为输入,以测试函数和噪声机制的参数εθ,l,εN为输出.测试函数消耗的隐私预算远小于噪声机制消耗的隐私预算,否则使用独立噪声机制更加方便.轨迹间位置的相关性越高,预测点大部分通过测试,不需要额外添加噪声;若相关性太低,测试总是失败,不仅噪声机制消耗隐私预算,测试函数消耗也需要消耗隐私预算,这种情况下隐私预算水平消耗迅速.
使用预算管理器β配置序列r的预算εβ(r)定义如下:
(2)
其中,βθ(r)为当前测试函数消耗的隐私预算,b(r)为测试函数结果,βN(r)为噪声机制消耗的隐私预算,εβ(r-1)为之前序列消耗的隐私预算.
我们知道,测试函数Θ对于∀εθ,l,z满足εθ-地理不可区分性,噪声机制N对于∀εN满足εN-地理不可区分性,则预测噪声机制PNM满足εβ(r)-地理不可区分性,如下,
PIM(T)(r)≤eεβ(r)d(x,x′)PIM(T′)(r)
(3)
预测噪声机制的准确性α(δ)取决于噪声机制N(εN)的准确性和测试函数添加的拉普拉斯机制Lap(εθ)的准确性,分别用αN(δ)和αθ(δ)表示,则α(δ)=max(αN(δ),l+αθ(δ)),通常取δ=0.9.
引入一个参数γ调节测试阈值?和添加的线性拉普拉斯噪声比例,γ=αθ/l(0≤γ≤1),γ不能超过1,否则添加的噪声比阈值l还大,通常把γ设置为0.8.介绍两种预算管理器:限制轨迹偏移度和固定隐私预算消耗率.
1) 限制轨迹偏移度
我们总是希望生成的虚假轨迹尽可能接近真实轨迹,如果距离太远得不到想要的服务质量,轨迹隐私保护也不再有意义,考虑限制轨迹偏移度的情况下,用户需要提供参数ε.
预算管理器1.限制轨迹偏移度
budget managerβ(r)
ifε(r)≥εthen stop
returnεθ,εN,l;
2) 固定隐私预算消耗率
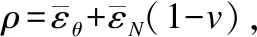
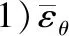
2)困难点在轨迹中均匀分布.这两个假设帮助计算预测成功率,预测成功率越高,噪声机制消耗隐私预算越少.ρ在固定隐私预算消耗率情况下是常量,在限制轨迹偏移度情况下动态计算.
预算管理器2.固定隐私消耗率
budget managerβ(r)
ifε(r)≥εthen stop
returnεθ,εN,l;
若预算管理器β返回的参数εθ=0,l=+∞,此时测试函数一定值为0;若预算管理器β返回的参数εθ=0,l=-∞,此时测试函数一定值为1,此时选择跳过测试函数以节约隐私预算水平.
预测噪声机制PNM整体算法描述如下:
算法3.预测噪声机制PNM
输入:用户轨迹T,轨迹隐私预算ε.
输出:虚假轨迹T′.
1.T′←0,r←0;
2.for(i=1;i++;i≤|n|) do;
3.β(r)=(εθ,εN,l);//预算管理器动态配置参数εθ,εN,l
4.z←Ω(r);//预测函数生成干扰位置
5.b←Θ(εθ,εN,l);//测试函数测试干扰位置是否通过测试
6. if(b=0)thenz′←z
7. elsez′←N(εN)(x)//没有通过测试使用噪声机制
8. end if
9.addb,z′ to r
10.end for;
11.returnr,T′;
算法3中,首先通过预算管理器配置预测噪声机制每步需要的参数,以当前时刻的结果训练r为输入,输出测试函数需要的隐私预算εθ,l,噪声机制需要的隐私预算εN,然后运行预测函数Ω得到预测干扰位置z,再使用测试函数Θ(εθ,l,z)测试预测.如果测试成功,则返回预测,否则使用噪声机制N(εN)生成新的干扰位置,最后得到用户真实轨迹对应的虚假轨迹T′.
4 实 验
实验在Windows7系统上用Java语言实现,运行环境为Intel Core i5、CPU3.2 GHz、4GB内存.实验数据来自著名的数据集GeoLife[11],它收集了北京182个用户轨迹,轨迹长度大致划分三组:小于5公里、5-20公里和20公里以上,用户移动时间58%少于1小时,26%为1至6小时内,16%为6小时以上.我们假设用户仅在静止或以低速(低于15km/h)移动时才查询LBS,如果位置变化很快,那么查询相对于当前位置信息没有意义.
数据集仅收集了用户移动轨迹,而不是用户实际查询LBS的位置点集合,为了符合真实LBS场景,对数据集做一些预处理,根据用户的移动速度,选择速度小于15公里/时的轨迹部分,采用3个指标来评价算法的有效性:
1)预测成功率.预测成功率ψ=neasy/|T|表示预测函数输出的干扰位置是容易点的个数占总位置个数的比例,其中neasy表示生成干扰位置是容易点的个数.
2)隐私预算消耗率.轨迹中每个发送请求位置消耗的隐私预算率ρ=εβ(r)/ε,表示预测噪声机制隐私预算消耗的速率,通过这个值,可以知道隐私预算需消耗的有多快,大概估算初始预算下能够覆盖多少个查询点.
虽然该机制的目的是隐藏用户真实位置,但每个位置发出请求的时间是公开的,我们可以使用上一位置请求服务的时间来估计用户可能已经经过的距离.如果这个距离小于所要求的范围,那么相邻的这两个位置一定满足ε-地理不可区分性,我们可以跳过测试直接使用上一位置生成的干扰位置.如果用户比预期的要快(比如他坐的是地铁),预测函数将会预测出一个不准确的干扰位置.这种方法的风险在于关联时间和移动距离的速度,为了安全起见,应该设定期望的最大移动速度,值太小跳过的测试点太多没有意义,值太大达不到所要求的偏移范围.
假设用户移动速度v=0.8km/h,同时设定r=0.5km,ε=In10,ε是全局隐私水平,表明在半径r为0.5km的范围区域内,任意两点生成同一干扰位置的可能性最多相差10,这在人口密集的城市区域是一个合理的隐私水平.如果固定隐私消耗率为3%,对应大约30次查询,对大多数用户来说,是一个合理的查询次数,如果限制轨迹偏移度在3公里范围内,对步行用户来说,也是一个合理的范围.
为了便于实验观察,选取8个用户作为连续查询用户,分别以t=5min、10min、15min、20min、25min、30min、35min、40min作为查询时间间隔,t值越小表明查询越频繁,依次编号1,2,3,4,5,6,7,8.选取符合要求的用户轨迹分别运行预测噪声机制PNM和独立噪声机制INM20次,计算其平均值,先固定隐私预算消耗率,得到实验结果如图1-图3所示.
由图1可以看出,预测函数生成干扰位置的预测成功率随查询时间间隔的变长而逐渐减小.查询时间间隔短,查询频繁,生成的干扰位置点就越多,预测函数的输入结果序列r越长,预测输出干扰位置更加准确,预测成功率也更高.同样变化的是跳过测试函数的干扰位置个数,预测成功率越高,跳过测试函数的干扰位置个数也越多,节省更多的隐私预算.
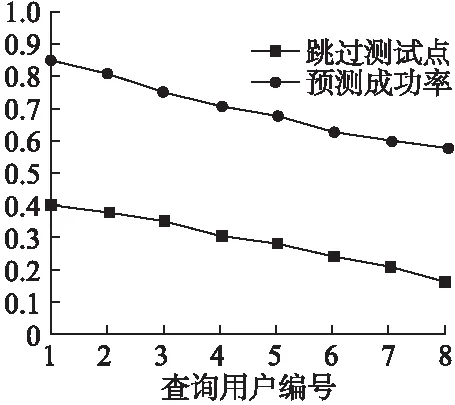
图1 预测噪声机制统计数据Fig.1 Prediction noise mechanism statistics
由图2和图3可以看出,固定隐私预算消耗率ρ为3%,预测噪声机制的隐私预算消耗率整体来说较平稳且接近独立噪声机制.轨迹偏移度上因轨迹间位置相关性,预测噪声机制性能要优于独立噪声机制,但两者均随着时间而逐渐增大.
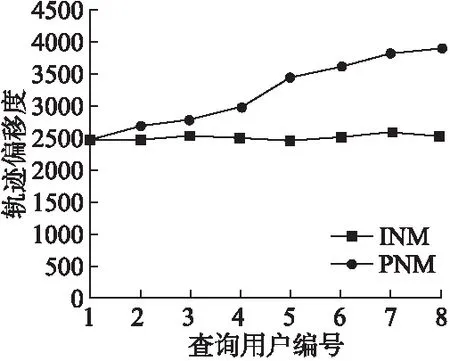
图2 预测噪声机制和独立噪声机制轨迹偏移度对比Fig.2 Comparison of predicted noise mechanism and independent noise mechanism trajectory offset
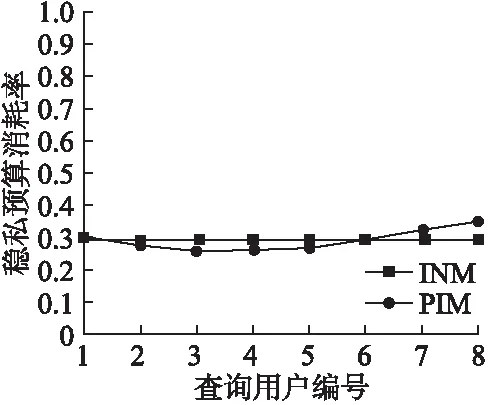
图3 预测噪声机制和独立噪声机制隐私预算消耗率对比Fig.3 Comparison of predictive noise mechanism and independent noise mechanism privacy budget consumption rate
现在限制轨迹偏移度derr在3公里范围内,得到实验结果如图4-图6所示.由图4可以看出,和固定隐私预算消耗率一样,预测成功率和跳过测试点仍然随着查询更加偶然而呈下降趋势,但是比固定隐私预算消耗率速率缓慢的多,这是因为限制了轨迹偏移度范围,使得出的干扰位置点更接近用户查询真实位置,预测成功率自然也更高.
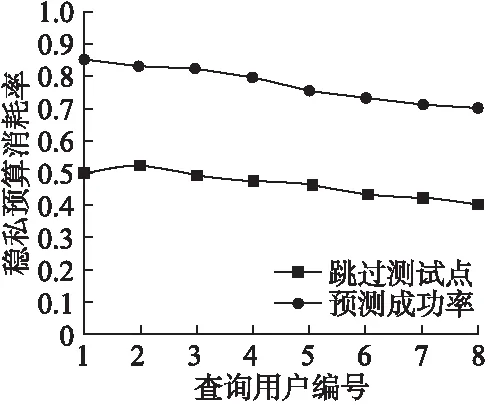
图4 预测噪声机制统计数据Fig.4 Prediction noise mechanism statistics
由图5和图6可以看出,限制轨迹偏移度情况下,独立噪声机制INM轨迹偏移度为一常量3000m,而预测噪声机制PNM小幅度波动,但没有超过3000m;隐私预算消耗率比固定隐私预算消耗率情况下消耗更多,且随着查询间隔时间变长而逐渐增大.
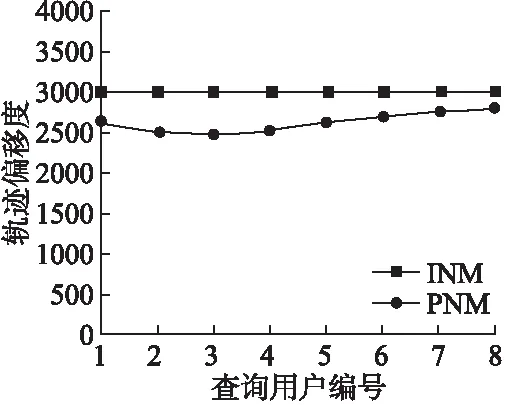
图5 预测噪声机制和独立噪声机制轨迹偏移度对比Fig.5 Comparison of predicted noise mechanism and independent noise mechanism trajectory offset

图6 预测噪声机制和独立噪声机制隐私预算消耗率对比Fig.6 Comparison of predictive noise mechanism and independent noise mechanism privacy budget consumption rate
5 结束语
本文提出一种可预测的差分扰动轨迹隐私保护方法,通过预测噪声机制实现,预测噪声机制由预测函数、测试函数和噪声机制三部分组成,同时使用两种预算管理器来配置测试函数和噪声机制需要的参数,节省每次查询时消耗的隐私预算.实验结果表明,不管是固定隐私预算消耗率还是限制轨迹偏移度,与独立添加平面拉普拉斯噪声到轨迹中的每个位置相比,预测噪声机制在轨迹偏移度和隐私预算消耗率上均有较高优势,很好地解决了用户轨迹位置隐私保护问题.
猜你喜欢
水利水电快报(2023年11期)2023-11-23 21:51:43
电脑爱好者(2020年10期)2020-07-28 17:10:30
数码世界(2018年2期)2018-12-21 21:23:46
汽车电器(2018年1期)2018-06-05 01:22:56
物联网技术(2017年5期)2017-06-03 10:16:31
上海理工大学学报(2016年2期)2016-06-02 09:22:25
陕西理工大学学报(自然科学版)(2015年6期)2016-01-25 11:00:22
电子设计工程(2015年12期)2015-02-27 12:06:09
科技资讯(2014年19期)2014-10-22 20:04:47
江苏高职教育(2014年2期)2014-07-16 07:10:04
