
一种基于混合采样的非均衡数据集分类算法
2019-06-06 05:46胡晓辉吴嘉昕
小型微型计算机系统 2019年6期
张 明,胡晓辉,吴嘉昕
(兰州交通大学 电子与信息工程学院,兰州 730070)
1 引 言
大数据时代使得数据的知识获取变得更加便捷,促进了数据密集型科学的发展.分类是机器学习和数据挖掘中重要的信息获取手段之一,传统的分类方法有线性判别分析法、决策树、贝叶斯、Logistic回归分析和支持向量机等[1-4],但传统的分类算法没有考虑数据的均衡性,在非均衡分类问题上仍面临着巨大的挑战.所谓非均衡数据,是指某一类样本的数量明显少于另一类样本的数量,即多数类(负类)和少数类(正类)存在比例失衡[5].在非均衡数据集中少数类可能比多数类包含着更多有价值的信息,在这种情况下,正确识别少数类比正确识别多数类更加重要.
随机森林[6]通过自助采样[7]获取样本集,从而构建决策树得到很好的分类预测效果,常被用于数据集分类研究[8,9]中.但在实际应用中,因为所获得的数据常常表现为非均衡数据[10],所以在数据处理方面经常引入欠采样和过采样方法,对于非均衡数据集的处理Chawla 等人提出了SMOTE算法[11],该算法通过人为构造少数类样本使得数据集趋于平衡.由于该方法没有考虑到少数类内部分布不均的现象,针对文献[11],Han等人后来又在SMOTE方法的基础上提出了Borderline-SMOTE方法[12],该方法把少数类样本分为安全样本、边界样本和噪声样本3 类,并对边界样本进行近邻插值.这些算法虽然都一定程度上改善了非均衡数据集处理的问题,但是因为这些算法都只是对少数类样本进行过采样处理,所以最后可能会导致样本集分类时出现过拟合现象.由于欠采样方法可能会失去许多样本的信息,而过采样方法可能会使少数类样本过拟合.本文提出了一种新的基于混合采样的随机森林算法(USI).在对非均衡数据分类的研究中,基于混合采样的随机森林算法(USI)与基于样本特性欠采样的随机森林算法(RU)、基于IS欠采样的随机森林算法、基于SMOTE过采样的随机森林算法(SMOTE)、基于USMOTE过采样的随机森林算法以及基于随机欠采样与SMOTE相结合的随机森林算法(RU-SMOTE)进行比较,实验结果表明改进算法(USI)进一步提高了在非均衡数据集上的G-mean值,F-value值,具有更高的综合分类准确率.
2 传统算法与原理
2.1 随机森林
随机森林[6]基本思想可概括为:包含多个决策树的分类器.首先有放回地重复随机抽取原始训练样本集中一定量的样本生成新的训练集,然后对这些训练集建立决策树模型得到不同的分类结果,最后统计分类结果来决定最优的分类结果.随机森林算法详细步骤如下:
1)设原始训练集为N,采用Bootstrap重抽样方法[7]有放回地随机抽取t个新样本集,构建t棵分类树.每个样本包含v个属性;
2)在样本v个属性中进行随机特征选择,选择m(m 3)每棵决策树不做任何修剪,最大限度地生长,多个决策树形成的分类器组成随机森林; 4)当待测样本X进入该随机森林后,随机森林里的每个决策树对其进行判别,通过类似投票的方式将票数最多的类设为该样本点的预测类别. 在非均衡数据集处理中随机欠采样[13]方法主要是随机删除多数类中的一部分样本,而对少数类样本不做任何操作,由于在随机删除样本的过程中存在随机性和偶然性,会导致多数类样本中的一些重要信息丢失,最终会影响在非均衡数据集中的综合分类性能. SMOTE算法[11]即合成少数类过采样技术.如图1所示, 对每个少数类样本X,得到其k近邻,k取5,如5个最近邻样本Y1,Y2,Y3,Y4,Y5,然后在X与这5个样本之间的连线上随机生成新的少数类样本Z1,Z2,Z3,Z4,Z5.它其实是对于随机过采样算法的一种改进算法,随机过采样增加少数类样本的方法只是通过简单复制样本,这样容易产生过拟合的问题,会使模型学习到的信息过于特别而不够泛化.SMOTE算法详细步骤如下: 1)少数类中每一个样本x,以公式(1)欧几里得距离D计算它到少数类样本集中所有样本的距离,得到其k近邻[14],通常k取5; (1) 2)对少数类样本集进行分组,以欧几里得距离最近的6个样本分为1组; 3)根据公式(2),在每组样本两两之间连线上随机生成少数类样本,加入样本集; 4)当少数类样本与多数类样本比例不成1:1,执行步骤3). Xnew=x+rand(0,1)*|x-t| (2) 随机欠采样,SMOTE算法较好地改善了随机森林处理非均衡数据集的问题,使得模型对样本的分类预测正确率有所提高.但是随机欠采样方法会失去许多样本的信息,而SMOTE过采样方法会使样本数据集的少数类过拟合. 在非均衡数据集的处理上,由于欠采样方法可能会失去许多样本的信息,而过采样可能会使少数类样本过拟合.而且传统的方法分类前,往往先将稀疏区域数据作为噪声数据直接删除.但是,由于在非均衡数据集中多数类样本与少数类样本数量差异较大,如果稀疏区域数据中的少数类样本数量过多,直接删除稀疏区域数据会使数据集更加非均衡.假设一个数据集T,多数类样本集为D,少数类样本集为S.针对以上问题,本文提出基于混合采样的非均衡数据集算法.首先采用基于变异系数[15]的样本检测方法识别非均衡数据集的稀疏域和密集域,基本思想如下: 1)在数据集T中计算出对象t到其k近邻距离之和的平均值,其中对象d为t的k近邻,Nkdist(t)为d的k近邻的个数.每个点的密度用平均值的倒数表示 (3) 2)该对象k近邻密度的标准差与它们的平均值的比值定义为t的变异系数,即 (4) 稀疏域:改进的SMOTE—USMOTE 该方法首先把稀疏域中少数类样本S分为安全样本、边界样本和噪声样本3类,找出少数类的边界样本后,不仅从少数类样本中求最近邻,生成新的少数类样本,而且在多数类样本中求其最近邻,生成新的少数类样本,最后再对加入人工合成少数类后的稀疏域数据集进行适当的欠采样处理[16],这会使得少数类样本更加接近其真实值. 1)在少数类样本S中,计算每个样本点pi与所有训练样本的欧氏距离,获得该样本点的m近邻,m=5. 2)在少数类样本S中,设在m近邻中有m′个属于多数类样本,显然0≤m′≤m.若m′=m,pi被认为是噪声样本;若m/2≤m′ 3)计算边界样本点pi′与少数类样本S的k近邻,k=5.选出α比例的样本点与pi′进行随机的线性插值,产生新的少数类,最后在多数类样本D中选出1-α比例的样本点与pi′进行线性插值,随机产生新的少数类,α=0.7. 4)对加入人工合成少数类后的稀疏域数据集进行欠采样处理,为了避免对多数类样本进行欠采样时去掉过多有用信息的数据,所以适当减少清理的程度.对于数据集的每一个样本pi,找到它的2个近邻,如果样本pi属于多数类,当分类后,它的2个近邻属于少数类时,则去掉样本pi;如果样本pi属于少数类,并且它的2个近邻属于多数类,则去掉pi的2个多数类近邻. 5)稀疏域中重构后的样本集形成新的样本集Train1. 密集域:改进的欠采样算法—IS 对多数类样本集D进行划分,首先采用k近邻方法将多数类样本集分为噪声样本、边界样本和安全样本,然后在边界样本集中选定一个样本点c,以c为圆心r为半径形成的圆内,n表示在圆内所包含的样本数量.如果在圆内的总样本大于等于n/2,则删除该样本点,否则保留样本点.具体流程如下: 1)采用k近邻方法将多数类样本集分为噪声样本、边界样本和安全样本.删除噪声样本,保留安全样本[11]; 2)在边界样本集中,选定样本点c,确定以样本点c为圆心,r为半径的圆形区域,调整控制r大小使圆形区域内的样本数量为10; 3)如果在圆内的总样本数大于或等于5,则删除该样本点,否则保留样本点.一直重复以上步骤直到达到设定的采样样本数; 4)密集域中重构后的样本集形成新的样本集Train2. 各样本定义如下:设稀疏域样本A大小LA、密集域样本B大小LB、稀疏域样本中的少数类样本a1大小La1、稀疏域样本中的多数类样本a2大小La2、密集域样本中的多数类样本b1大小Lb1、密集域样本中的少数类样本b2大小Lb2. USI算法的流程见图2.该算法首先采用基于变异系数的稀疏点检测方法识别非均衡数据集的稀疏域和密集域,设置变异系数阈值,如果样本的变异系数大于该阈值,则划分为稀疏域样本集,否则为密集域样本集;然后,对稀疏域中的少数类,采用USMOTE算法进行过采样,过采样倍率为N;对于稀疏域中的多数类不做处理直接加入训练集中;最后,对于密集域中的多数类样本,采用IS算法进行欠采样,欠采样倍率为M. N=La2/La1 (5) M=Lb1/Lb2 (6) 本文提出的基于混合采样的USI算法的具体步骤如下: Step 1.遍历S(fori:S)计算出每个样本Xi的变异系数. a)以欧氏距离计算出样本Xi到每个样本的距离并加入G集合中,对G集合进行排序; b)找出Xi的k近邻,计算样本Xi分别到k个样本的距离之和Gnum; c)求得每个样本的密度Td(Xi)=Gnum/k; d)求出每个样本的变异系数V(Xi). Step 2.如果V(Xi)>Vp,Xi划分到稀疏域A,否则划分到密集域B. Step 3.遍历LA,如果Xi是少数类样本,则加入集合a1;否则加入集合a2. Step 4.对A中的a1样本,采用改进SMOTE的USMOTE算法以N倍采样率生成新样本,得到样本集Ca1,此样本集与a1,a2形成新样本集Train1. 图2 算法流程图Fig.2 Algorithm flow chart Step 5.在B集合中采用IS算法对多数类样本以欠采样倍率M形成新样本集Train2. Step 6.Train1和Train2形成训练集Train-data进行训练. Step 7.对新样本集Train-data采用随机森林进行分类. 本文提出的基于混合采样的随机森林算法(USI)相比其他算法,首先通过引进“变异系数”识别非均衡数据集的稀疏域和密集域,然后分别对稀疏域和密集域进行改进的过采样和欠采样方法,本文提出的USI算法克服了其他欠采样方法如RU、IS算法可能会失去许多样本的信息,而过采样方法如SMOTE、USMOTE算法以及混合采样RU-SMOTE算法可能会使少数类样本过拟合等问题. 在非均衡数据分类研究评价[17,18]中以TP表示少数类样本被正确分类的样本个数,FN表示少数类样本被错误分类的样本个数,FP表示多数类样本被错误分类的样本个数,TN表示多数类样本被正确分类的样本个数.设1为少数类,0为多数类. 真正率(查全率):即实际类别为1的样本中,被模型正确分类的样本所占比例: TPR=TP/(TP+FN) (7) 真负率:即实际类别为0的样本中,被模型正确分类的样本所占比例: TNR=TN/(FP+TN) (8) 假正率:即实际类别为0的样本中,被模型错误分类的样本所占比例: FPR=FP/(TN+FP) (9) 假负率:即实际类别为1的样本中,被模型错误分类的样本所占比例: FPR=FN/(TP+FN) (10) 精度(查准率):即所有预测为1的样本中,正确预测的样本所占比例: rPr=TP/(FP+TP) (11) 4.1.1 F-value准则 在非均衡数据评价标准中,F-value是一个综合性的评价标准[20],如公式(12)所示: (12) 其中TPR表示查全率,其公式如(7)所示,rPr表示查准率,其公式如(11)所示.β是一个系数,通常取值为1.根据F-value表达式可以看出,F-value可以正确的衡量分类器的每一项的性能,如果一个分类器分类后得到的召回率和精确率值都比较高,那么F-value的值也会比较高,表明该分类器性能较好,对少数类的识别精度越高. 4.1.2 G-mean准则 G-mean评价标准中包含两个子度量标准[21].第一个是TPR,它主要是用来衡量分类器对少数类样本的灵敏度,其公式如(7)所示.第二个则是TNR,它主要是用来衡量多数类的识别性能,其对应公式如(8)所示.将这两个衡量标准结合得到G-mean评价指标,如公式(13): (13) 其中TPR是分类器对少数类的分类精度,TNR是分类器对多数类的分类精度.根据G-mean的表达式可以看出,在不考虑TNR的值大小的前提下,不管TPR的数值大还是数值小都不能保证G-mean的值大.同样,在不考虑TPR的值大小的前提下,不管TNR的数值大还是数值小都不能保证G-mean的值大,只有少数类预测准确率和多数类预测准确率都高的时候,G-mean值才会增加.因此可以说G-mean值能更加全面的评价分类器的性能. UCI数据库是加州大学欧文分校(University of CaliforniaIrvine)提出的用于机器学习的数据库,UCI数据集是一个常用的标准测试数据集,为了评价本算法的性能,因此采用了 表1 数据表 数据集维数少数类/多数类非均衡率credit17439/45618.78%pima819419/5688534.1%page1096/56314.5%iris429/1853.5%ecoli877/25929.7%german2510926/7652314.2% UCI机器学习数据库中的6组有代表性的非均衡数据集,如表1是数据特征信息,数据是结构化数据,需要对其做特征缩放,将特征缩放至同一个规格.数据预处理将训练集和测试集归一化到[0,1]区间.如果样本集中包含几个类别,则选择其中一类样本或者将数量较少的几类样本合并后作为少数类,其余作为多数类.采用python语言进行实验,这6组非均衡数据集分别是credit数据集,pima数据集,page数据集,iris数据集,ecoli数据集,german数据集.每次实验将样本集随机划分,80%为训练集20%为测试集. 4.3 实验分析与结果(不同算法在非均衡数据集上的比较) 表2为6种算法在6种数据集上的G-mean值比较,可以看出,本文提出的USI算法与基于样本特性欠采样(RU)的随机森林算法、基于IS欠采样的随机森林算法(IS)、基于SMOTE过采样的随机森林算法(SMOTE)、基于USMOTE过采样的随机森林算法(USMOTE)以及基于随机欠采样与SMOTE相结合的随机森林算法(RU-SMOTE)进行比较,其G-mean值比其他算法都有较大幅度的提升.当决策树个数设置为9时,credit数据集中RU算法的G-mean值是0.8991,IS算法的G-mean值是0.9031,SMOTE算法的G-mean值是0.9193,USMOTE算法的G-mean值是0.9263,RU-SMOTE算法的G-mean值达到0.9325,USI算法的G-mean值达到0.9693.说明credit数据集中稀疏域样本点对分类性能影响较大,导致其他算法表现较差,而USI算法通过引进变异系数,采用改进的混合采样方法克服了以上问题. 表2 不同算法上的G-mean值对比 数据集G-meanRU ISSMOTE USMOTERU-SMOTEUSIcreditpimapageiris ecoli german0.89910.90570.77820.62810.62530.8482 0.90310.91350.78010.64310.67210.85050.9193 0.92930.78850.67590.68740.86440.92630.93830.81560.67930.76450.87730.93250.94020.81730.71320.79370.88130.96930.96360.85220.79340.89220.9076 图3给出6种算法在选取的4组数据集(credit、page、pima、german数据集)上不同决策树个数对应的G-mean值,各算法的G-mean值均随着决策树个数增加而增加,刚开始增加较快,并最终趋于平稳.本文提出改进的USI算法的G-mean值均比其他算法有一定幅度提高.说明USI算法对少数类样本和多数类样本的预测准确率都有所提高. 表3 不同算法上的F-value值对比 数据集G-meanRU ISSMOTE USMOTERU-SMOTEUSIcreditpimapageiris ecoli german0.87810.86230.77400.74710.62530.9105 0.88450.87330.77920.75610.74130.91660.9023 0.87660.78140.77650.78960.93320.91420.89350.78920.78660.78760.93620.92650.90520.80120.79320.79540.93910.9458 0.94060.84130.91450.78340.9552 表3为6种算法在6种数据集上的F-value值比较,可以看出,除了ecoli数据集,其他数据集上USI算法的F-value值均得到提高.当决策树个数设置为9时,iris数据集中RU算法的F-value值是0.7471,IS算法的F-value值是0.7561,SMOTE算法的F-value值是0.7765,USMOTE算法的F-value值是0.7866,RU-SMOTE算法的F-value值达到0.7932,USI算法的F-value值达到0.9145.其中,USI算法性能大幅度提升.说明iris数据集中,其他算法可能会使样本数据集的少数类过拟合,导致查全率和查准率较低.USI算法通过引进变异系数采用改进的混合采样方法克服了以上问题,提高了分类准确率. 图3 不同数据集上的G-mean值比较Fig.3 Comparison of G-mean values on different data sets 图4 不同数据集上的F-value值比较Fig.4 Comparison of F-value values on different data sets 图4给出6种算法在选取的4组数据集(credit、page、pima、german数据集)上不同决策树个数对应的F-value值,可以看出各算法的F-value值均随着决策树个数增加而增加.本文提出改进的USI算法的F-value值均比其他算法有一定幅度提高.说明USI算法的综合分类准确率有所提高. 在非均衡数据集分类算法的研究中,由于欠采样方法可能会失去许多样本的信息,而过采样方法可能会使少数类样本过拟合.本文提出了一种基于混合采样的算法(USI)来平衡数据集.该算法通过引进变异系数界定稀疏域和密集域,对于稀疏域中的少数类样本,采用改进SMOTE算法的过采样方法(USMOTE)合成新的少数类样本,对于密集域中的多数类样本,采用改进的欠采样方法(IS)形成新的多数类样本,最后将平衡后的数据集送入由多个决策树组成的分类器随机森林中进行训练,并与其他分类算法进行比较,实验结果表明,本文提出的算法(USI)进一步提高了在非均衡数据集上的G-mean值,F-value值,分类准确率均优于其他算法.2.2 随机欠采样
2.3 SMOTE算法
3 分类算法改进
3.1 稀疏域和密集域检测
3.2 稀疏域样本处理
3.3 密集域样本处理
3.4 基于混合采样的随机森林算法流程

4 实验分析
4.1 非均衡数据分类研究评价准则
4.2 数据集描述
Table 1 Sample data table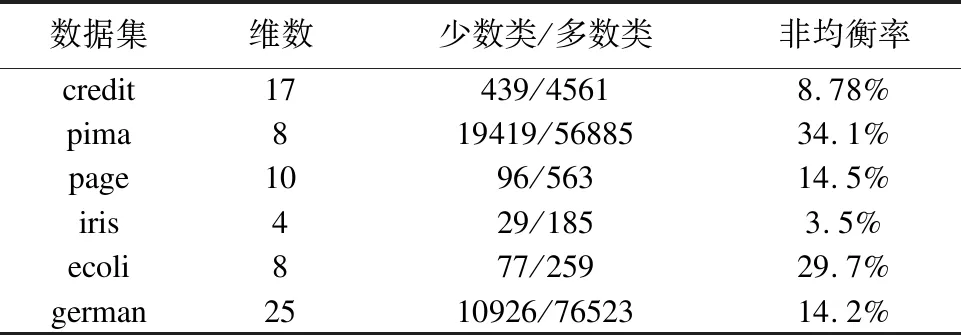
Table 2 Comparison of G-mean values on different algorithms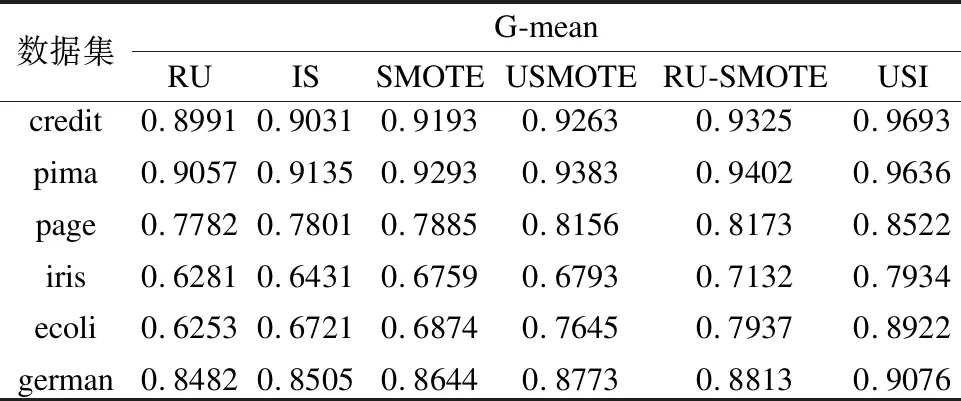
Table 3 Comparison of F-value values on different algorithms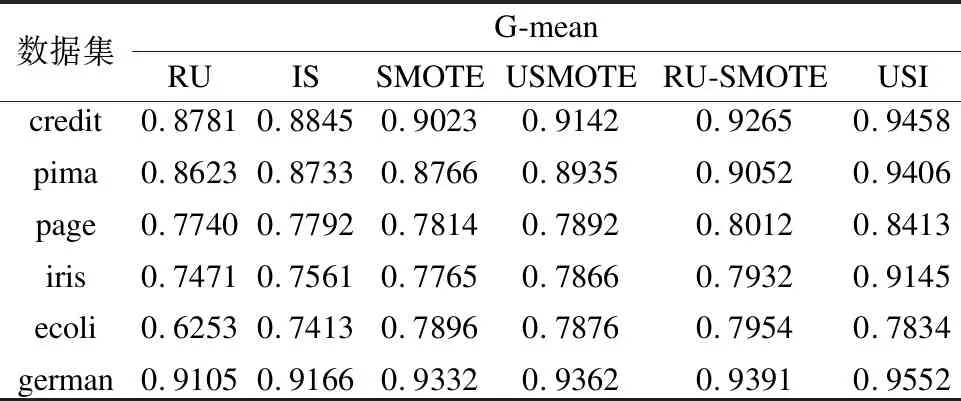

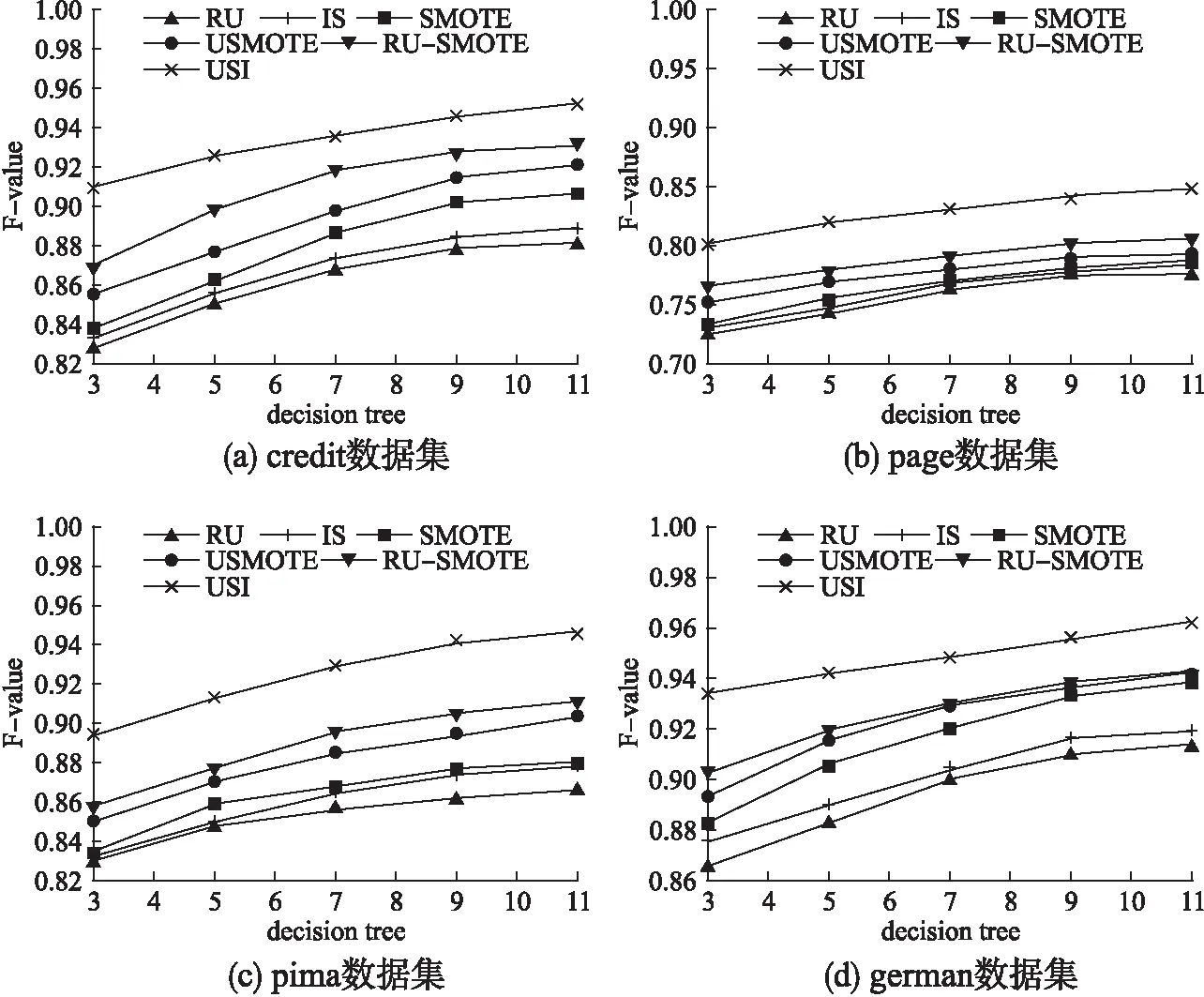
5 结 语
猜你喜欢
电子产品世界(2022年4期)2022-04-21今日农业(2021年9期)2021-11-26英语文摘(2021年2期)2021-07-22计算机系统应用(2021年2期)2021-02-23数码世界(2020年4期)2020-06-18计算机应用与软件(2020年1期)2020-01-14科学与信息化(2019年28期)2019-10-21计算机测量与控制(2019年4期)2019-05-08科学与财富(2016年32期)2017-03-04BOSS臻品(2015年1期)2015-09-10
