
基于迁移学习和BiLSTM-CRF的中文命名实体识别
2019-06-06 05:46于碧辉
小型微型计算机系统 2019年6期
武 惠,吕 立,于碧辉
1(中国科学院大学,北京 100049)2(中国科学院 沈阳计算技术研究所,沈阳 110168)
1 引 言
命名实体识别[1]是自然语言处理领域所研究的基础性核心课题之一,主要任务是从非结构化文本中提取能体现现实世界中已存在的具体实体或者抽象实体的单词或者词组,例如人名,地名和组织机构名等.
近几年,随着深度学习的深入研究,深度学习在自然语言处理的诸多应用中都取得了一些进展,例如问答系统、机器翻译等.深度学习是一种从原始数据中自动学习特征的方法,具有较强的泛化能力,在很大程度上减弱了对繁琐的人工特征和专家知识的依赖.于是,采用深度学习方法进行命名实体识别任务受到学者们的广泛关注,其中,Zhiheng Huang等人[2]构建了多种神经网络模型来解决自然语言处理领域中的序列标注问题,实验证明BiLSTM-CRF模型在序列标注上有很好的性能,在CoNLL2003数据集上进行命名实体识别时,F1值达到了90.10%.Jason P.C.Chiu和Eric Nichols[3]利用BiLSTM和CNN检测字和字符级特征,完成了命名实体识别任务,在CoNLL2003数据集上F1值达到了91.62%,在OntoNotes 5.0的数据集上F1值比最好的F1值提高了2.3%.Xuezhe Ma和Edurd Hovy[4]将BI-LSTM、CNN与CRF相结合通过构建BI-LSTM-CNNs-CRF模型来实现命名实体识别任务,在CoNLL2003的数据集上,F1值达到了91.21%.
命名实体识别是一种典型的序列标注问题,采用深度学习方法进行命名实体识别时,一般需要大规模的标注数据.但由于人工标注的代价高昂,在一些领域并没有大规模的标注数据,所以,基于小规模标注语料进行命名实体识别成为现阶段研究的重点问题之一.
针对中文命名实体识别任务,本文提出了一种融合迁移学习的神经网络模型——TrBiLSTM-CRF模型.该模型首先利用基于实例的迁移学习算法对辅助数据集进行知识迁移,协助解决目标领域的学习问题,然后利用1998年1月份《人民日报》熟语料对基于上下文词语的词向量进行训练,得到词向量表,最后将输入语句所对应的词向量序列输入双向LSTM-CRF模型进行关于中文机构名的命名实体识别任务.实验结果表明,本文所提出的TrBiLSTM-CRF模型在中文机构名命名实体识别任务中取得了较好的实验性能.
2 相关工作
迁移学习[5]是一种新的机器学习方法,通过运用已有的知识对不同但相关领域问题进行求解,主要研究如何把源域的知识迁移到目标域上,其中,已有的知识记为源域(source domain),要学习的新知识记为目标域(target domain).自从被提出之后,迁移学习在计算机视觉[6],自然语言处理[7],文本分类[8]等领域有着广泛的应用.
2010年,Pan S J和Yang Q[9]按学习方法对迁移学习进行分类,将其分成基于实例的迁移学习方法(Instance based Transfer Learning)、基于特征的迁移学习方法(Feature based Transfer Learning)、基于模型的迁移学习方法(Model based Transfer Learning)和基于关系的迁移学习方法(Relation based Transfer Learning)四大类.
基于实例的迁移学习方法[10]是根据一定的权值生成规则,对源域样本进行重用,来进行迁移学习.该方法的主要研究内容是权值生成和样本选择.这里的权值是指源域样本和目标域样本的相似度,若源域样本与目标域样本越相似,则源域样本的权值越大.王红斌等人[11]提出了一种基于实例的迁移学习算法——TLNER_AdaBoost,实验证明TLNER_AdaBoost算法不仅提高了中文命名实体识别任务的实验性能,而且大大减少了人工对语料的标注工作.Yang Z等人[12]构建了跨域、跨应用和跨语言三种融合迁移学习于深度层级循环神经网络模型,通过实验验证在深度层级神经网络的基础上使用迁移学习算法可以显著提高序列标注的性能.
本文提出了一种新异的TrBiLSTM-CRF模型进行中文命名实体识别.该模型将迁移学习和深度学习算法相结合,在小规模标注语料的情况下,迁移学习有效缓解了深度学习对少量数据学习能力不足的问题,深度学习则利用多层非线性神经网络自动学习特征,减少了对人工特征和专家知识的依赖.
3 TrBiLSTM-CRF模型
TrBiLSTM-CRF模型共包含四部分:基于实例的迁移学习的数据集构建模块,词向量构建模块,BiLSTM模块和CRF模块,其整体框架如图1所示.
首先,采用基于实例的迁移学习算法,通过权值生成和样本选择,将源域样本迁移到目标域,构成新的训练数据集;然后通过词向量模型进行训练,得到词向量表;同时,通过查表将训练数据集中每个句子所对应的词向量序列输入BiLSTM模块进行特征提取;最后通过CRF模块将BiLSTM输出的特征向量解码为一个最优的标记序列.
3.1 基于实例的迁移学习算法
假设目标域为Dt,源域为不同但相关领域的数据集Ds,通过计算源域样本和目标域样本的相似度,调整源域样本的权值,实现源域样本的更新,生成新的数据集Ds′,将新的数据集Ds′迁移到目标域中,构成新的训练数据集Dl=Dt∪Ds′,最终的目的是使训练数据集在规模和质量上满足模型训练的需求.这里的样本是指命名实体,样本相似度是指两个命名实体在组成结构上的相似度,主要用来评估源域样本对目标域样本的贡献程度.
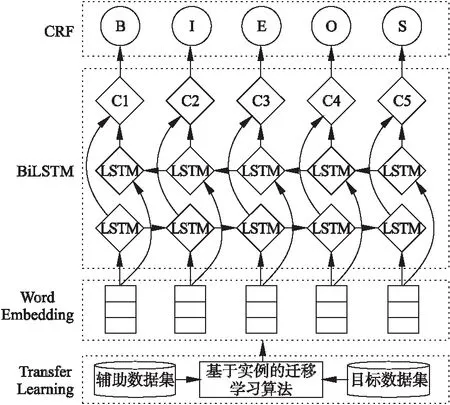
图1 TrBiLSTM-CRF模型Fig.1 A TrBiLSTM-CRF model
3.1.1 样本相似度
基于命名实体由多个词构成的特点,本文使用了三种计算样本相似度的方法进行实验:编辑距离、实体相似性、词性相似性.这三种样本相似度的计算方法都是以词为单位进行计算的.其中,编辑距离和词性相似性是从语法层面上计算样本相似度,词性相似性通过考虑词性标注对实体构成的应用,判断指出实体中每个词所扮演的语法角色.实体相似性是从语义层面上计算样本相似度,较好地反映了实体之间的语义信息.下面分别给出了这三种样本相似度的具体计算方法(本文所提到的实体均指命名实体).
假设实体A=(a1,a2,…,an)和B=(b1,b2,…,bm)分别由n和m个不同的词构成.
定义1.编辑距离是指对于两个实体,由一个实体转化成另一个实体所需要的最少操作次数.具体操作方式有:插入一个词、删除一个词、替换一个词.显然,edit(A,B)越小,实体A,B越相似.即:
edit(A,B)=minED(n,m)
(1)
ED(n,m)的计算公式为:
ED(n,m)=
(2)
其中,i=1,2,…,n,j=1,2,…,m.
定义2.实体相似性是指在序列相同的前提下,两个不同实体中最大相同的词的数量与最大实体数量的比值.其计算公式为:
(3)
其中,x表示在序列相同的前提下,实体A和实体B最大相同的词的数量.
定义3.词性相似性是指在序列相同的前提下,两个不同实体中最大相同词性的数量与最大实体数量的比值.其计算公式为:
(4)
其中,y表示在序列相同的前提下,实体A和实体B最大相同词性的数量.
3.1.2 权值计算
依据三种样本相似度的计算方法,计算源域Ds中每个样本与目标域Dt中样本的相似度.其中源域Ds中某个样本p与目标域Dt中样本的相似度分别为:
ed(p)=min{edit(p,t1),…,edit(p,tk)}
(5)
se(p)=max{Sentity(p,t1),…,Sentity(p,tk)}
(6)
sp(p)=max{Spos(p,t1),…,Spos(p,tk)}
(7)
其中,t1,…,tk为目标域Dt中相同类型的样本,k(k≥1)表示目标域Dt中与源域Ds样本p为同一类型的样本个数.

采用数据引力[13]得到源域Ds中所有样本关于编辑距离、实体相似性、词性相似性三种样本相似度所对应的权值.假设源域Ds和目标域Dt的质量分别为ms和mt(ms和mt可以近似表示为数据集中同一类型样本的数量),则关于源域Ds中样本p编辑距离、实体相似性、词性相似性所对应的权值为:
(8)
(9)
(10)
考虑以上三种样本相似性,源域Ds中每个样本所对应的最终权值为:
Wp=αWp_dist+βWp_entity+γWp_pos
(11)
其中,α、β、γ分别为常数,并且α+β+γ=1,Wp为归一化因子.考虑实体的构成与影响因素,借助模糊理论[14]确定α、β、γ的值.α、β、γ权值反映了不同因素相对于结果重要性程度的差异,权值系数的确定实际上就是确定对于结果的重要度.
通过采用模糊数学的理论和技术对受多种因素影响的对象进行综合评价.首先通过实验确定影响因素Wp_dist、Wp_entity、Wp_pos对命名实体识别的影响程度,然后基于结果分析,确定各个影响因素之间的相关度,构成模糊评判矩阵.最后,通过求解该句子的特征值,确定各个影响因素的权值.
根据权值大小,对源域样本进行重用.若源域Ds中某个样本对应的权值Wp>φ(其中φ为常数),则该样本可以作为目标域样本进行训练,通过保留原始数据,将其迁移到目标域中;否则,将该样本丢弃,无法对其进行迁移学习.
3.2 词向量
为了减少对人工特征和专家知识的依赖,本文采用了基于上下文词语的词向量方法[15]对词向量进行预训练.
主要内容是利用Word2vec在大规模的无标注中文语料上进行训练,得到词向量表.其中,Word2vec是以神经网络形式表示的语言模型[16],包含Skip-gram和CBOW两种语言模型.Skip-gram模型是由当前词语预测它周围的上下文词语,而CBOW是由一个词语的上下文词语作为输入,来预测当前这个词语.本文采用CBOW模型在1998年1月份《人民日报》语料上训练基于上下文词语的词向量.
3.3 BiLSTM模块
长短期记忆网络(Long Short Term Memory network,LSTM)是2014年由Hochreiter和Schmidhuber[17]提出的一种特殊的循环神经网络(recurrent neural network,RNN),该模型能够学习到长期依赖关系,解决了传统RNN由于序列过长等问题而产生的梯度消失和梯度爆炸问题.
3.3.1 LSTM单元
LSTM单元由一个记忆单元和更新门(update gate)、输出门(output gate)、遗忘门(forget gate)三个门构成,其中,记忆单元的作用是对信息进行管理和保存,三个门的作用是控制记忆单元中信息的更新、衰减、输入、输出等动作.它的主要思想是通过学习LSTM单元中三个门的参数来管理记忆单元中的信息,从而使有用的信息经过较长的序列也能保存在记忆单元中.其单元结构如图2所示.
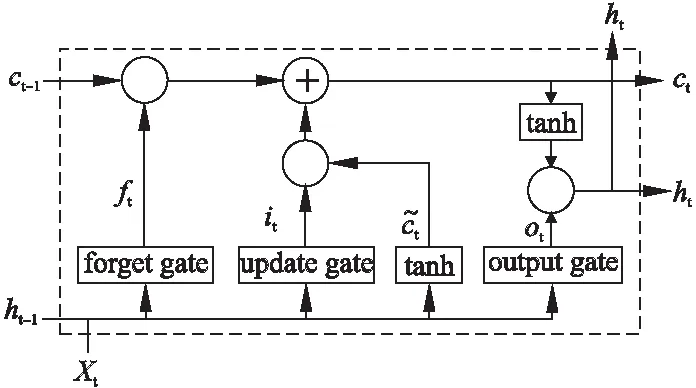
图2 LSTM单元Fig.2 A LSTM unit
LSTM单元在t时刻的输入由输入层xt、序列中前一个单元的隐含层ht-1和记忆单元ct-1三部分构成,在t时刻的输出为该单元的隐含层ht和记忆单元ct.首先通过计算三个门的信息输出,来控制记忆单元的信息,然后计算记忆单元内的信息,最后使用记忆单元值和输出门计算该时刻隐含层的值.具体计算方式如公式(12)所示.
it=σ(Wu[ht-1,xt]+bu)
ft=σ(Wf[ht-1,xt]+bf)
ot=σ(Wo[ht-1,xt]+bo)
ht=ot*tanh(ct)
(12)
其中σ表示sigmoid激活函数,tanh表示双曲正切激活函数,所有的W和b均为参数.
3.3.2 BiLSTM
对于命名实体识别来说,由于待识别的实体在句子的分布不同,其上下文信息的重要程度也不同.为了更好地利用上下文信息,我们采用双向LSTM(Bidirectional LSTM,BiLSTM)结构进行模型训练,其结构图如图3所示.
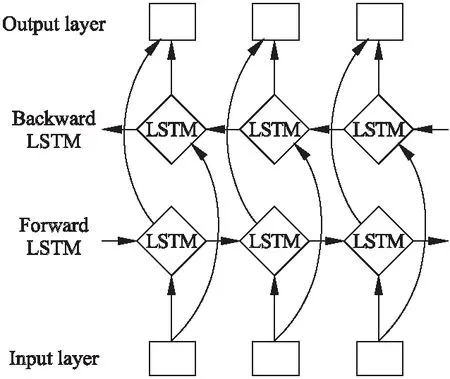
图3 BiLSTM结构Fig.3 Bidirectional LSTM network
BiLSTM是对LSTM的优化改进,在自然语言处理领域的序列标注任务上有着出色的表现[2-4].从图3中可以看出,BiLSTM分别用正向和反向的LSTM单位来计算过去和将来所含的隐藏信息,共同构成最终的输出.
3.4 CRF模块
条件随机场(conditional random field,CRF)是一种概率无向图模型[4],该模型是计算某个序列中的最优联合概率,其优化的是整个序列,而不是将每个时刻的最优解拼接起来,在这一点上CRF要优于LSTM.故本文采用CRF对BiLSTM的输出进行解码,得到全局最优的标注序列.
若z={z1,z2,…,zn}表示一个句子的输入序列,zi为该句子中第i个词的词向量,y={y1,y2,…,yn}表示句子z的标签序列,Y(z)表示句子z的可能标签序列的集合.其CRF概率模型的具体形式为:
(13)
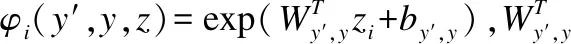
在训练过程中,采用极大似然估计原理对其进行优化,其对数似然函数为如下形式:
L(W,b)=∑ilogp(y|z;W,b)
(14)
由极大似然估计原理,最大化对数似然函数就是最大化CRF条件概率模型,即优化目标函数:
(15)
4 实 验
4.1 实验语料
本文使用1998年1月份《人民日报》数据集进行中文机构名命名实体识别,该数据集是由北京大学计算语言学研究所和富士通研究开发中心有限公司共同制作的标注语料库.实验过程中,随机将其分为目标数据集、辅助数据集、测试数据集三部分,其中测试数据集占总数据集的10%,Dt是含有机构名命名实体标签和其他词性标签的目标数据集,Ds是把所有实体标签改为NN类型的辅助数据集.数据集分布情况如表1所示.
表1 数据集
Table 1 DataSet

名称数量标注信息目标数据集11223句含有机构名命名实体标签和其他词性标签辅助数据集22475句所有实体标签改为NN类型测试数据集3718句含有机构名命名实体标签和其他词性标签
TrBiLSTM-CRF模型的训练集由目标数据集和基于迁移学习更新之后的辅助数据集所组成的大规模数据集;其他对比实验,比如:CRF、BiLSTM、BiLSTM-CRF,所使用的训练集为目标数据集.以上四种算法所使用的测试集数据来源于测试数据集.
4.2 实验设置
基于上下文词语的词向量方法是利用CBOW模型对1998年1月份《人民日报》数据集中的每个词进行训练,得到相应的词向量表.CBOW模型的参数设置为:隐藏层的神经元数量为100,即词向量的维度为100;上下文的窗口大小为3;采用分层softmax的方法提高训练效率.
BiLSTM的参数设置为:词向量维度为100,BiLSTM隐藏层为1层,前向和反向LSTM的神经元数量为128,学习率为0.001,批尺寸batch_size为128,迭代次数epoch为40.
本文使用BIESO对词进行实体标签标记,采用准确率P、召回率R和F值作为命名实体识别实验的性能评价指标,具体公式如下:

(16)

(17)
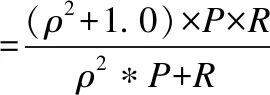
(18)
其中,ρ的值设置为1,表示准确率和召回率同等重要.最终采用以上三种性能评价指标的加权平均值作为实验的性能评测指标.
4.3 实验结果与分析
为了验证TrBiLSTM-CRF模型进行中文命名实体识别任务的实验性能,本文主要进行以下两组实验,分别为:
1)迁移学习的性能试验;
2)不同命名实体识别方法的对比实验.
4.3.1 迁移学习的性能试验
1)权值参数讨论
本文分别从编辑距离、实体相似性、词性相似性所确定的权值来确定三种权值对样本相似度的影响,然后基于模糊理论来计算源域数据集的权值,实现基于实例的迁移学习算法.
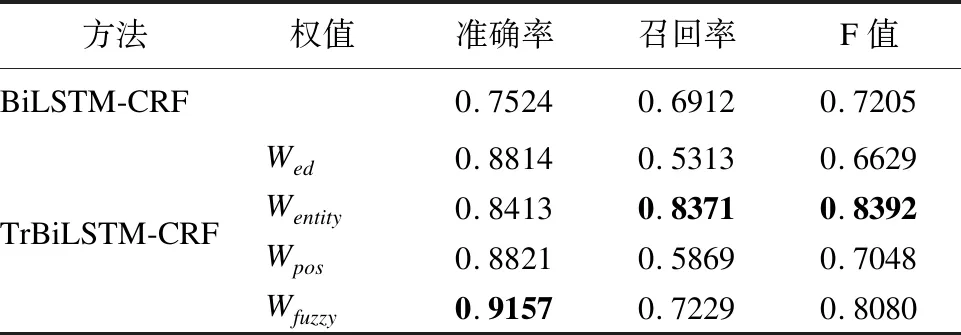
由表2可以得到以下结论:
在语法层面上,分别将编辑距离所计算的权值Wed和词性相似性所计算的权值Wpos应用在TrBiLSTM-CRF模型进行中文机构名命名实体识别时,其准确率分别为88.14%和88.21%,比同条件下BiLSTM-CRF模型的准确率分别高出了12.90%和12.97%,但召回率明显低于BiLSTM-CRF模型的召回率.故由编辑距离和词性相似性所确定的权值主要用于提高模型的准确率.
表2 不同权值的实验结果
Table 2 Experimental results with different weights
方法权值准确率召回率F值BiLSTM-CRF0.75240.69120.7205TrBiLSTM-CRFWed0.88140.53130.6629Wentity0.84130.83710.8392Wpos0.88210.58690.7048Wfuzzy0.91570.72290.8080
在语义层面上,根据实体相似性所确定的权值Wentity进行TrBiLSTM-CRF模型训练时,得到的实验结果比BiLSTM-CRF模型的实验结果在准确率P、召回率R和F值上分别提升了8.89%、14.59%、11.87%,有效提高了召回率.
本文根据编辑距离、实体相似性、词性相似性对命名实体识别的影响,采用模糊理论,由权值Wed、Wentity和Wpos确定新的权值Wfuzzy,使得TrBiLSTM-CRF模型的准确率、召回率和F值分别为91.57%、72.29%、80.80%,显著高于BiLSTM-CRF模型的实验结果,因此,由语法和语义特征共同确定的权值Wfuzzy应用到TrBiLSTM-CRF模型的实验性能最好,在准确率、召回率和F值上都有显著提高.
2)目标数据集所占比重讨论
在目标数据集大小不同的情况下,分别对TrBiLSTM-CRF和BiLSTM-CRF进行了实验,实验结果如图4所示.

图4 不同目标数据集的实验结果Fig.4 Experimental results for different target datasets
在训练集不变的情况下,随着目标数据集所占比重的增大,BiLSTM-CRF模型的F值逐渐上升,但F值的增长越来越缓慢.而在TrBiLSTM-CRF模型中,当目标数据集所占比重增大时,辅助数据集所占比重减小,F值先增大后减小.
在辅助数据集大于目标数据集的情况下,TrBiLSTM-CRF模型的性能都显著优于BiLSTM-CRF模型的性能.其中,当辅助数据集与目标数据集的比例约为3∶1时,TrBiLSTM-CRF模型的F值最大,性能最好.
4.3.2 中文命名实体识别方法的对比实验
为了更有效的验证TrBiLSTM-CRF算法的性能,本文分别采用以下五种方法进行实验设置.
1)条件随机场CRF
2)TLNER_AdaBoost[11]
TLNER_AdaBoost是文献[11]提出的一种基于实例的扩展迁移算法,通过该算法扩充训练数据集,构建一个性能更好地分类器模型,在命名实体识别中得到了较好的应用.
3)BiLSTM
采用双向LSTM在数据集上进行中文机构名命名实体识别实验.
4)BiLSTM-CRF
采用BiLSTM-CRF在数据集上进行中文机构名命名实体识别实验.
5)TrBiLSTM-CRF
采用TrBiLSTM-CRF在数据集上进行中文机构名命名实体识别实验.
上述方法的数据集和参数均在4.1和4.2节进行了介绍,CRF、TLNER_AdaBoost、BiLSTM、BiLSTM-CRF和TrBiLSTM-CRF五种方法的实验结果如表3所示.
表3 不同方法的实验结果
Table 3 Experimental results of different methods

方法准确率P召回率RF值CRF0.88960.67230.7658TLNER_AdaBoost[11]0.88120.53560.6662BiLSTM0.74030.66530.7008BiLSTM-CRF0.75240.69120.7205TrBiLSTM-CRF0.91570.72290.8080
由表3可知:
与CRF方法相比,TrBiLSTM-CRF算法在准确率、召回率和F值均高于CRF的结果,其准确率、召回率和F值分别达到91.57%、72.29%、80.80%,并且有效地解决了对复杂的人工特征和领域知识的需求问题.
与现有的TLNER_AdaBoost[11]方法相比,本文所提出的的TrBiLSTM-CRF模型优于TLNER_AdaBoost模型的实验结果,在准确率、召回率、F值分别提升了3.45%、18.73%、14.18%.表明迁移学习与深度学习的结合比单独使用TLNER_AdaBoost迁移学习模型进行命名实体识别的性能更好.
与BiLSTM、BiLSTM-CRF方法相比,TrBiLSTM-CRF算法的准确率远远高于BiLSTM和BiLSTM-CRF方法的准确率,主要原因是使用了迁移学习算法,将辅助数据集和目标数据集通过实例迁移学习组成新的训练数据集,解决了标注数据集少的问题.
综上所述,本文所提出的TrBiLSTM-CRF模型,由于采用了基于实例的迁移学习算法,更好地学习到更多对目标数据集有贡献的知识,从而提升了模型在命名实体识别任务中的性能.
5 结束语
本文以中文机构名为研究对象,提出了基于迁移学习和深度学习的TrBiLSTM-CRF模型,对命名实体识别进行了研究.通过基于实例的迁移学习算法对知识进行迁移,一定程度上扩充了具有正迁移特性的训练样本,同时,降低了具有负迁移特性或零迁移特性的样本对训练模型的影响,从而缓解了对少量标注数据学习能力不足的问题.另一方面,采用深度学习算法从原始数据中自动学习特征,有效地解决了对复杂的人工特征和领域知识的需求问题.通过实验证明,本文所提出的TrBiLSTM-CRF模型在中文机构名命名实体识别任务中获得了较好的实验性能,具有一定的有效性.
在未来的研究工作中,将在命名实体识别领域围绕基于迁移学习和深度学习的相关算法进行进一步研究.例如,在采用词向量特征的基础上,考虑融入字、词性等特征进一步研究完善深度学习模型.另外,将尝试把本文所提的TrBiLSTM-CRF模型应用于专业领域或者垂直领域.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
邮电设计技术(2021年2期)2021-03-13
计算机技术与发展(2020年11期)2020-12-04
河北画报(2020年8期)2020-10-27
计算机与数字工程(2019年11期)2019-11-29
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
青年文学家(2015年29期)2016-05-09
科技视界(2016年1期)2016-03-30
俄罗斯问题研究(2013年1期)2013-03-11
