
双通道卷积神经网络人脸表情识别
2019-06-04 03:25:56张琳琳陈志雨
长春工业大学学报 2019年2期
张琳琳, 陈志雨, 张 啸
(长春工业大学 计算机科学与工程学院, 吉林 长春 130012)
0 引 言
面部表情在人与人之间的交流和互动中起着重要作用。最近,心理学研究报告指出,面部表情是人类表达情感的最具有判别力的方式。在整个发言者的信息中,面部表情所传达的信息占55%,言语部分包含的信息占7%,声音传达的信息占38%[1],近年来人脸表情识别已经被应用到越来越多的领域,比如人机交互[2]、安全检测[3]、操作员疲劳检测[4]、情绪音乐[5]、临床医学[6]等。由于其广泛的应用,面部表情识别吸引了大量学者研究[7-10]。
人脸表情识别系统流程主要包括图像预处理、图像检测、特征提取、特征分类四部分。在整个流程中,对面部图像进行特征提取起着至关重要的作用,是决定算法成功的关键步骤。人脸表情特征提取技术主要基于外观特征或几何特征[11]。使用由表情引起的脸部纹理(例如皱纹等)提取外观特征,几何特征是从脸部及其组成部分(例如眉毛、嘴巴、鼻子等)中提取出来的。1970年,Paul Ekman和Wallace V. Friesen开发了面部动作编码系统(Facial Action Coding System, FACS)[12],该方法被广泛应用于描述和测量面部行为。梯度直方图(Histograms of Oriented Gradients, HOG)、尺度不变特征变换(Scale Invariant Feature Transform, SIFT)、局部二值模式是用于提取面部特征的最新技术。上述技术均使用手工特征进行面部表情识别,这使得特征对包含姿势、照明和遮挡变化的面部图像具有很小的容忍度。卷积神经网络不同于传统的机器学习和计算机视觉方法,而是从用于训练的数据集中通过使用梯度下降等迭代算法自动学习并提取特征,通常与前馈神经网络相结合完成端到端的训练。
近年来,使用卷积神经网络(Convolutional Neural Network, CNN)进行图像数据特征提取的深度学习变得越来越流行。随着并行计算技术的广泛应用,CNN在许多计算机视觉任务中表现出色。从低级图像处理(如超分辨率)[13]到高级图像理解(如图像分类[14]、物体检测[15]和场景标注[16]),CNN的成功主要归功于其对复杂自然图像不同表现水平的能力。但是现有的网络结构对全连接层关注较少,全连接层在不同尺度下的特征提取能力不同。文献[17]针对CNN全连接层在不同尺度下的特征提取能力问题,提出一种三通道全连接层的CNN,该方法在纹身图像检测中取得了比较好的效果。为了提高网络性能,增强网络特征表达能力,文中提出了一种基于双通道卷积神经网络模型,在全连接层对传统的单通道全连接层进行改进,构建了一个有双通道全连接层的卷积神经网络。文献[18]指出,在适当选择的度量空间下,期望理想的面部特征具有比最小类间距离更小的最大类内距离。但是,现有算法很少能够有效地实现这一标准。因此,文中在训练过程中使用A-Softmax损失,使用角度作为距离度量,将角度距离和学习到的特征相结合,以便增强辨别力。为了验证该模型的效果,文中在FER2013人脸表情数据集上进行了实验。
1 卷积神经网络
CNN与普通多层感知器(Multilayer Perception, MLP)的区别在于其卷积层、池化层和非线性激活函数的使用。卷积层由滤波器组成,例如,5×5×1(5×5表示宽度和高度各为5个像素,1表示图像为灰度)。直观地说,卷积层用于“滑动”输入图像的宽度和高度,并计算输入区域和权重学习参数的点积,这反过来将产生二维激活图,并由给定区域处滤波器的响应组成。池化层根据卷积层中滤波器的结果减小输入图像的大小,结果使模型中的参数数量也减少,因此被称为下采样。激活函数用于在计算中引入非线性,没有激活函数,模型将只学习线性映射。目前比较常用的激活函数是ReLU函数[19],因为它与tanh,sigmoid两个函数相比,大大加速了随机梯度下降的收敛[20]。
CNN每个层包含的特征信息在整个网络中是分层分布的,较低层主要包含图像的纹理和边角特征,是图像的局部特征。较高层包含的是特定类的特征,更适合需要全局特征的复杂任务。随着层的逐渐加深,特征会变得越来越复杂和全局化。通常把全连接层提取的特征认为是高层特征,传统的CNN如Lenet[21]、Alexnet[22]等均使用单通道的全连接层,此外,传统的单一通道全连接层都是只保留了最后一层池化层的部分“重要”特征,丢弃了那些认为“不太重要”的特征,这使得全连接层提取到的特征在图像表达能力方面具有一定的局限性。为了充分利用最后一层池化层中的特征信息,同时增强全连接层对不同尺度空间特征信息的表达能力,文中设计了一个双通道全连接层卷积神经网络结构,具体如图1所示。
2 网络模型改进
2.1 Maxout激活函数
Maxout网络是一种简单的前向传播结构模型,文献[23]研究表明,传统的激活函数(如Sigmod、ReLU)都只能拟合二维函数,Maxout却可以拟合任意维度的函数。给定输入x∈Rd(x表示给定的输入特征向量或上一隐层的状态),Maxout隐层中每个神经元的计算公式如下:
hi(x)=maxzij
j∈[1,k]
(1)
zij=xTWij+bij
W∈Rd×m×k,b∈Rm×k
(2)
式中:W、b----分别表示权重和偏置,W是大小为(d,m,k)的三维矩阵;
d----输入层节点个数;
k----每个隐层节点对应的“隐隐含层”节点数,Maxout函数从k个“隐隐含层”节点中取最大值作为该层的输出。
与传统的激活函数相比,Maxout激活函数的输出表示具有非稀疏性,将其与Dropout技术结合使用,Dropout用在Maxout网络层的后面可以在一定程度上优化网络结构。
2.2 A-Softmax损失
A-Softmax损失最早在文献[18]中提出被用于人脸识别任务,其基本思想是通过操纵特征面从而产生角度间隔。
在用CNN处理多分类问题中,假定输入特征为xi,对应的标签为yi,A-Softmax损失的计算方法如下:
(3)
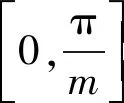
在A-Softmax损失的监督下,学习的特征构造了一个有区别的角度度量,其相当于超球面流形上的测地距离。CNN学习具有几何可解释角间隔的面部特征,因为A-Softmax损失需要Wi=1,bi=0,所以预测仅取决于样本x和Wi之间的角度,因此x可以被分类为具有最小角度的身份。添加参数m是为了学习不同身份之间的角度间隔,角度间隔随着m的增大而增大,如果m=1,角度间隔为0。A-Softmax损失通过约束学习特征从而在超球面流形上进行区分,它与超球面流形之间的紧密联系使得学习的特征对于面部识别更有效。
2.3 双通道CNN模型
文中对传统CNN模型的全连接层进行改进,构造了含双通道全连接层的CNN模型,新的CNN模型包括5个卷积层、3个池化层、1个全连接融合层和双通道的全连接层,如图1所示。

图1 双通道CNN模型
将最大池化和平均池化结合使用,可以保留更多样化的特征信息。为了防止过拟合以及提高模型的泛化性,使用了Dropout技术和批量归一化技术。与传统的CNN模型相比,文中提出的方法具有以下特点:
1)充分考虑全连接层不同神经元个数对图像高层语义特征提取能力的影响,设计了双通道融合的全连接层,增强了CNN模型的特征表达能力。
2)在双通道全连接层使用Maxout激活函数代替传统的ReLU激活函数,使网络能够表达更精确的高维特征信息。
3)考虑到在人脸表情识别过程中存在的理想面部特征具有比最小类间距离更小的最大类内距离问题,在训练过程中,使用A-Softmax损失,使CNN可以学习到具有几何可解释角度间隔的面部特征。
改进后的CNN模型各网络层参数见表1。
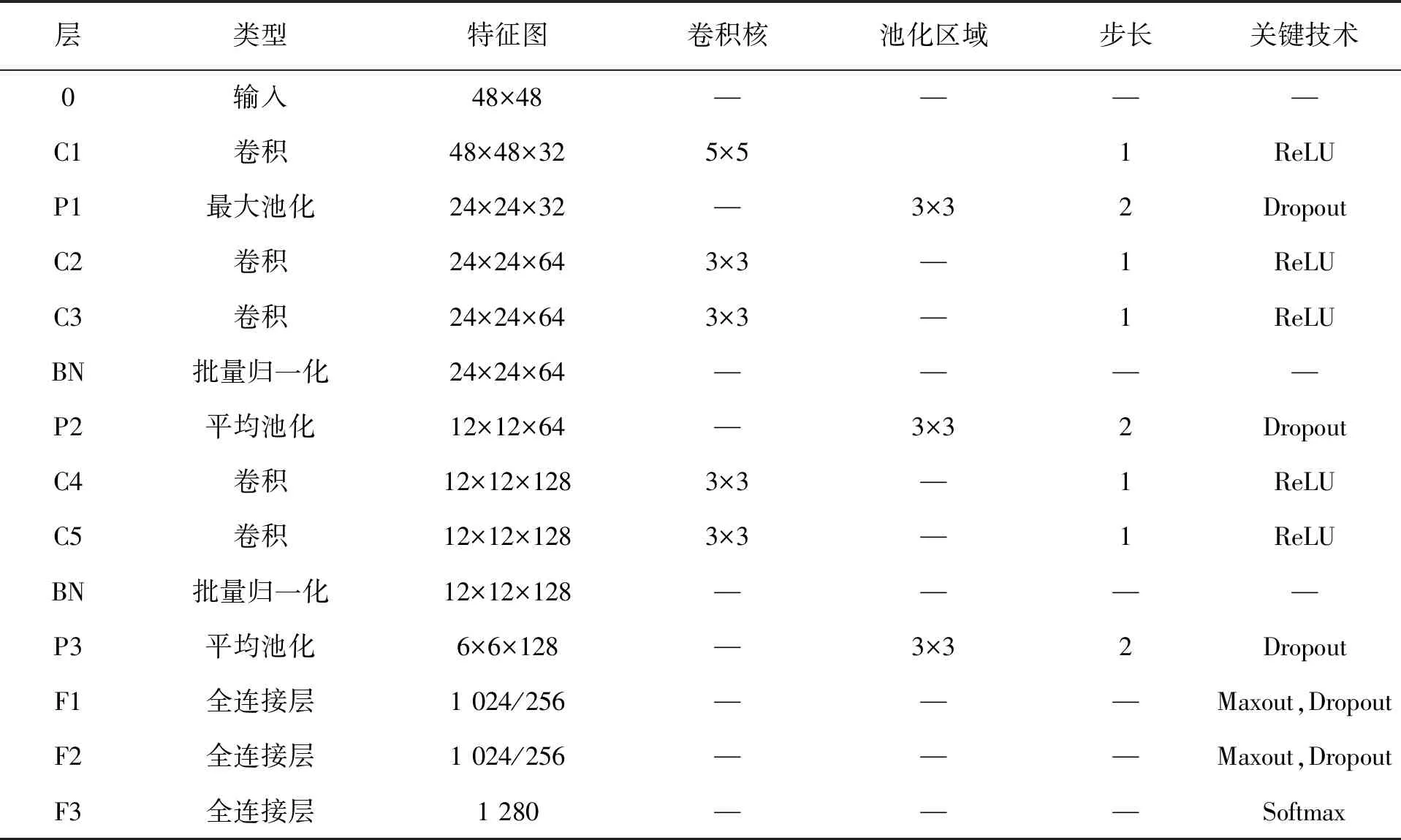
表1 双通道CNN模型参数
3 实 验
实验使用的深度学习工具为TensorFlow,所有实验都在MAC OS X上进行,使用CPU为2.9 GHz Intel Core i5,内存为8 G,硬盘为1 T。
3.1 数据集
传统方式进行人脸表情识别通常是手动提取特征,这些特征对光照、姿态和遮挡变化的容忍度较差,用于这些方法的数据集主要在特定环境(例如在实验室中)中收集,仅具有正面面部图像,并且一些表情是不自然和夸大的,这导致许多方法受数据库影响,如果将这些方法推广到其他数据集或现实,获得良好性能的概率将非常小。文中实验使用的是Kaggle网站提供的FER2013人脸表情数据集,它是自发面部表情的代表性数据集,包含年龄、种族、性别、姿势、背景、光照和遮挡等多种变化,如图2所示。

图2 FER2013数据集
该数据集由35 887个48×48像素的灰度图像组成,包含7种表情:高兴、悲伤、厌恶、恐惧、吃惊、生气、中性。图像的处理方式使得面部几乎居中,每个面部在每张图片中大约占据相同的空间。
3.2 预处理
为了使模型对噪声和轻微变化更具有鲁棒性,使用了简单的数据扩增技术,首先水平翻转图像,然后对每个图像以(-20,20)之间的随机角度进行旋转,最后将所有图像归一化为具有零均值和单位方差。
3.3 实验结果及分析
采用双通道CNN模型在FER2013数据集上进行了实验,卷积层和全连接层全部使用ReLU激活函数,在第三和第五卷积层之后使用批量归一化技术,训练模型时使用交叉熵损失函数,初始化学习率为10e-4,卷积层和全连接层Dropout大小均为0.9。使用Adam优化器,在训练模型时,分别对三组拥有不同参数的双通道全连接层进行实验,三组双通道参数分别为:
1)通道1:1 024-1 024,通道2:256-256;
2)通道1:2 048-1 024,通道2:1 024-256;
3)通道1:4 096-4 096,通道2:256-256。
用上述三组参数进行多次实验,发现只有1)中的参数表现出较好的效果。用1)中的参数在FER2013数据集上重复进行了5次实验,测试结果的准确率,见表2。
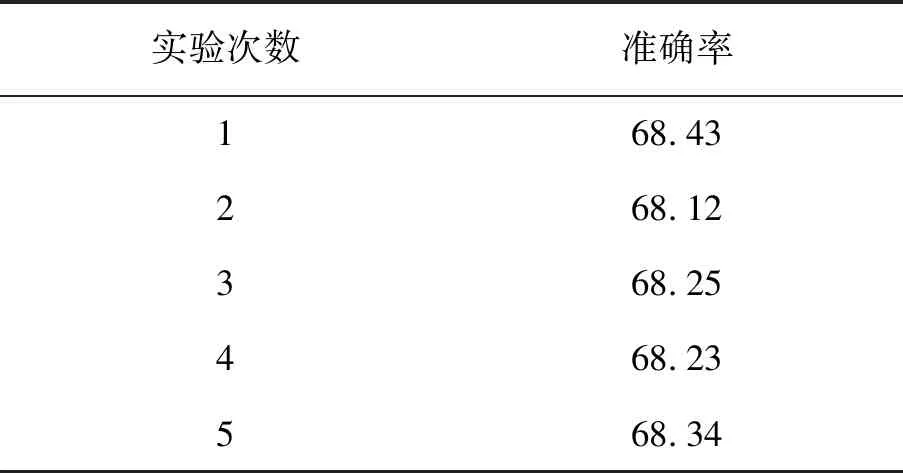
表2 双通道CNN模型5次实验准确率 %
分别对改进前后的模型在训练过程中的准确率进行了可视化,仅改变全连接层通道数,保持上述实验中其它参数不变,传统单通道全连接层CNN模型在FER2013数据集上的准确率约为67.2%,使用双通道全连接层的CNN模型通过提取不同尺度的特征信息,可以有效地提高模型的特征表达能力,能够使模型的准确率提升约1%,如图3所示。
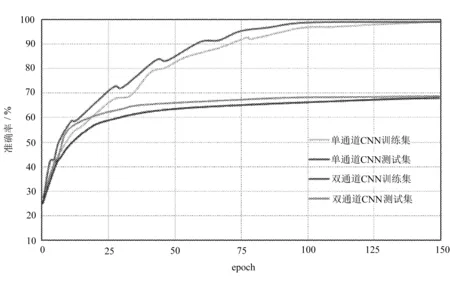
图3 FER2013数据集的训练集和测试集准确率曲线
为了让CNN模型能够更好地拟合图像的高维特征,在全连接层使用Maxout激活函数代替上述实验中的ReLU激活函数,设“隐隐含层”神经元个数为5,在使用A-Softmax损失训练模型时,其参数m用来学习不同类特征之间的角度间隔,设m值为4,最后结合数据扩增技术分别在FER2013数据集上进行实验,此次实验中卷积层Dropout为0.8,全连接层Dropout为0.5,学习率为10e-4,使用Adam优化器进行训练,实验结果见表3。

表3 不同方法在FER2013数据集上准确率对比 %
使用传统CNN模型和文中方法在FER2013数据集上不同表情的分类准确率如图4所示。

图4 不同表情分类准确率对比
从图4可以看出,两个模型预测高兴标签的准确率都比较高,说明了高兴表情特征比其它表情特征都更容易识别。其次,对比传统CNN模型和文中方法,使用文中方法能够使大多数表情标签的识别准确率提高,而使厌恶和悲伤两种表情的识别准确率下降,说明不同模型对不同表情的分类能力不同,使用传统CNN模型更有利于识别厌恶和悲伤两种表情。最后,观察生气和恐惧两种表情的识别结果,发现两种表情的识别准确率都有所提升,使用文中方法后两种表情的类间距离变大。
4 结 语
为了使提取的特征对光照、姿态和遮挡等变化具有较好的容忍度,文中在传统CNN模型的基础上,将单通道的全连接层改成双通道,提升了全连接层对高层语义特征的表达能力,在全连接层使用Maxout激活函数代替传统的ReLU激活函数,使网络能够表达更精确的高维特征信息。在训练过程中,使用A-Softmax损失,使改进后的CNN模型可学习到具有几何可解释角度间隔的面部特征。试验表明,文中方法具有较好的效果。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
昆明医科大学学报(2021年4期)2021-07-23 01:21:56
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年11期)2019-07-04 00:34:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电子设计工程(2015年16期)2015-02-27 12:07:56
电视技术(2014年19期)2014-03-11 15:38:20
