
基于深度卷积神经网络的柑橘目标识别方法
2019-06-04 01:10陈俊文
农业机械学报 2019年5期
毕 松 高 峰 陈俊文 张 潞
(北方工业大学电气与控制工程学院, 北京 100041)
0 引言
我国为世界上重要的水果生产国之一,自2012年以来,我国柑橘、苹果等主要水果品种的种植面积和产量已居世界第一。2017年,我国柑橘产量为3 816.78万t[1],占世界柑橘产量的四分之一。采摘是水果生产过程中劳动力投入最大的作业环节,柑橘采摘劳动量为整个生产过程工作量的50%~70%,所处环境的复杂性导致水果采摘仍然以人工作业为主[2]。水果自动化采摘对于解决劳动力不足、保证水果适时采摘、提高采摘品质和市场竞争力等具有重要意义。因此,研究水果自动化采摘技术迫在眉睫[3]。
柑橘目标识别是自动采摘的基础,众多研究者主要从颜色、纹理、边缘等多个特征综合角度出发,研究了限定环境下或自然环境下果实目标识别方法[4-17]。利用多种分类和聚类算法设计目标识别模型,获得了较好的目标检测效果。但上述方法的基础是从果实自身特征出发获得图像特征,当存在光线变化、阴影覆盖、着色不均、枝叶遮挡和果实重叠等多种自然采摘环境下常见干扰因素时,果实特征发生明显变化,使得用于描述果实的特征也出现明显的不同,因此基于图像特征的柑橘识别方法在自然环境下检测效果不理想。
自然环境下柑橘图像的特征在不同干扰因素下具有明显的差异。自然环境下干扰因素较多且变化较大,难以获得涵盖上述所有干扰情形的柑橘目标特征,因此基于图像分析的柑橘目标识别方法难以应对自然环境下多种干扰因素同时存在的情况。
针对户外柑橘采摘机器人的目标识别定位问题,本文设计基于深度卷积神经网络的自然环境下柑橘目标识别模型。对实际采收环境下的柑橘目标进行数据测试。
1 柑橘目标识别方法
基于图像的柑橘目标识别的基础在于获得可稳定描述自然环境下柑橘目标的图像特征,而大部分传统的目标特征提取方法都是在提取目标物体的浅层特征,如HOG特征、SIFT特征、颜色特征、局部二值特征等。这些人工设计的特征只适用于某些特定场景,复杂场景中表现的并不尽如人意,致使构建的目标识别模型难以满足复杂田间场景的需求,检测效果很不稳定。深度学习模型具有模型层次深、特征表达能力强的特点,能自适应地从大规模数据集中学习当前任务所需要的特征表达[18],在目标识别领域,卢宏涛等[19]认为使用深度学习方法提取到的特征具有传统手工特征所不具备的重要特性,其通过逐层训练学习,最终得到蕴涵清晰语义信息的特征表示,从而大大提高识别率。自然采摘环境的干扰因素多是典型的复杂场景,目标随环境干扰因素变化而难以获得完备的目标特征集,基于深度卷积神经网络模型的柑橘目标视觉识别方法,可以克服自然环境下的多种干扰条件影响,获得较高的识别准确性和稳定性。
基于深度卷积神经网络的柑橘识别模型主要分为图像预处理模块、深度特征提取模块、特征处理模块。柑橘识别模型结构如图1所示。
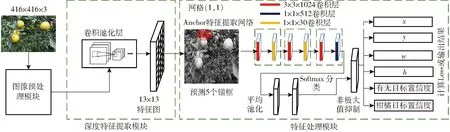
图1 自然环境下的柑橘识别模型网络结构Fig.1 Network structure diagram of citrus recognition system in natural environment
图像预处理模块对图像进行降噪和数据扩展等操作,调节图像的色调、饱和度和亮度后,图像在输入网络之前进行预处理,尺寸缩放到416像素×416像素。深度特征提取模块实现了基于DARKNET19网络[20]的卷积池化构建方法,提取完整图像的高阶特征,经过卷积池化层后得到13×13特征图。
特征处理模块分为区域生成网络模块(Region proposal network,RPN)和预测框特征提取分类模块。特征处理模块通过多个交叉的卷积层对特征降维,并利用池化操作提取柑橘图像的高阶特征,进而对特征进行分类。区域生成网络模块利用锚框(Anchor boxes)方法在获得的特征图上预测初始预选框。利于K均值聚类(K-means clustering)算法求取锚框参数并预测出锚框尺寸和比例,K是聚类算法将样本集划分成簇的数量,实验测得K=5时锚框预测的正确率最高。深度特征提取模块中,图像经过卷积池化层后,特征图维数为13×13。对特征图的每个网格按照预测出的比例划出5个锚框(以图1中13×13特征图的第1行第1列网格为例,网格(1,1)表示该网格)并将这5个锚框映射回原图得到初始预选框。预测框特征提取分类模块的结构基于DARKNET19网络,在网络训练阶段移除DARKNET19网络最后一个卷积层,增加3个3×3×1 024的卷积层,并且在后面与1个1×1×512的卷积层和2个1×1×30的卷积层交叉,从而提高模型的特征抽取能力。由于经过多层卷积后特征向量的维度大幅增高,不利于数据分类与训练收敛,加大了网络的训练和预测时间,因此设计3层3×3卷积层和3层1×1卷积层交叉结构对特征降维,从而降低其深度以提高系统的训练效率与实时性。
将提取到的图像特征全局平均池化,并将其输入到Softmax层进行分类得出预测结果。预测结果包含6个元素:对应网格的偏移量x和y、预测出的柑橘目标边界框的宽度w和高度h、有无目标置信度(Box confidence score)和柑橘目标置信度。有无目标置信度表示该目标框包含柑橘目标的可能性,柑橘目标置信度表示如果包含柑橘目标,则该目标是柑橘的可能性,因此预测结果维度为(13,13,5×(4+1+C)),其中C是目标类别。由于只需检测柑橘,因此C=1,预测结果的维度即为(13,13,30)。本文在训练阶段利用Softmax分类器将输出数值与标签数据比较得到其总损失,进而使用随机梯度下降(Stochastic gradient descent, SGD)优化损失函数使其收敛。在检测阶段,每个组合的结果分别是预选框位置相对于标签位置偏移量,有目标的置信度、以及有某个指定目标的置信度,柑橘识别模型只需要柑橘置信度,因此只有一类。
2 基于迁移学习的网络初始化
迁移学习利用预先训练好的具有良好学习能力的网络模型参数初始化某个小型训练集模型参数,这种参数初始化方法可以将已学习的知识能力迁移到另一个网络中,使得新网络具有快速学习能力[21],从而显著改善因训练数据集不足带来的网络过拟合问题,增加识别模型在复杂自然条件下柑橘目标识别的泛化能力。
ImageNet数据集是目前图像深度学习领域应用较广的数据集,与图像分类、定位、检测相关的工作大多基于此数据集展开,成为目前深度学习图像领域算法性能检验的“标准”数据集。本文使用标准ImageNet1000类数据集预训练柑橘识别模型。对于每个网格5个预选框给出的30个数值,每个目标只需要一个预选框预测器,根据预测区域与标签区域之间的重叠比例(IOU)最高值确定预测目标,从而使预测器更好地适应柑橘识别任务,从而改善整体召回率。训练期间的损失函数(Loss function)包含位置误差和分类误差。
若目标存在于该网格单元中,则损失函数仅惩罚分类错误;若预测器负责实际边界框,则也惩罚边界框坐标错误。网络更加重视预测到目标的预测框,加入预测到目标的预测框系数λcoord来提高其数值占比。在VOC2007数据集下,这一数值为5,相应的,对于没有检测到目标的预测框,加入未预测到目标的预测框系数λnoobj来降低其数值占比,本文取0.5。在训练过程中,通过优化算法使得Loss函数收敛到最小。在预测阶段,由于网格设计强化了边界框预测中的空间多样性,一些较大或靠近多个网格单元边界的目标可能会被多个网格单元定位,因此本文使用非极大值抑制算法[22]来修正多重检测,从而获得准确的识别结果。
3 迁移学习结果与分析
3.1 实验设计
为保证数据集能够较好地反映自然环境下柑橘目标的真实特点,在广西合浦柑橘种植园拍摄了1 200幅柑橘样本图像,拍摄时间包括晴天正午、晴天傍晚以及阴天正午3个时段。选用Basler acA2440-20gc型工业相机采集图像数据,采用焦距为8 mm的定焦镜头。经过人工挑选后制作了包括1 000幅柑橘图像的VOC2007格式的数据集。为保证训练集的有效性,训练集中包含光照不均图像241幅、前背景相似图像134幅、果实以及枝叶相互遮挡图像246幅、阴影覆盖图像211幅、过曝图像168幅。将1 000幅图像按照训练集、测试集、验证集7∶2∶1的比例配置。以端到端训练方式对上述训练集进行训练,并计算平均损失率和在全体测试集和验证集上的平均准确率(Mean average precision,MAP)。
同时为了验证本文方法的有效性,将可变性部件模型[23](Deformable part model,DPM)与本文模型进行对比测试。DPM算法提取目标的HOG特征,并使用支持向量机分类器,源码版本选择voc-release 4.01,训练50 000次,数据集依然采用VOC2007格式,按照训练集、测试集7∶3的配置分配训练。
3.2 实验数据性能指标计算方法
本文方法和DPM算法均使用VOC2007格式数据集和P-R曲线测试网络性能。P-R曲线的数据插值方法使用VOC2007规范,即11点插值法(Eleven-point interpolation)。对于网络检测出来的目标,定为Positive样本,未检测出来的目标定为Negative样本。采用0.5为IOU阈值,大于0.5的认定为检测正确,检测结果为T;反之,则为检测错误,检测结果为F。故实验结果有4种,分别为检测出来的IOU值小于等于0.5的目标FP、检测出来的IOU值大于0.5的目标TP、未检测出来的真值目标FN、TN。本文不统计TN类样本。准确率(Precision)的计算方法为
(1)
式中TP——检测出来的IOU值大于0.5的目标数量
FP——检测出来的IOU值小于等于0.5的目标数量
召回率(Recall)为识别出的柑橘数占图像中总目标数的比例,其计算方法为
(2)
式中FN——未检测出来的真值目标数量
3.3 结果分析
迁移学习具有良好的泛化能力且具有良好的抑制过拟合能力,本文利用迁移学习和非迁移学习训练柑橘目标识别模型,训练损失如图2所示。

图2 迁移学习与非迁移学习方法训练损失Fig.2 Training loss of transfer learning and non-transfer learning methods
从图2可知,迁移学习可以使得训练过程更加平滑,在相同训练轮数下,其平均损失远低于未使用迁移学习。训练结束后,迁移学习在召回率大于后者的情况下,依然可以取得更好的平均准确率。两种训练方法的参数如表1所示。
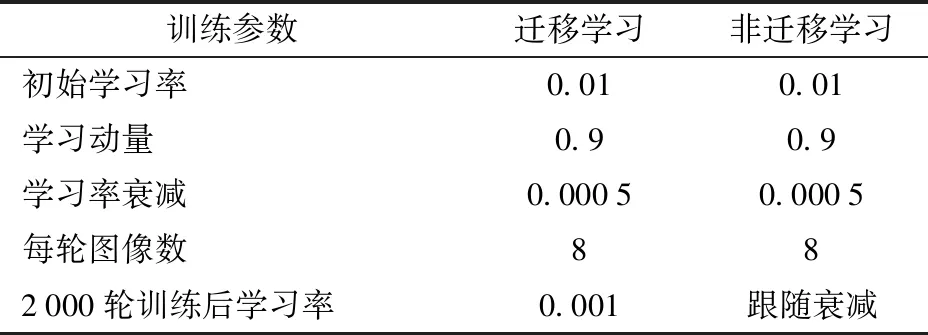
表1 迁移学习与非迁移学习训练参数Tab.1 Training parameters of transfer learning and non-transfer learning methods
迁移学习与非迁移学习方法的基本训练参数相同,初始学习率取0.01,动量为0.9,学习衰减率为0.000 5,每轮训练图像数量为8。2 000轮训练后,迁移学习的学习率固定,陷入局部最优。未使用迁移学习的网络在达到局部最优后,即使降低学习率也并不能使得网络平均损失率明显下降。迁移学习和非迁移学习训练方法的平均损失、最大召回率和平均准确率如表2所示。
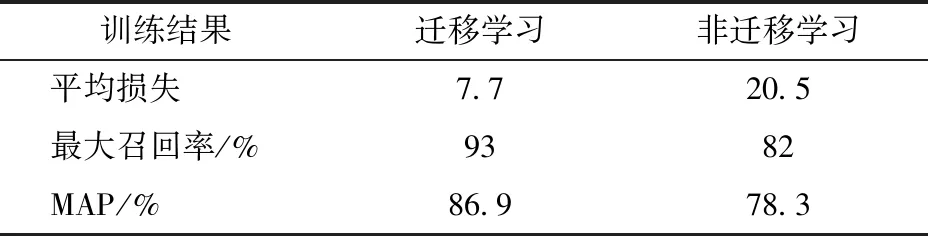
表2 迁移学习与非迁移学习训练结果Tab.2 Training results of transfer learning and non-transfer learning methods
由表2可知,非迁移学习训练的柑橘目标识别模型获得的平均损失为20.5,本文通过降低学习率的方法使得平均损失下降了12.8,最终平均损失达到了7.7。训练结束后,在验证、测试数据集上计算平均准确率,分别为86.9%和78.3%。基于迁移学习方法训练的模型平均损失较低,平均准确率较高,有效提高了模型的性能。
使用迁移学习和未使用迁移学习训练模型的柑橘目标检测结果如图3所示。

图3 迁移学习和非迁移学习训练模型检测结果Fig.3 Test results of transfer learning and non-transfer learning methods
图3a中标号1的结果将两个识别条件良好的柑橘识别成了一个,而且还存在目标框重叠问题,标号2结果将两个相互重叠的柑橘识别成一个目标。作为对比,图3b中标号1、2的检测结果都能正确区分并识别柑橘,并且图3b识别出了更多的柑橘,可以看出迁移学习的检测系统具有更高的召回率。由图3可知,两种训练方法都识别出柑橘目标,但常规训练下的网络识别出的柑橘目标框存在较大的误差与较低的召回率。由此可知迁移学习可以提高网络的目标检测性能。
DPM算法是目前常用目标检测算法之一。DPM算法与本文方法在自然采摘环境下柑橘目标识别的P-R曲线如图4所示。测试集和验证集共包含300幅图像,包括光照不均、前背景相似、果实以及枝叶相互遮挡、阴影覆盖、过曝。
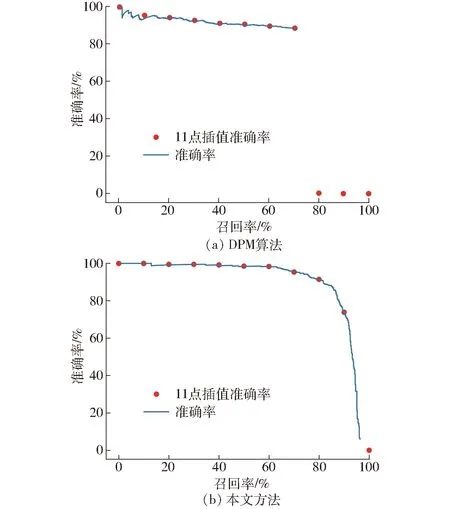
图4 两种方法的P-R曲线Fig.4 P-R curves of two methods
图4a中DPM算法的P-R曲线平均准确率为67.56%,远低于本文方法的86.91%。本文方法较DPM算法具有更高的召回率,且P-R曲线较DPM算法曲线更加平滑稳定,在较高召回率情况下,依旧可以保持较高的准确率。以人工进行柑橘目标识别标注的结果为标准,在不同干扰因素下,DPM算法与本文方法的识别平均准确率对比如表3所示。
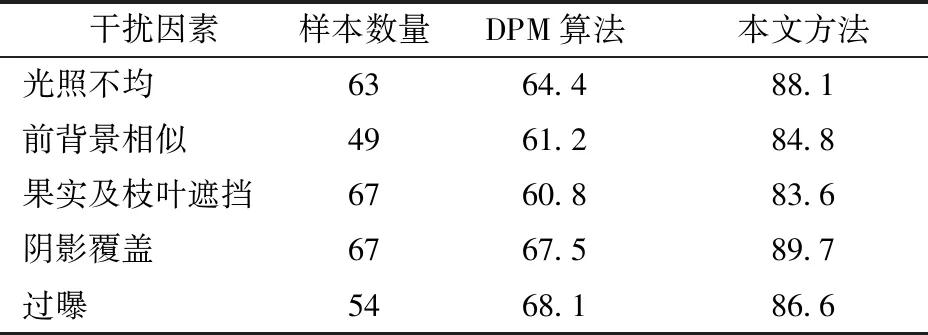
表3 DPM算法与本文方法识别平均准确率对比Tab.3 Experimental result of citrus using DPM and proposed method %
从表3可知,DPM算法的准确率远低于本文方法。针对果实与枝叶遮挡条件,评估所用数据集包含67幅存在果实与枝叶遮挡的图像,遮挡率的计算方法为67幅遮挡图中被遮挡柑橘的遮挡面积占其总面积的比率均值,经统计,平均遮挡率为48%,DPM算法检测的准确率只有60.8%,而本文方法准确率为83.6%。同时,本文方法在表3的多个影响因素下的识别平均准确率的均值为86.6%。
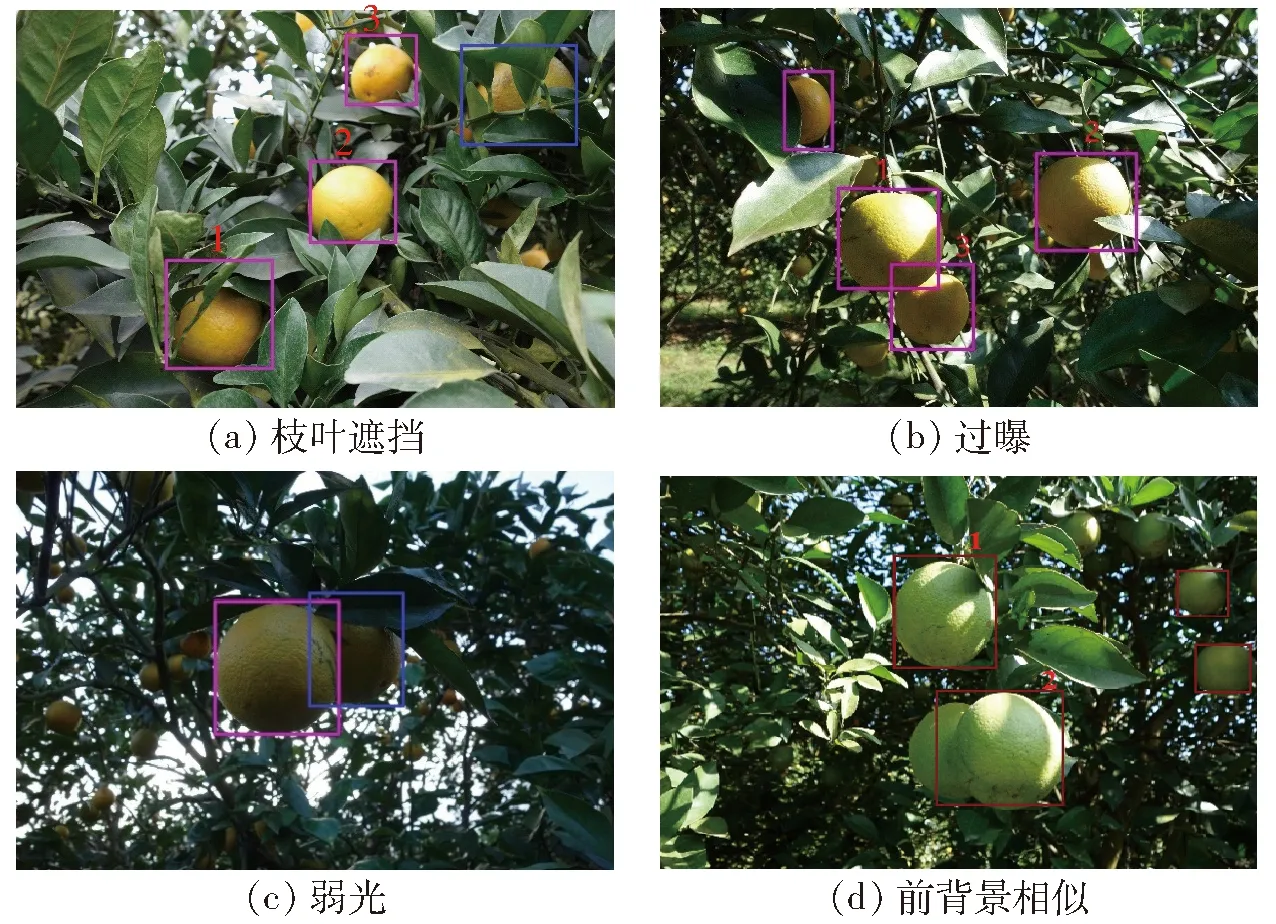
图5 本文方法对自然条件下柑橘目标识别结果Fig.5 Detecting results of citrus by proposed method under natural conditions
本文方法的目标识别结果如图5所示。图5a中,枝叶遮挡面积小于50%(图中标号1、2、3),其IOU值分别为0.8、0.95、0.9。但如果遮挡面积过大,则依旧无法成功识别(图中蓝框)。蓝框中的柑橘具有标签值,但未被识别,相当于IOU值为0,分类结果为FN。其他情形以此类推。图5b中,标号1、2、3的样本存在阴影覆盖和过曝,本文方法依然可以识别柑橘目标。图5c中,弱光条件下,柑橘纹理不明显,同时颜色也有较大变化,个别位置甚至可能出现柑橘和枝叶颜色混合的现象,这时不管是SIFT特征还是HOG特征效果较差。但使用本文方法均可准确识别柑橘。蓝框标出的柑橘由于光照条件太差,颜色信息损失太多并未成功识别。图5d中,在前背景相似情况下,柑橘颜色几乎和枝叶颜色融为一体,同时还伴有光照变化和阴影覆盖等情况存在。本文所设计的模型取得了较好的效果,其中识别效果较差的2号柑橘的IOU仍可达到0.8,分类结果为TP。由图5识别结果可知,本文方法能够有效地应对多种户外采摘条件下的干扰因素。
实地拍摄的图像尺寸为2 448像素×2 448像素,由于图像像素较大,柑橘较小,因此将图像分成4幅有重叠的子图进行识别,子图尺寸为1 000像素×1 000像素。识别模型将子图缩放到416像素×416像素,识别完成后将识别结果聚合,以此实现多尺度图像的识别。本文所设计的柑橘目标识别模型的运算平台为i7-6850K CPU,Nvidia GTX 1080Ti GPU,内存32 GB。识别时间为从将图像分割成4幅子图到将4幅子图识别结果聚合在一起输出最后识别结果的总时间。经测试,1 000幅图像的平均识别速度为12.5帧/s,因此该模型具有良好的实时性,能够满足实际自动化采摘的目标识别速度要求。
4 结论
(1)设计的基于深度卷积神经网络的柑橘目标识别模型对光照变化、亮度不匀、前背景相似、果实及枝叶相互遮挡、阴影覆盖等实际采摘环境下常见干扰因素及其叠加情形具有良好的鲁棒性,可为柑橘采摘机器人设计提供参考。
(2)本文方法对柑橘识别的平均准确率均值达到了86.6%,平均损失为7.7,最大召回率为93%,实验结果表明,该模型能够在自然采摘环境下进行准确和快速的柑橘目标识别及定位。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
幼儿教育·父母孩子版(2020年6期)2020-07-27
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
数位时尚(幼儿教育)(2018年10期)2018-10-30
北京航空航天大学学报(2018年1期)2018-04-20
