
劳均可负担耕地面积与机械化程度的关系研究
2019-05-27 08:53:40吕洋洋王福林李志远赵逸翔
农机化研究 2019年8期
吕洋洋,王福林,李志远,赵逸翔
(东北农业大学 工程学院,哈尔滨 150030)
0 引言
我国作为农业人口大国,农村人口占全国人口的比例高达2/3。自实施农村土地经营制度及实现大面积农业机械化以来,涌现出了数以亿计的农村剩余劳动力。农村剩余劳动力是指超过农村产业需求的一部分劳动力,是一个相对和动态的概念。农村剩余劳动力的多少会随着耕地面积、机械化程度、种植结构等条件的变化而变化。它的存在及其在全国的大量无序流动将带来许多经济和社会问题。为了从根本上解决“三农”问题,首先必须要科学估算农村剩余劳动力数量。近年来,学者们对农村剩余量的估算做了大量的研究,其使用的方法和结果不尽相同,但大多数学者都没有考虑机械化程度对农村剩余劳动力数量的影响[1-3]。
在农业生产过程当中,农业机械发挥着无人不晓的作用,如提高农业抵抗自然灾害的能力、改善生产条件、减弱农业劳动强度及提高劳动生产率[4]。农业机械与农业劳动力之间存在明显的替代现象,农业机械化水平的不断提高,将加速中国农业剩余劳动力的产生[5]。本文推导建立了劳均可承担耕地面积与农业机械化程度的模型,并在此基础上给出了模型中参数的获取和处理方法。以黑龙江省红星隆分局八五四农场为研究对象,调查了该农场10 100个劳动力在农业机械化程度是0和100%时可承担的耕地面积大小,最后利用准确的数据及研究模型得出宝清县在不同农业机械化程度下农民种植水田可承担的劳均耕地面积。
1 劳均可负担耕地面积估算模型的建立
由农业机械化程度的定义[6]可知,设S为耕地面积,s1为机械化的作业面积,x为机械化程度,则

(1)
s1=s·x
(2)
所以,人畜力完成的作业面积s2为
s2=s-s1=s(1-x)
(3)
则
s=s1+s2=s·x+s·(1-x)
(4)
如果L(x)代表农业机械化程度是x时所需劳动力数量,则每公顷耕地面积在农业机械化程度100%时所需的劳动力数量为m,在机械化程度0时所需的劳动力数量为n,则
L(x)=m·s1+n·s2=m·s·x+n·s·(1-x)
(5)
令l(x)为劳均可负担耕地面积,则
(6)
将公式(5)代入公式(6)得
(7)
在农业机械化程度100%时,每个劳动力的耕地面积为
(8)
农业机械化程度0时,每个劳动力的耕地面积为
(9)
将公式(8)和公式(9)代入公式(7)得
(10)
公式(10)是平均各劳动力的耕地面积l(x)与农业机械化程度x之间关系的模型。在该模型中,有两个参数l(100%)和l(0)。
2 数据获取研究
模型中有两个参数:农业机械化程度100%时的平均各劳动力可负担耕地面积l(100%)和机械化程度0时平均各劳动力可负担耕地面积l(0)。
对于l(100%)和l(0)这两个参数,虽然不能在统计资料中通过查询得到,但可通过深入生产实际进行走访调研的方式来获得。有两种具体的方法来确定:一是通过对农村的走访调研直接确定l(100%)和l(0)的值;二是调查当前机械化水平下劳动力所能承担的耕地面积,然后对机械化程度和各劳动力所能承担的耕地面积这两组数据进行回归分析,通过建立的回归模型求出上述两个参数的值。需要指出的是:不管采取哪一种获取办法,调研样本一定要足够多,起码应不小于50个,而且要对样本进行统计检验。如果检验结果不通过,则需要增加样本的数量,直到可以通过统计检验为止。此外,在走访调研中需要注意的是:首先在走访调研之前,要将调查表格设计完全;其次,要明确指出劳动力可承担的耕地面积是在耕作最忙碌的时刻确定的,即投入的劳动力数目是最多的时候确定的;最后,如果避免不了必要的季节性雇工,那么雇佣的劳动力数量应该加入到劳动力的需求数量之中。
3 分布检验
数据测量常因干扰数据的存在使正常数据发生偏离,进而会给后续的分析带来很多麻烦甚至严重后果。为了提高数据的可靠性,不能从主观上剔除异常数据,需要进行统计检验,根据统计规律判断是否有异常数据。如果有异常数据,则应从中删除[7]。
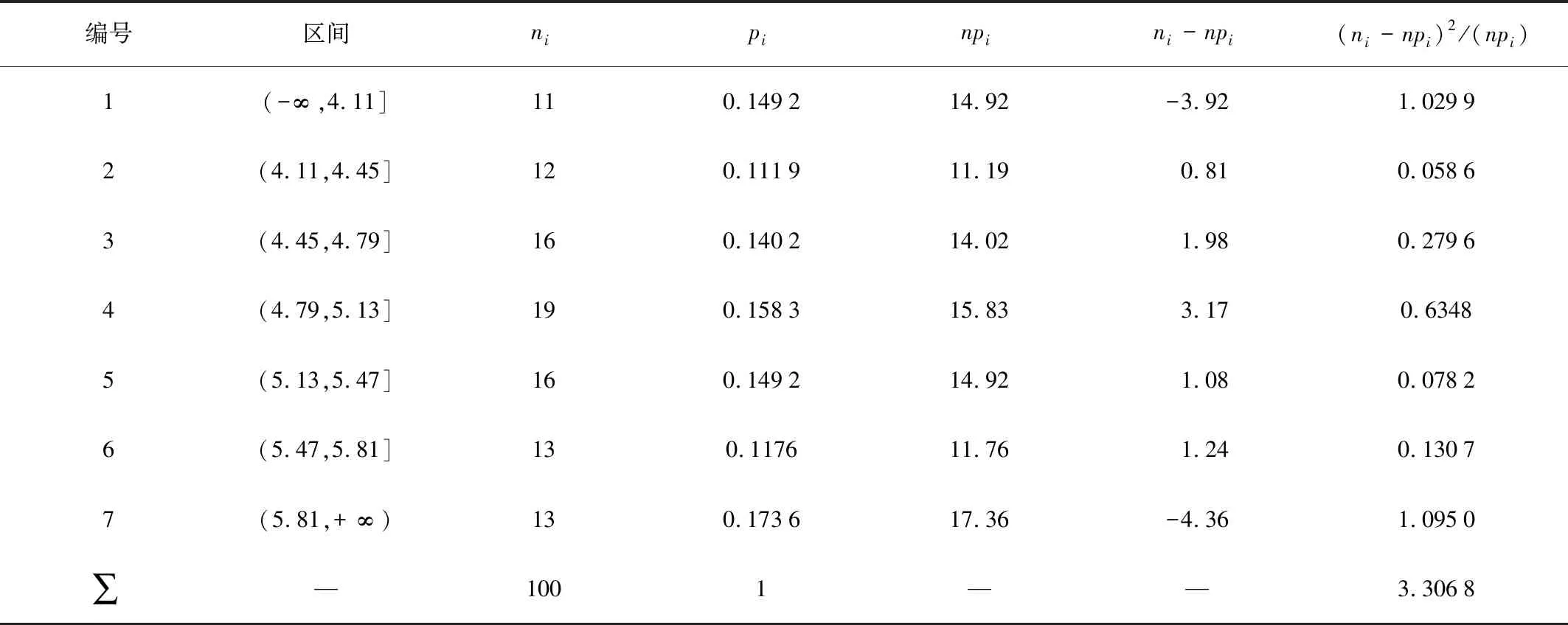
分布检验的常用方法是χ2检验[10],其基本思路是:将随机测试的所有结果Ω划分为k个互不兼容事件A1,A2,…Ai,…,Ak(A1∪A2∪…∪Ai∪…∪Ak=Ω),Ai∩Aj=∅,i≠j,i,j=1,2,…,k。于是,在假设H0下,可以计算pi=P(Ai),i,j=1,2,…,k。显然,在n次试验中,事件Ai的频率ni/n和pi是不同的。若假设H0成立,则差异一般不显著;若H0不成立,则这种差异就显著。
基于这种想法,采用皮尔逊统计量,即

(11)
式(11)作为衡量检验假设H0与实际吻合程度的尺度。
假设总体X的理论分布是函数F(x),x1,x2,…,xn是来自F(x)的样本,F0(x)是预先给定的一个分布函数,则
H0:F(x)=F0(x),H1:F(x)≠F0(x)
(12)
χ2检验法的具体操作步骤如下:
1)样本数值分为k个互不相交的区间(a0,a1],(a1,a2],…,(ai-1,ai],…,(ak-1,ak]。其中,-∞ 2)计算样本中落入每一区间(ai-1,ai](i=1,2,…,k)中的数量ni,ni称为实测频数。 3)求理论分布下落在(ai-1,ai]内的概率,当假设H0为真时,X落在(ai-1,ai]内的概率为pi=P(ai-1 “且要异论相搅”,“事为之防,曲为之制”,乃是宋代统治者巩固其集权统治的“家法”,后世即便具有改革要求的君主也都不能不遵守此一“家法”,其负面影响不可避免: 4)做统计量,即 (13) 根据皮尔逊定理知χ2~χ2(k-r-1),r是F0(x)中被估计参数的个数。 6)由样本数据计算出统计量χ2的值。 χ2检验法是在n趋向于无穷大时推导出来的,所以在实际应用过程中要保证n一定要足够大及npi不能过小这两个基本条件。正常情况下,样本容量要满足n≥50,∀npi≥5的要求,最好达到npi≥10的要求。如果满足不了上述要求,就应当适当地合并区间以达到要求。 计量测量不但对数据的精确性有很高的要求,且在得到大量数据后还需要有效地剔除其中的异常数据,从而保证得到有效性的数据。 假定各劳动力承担的耕地面积抽样数据经过检验后服从正态分布,则记为X~N(μ,σ2),μ表示每个劳动力耕地面积的数学期望,σ2表示每个劳动力承担耕地面积的方差。因此,根据数理统计学原理,随机变量X的概率密度为 (14) 其中,μ、σ(σ>0)是两个常数,称X为服从参数是μ和σ的正态分布,记作X~N(μ,σ2)。它的分布函数为 (15) 当μ=0、σ=1时,则X服从标准正态分布。用φ(x)和Φ(x)分别表示其概率密度和分布函数,即 (16) (17) (18) (19) 依照上述原则,样本中任意一个观测数据与该样本的期望值μ的差值的绝对值小于3σ的概率可以表示为 (20) 目前,世界上许多国家对质量控制的标准各有不同,但大多数是以μ+3σ为界。即当样本的观测值在区间[μ±3σ]范围内,可认为该观测值正常;若样本的观测值不在这个区间范围内,则可以认为该观测值异常,应予以剔除。该异常值的剔除方法叫作3σ原则。本文按照上述异常数据的剔除方法,剔除了实例中的每个劳动力可负担的耕地面积中的异常数据。 (21) (22) (23) (24) 通过对黑龙江省红星隆分局八五四农场10个生产队100个劳动力的调研,按从小到大排序,得到农业机械化程度为0时各劳动力耕地面积的大小如表1所示,农业机械化程度为100%时各劳动力耕地面积的大小如表2所示。 利用表1中的数据可计算出农业机械化程度为0时每个劳动力耕地面积的平均值和标准差为 (25) σ(0)≈0.2402 (26) 表1 当机械化程度为0时各劳动力负担耕地面积的调查表 表2 当机械化程度为100%时各劳动力可负担耕地面积的调查表 续表2 利用表2中的数据可计算出机械化程度为100%时每个劳动力可承担耕地面积的平均数和标准差为 (27) σ(100%)≈0.8592 (28) 假定每个劳动力可负担耕地面积的数值服从正态分布,由于正态分布函数的定义域是(-∞,+∞),所以将表1中的100个数据被划分为7个区间:第1个区间是(-∞,1.12],最后1个区间是(1.72,+∞),其余5个区间按组距0.12进行划分。将表2中的100个样本数据也划分为7个区间:第1个区间是(-∞,4.11],最后1个区间是(5.81,+∞),其余5个区间按组距0.34划分。 当假设H0成立时,表1样本数据ξ落在各区间的概率估值为 pi(0)=P(0){ai-1(0)<ξ(0)≤ai(0)} (29) 当假设H0成立时,表2样本数据ξ落在各区间的概率估值为 pi(100%) =P(100%){ai-1(100%)<ξ(100%)≤ai(100%)} (30) 当i=1,2,…,k时,可分别计算出pi(0)和pi(100%)的值,其结果如表3和表4所示。当机械化程度为0时,其χ2值为 (31) 其自由度是K-r-1=7-2-1=4,如果取α=0.05,通过查询χ2分布表得 (32) 表3 机械化程度为0时各劳动力负担耕地面积的χ2检验计算表 续表3 μ(0)±3σ(0)=1.4686±3×0.2402 =[0.7480,2.1892] (33) 所以,表1中的2.19、2.19和2.31这3个数据为异常数据,应予以剔除。剔除后,机械化为0时劳均可负担耕地面积为 =1.4451≈1.45hm2 (34) 表4 机械化程度为100%时各劳动力负担耕地面积的χ2检验计算表 同理,χ2=3.306 8<9.488,所以接受H0。即当机械化程度为100%时,每个劳动力可负担的耕地面积也符合正态分布,则 μ(100%)±3σ(100%)=5.0012±3×0.8592 =[2.4236,7.5788] (35) 所以,表2中的7.59和7.91这两个数据为异常数据,应予以剔除。剔除后,机械化为100%时劳均可负担耕地面积为 (36) 将l(0)=1.45hm2和l(100%)=4.95hm2代入上述公式(10),经整理得 (37) 用式(37)可计算不同农业机械化程度下平均各劳动力可负担耕地面积的大小,结果如表5所示。 表5 不同机械化程度下平均各劳动力可负担耕地面积 1)建立了平均各劳动力可负担耕地面积与农业机械化程度之间的关系模型。 2)给出了获取、检验模型参数的方法及异常数据剔除、整理的方法,并经分布检验得出每个劳动力可承担的耕地面积大小在种植业机械化程度为0和100%时均符合正态分布。 3)通过剔除调研数据中的异常数据,分别整理出机械程度为0和100%时人均耕地面积为1.45hm2和4.95hm2。 4)根据模型,计算给出了黑龙江省红星隆分局八五四农场的劳动力在不同机械化程度下的劳均可负担耕地面积。
4 异常数据的剔除方法



5 数据整理方法

6 实例计算








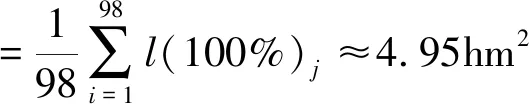

7 结论
猜你喜欢
中学数学研究(广东)(2023年9期)2023-06-03 03:32:40现代经济信息(2023年9期)2023-04-15 14:10:32中学生数理化·八年级物理人教版(2022年9期)2022-10-24 07:03:48中国化肥信息(2021年9期)2022-01-19 03:19:06今日农业(2021年1期)2021-03-19 08:35:16今日农业(2020年24期)2020-12-15 16:16:00北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:48华南农业大学学报(社会科学版)(2015年3期)2016-01-11 11:46:23俄罗斯问题研究(2012年1期)2012-03-25 09:54:48中学理科·综合版(2008年9期)2008-10-15 10:53:48
