
基于多特征模型融合的社交评论分析
2019-05-24 14:20郭瑞祥左彬靖杜成喜肖明王杰
无线互联科技 2019年1期
郭瑞祥 左彬靖 杜成喜 肖明 王杰
摘 要:随着社交网络的日益庞大,各类评论信息产生的渠道和数量也飞速增长,通过人工阅读所有评论来了解口碑情况变得日益困难,所以构建一个精准的口碑评论分值预测模型对商家和用户来说都显得日益重要。文章旨在对真实口碑评论数据进行分析挖掘和多维度特征提取,并构建一个基于多特征的加权融合模型对口碑评论的评分值进行预测。通过实验证明,在当前数据基础上,该模型可以有效地对口碑评论进行预测,相比传统方法,效果更好。
关键词:口碑评论;特征提取;机器学习
随着移动互联网时代的到来,个人在社交媒体贡献着大量的内容,发表评论已经成为个人表达个人情绪、消费评价、对事物的看法的一种主要方式,对商家发声反馈的渠道越来越多,但是发声的便利性跟渠道的多样性也带来了一些问题,商家完整全面聆听客户反馈的难度也增大了。“口碑评论”是反映一个商家或景点受欢迎程度的很直接的参考意见,此类评价分散在各个媒体渠道中,想要了解商家的大众口碑、服务质量,需要逐条地去阅读各类评价,因数据量巨大很难准确评估商家在大众心里的印象和口碑。
为了解决上述问题,本文提出一种基于多特征的加权融合模型,针对DataFountain平台提供的互联网上用户对景区评价以及口碑分值的数据集,进行统计特征,N-gram,TF-IDF,Word2Vec多维的特征提取,分别训练Lightgbm,TextCNN,RidgeRegression模型,进行模型融合。本文选用1/1+RMSE作为评价标准,在该评价标准下,通过实验比较各算法模型的效果,结果表明,本文提出的方案取得了很好的预测效果。
1 数据描述
本文的数据基于旅游评论数据,大多源于驴妈妈、携程等第三方平台爬取,能很好地反映旅游社交评论的情况。主要字段为用户ID、用户评价,标签字段为用户的评论分值,如表1所示[1]。
2 模型设计及其原理
2.1 模型整体结构
基于数据情况对文本进行特征提取和模型的设计,在数据预处理及分词去停词后,主要提取了N-gram,TF-IDF,Word2Vec,情感值等统计特征。基模型的构成为Word2Vec+TF-IDF+N-Gram+Stats-feature+LightGBM,TF-IDF+N-Gram+Ridge,Word2Vec+TextCNN。
模型结构如图1所示。
2.2 特征分析及算法原理
2.2.1 特征分析
(1)N-Gram。
N-Gram是自然语言处理中一个非常重要的语言模型,在文本特征处理的时候,通常一个关键词作为一个特征。但是这在一些场景下是远远不够的,我们需要进一步提取更多的特征,如考虑两两组合提取Bi-Gram特征,根据N-Gram语言模型,计算各个Bi-Gram组合的概率,作为新的特征。本文主要提取了Bi-Gram和Tri-Gram特征。
(2)TF-IDF。
用词频来衡量文章中的一个词的重要性不够全面,有时候重要的词出现的不够多。为了解决这个问题,词频—反转文件频率(Term Frequency–Inverse Document Frequency,TF-IDF)被提出来了。TF-IDF定义为词频(TF)乘以逆文档频率(IDF),能有效地反映出一个词在文档中的重要性,并且具有简单快速易理解的特点。
(3)Word2Vec。
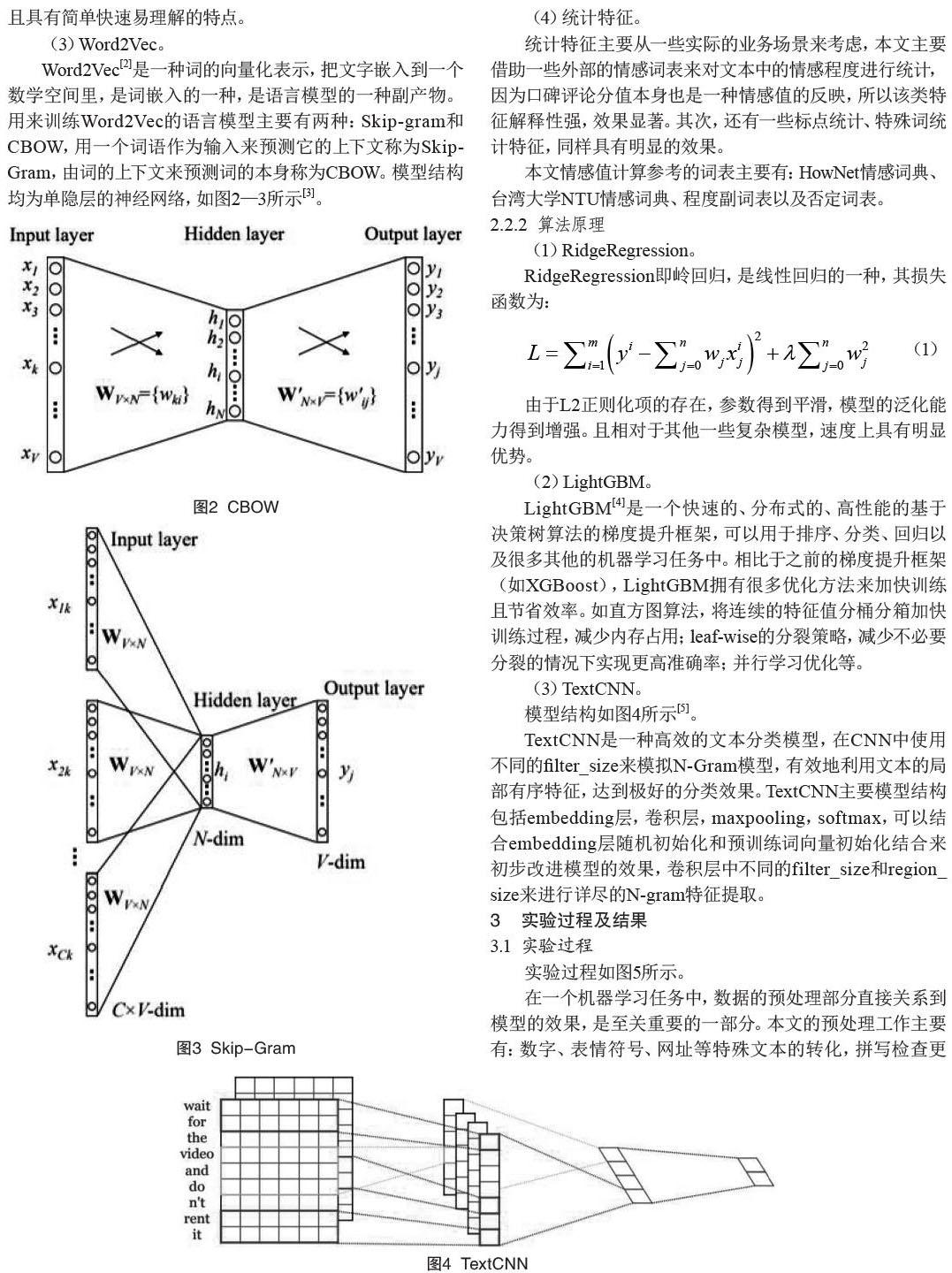
Word2Vec[2]是一种词的向量化表示,把文字嵌入到一个数学空间里,是词嵌入的一种,是语言模型的一种副产物。用来训练Word2Vec的语言模型主要有两种:Skip-gram和CBOW,用一个词语作为输入来预测它的上下文称为Skip-Gram,由词的上下文来预测词的本身称为CBOW。模型结构均为单隐层的神经网络,如图2—3所示[3]。
(4)统计特征。
统计特征主要从一些实际的业务场景来考虑,本文主要借助一些外部的情感词表来对文本中的情感程度进行统计,因为口碑评论分值本身也是一种情感值的反映,所以该类特征解释性强,效果显著。其次,还有一些标点统计、特殊词统计特征,同样具有明显的效果。
本文情感值计算参考的词表主要有:HowNet情感词典、台湾大学NTU情感词典、程度副词表以及否定词表。
2.2.2 算法原理
(1)RidgeRegression。
(2)LightGBM。
LightGBM[4]是一个快速的、分布式的、高性能的基于决策树算法的梯度提升框架,可以用于排序、分类、回归以及很多其他的机器学习任务中。相比于之前的梯度提升框架(如XGBoost),LightGBM拥有很多优化方法来加快训练且节省效率。如直方图算法,将连续的特征值分桶分箱加快训练过程,减少内存占用;leaf-wise的分裂策略,减少不必要分裂的情況下实现更高准确率;并行学习优化等。
(3)TextCNN。
模型结构如图4所示[5]。
TextCNN是一种高效的文本分类模型,在CNN中使用不同的filter_size来模拟N-Gram模型,有效地利用文本的局部有序特征,达到极好的分类效果。TextCNN主要模型结构包括embedding层,卷积层,maxpooling,softmax,可以结合embedding层随机初始化和预训练词向量初始化结合来初步改进模型的效果,卷积层中不同的filter_size和region_size来进行详尽的N-gram特征提取。
3 实验过程及结果
3.1 实验过程
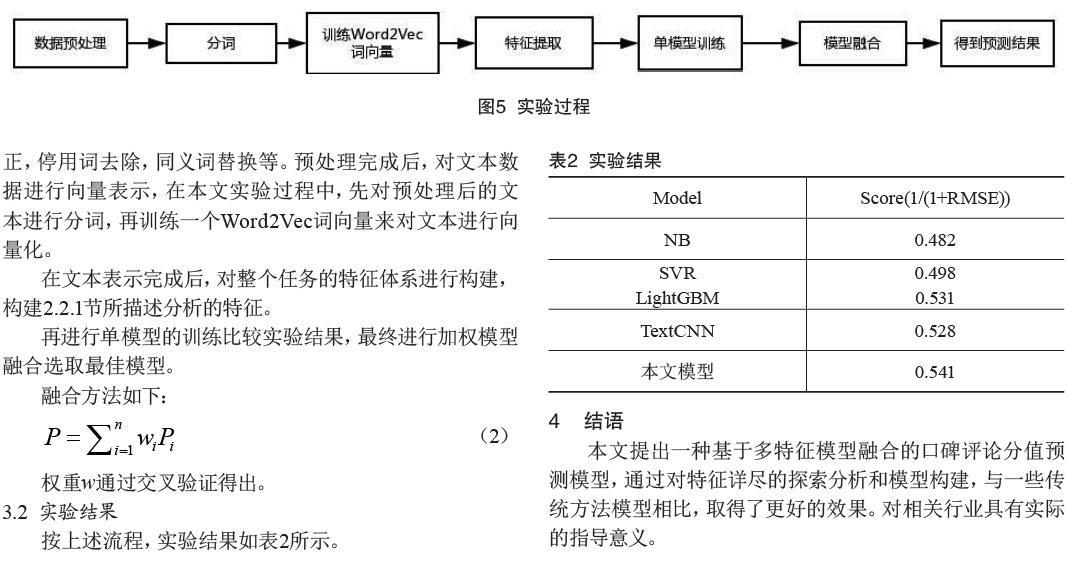
实验过程如图5所示。
在一个机器学习任务中,数据的预处理部分直接关系到模型的效果,是至关重要的一部分。本文的预处理工作主要有:数字、表情符号、网址等特殊文本的转化,拼写检查更正,停用词去除,同义词替换等。预处理完成后,对文本数据进行向量表示,在本文实验过程中,先对预处理后的文本进行分词,再训练一个Word2Vec词向量来对文本进行向量化。
在文本表示完成后,对整个任务的特征体系进行构建,构建2.2.1节所描述分析的特征。
再进行单模型的训练比较实验结果,最终进行加权模型融合选取最佳模型。
4 结语
本文提出一种基于多特征模型融合的口碑评论分值预测模型,通过对特征详尽的探索分析和模型构建,与一些传统方法模型相比,取得了更好的效果。对相关行业具有实际的指导意义。
[参考文献]
[1]DataFountain.景区口碑评价分值预测[EB/OL].(2018-06-23)[2018-11-05].https://www.datafountain.cn/competitions/283/details/data-evaluation.
[2]LE Q,MIKOLOV T.Distributed representations of sentences and documents[C].Sydney:International Conference on International Conference on Machine Learning,2014.
[3]XIN R.Word2Vec parameter learning explained[M].Evansto:Eprint Arxiv,2014.
[4]KE G L,MENG Q,FINLEY T,et al.LightGBM: a highly efficient gradient boosting decision tree[C].Siem Reap:the Neural Information Processing Systems Conference,2017.
[5]KIM Y.Convolutional neural networks for sentence classification[M].Evansto:Eprint Arxiv,2014.
猜你喜欢
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
中国生物医学工程学报(2017年6期)2017-02-10
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
广西科技大学学报(2016年1期)2016-06-22
噪声与振动控制(2015年4期)2015-01-01
轴承(2010年2期)2010-07-28
