
基于长短期记忆神经网络的油田新井产油量预测方法
2019-05-16 03:08侯春华
油气地质与采收率 2019年3期
侯春华
(中国石化胜利油田分公司勘探开发研究院,山东东营257015)
通过新井的不断投入来弥补老井递减,是保持油田产油量持续稳定的必然手段。但由于新井生产历史短,不确定因素多,一直是油田产油量预测的重点和难点。中国对油田新井产油量的预测有诸多种方法,主要可以概括为基于单因素的预测方法和基于多因素的预测方法[1-9]。其中,基于单因素的预测主要采用曲线拟合法,往往只考虑时间因素;基于多因素的预测考虑了开发指标与其他相关影响因素的关系,一般有多个输入变量和1个输出变量。近年来,随着人工智能算法的进步,人工智能预测方法逐渐应用于油田新井产油量预测。人工智能算法可以较好地对复杂的非线性函数映射关系进行描述,对数据中的特征进行挖掘和学习,从而将数据转换为更高层次的表达,拟合和预测效果均较好。目前在油田新井产油量预测中使用的人工智能算法主要有支持向量机回归和反向传播(简称BP)神经网络[10-13],但这2种方法无法考虑数据在时间上的相关性,并且对自变量的选择较敏感。为此,笔者采用改进的循环(简称RNN)神经网络,即基于长短期记忆(简称LSTM)神经网络对油田新井产油量进行预测,该方法不仅可以考虑相关因素对产油量的影响,还能考虑数据在时间上的相关性,预测精度高,适应性强,可作为一种新的方法应用于油田新井产油量预测。
1 RNN与LSTM神经网络
1.1 BP神经网络
神经网络模型模仿了生物神经元,具有加权、求和与转移3个功能。BP神经网络[14]是一种按照误差逆向传播算法训练的多层前馈神经网络,其结构包括输入层、隐含层和输出层,是目前应用最广泛的神经网络。在输入层输入后,下一层第j个神经元的净输入值方程为:

净输入通过传递函数(Transfer Function)后,即可得第j个神经元的输出方程为:
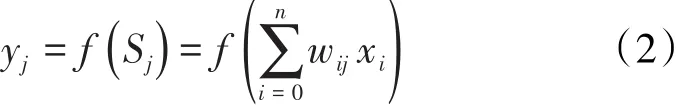
BP算法由数据流的正向传播和误差信号的反向传播2个过程构成。正向传播时,传播方向为输入层→隐层→输出层,每层神经元的状态只影响下一层神经元。若在输出层得不到期望的输出,则转向误差信号的反向传播流程。通过交替进行这2个过程获得参数值。
1.2 RNN神经网络
相比于普通的BP神经网络,RNN神经网络是有记忆的,它能够捕捉到序列的历史信息并将其应用于当前输出的计算中。在RNN神经网络中,一个序列在当前的输出不仅与其在当前的输入有关,也与前面的输出有关,即能够捕捉到序列的历史信息并将其应用于当前输出的计算中。而BP神经网络假设样本之间是相互独立的,无法将数据在时间上的相关性考虑进去,因此在处理序列数据时采用RNN神经网络可以避免BP神经网络的缺点。
油田产油量除了受到工作量、地质因素和技术因素等影响之外,在时间上也表现出较强的相关性,若进行产油量预测时未将其考虑进去则会对预测的准确度造成较大的影响,因此RNN神经网络更适合于油田产油量的预测。RNN神经网络主要是利用其隐藏层单元将产油量在时间上的相关性考虑进去,其隐藏层单元展开如图1所示。
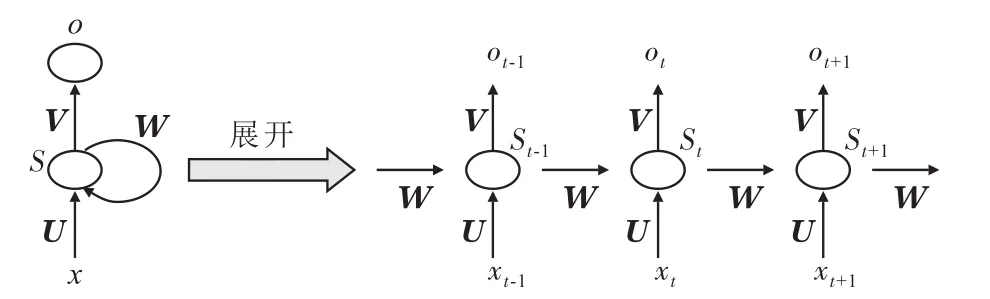
由当前步的输入和隐藏层上一步的状态计算得到当前步的状态为:
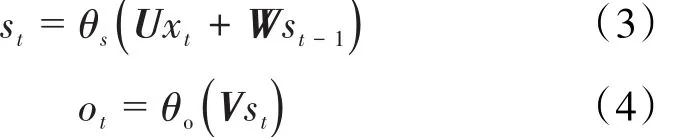
RNN神经网络可以通过时间反向传播(Back-Propagation Through Time,简称 BPTT)算法进行训练。由于RNN神经网络每一隐藏层的各个时间步都共享权重参数U,W和V,即当前损失函数对网络权重的偏导数不仅与当前时间步有关,还与之前的时间步有关,因此需要对每个时间步反向传播的结果利用链式法则进行叠加,得到损失函数对网络权重的偏导数,再通过梯度下降对网络权重进行更新。
在RNN神经网络中,理论上隐藏层第t时间步的状态是可以包含前面所有时间步信息的,但随着时间步反向迭代的进行,较远时间步的梯度会逐渐趋近于0,致使标准RNN神经网络无法学习到长期依赖,这被称为梯度消失(Vanishing Gradient)问题。
在建立油田产油量的预测模型时,利用的数据往往是一个较长周期内的年度数据,甚至是大量的月度和每日的数据。因此,如果直接基于RNN神经网络构建预测模型,则会由于梯度消失的问题对较早时期的数据无法学习。
1.3 LSTM神经网络
为了解决梯度消失问题,有学者对标准RNN神经网络结构进行了改进,提出了LSTM神经网络[15]。在RNN神经网络的基础上,LSTM神经网络引入了记忆单元(Memory Cell)和隐藏层状态(Cell State)的机制来控制隐藏层之间的信息传递。一个LSTM神经网络的记忆单元内有3个门(Gates)计算结构(图2),分别是输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)。其中,输入门能控制新信息的加入或滤出;遗忘门能忘记需要丢掉的信息以及保留过去有用的信息;输出门能使记忆单元只输出与当前时间步相关的信息。这3个门结构在记忆单元中进行矩阵乘法和非线性求和等运算,使得记忆在不断的迭代中仍然不会衰减。
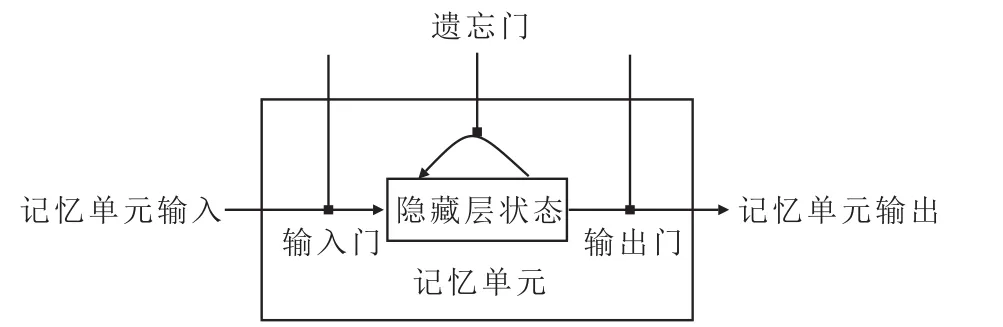
图2 LSTM神经网络的记忆单元结构Fig.2 Memory cell structure of LSTM neural network
第t时间步输入的信息首先通过输入门,第t时间步记忆单元输入层的值和隐藏层状态的候选值分别为:
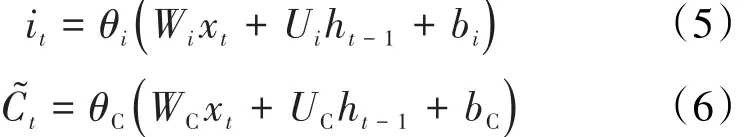
随后,信息通过Forget Gate,第t时间步记忆单元遗忘层的值为:
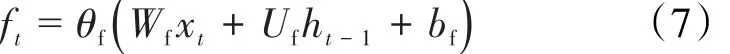
此时,可以得到记忆单元隐藏层状态在第t时间步时的更新值为:

最后,信息通过Output Gate,第t时间步记忆单元输出层的值以及最终记忆单元的输出值分别为:
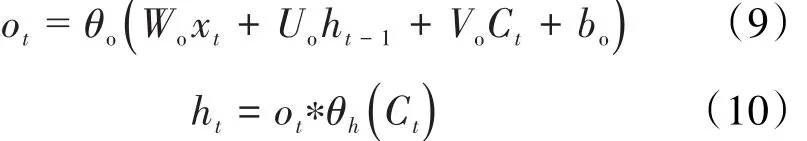
研究[16-17]表明,LSTM神经网络在诸多条件下的表现均优于标准RNN神经网络。基于以上介绍,针对LSTM神经网络对多元时间序列建模能力强的特点,采用LSTM神经网络对数据中的特征进行挖掘和学习,得到更加理想的预测模型,对油田产油量进行预测。
利用LSTM神经网络的建模步骤主要包括:①对所选数据集进行划分,得到训练集和验证集来进行交叉验证,并保留一部分作为测试集对模型进行评价。②为避免过多输入变量造成求解模型的困难,对输入的影响变量进行筛选。③为消除各个变量之间的不同量纲并加快模型训练速度,在输入数据前对每个变量的数据进行标准化处理。④选择模型的一系列超参数进行网络训练,并根据结果不断进行调试,得到最终的预测模型。⑤将训练好的模型在测试集上进行测试,对比预测结果与实际值的差距,检验模型的预测效果。
2 基于LSTM神经网络的油田新井产油量预测模型
油田的产油量预测包括自然产油量、新井产油量、措施产油量等不同构成产油量的预测。不同的构成,影响因素不同,但都可以采用该方法进行预测。为说明方法的使用步骤及验证方法的精度,以某油田新井单井年产油量预测为例,构建相应的LSTM神经网络模型进行产油量预测,并与支持向量回归和BP神经网络2种方法的预测结果进行对比。
2.1 数据来源
选取某油田2001—2017年开发指标中的年度数据。其中,将2001—2012年的数据作为训练集用于拟合模型,2013—2016年的数据作为验证集用于确定网络结构和模型参数,保留2017年的数据作为测试集用于评价模型性能。模型的输出变量是新井单井年产油量,候选的输入变量包括区块的综合含水率、注采比、单井控制地质储量、采出程度、新井总井数、新井当年生产天数。LSTM神经网络模型的构建通过Keras深度学习框架实现。
2.2 输入变量筛选
过多的输入变量将会导致网络规模过大、参数过多、收敛速度慢。此外,若输入变量之间高度相关,造成变量的重复使用和数据冗余,也会增加网络的计算量。因此,采用Pearson相关性分析来衡量油田数据的线性相似度,选择与新井单井年产量相关性较高但相关性较小的输入变量来避免上述问题。2个变量的Pearson相关系数计算公式为:
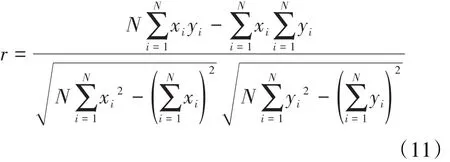
Pearson相关系数的绝对值越接近1,2个变量间的相关程度越高;Pearson相关系数越接近0,2个变量间的相关程度越弱。从所选输入变量及其之间的相关性分析结果(表1)可以看出,综合含水率与单井控制地质储量、采出程度相关系数达到0.77以上,说明这3个指标存在较明显的相关性,开发指标之间并不是独立的。因此,仅选取其中1项综合含水率进入模型即可代表3个因素对预测变量的影响。同时,由于综合含水率、注采比、新井总井数、新井当年生产天数4个变量之间相关性较低,因此选择这几个作为模型的输入变量较为合适。
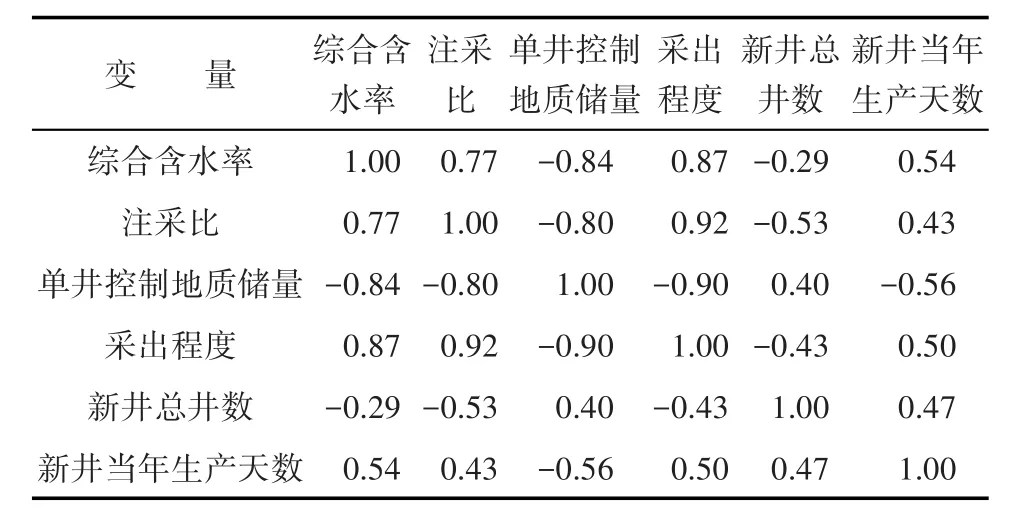
表1 油田所选输入变量及其之间的相关性分析结果Table1 Selected input variables and their correlation analysis result
2.3 输入数据预处理
在输入数据前,对每个变量进行极差标准化处理,映射到(0,1)区间,公式为:
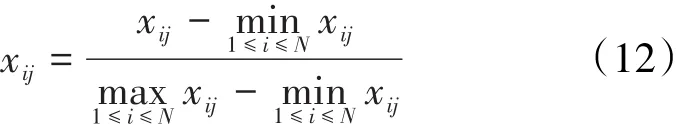
实际操作中,在变量进入模型前,由于考虑了多个滞后期的影响,需要指定时间步长并对数据进行重塑。时间步长为1意味着t-1时点的输入特征会作为预测t时点目标变量的输入,时间步长为2意味着t-2和t-1时点的输入特征会作为预测t时点目标变量的输入,依此类推。最终进入模型的数据被重塑为(样本数目、时间步长、特征数目)三维数据。通过多次调整,观察到在利用所选数据构建预测模型时,采用时间步长为3可以得到较好的预测效果。
2.4 网络训练
采用双LSTM层的神经网络模型对新井单井年产油量进行预测。经过不断地调试和搜索,最终确定模型第1层有50个神经元,第2层有60个神经元,激活函数采用ReLU激活函数,损失函数采用均方误差函数,优化器为Adam优化算法,每次训练的轮次为100。由于多个网络层带来大量参数,实际训练中容易过拟合,因此采用Dropout方法防止过拟合。Dropout方法在众多数据集上被验证是防止过拟合的有效方法[18],是指在深度学习网络的训练过程中,按照一定的比例将神经网络单元暂时从网络中丢弃。采取的Dropout比例为0.1。另外,由于实际训练时网络初始权重的设定等过程存在随机性,因此将训练过程重复实验30次,将表现指标上得到的结果取平均值作为衡量模型表现的参考。其中一次训练过程中,模型的损失函数下降过程(图3)以及产油量实际值和拟合值的对比(图4)可以看到,模型在训练集上的损失函数不断下降并最终趋近于0,说明最终得到的参数是该结构下的最优参数结果;而从图4中可以看到,模型得到的拟合值曲线与新井单井年产油量的实际值曲线表现出了同样的趋势,并且在每一年度中两者之间的误差都比较小甚至十分接近,说明模型的拟合效果很好。
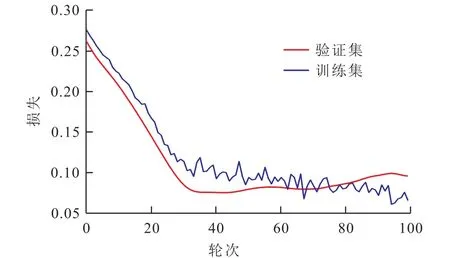
图3 损失函数下降过程Fig.3 Loss function decline process

图4 新井单井年产油量实际值与拟合值对比Fig.4 Comparison of actual and fitting values of yearly oil production of new single well
利用模型训练得到拟合值和所选取数据的实际值之间的平均相对误差来衡量模型的拟合效果,30次训练的平均相对误差均值为9.91%,说明该模型拟合效果较好。
2.5 网络预测及模型对比
将训练好的模型用于预测2017年新井单井年产油量,根据标准化的过程,将预测变量逆向还原后与实际值对比,并计算预测值的平均预测误差。利用支持向量回归模型和BP神经网络对同一数据集建模进行预测。从3种方法的预测结果及对比(表2)可看出,LSTM神经网络的预测值为1 255.67 t/a,与实际值1 287.76 t/a差距较小,平均预测误差为1.45%,说明应用LSTM神经网络对油田产油量的预测精度较高;并且30次训练过程中预测值的标准差为18.48,预测误差的标准差为0.99%,说明构建出的模型在不同的随机初始权重下得到的预测结果有着较好的稳定性。
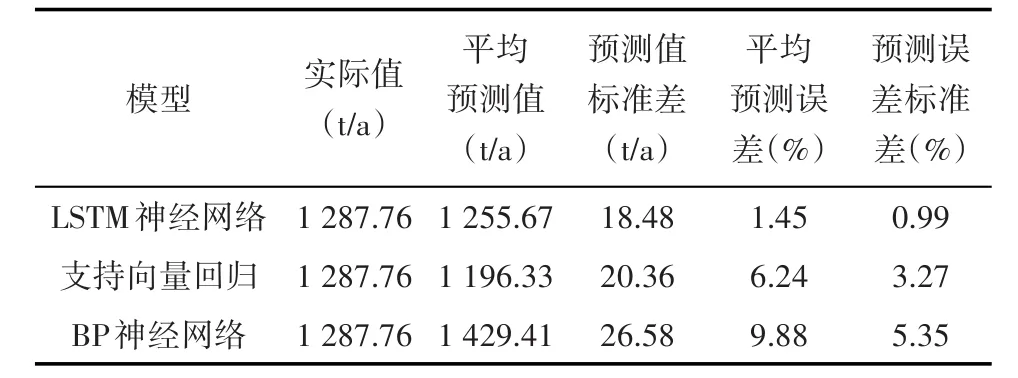
表2 3种方法预测2017年新井单井年产油量效果对比Table2 Performance comparison of forecasted yearly oil production of new single wells by LSTM neural network,support vector regression model and BP neural network in 2017
支持向量回归模型和BP神经网络在训练集和验证集上的平均相对误差分别为10.92%和12.17%,对2017年数据的平均预测误差为6.24%和9.88%。这2种模型的拟合效果稍差于LSTM神经网络,预测准确性相比于LSTM神经网络差距较大。因此基于LSTM神经网络构建的新井单井年产油量预测模型的效果要优于基于支持向量回归和BP神经网络构建出的模型。
将3种方法得到的拟合和预测结果分别与实际值对比(图5)可以看到,LSTM神经网络模型不仅能够拟合和预测得更加准确,还能更好地把握住数据变化的趋势,而另外2种模型对数据趋势的把握都稍差于LSTM神经网络模型。

图5 3种方法新井单井年产油量实际值与拟合值对比Fig.5 Comparison of actual and fitting values of yearly oil production of new single well estimated by three methods
3 结论
提出基于LSTM神经网络的油田新井产油量预测模型。以某油田新井单井年产油量预测为例,说明了方法使用步骤,验证方法精度。利用Pearson相关性分析对网络输入变量进行了筛选,设计网络结构及确定参数,将数据归一化并重塑后对模型进行训练并进行预测。实例结果表明,与支持向量回归模型和BP神经网络相比,LSTM模型预测精度较高、适应性较强,基于LSTM神经网络的预测方法是可行的,可以作为一种新的方法用于预测油田新井产油量。
符号解释:
Sj——下一层第 j个神经元的净输入;j,i——变量,1,2,…,n;wji——第i个神经元与下一层第j个神经元的连接强度,即权值;xi——第i个神经元的输入,即自变量的第i个样本点;bj——阈值;yj——下一层第j个神经元的输出,即因变量的第j个样本点;f(·)——传递函数;wij——神经元之间的权值;st——隐藏层第t时间步的状态;t——隐藏层记忆单元的时间长度;θs——隐藏层激活函数;U——输入层到隐藏层的权重矩阵;S——神经网络的隐藏层;W——隐藏层到隐藏层的权重矩阵;V——隐藏层到输出层的权重矩阵;o——神经网络的输出层;x——神经网络的输入层;xt——第t时间步时的输入;ot——第t时间步记忆单元输出层的值;θo——输出层激活函数;it——第t时间步记忆单元输入层的值;θi——该层激活函数;Wi——记忆单元中输入对应的权重;Ui——记忆单元中上一时间步输出值对应的权重;ht-1——上一时间步输出值;bi——记忆单元中的常数;C˜t——第t时间步隐藏层状态;θC——隐藏层激活函数;WC——隐藏层中输入对应的权重;UC——隐藏层中上一时间步输出值对应的权重;bC——隐藏层中的常数; ft——第t时间步记忆单元遗忘层的值;θf——遗忘层的激活函数;Wf——遗忘层中输入对应权重;Uf——遗忘层中上一时间步输出值对应的权重;bf——遗忘层中的常数;Ct——隐藏层状态在第t时间步的值;∗——矩阵的哈达玛积(Hadamard Prod⁃uct);Wo——该层中输入对应权重;Uo——输出层中上一时间步输出值对应的权重;Vo——输出层中隐藏层状态对应的权重;bo——输出层中常数;ht——第t时间步最终输出值;θh——对隐藏层状态值的激活函数; r——Pearson相关系数;N——样本数量;xij——第i个样本第j个变量的值。
猜你喜欢
作物研究(2021年4期)2021-09-05
水泵技术(2021年2期)2021-07-31
中学生数理化·中考版(2020年11期)2020-12-14
智富时代(2019年10期)2019-12-09
智富时代(2019年10期)2019-12-09
煤炭工程(2019年5期)2019-05-28
动漫星空(兴趣百科)(2017年5期)2017-10-30
热带农业科学(2017年9期)2017-10-23
江苏农业科学(2017年1期)2017-02-27
能源(2016年1期)2016-12-01
