
数据挖掘在高校毕业生精准就业中的路径研究
——以计算机专业为例
2019-05-16 09:17任培花
山西大同大学学报(自然科学版) 2019年2期
任培花,阮 超
(山西大同大学计算机与网络工程学院,山西大同037009)
随着我国教育制度的改革,高校招生规模不断扩大,劳动力市场供过于求,大学生就业形势十分严峻。近年来随着信息化技术的不断使用高校积累了大量的教学与管理数据,但目前并不能有效地对这些数据进行使用与分析,高校的教务系统一般只是对学生成绩的录入与展示,而对成绩分析的涉及很少,将成绩数据与就业回访数据进行交叉分析的更是少之又少。即使有个别高校尝试运用数据分析方法研究这些数据来解决学生的就业问题,最后大多不能提取出有效的信息,不能很好的为在校学生的就业提供合理的指导意见。然而对于就业单位而言,招聘学生时,面对学生众多的科目成绩,很难确定该学生的岗位能力水平,因此急需采用有效的数据挖掘方法将在校学生的各科成绩转化为能力成绩,这些能力成绩可以直接为在校学生就业单位提供参考依据。
将数据挖掘技术运用于教育教学领域称之为教育数据挖掘,国外在教育方面进行数据挖掘起步较早。Hashmia Hamsa采等用决策树和模糊遗传算法建立模型,通过预测模型可用于识别每个学科的学生表现[1];Prabal Verma等基于物联网节点的感知能力收集学生日常活动数据,使用集成了硬件、软件和网络技术的智能计算技术,为系统提供实时状况感知和自动分析,并且结合教育数据挖掘算法和学生成绩数据集的结果来计算每个课程的学生表现[2];Yin Fei Dai等利用Apriori关联规则算法,对数百名学生成绩进行综合挖掘,结合理论和事实基础对这些数据进行合理的开发和利用,找出学生与课程之间的相关性。在课程设置和安排方面具有重要意义[3]。
国内研究数据挖掘技术始于90年代中期。近年来将数据挖掘技术应用与成绩分析方面的研究逐渐增多,如针对学生成绩问题,用决策树建立分析预测模型,找出影响学生成绩的因素[4];采用Apriori算法挖掘出对学生通过等级考试最有影响的因素以及各科目试卷成绩的优良影响关系[5];从历年来的学生成绩及其相关数据库中找到符合条件的规则,学校对教学内容进行调整和教学方法进行改进以适应学生的学习和教学质量的提高[6];苏州大学夏华老师融合统计学、数据挖掘方法实现对成绩数据的指标量化和全面管理,通过各项统计指标清晰展现学生成绩的总体水平和个体差异,运用关联规则和决策树对成绩数据进行挖掘,发现成绩背后的潜在规律和关系[7];青岛理工大学胡在林老师将关联规则和决策树结合算法用于本校计算机学生成绩分析与预测研究工作,分析预测结果更加全面、可靠,预警功能更加有针对性。成绩分析和预警的结果能够为学校教学提供信息支持[8]。
地方高校普遍存在业务数据分散,数据分析欠缺,学生能力指标脱离实际,就业指导水平低下等问题。通过深入研究分析,构建了一个高校毕业生精准就业中的数据分析模型,该模型将高校中部分业务数据重构数据中心,然后采用决策树算法进行学生能力指标计算,进而给出学生一个较为准确的就业方向推荐。
1 高校毕业生精准就业数据分析流程
地方高校的业务数据种类很多,如学生成绩数据、教师数据、科研数据、设备数据、社团数据、就业数据等等。以实现地方高校毕业生精准就业为视角开展研究,将分散的学生成绩数据与就业数据进行整合研究,即建立包含学生成绩和就业数据的数据中心,然后从学生精准就业的角度,对数据中心中的数据进行模型化研究。由于决策树算法具有分类精度高、生成模式简单、对噪声数据有很好的健壮性等优点,故该模型中的数据分析方法采用决策树算法。下面是高校毕业生精准就业数据分析流程图,如图1所示。
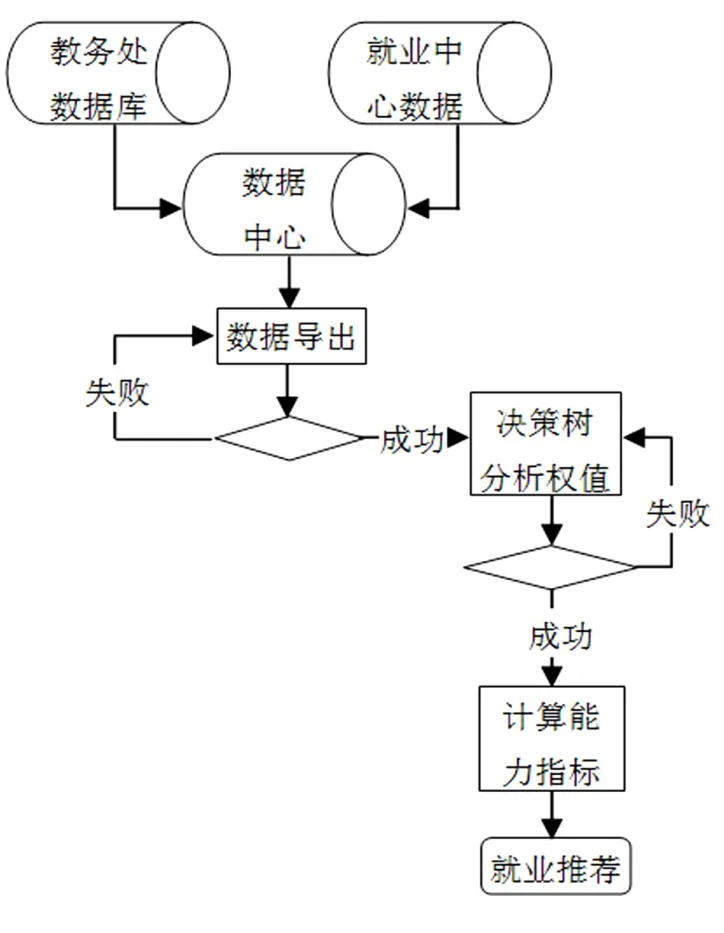
图1 高校毕业生精准就业数据分析流程图
具体的做法:
(1)实时获取数据
以某高校计算机专业为例,使用python脚本从不同部门的数据库系统中,实时获取学生成绩数据与就业回访数据,建立数据中心。其中学生成绩数据包括已就业学生和在校生两种。就业回访数据只包含已就业的学生回访数据。
(2)数据导出
对整合后的学生数据进行导出,为了便于各种数据分析工具的使用,导出的格式类型要丰富。
(3)数据分析
以已就业学生为样本,采用决策树算法挖掘出影响学生就业的各科课程的权重,从而得出在校学生的能力指标分数,以此对在校学生进行就业精准推荐。
图1 的分析结果不是一成不变的。随着时间的推移,业务系统的数据不断增多,数据中心分析得出的各科权值在实时更新,通过实时获取数据模块来实时获取各业务系统的最新数据,保证了数据中心数据集的更新度,从而分析计算得出最有效的能力指标分数。
2 高校毕业生精准就业路径模型
经过调研分析,数据分析模型主要涉及的用户包括学生、系统管理员。学生享有浏览成绩、查询自己能力指标的功能。系统管理员负责判别各业务系统的数据库,区分出主流数据库如MySQL、Oracle、SQL Server或是电子表格等,然后启动Python脚本或手工导入。将不同业务部门数据导入数据中心,运行SQL脚本关联更新数据中心学生表,以及维护系统的稳定性。如图2所示为高校毕业生精准就业路径模型。
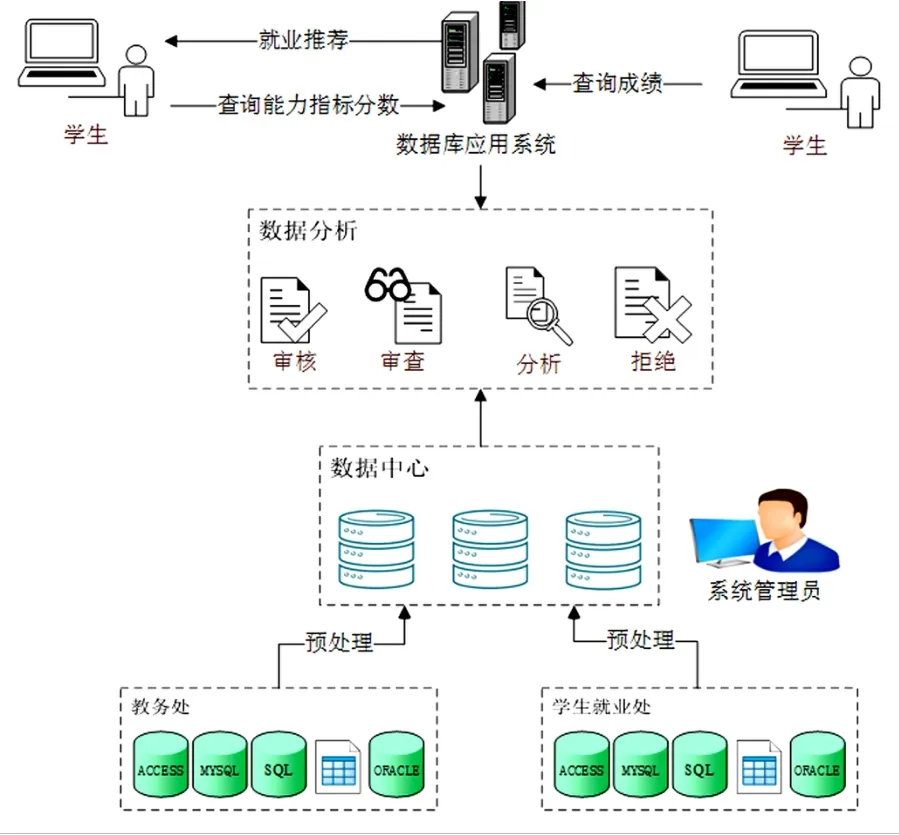
图2 高校毕业生精准就业路径模型
(1)实时抽取数据
根据业务系统数据库类型的不同,数据抽取的方式也不同。针对主流数据库如MySQL、Oracle、SQL Server等,先将数据预处理后进入数据中心,之后运行写好的Python脚本,将最新的数据更新进入数据中心。为保证数据不会丢失,Python脚本每30秒执行一次,每次抽取5分钟之内的数据,重复数据replace,既可以保证数据的实时性又可以保证数据的有效性与准确性;针对于电子表格等,需要手动将导入数据,可使用数据库工具Navicat将Excel数据导入数据库,并执行SQL脚本将数据关联更新进入数据中心。待之后业务系统数据库升级为主流数据库,可采用上述方式实现实时抽取数据。
(2)学生能力指标评定
关于学生能力指标的制定,为了保证能力指标的有效性,以人才培养方案为指导,以已就业学生回访数据为基础,进行课程权重分析。下面以某高校2016年计算机专业人才培养计划为例,通过分析2016年~2017年学生就业中心计算机专业学生的回访数据,首先抽取和该专业就业密切相关的课程分类表,如表1所示。

表1 计算机专业科目分类表
经过抽取分析可以得出,课程大类分为学科与专业基础课程、专业选修课程和实践教学课程三大类。然后参照用人单位的招聘要求,将这三类分别对应学生的理论学习能力、实践应用能力和综合素质能力,这三种能力可以作为学生能力指标使用,如表2所示。

表2 学生能力指标科目分类表
(3)数据分析
数据分析模块使用数据中心的数据采用数据挖掘中的决策树算法对学生成绩数据进行分析。决策树算法属于监督学习的范畴,分析过程如下:
①加载数据集,根据数据集设置样本X与标签Y;
②采用机器学习算法库sklearn中的决策树CART算法,对X与Y进行训练,画出决策树;
③根据决策树可以得出每个因子的重要程度,以此来划分权值。
具体实现过程:系统管理员将数据中心学生表数据导出,运行Python代码对学生表数据进行分析,得出影响学生就业的各科目权值。如表3所示为,由于字段过多只显示部分。

表3 学生各课权值表
参考表2学生能力指标科目分类表,计算加权平均数即可得出学生各个能力指标分数,如表4所示。

表4 学生能力指标分数表
3 结语
目前地方高校的信息化建设虽然取得了较为显著的成就,但仍然存在一些问题:各业务部门的信息化程度参差不齐,有些部门没有专门的数据库,业务数据甚至以电子表格的形式存在;缺乏统一的数据标准,增加了数据分析的困难;业务部门之间数据整合水平普遍低下等等。考虑到现存的问题,数据回收采用手工和Python脚本实时抽取两种方式。另外目前数据中心涉及的业务数据仅包括成绩数据和就业数据,以后可以围绕学生就业,刻画包含学业、创新创业、社团活动、竞赛、就业等方面的学生全维度画像(如图3所示),进而增加数据中心的多维度数据,这样有助于算出更全面的学生能力指标分数,帮助管理者全面认识学生,推动大数据画像技术服务于大学生精准就业。
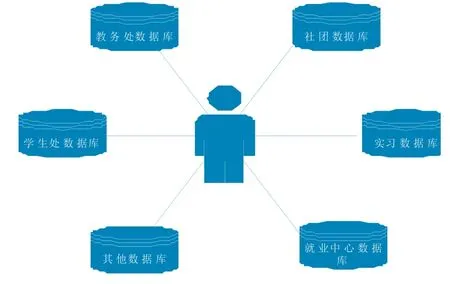
图3 学生全维度画像图
猜你喜欢
机械研究与应用(2022年4期)2022-09-15
建材发展导向(2021年7期)2021-07-16
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
西藏艺术研究(2019年1期)2019-09-04
电子制作(2018年16期)2018-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
智能系统学报(2015年4期)2015-12-27
中国交通信息化(2015年3期)2015-06-05
郑州大学学报(医学版)(2015年1期)2015-02-27
