
满足RoboCup规范小型类人足球机器人设计与目标识别
2019-05-16 08:11燕必希王子润董明利
北京信息科技大学学报(自然科学版) 2019年2期
燕必希,王 智,费 奇,王子润,董明利
(北京信息科技大学 仪器科学与光电工程学院,北京 100192)
0 引言
RoboCup足球机器人竞赛是由RoboCup国际协会组织的高科技对抗活动,其愿景是在2050年,能够和真人展开一场真正的足球比赛[1]。由于其具有的趣味性和高技术应用特点,在国际上得到广泛开展。足球机器人融合了信息、机械、自动化、计算机、传感技术、人工智能和仿生学等多学科知识和研究成果,代表高技术发展的前沿,足球机器人成为当今科学研究的热点之一。
参加RoboCup竞赛的足球机器人必须满足RoboCup技术规范。对于小型类人足球机器人,最新技术规范版本是2018版,要求身高在40~90 cm之间,并满足自然人的特征,如脚的外包络矩形不能太大,长宽比例在一定范围内,机器人躯干、四肢的比例和重心位置等均与自然人相近[2]。
在比赛过程中,足球机器人通过摄像机定位足球和球门,调整自身姿态和位置,对带球或是射门进行决策,并最终得分。在上述一系列技术环节中,快速找到足球和球门是机器人足球比赛中最为基础和关键的环节。传统的基于彩色图像分割算法[3]是通过识别物体的颜色特征信息来识别物体,但由于最新的足球机器人比赛规则发生变化,边界、门框颜色都为白色,足球也不同以往的彩色球,导致最终传统算法失效。特征提取SIFT算法[4](scale-invariant feature transform)是通过识别物体的位置、尺度、方向信息来识别物体,但由于足球机器人比赛场景复杂,场地内物体较多,导致识别效果较差。深度卷积神经网络算法RCNN[5](regions with convolutional neural network features)和Faster-RCNN[6](faster-regions with convolutional neural network features)将识别任务分为目标区域预测和类别预测,导致最终识别速度过慢,不能很好地达到实时性,因此不能满足足球机器人比赛的要求。
针对上述要求,本文设计了满足RoboCup2018版技术规范要求的小型类人足球机器人,采用深度卷积神经网络YOLOv3(you only look once)[7]作为视觉识别算法,使用3000张机器人比赛的照片对YOLOv3模型进行训练,训练后的模型对足球、门框、机器人具有良好的鲁棒性和泛化能力。YOLOv3算法采用了端到端的识别原理,能够快速识别图像中的目标,从而达到实时性检测。
1 小型类人足球机器人设计
RoboCup2018技术规范要求小型类人足球机器人满足如下要求:
2)脚的包络边界为凸壳矩形,矩形的长边与短边之间的比例不得超过2.5。
3)机器人外包络必须小于直径为0.55×Htop的圆柱体,其中Htop为机器人直立姿态下的身高。
4)四肢延展后,范围不得超过1.5×Htop。
5)腿长Hleg(包括脚)需满足0.35×Htop≤Hleg≤0.7×Htop。
6)上述5)中腿长,指机器人处于直立状态时,腿部第一个关节到脚的末端之间距离(站立时要求关节轴线平行于站立地面)。
7)头部高度Hhead(包括颈)需满足0.05×Htop≤Hhead≤0.25×Htop。Hhead为从肩部第一关节的轴线到头部顶部的垂直距离。
8)从手臂第一个关节开始算起,要求手臂长度大于等于Htop-Hleg-Hhead。
根据上述要求,制作机器人如图1所示。

图1 机器人设计图
选用韩国Robotis公司Mx系列舵机做为关节,共设计有20个自由度。机器人身高Htop=592 cm,重心位置在机器人直立时距离地面HCOM=331 cm,脚130×83 cm2,上肢284 cm,下肢305 cm,头高95 cm,上述参数均满足RoboCup2018技术规范。
2 YOLOv3算法
YOLOv3算法使用了52层卷积神经网络和1个全连接层,使用了分类网络基础模型Darknet-53[8],训练时使用已给标签的图像进行模型训练,通过类别特征及位置信息确定卷积神经网络中卷积核的参数。测试时利用训练完成的卷积核对输入图像进行目标识别,实现了快速准确识别。图2是YOLOv3目标检测的系统流程。

图2 YOLOv3目标检测的系统流程
如图2所示,在输入图片resize(尺寸调整)中,将输入图像尺寸调整为416×416并网格化,提取含有目标边框的信息。
将大小为416×416带有目标的输入图像划分为7×7的均匀网格,各网格检测边框时包含5个参数信息(x、y、ω、h、Cobj),分别表示带有目标预测边框的中心横坐标、纵坐标、宽度、高度、置信度评分[9]:
(1)
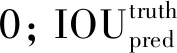
(2)
式中:Apred为检测框面积;Atruth为真实框面积。
网格后的图片进行卷积神经网络CNN(convolutional neural networks)运算,提取特征。利用52层卷积层提取图像特征,最后一层全连接层进行目标预测。若当前网格存在多个目标,则在该网格为每个目标分别赋予分类条件概率P(class|obj),整幅图片的7×7网格中目标 classi的置信度:

式中下标i为第i个目标。
卷积后的图片通过非极大值抑制(non maximum suppression,NMS)设定阈值对预选框进行筛选。设置检测边框置信度评分阈值,通过非极大值抑制过滤低于预设阈值的边框,则最终保留下的边框为正确的边框。
图3为YOLOv3在实际图像中对狗、车、自行车的识别过程。图像经过resize和卷积神经网络的处理,通过非极大值抑制对预选框进行筛选,得出最终的类别框。

图3 使用YOLOv3进行目标识别
3 实验结果
3.1 机器人制作
根据制作图纸进行了机器人的加工和组装,实物图如下。

图4 机器人实物图
3.2 网络训练
训练模型在PC端完成,配置为GPU(GTX-1080),需要配置CUDA9.0并行计算库,cuDNN7.0并行加速库,OpenCV3.2图像处理库;在ubuntu16.04系统下,搭建开源深度学习框架Darknet;拍摄3300张足球机器人比赛中含有目标的图片,其中3000张进行网络训练,300张进行测试;对预训练模型darknet53.conv.74进行50 200次迭代;评分阈值设为0.25。
训练时将目标分为3类,对足球(soccer)、机器人(robot)、门框(goal)进行训练。训练完成后,为了测试模型的准确性,使用足球机器人摄像头对现场拍摄,拍摄300张测试图片对YOLOv3模型进行测试。图5为部分图片检测效果。

图5 机器人比赛照片检测效果
Mmap(均值平均精度)和Rrecall(召回率)[10]是衡量深度学习中对象检测算法准确率的重要指标。Tp(Ture Position)是预测框与真实框保持一致的数目,Fp(False Position)是表示预测框与真实框不符合的数目,Fn(False Negatives)是表示真实框没有被检测到的数目。
通过分别使用特征提取SIFT算法、深度卷积神经网络的目标识别算法RCNN、Faster-RCNN、YOLOv3对300张图片进行测试,结果如表1所示。

表1 测试集实验结果
从表1可看出,YOLOv3算法比SIFT和RCNN算法的准确率、召回率、每秒识别帧数都要高,相较于深度学习算法Faster-RCNN虽然降低了准确率和召回率,但仍然保持较高的准确率和召回率,每秒识别帧数远大于Faster-RCNN,可以满足实时性检测。满足足球机器人比赛中的准确性和实时性要求。
4 结束语
设计了满足RoboCup2018技术规范的足球机器人,并应用YOLO3算法对比赛用球、门框、机器人进行了特征识别。YOLOv3算法相较于传统的基于彩色图像分割算法、特征提取SIFT算法以及现有的RCNN、Faster- RCNN深度学习算法具有较高的准确率和召回率,识别速度快,满足实时性要求。通过实验证明了训练后的YOLOv3模型对识别的物体具有良好的鲁棒性和泛化能力。设计的足球机器人参加了RoboCup2018中国赛和国际赛,取得了中国赛技术挑战赛第三名和国际赛技术挑战赛第四名的成绩。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
华人时刊(2021年23期)2021-03-08
作文新天地(初中版)(2019年6期)2019-08-15
小雪花·成长指南(2016年9期)2016-10-12
消费电子(2015年7期)2015-12-11
读者(2010年8期)2010-08-30
数码摄影(2009年1期)2009-01-22
